출처
- Charu C. Aggarwal (2021) 추천시스템 : 기초부터 실무까지 머신러닝 추천 시스템 교과서. 에이콘 출판사 25-57p
- Charu C. Aggarwal (2016). Recommendation System. Springer International Publishing 23-50
1.1 Introduction
- 웹의 중요성 증가 → 추천 시스템 기술 개발
- 평가 제도 (ex. 5개 별 평가 시스템)
추천 시스템의 기본 아이디어
다양한 데이터 소스를 활용하여 고객의 관심사를 추론하는 것
추천 분석: user와 item간의 과거 상호 작용을 기반으로 함
* 추천받는 주체: user
* 추천하는 상품: item- 과거의 관심과 성향이 미래 선택에 대한 좋은 지표이기 때문!
- 예외: 지식 기반 추천 시스템
- 사용자가 지정한 요구 사항을 기반으로 추천 (과거 이력 X).
추천 시스템의 기본 원리
- 사용자와 항목 중심 활동 간에 상당한 종속성이 존재
- ex. 역사 다큐멘터리 좋아하는 user → 다른 역사 or 교육 프로그램에 관심 가질 가능성 높음
- 종속성
- 카테고리가 아닌 개별 항복의 세부 단위로 존재할 수 있음
- 평가 매트릭스에서 데이터 기반으로 학습 가능
- 결과 모델은 target user의 예측에 사용됨
- 사용자가 사용할 수 있는 평가 항목이 많을 수록 사용자의 미래 행동에 대한 예측을 더 잘할 수 있음
모델 예시
- 이웃 모델 (Neighborhood models)
- 유사한 사용자 집단의 관심과 행동으로부터 집단의 개별 구성원에게 추천에 활용
- 협업 필터링 (Collaborative Filtering)의 일부
- 협업 방식으로 여러 사용자의 평가를 사용하여 누락된 평가를 예측
프레임워크
- 콘텐츠 기반 추천 시스템 (Content Based Recsys)
- 콘텐츠는 사용자의 등급과 항목의 속성 설명을 활용하여 예측
- 사용자의 관심이 과거에 평가했거나 접근한 속성을 기반으로 모델링 될 수 있음
- 지식 기반 시스템 (Knowledge Based System)
- 사용자가 대화식으로 관심 분야를 지정
- 사용자 명시 사항과 도메인 지식이 결합되어 추천
1.2 Goals of Recommender Systems
Two Primary Models
- Prediction version of problem
- 특정 항목에 대한 사용자의 평점을 예측
- 항목에 대한 사용자의 선호도를 나타내는 훈련데이터가 이용가능하다고 가정
- m x n (m: users, n: items) 행렬
- Matrix Completion Problem이라고 불림
- 불완전한 행렬 값이 존재하고 나머지는 학습 알고리즘으로 예측을 하기 때문
- Ranking version of problem
- 사용자에게 상위 K개 항목을 추천 (일반적) or
특정 항목을 대상으로 상위 K개 사용자를 결정
- 사용자에게 상위 K개 항목을 추천 (일반적) or
Objective
- 추천 시스템의 사용 목적
- 제품 판매량 증가
- 판매자 수익 증대
- 수익 증대가 눈에 확 안띄는 경우가 종종 있음
일반적인 운영 및 기술 목표
- 관련성 (Relevance)
- 현재 사용자와 관련한 항목을 추천하는 것
- 사용자는 흥미를 느끼는 항목을 소비할 가능성이 더 크다
- 참신함 (Novelty)
- 사용자가 과거에 본 적이 없는 것일 때 도움이 많이 됨
- 인기 상품을 반복적으로 추천하는 것도 판매 다양성의 감소로 이어질 수 있음
- 뜻밖의 발견, 우연으로 얻은 행운 (Serendipity)
- 사용자가 진정으로 놀라운 권장 사항을 제공한다는 점에서 Novelty와 다름
- 다른 유형의 품목에 대한 잠재적 관심으로부터 사용자가 놀랄 수 있음
- ex.
