인프런 Chris Song님 강의 정리
Section2: 코드 품질, 데이터 검증, 모델 분석
데이터 검증
TFDV (TensorFlow Data Validation)
데이터 검증이 필요한 이유
- 머신러닝 시스템에서 데이터로 인한 장애는 파악하기 어려움
- 데이터가 잘못 들어와도 예측은 정상적으로 수행되기 때문
- 데이터를 사용하기 전에 미리 데이터가 정상적인지 확인하는 과정이 필요
- TFDV에는 기술 통계 보기, 스키마 추론, 이상 항목 확인 및 수정, 데이터 세트의 드리프트 및 왜곡 확인이 포함됨
TFDV?
- TensorFlow Data Validation
- 데이터를 더 쉽게 이해하고 점검할 수 있도록 도와주는 라이브러리
- Train, Test Data의 요약 통계, 분포를 쉽게 비교 가능
- 필수 값, 데이터에 대한 기대치를 의미하는 데이터 스키마 생성
- 내부적으로 Facet, Apache Beam 사용
기능
- Statistics 생성 및 시각화
- 스키마 추론
- 데이터 검증
- Drift와 Skew 체크
TFDV 실습
- Library 설치
pip install tensorflow-data-validation
pip install apache-beam-
설치 확인

-
데이터 준비 (시카고 택시 데이터)
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}Statistics 생성 및 시각화
-
Statistics 생성
- TFDV는 존재하는 특징과 그 가치 분포의 형태에 대한 데이터를 간략히 설명하는 통계를 계산할 수 있음
- 내부적으로 TFDV는 Apache Beam's 데이터 전송 처리 프레임워크를 사용하여 대규모 데이터 세트에 대한 통계 계산을 확장함
- TFDV와 더 깊이 통합하려는 애플리케이션의 경우(예: 데이터 생성 파이프라인 끝에 통계 생성을 첨부) API는 통계 생성을 위한 Beam PT 변환도 제공함