- 인도 음식을 먹는 사용자에게 새로운 인도 음식점을 추천 → Novelty
- 인도 음식을 먹는 사용자에게 에티오피아 음식을 추천하고
그러한 결과가 어필이 될 경우 → Serendipity
- 종종 관련이 없는 항목을 추천하는 부작용(side effect)이 있음
- Serendipity를 늘리면 완전히 새로운 관심 영역을 발견할 수 있어서
장기적이고 전략적인 이점이 있는 경우가 더 많음
- Serendipity를 늘리면 완전히 새로운 관심 영역을 발견할 수 있어서
- 추천 다양성의 증가 (Increasing recommendation diversity)
- 추천 목록에 다른 유형의 항목이 포함되면 유저가 항목 중 하나 이상 좋아할 가능성이 커짐
- 다양성은 사용자가 유사한 아이템을 반복적으로 추천해도 질리지 않는 장점이 있음
Recsys 소프트 목표
- 사용자의 관점에서 웹사이트에 대한 전반적인 사용자 만족도를 높일 수 있음
- 사용자 충성도 증가 → 매출 증가
- 판매자의 관점에서 사용자의 요구에 대한 통찰력 제공 및 사용자 경험을 customize 가능
- 특정 항목이 추천되는 이유에 대한 설명이 유용할 것
예시
GroupLens
- Usenet뉴스 추천을 위해 구축된 선구적인 추천 시스템
- 독자들로부터 평가를 수집, 다른 독자가 기사를 읽기 전에 기사를 좋아할지 여부를 예측
- 협업 필터링 연구에 대한 선구적인 공헌 외에도 여러 데이터 세트를 발표한 것으로 유명
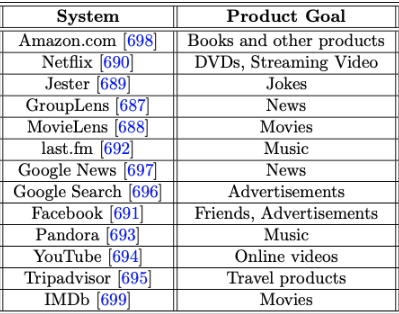
Amazon
- 상업 환경에서 선구적인 추천 시스템
- 아마존의 추천은 명시적으로 제공된 평가, 구매 행동, 검색 행동을 기반으로 제공됨
- 평가는 5점 척도
- 추천되는 이유에 대한 설명이 제공됨
Netflix
- 5점 척도로 영화 및 TV 프로그램을 평가할 수 있는 기능을 제공
- 다양한 항목을 시청하는 사용자 행동은 저장됨
- 사용자가 시청한 항목을 기반으로 추천함
- 사용자에게 특정 영화를 볼 것인지 여부를 결정할 수 있는 추가 정보를 제공
- 추천 항목에 대한 설명을 제공
- 사용자가 특정한 영화를 관심있어하는 이유를 이해하는데 중요함
- 사용자의 경험을 개선함 → 충성도와 유지율을 높이는데 도움이 될 수 있음
- 클릭 이력을 기반으로 사용자에게 뉴스를 추천할 수 있음
- 뉴스 기사는 항목으로 취급됨
- 사용자가 뉴스를 클릭하는 행위 → 해당 기사에 대한 긍정적인 평가로 볼 수 있음
- 단항 평가 (Unary rating): 싫어함을 표시할 수 없음
- 평가는 사용자의 작업에서 추론하기 때문에 암시적임
- SNS는 연결 수를 늘리기 위해 사용자에게 잠재적인 친구를 추천하는 경우가 많음
- 소셜 인맥 증가 → 소셜 네트워크에서 사용자의 경험을 향상시킴 → 소셜 네트워크 성장
⇒ Link prediction이라고도 불림 - 이러한 추천은 평가 데이터가 아닌, 구조적 관계를 기반으로 함
The Spectrum of Recommendation Applications
1.3 Basic Models of Recommender Systems
- 협업 필터링 (Collaborative filtering)
- 유저-항목 상호작용 데이터 (평가, 구매 행동)
- 콘텐츠 기반 추천 (Content-based recsys)
- 유저와 항목의 속성 정보 (텍스트 프로필, 관련 키워드)
- 일반적으로 단일 사용자 평가에 초점
- 대부분 케이스에 대한 평가 행렬도 사용함
- 지식 기반 추천 (Knowledge-based recsys)
- 사용자의 요구 사항을 기반으로 함
- 하이브리드 시스템 (hybrid system)
- 다양한 유형의 추천 시스템의 장점을 결합
- 다양한 설정에서 강건하게 수행할 수 있는 기술을 만들 수 있음
Collaborative Filtering Methods (CF)
- 여러 사용자가 제공하는 평가의 협업 능력을 사용하여 추천함
- 너와 비슷한 나, 내가 좋아하는 이건 어때?