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
-
Facets를 사용하여 데이터의 간결한 시각화
-
tfdv.visualize_statistics(train_stats) -
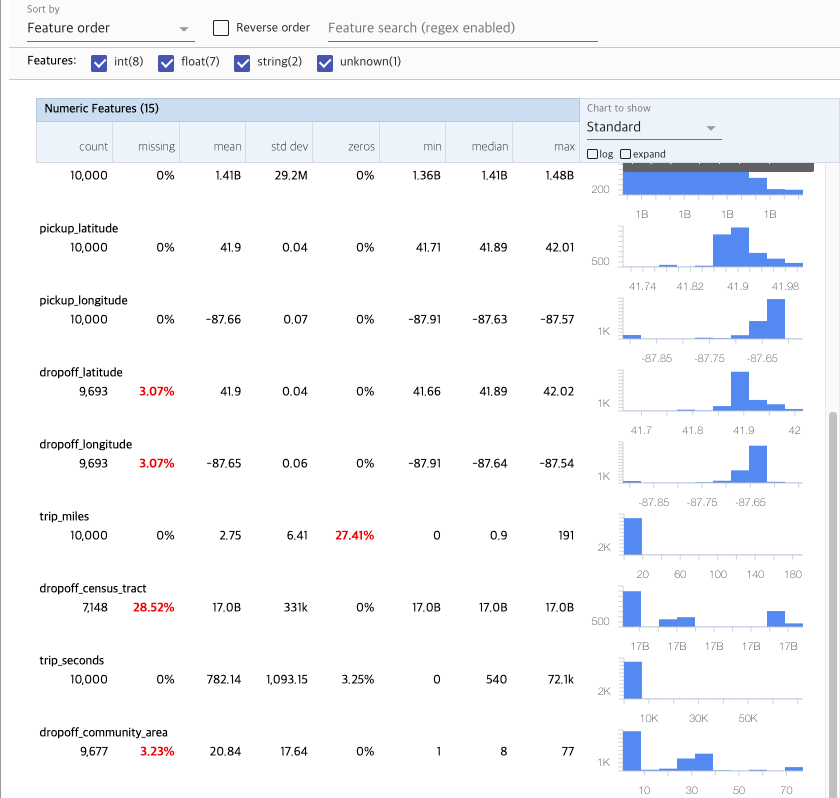
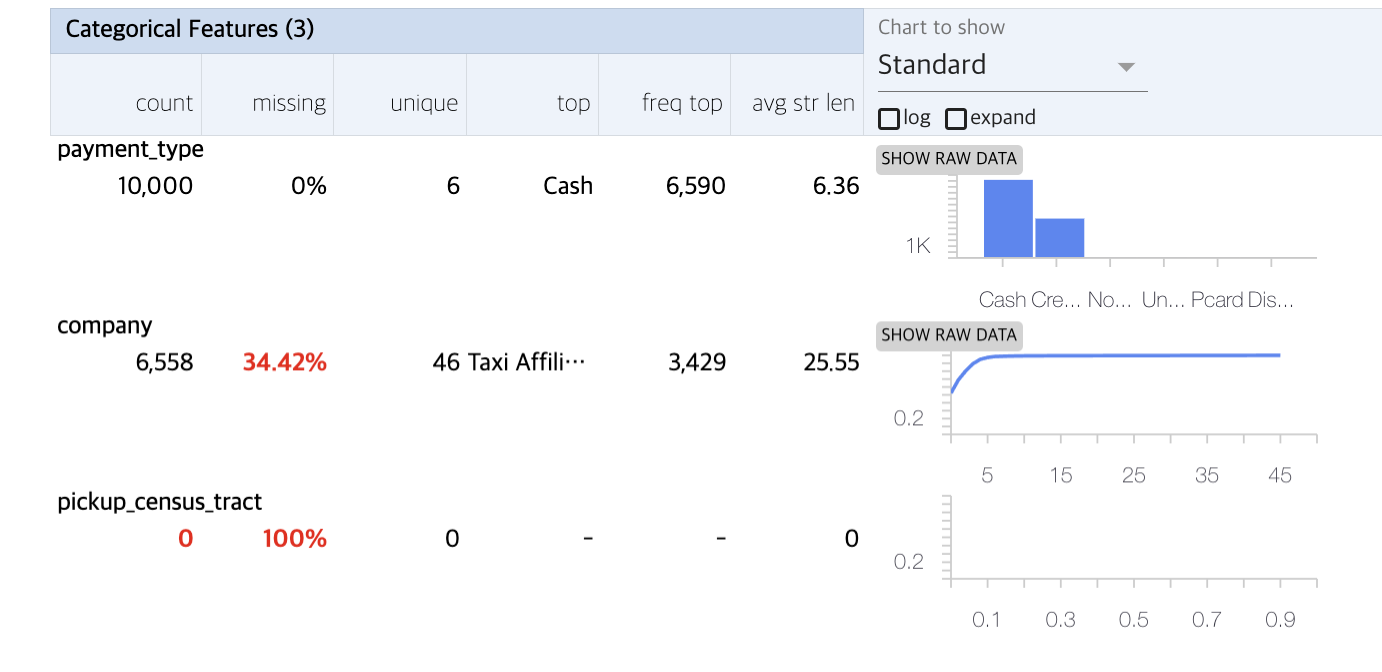
숫자 형상과 범주는 별도로 시각화되며 각 형상에 대한 분포를 보여주는 차트가 표시됨
-
결측값 또는 영(0) 값을 가진 형상은 해당 형상의 예에 문제가 있을 수 있다는 시각적 지표로 백분율을 빨간색으로 표시함. 백분율은 해당 기능에 대한 결측값이 있거나 값이 0인 예제의 백분율
-
pickup_census_tract 값이 있는 예는 없음 --> 제거 필요
-
차트 위에 있는 "expand" 버튼을 클릭하면 분포를 크게 볼 수 있음
-
"log" 버튼을 클릭하면 로그 스케일 처리를 한 데이터 분포를 볼 수 있음
-
"Chart to show"(차트 표시) 메뉴에서 "quantiles"(정량화)를 선택하고 마커 위로 마우스를 가져가면 정량화 백분율이 표시됨
-
원본
-
로그 스케일링

-
Quantiles 버튼 클릭

-
스키마 추론
- 스키마는 ML과 관련된 데이터에 대한 제약 조건을 정의함
- 예제 제약 조건에는 각 기능의 데이터 유형(숫자인지 범주형인지 또는 데이터에 존재하는 빈도)이 포함됨
- 범주형 기능의 경우 스키마는 도메인 허용 가능한 값 목록도 정의함
tfdv.infer_schema로 스키마를 추론한 후,tfdv.display_shcema로 출력
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)-
Schema