- 기본 평가 행렬이 희소하다는 문제가 있음
- 대부분 사용자는 일부 영화만 보았을 것임
- Observed ratings
- Basic Idea
- 관찰된 평가가 다양한 사용자와 항목에 높은 상관 관계가 있는 경우가 많기 때문에,
관찰되지 않은 평가를 비슷한 평가로 대체할 수 있다.
→ 비슷한 사용자의 값으로 결측치를 추론
- 관찰된 평가가 다양한 사용자와 항목에 높은 상관 관계가 있는 경우가 많기 때문에,
Methods
- 메모리 기반 방법 (Memory based methods)
- 이웃 기반 협업 필터링 알고리즘(neighborhood based CF)이라고도 불림
- 사용자 항목 조합의 평가가 이웃을 기반으로 예측됨
- 이웃의 정의
- User-based CF
- 사용자와 같은 생각을 가진 사용자가 제공한 평가를 사용하여 추천함
- 유사한 사용자를 결정 & 동료 그룹의 평가에 대한 가중 평균을 계산
→ 관찰되지 않은 항목에 대한 평가를 추천 - 유사한 사용자를 찾기 위해 평가 매트릭스의 row간에 유사성 함수가 계산됨
- Item-based CF
- Target 항목과 가장 유사한 항목 집합을 결정하는 것
- 해당 집합의 평점은 사용자가 항목을 좋아할 것인지 예측하는데 사용됨
- 유사한 사용자를 찾기 위해 평가 매트릭스의 column 간에 유사성 함수가 계산됨
- User-based CF
- 장점
- 구현이 간단함
- 추천 결과를 설명하기 쉬움
- 단점
- 희소 평가 행렬에서 잘 작동하지 않음
- 모델 기반 방법 (Model based methods)
- ML, Data Mining은 예측 모델의 맥락에서 사용됨
- Ex. 결정트리, Rule-based Model, 베이지안 방법, 잠재요인 모델 등
Types of Ratings
- 추천시스템의 설계는 평가를 추척하는 시스템에 영향을 받음
- 평가는 연속적(continuous)인 값과 간격 기반(interval-based) 값 모두 가능
- 일반적으로는 interval based를 사용 (ex. 5점 척도: 1~5)
- 불균형 평가 척도 (unbalanced rating scale)
-
3개의 긍정적인 평가와 2개의 부정적인 평가가 존재
-
중립 평가가 누락됨

-
- Ordinal Ratings (서수 평가)
-
범주 값을 정렬
-
ex. Strongly Disagree, Disagree, Neutral, Agree, Strongly Agree

-
- Binary Ratings (이진 평가)
- Like / Dislike or 0 / 1
- Unary Ratings (단항 평가)
- 항목에 대해 호감도를 지정하는 메커니즘만 존재 (비호감도는 없음)
- ex. Facebook에 좋아요 버튼만 있는 경우
- 암시적인 피드백 데이터 세트에 주로 쓰임
- ex. 고객이 상품을 사는 행동 → 상품에 대한 선호도
- 항목에 대해 호감도를 지정하는 메커니즘만 존재 (비호감도는 없음)
명시적(Explicit), 암시적(Implicit) 평가 예시
- 명시적 평가
-
숫자가 클수록 긍정적인 의견
-
효용 행렬이라고도 함 (utility matrix)
-
효용이 이익의 양일 경우 →