-
도메인에 대한 허용하능한 목록

평가 데이터 오류 확인
- 평가 데이터가 동일한 스키마를 사용하는 것을 포함하여 학습 데이터와 일관성이 있어야함
- 평가 데이터가 훈련 데이터와 거의 동일한 범위의 값 예제를 포함하는 것도 중요함
- 학습 데이터, 평가 데이터 상의 분포가 이상하지 않은지 눈으로 확인 가능
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
평가 이상 여부 확인
- 평가 데이터 세트가 훈련 데이터 세트의 스키마와 일치하는지 확인
- 허용 가능한 값의 범위를 식별하려는 범주형 기능에 특히 중요함
tfdv.validate_statistics

스키마의 평가 이상을 수정
- 평가 데이터에 학습 데이터에 없는 새로운 데이터가 존재하는 경우를 파악 가능
- 예제
- 훈련 데이터에 없던 평가 자료에는 "company"라는 새로운 가치관이 들어 있음.
- "payment_type"에 대한 새로운 가치도 가지고 있음
- 이러한 현상은 이상 징후로 간주되어야 하지만, 이러한 이상 징후의 데이터에 대한 도메인 지식에 따라 다름
- 문제가 실제로 데이터 오류를 나타내는 경우 기본 데이터를 수정하거나 스키마를 업데이트하여 평가 데이터 세트에 값을 포함시킬 수 있음
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
스키마 환경
- 기본적으로 파이프라인의 모든 데이터 집합은 동일한 스키마를 사용해야 하지만 예외가 종종 있음
- 지도 학습에서 데이터 세트에 레이블을 포함해야 하지만 추론을 위해 모델을 지원할 때는 레이블이 포함되지 않음
- 경우에 따라 스키마 변형이 필요함
예시
- 학습용 레이블에 'tips'가 있지만 서비스 데이터에 없음
- 초기에는 'FLOAT' 타입을 기대했지만, 'INT' 자료형을 갖고 있음
- TFDV는 이러한 차이를 인식함으로써 학습 및 서비스를 위해 데이터가 생성되는 방식의 불일치를 발견하는데 도움이됨
- 모델 성능이 저하될 때까지 이러한 문제를 인지하기 어렵고, 때로는 치명적인 결과를 초래할 수도 있음
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
- INT 값을 FLOAT로 변환
- 'tips' 피처가 예외(Column dropped)로 표시됨.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
데이터 드리프트 및 스큐
데이터 드리프트
- 모델을 배포하고 난 후, 성능이 점점 낮아짐
- ex. 들어오는 input 값의 분포가 바뀌는 경우
(원래 서비스 데이터에 남자 비율이 90%였는데 40%로 바뀌는 경우)
- ex. 들어오는 input 값의 분포가 바뀌는 경우
- 드리프트 감지는 범주형 특성 및 데이터의 연속범위에 대해 지원
- L-Infinity Distance로 드리프트를 표현하고, 드리프트가 허용 가능한 것보다 높을 때 경고를 받을 수 있도록 임계 거리를 설정할 수 있음
- 올바른 범위를 설정하는 것은 일반적으로 도메인 지식과 insight가 필요함
스키마 스큐
- 학습 및 서빙 데이터가 동일한 스키마를 따르지 않을 때 발생함
- integer 타입이 들어와야되는데 float 타입이 들어오는 경우
- 학습 데이터와 서빙 데이터는 모두 동일한 스키마를 준수해야함
- 둘 사이의 예상 편차(ex. 학습데이터에만 존재하지만 제공에는 없는 라벨) 스키마의 환경 필드를 통해 지정해야됨
특성 스큐
- 모델이 학습하는 특성 값이 서빙 시에 표시되는 특성값과 다를 때 발생
- 일부 특성 값이 학습 및 서빙 중간에 수정되는 경우
- 학습과 서빙 시에 특성을 전처리하는 로직이 다른 경우
- 학습 or 서빙 중 하나에만 일부 전처리를 적용하는 경우
분포 스큐
- 학습 데이터 세트의 분포가 서빙 데이터 세트의 분포와 다를 때 발생
- 주요 원인
- 다른 코드 또는 다른 데이터 소스를 사용하여 학습 데이터 세트를 생성하는 것
- 학습할 제공 데이터의 대표적이지 않은 하위 샘플을 선택하는 잘못된 샘플링 매커니즘
실습
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
- 스키마 고정
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
참고

Data Scientist, Data Analyst