사용자-항목 조합의 효용 = 항목을 특정 사용자에게 추천함으로써 발생하는 이익의 양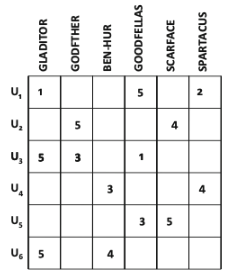
-
- 암시적 평가
-
긍적적인 선호도의 표시만 허용
-
긍정 선호도 효용 행렬이라고 함 (positive preference utility matrix)
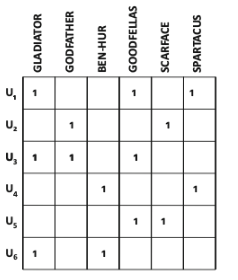
-
- 참고
- 결측치 저리
- 암시적 평가(단항 평가)
- 초기 단계에 누락된 값을 0으로 처리
- 데이터의 기본 가정이 사용자가 대부분 구매하지 않을 것이라고 생각 → 편향이 작음
- 결측값을 처리하는 것이 과적합을 방지할 수 있어서 단항 평가에서는 사용하기도 함
- 데이터의 기본 가정이 사용자가 대부분 구매하지 않을 것이라고 생각 → 편향이 작음
- 1로 할 경우 과적합이 발생할 수 있음
- 초기 단계에 누락된 값을 0으로 처리
- 명시적 평가
- 누락된 값을 대체하는 것은 권장되지 않음
- 분석에 상당한 편향이 발생할 수 있기 때문
- 암시적 평가(단항 평가)
- 평가 점수
- 명시적 행렬: 선호도(preferences)에 해당
- 암시적 행렬: 신뢰도(confidences)에 해당
- 결측치 저리
협업필터링은 분류, 회귀 모델의 일반화
- 분류/회귀 모델
- 종속 변수: 결측값이 있는 속성
- 독립 변수: 값 이 존재
- 협업 프레임은 이러한 프레임워크의 일반화로 볼 수 있음
-
class 변수가 아닌 모든 열에 결측값이 허용됨
-
각 특성이 독립 변수와 종속 변수의 이중 역할을 수행하기에 구분이 존재하지 않음
-
예측이 row-wise 방식이 아닌 entry-wise 방식으로 수행됨
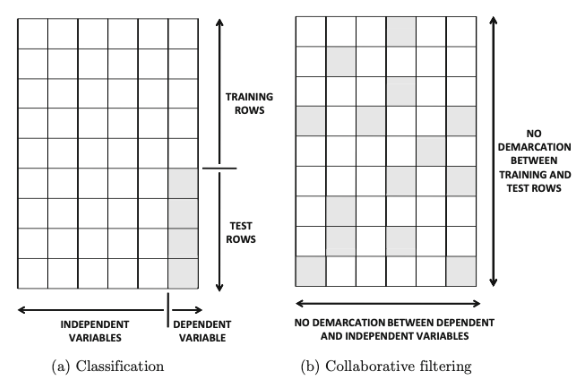
-
- 행렬 완성 문제
- 분류, 회귀의 transductive setting과 많은 특성을 공유함
- test instances는 training process에 포함됨
- training 때, 사용할 수 없는 test 인스턴스에 대한 예측은 어려움
- 귀납적 모델
- 새로운 instance에 대해 쉽게 예측할 수 있는 모델
- ex. Naive Bayes (모델 구축 시, 특성들이 알려져 있지 않기 때문)
- 행렬 완성에 대한 setting은 본질적으로 transductive함
- 분류, 회귀의 transductive setting과 많은 특성을 공유함
Content-Based Recommender Systems
- 설명 속성은 추천하는데 사용됨
- 사용자의 평가 및 구매 행동이 항목에서 제공되는 콘텐츠 정보와 결합
- ex. 유사한 장르 영화 추천
- Documents
- training: 구매 or 평가한 항목들
- class varialbe: 평가 or 구매 행동
장단점
- 장점
- 항목에 대한 충분한 평가 데이터를 사용할 수 없는 경우에도 추천 가능
- 유사한 속성을 가진 다른 항목이 평가되었을 수 있기 때문
- = 신규 아이템 추천에 효과적
- 항목에 대한 충분한 평가 데이터를 사용할 수 없는 경우에도 추천 가능
- 단점
- 명백한 추천을 함
- 키워드나 콘텐츠를 사용하기 때문
- 만약 사용자가 한번도 해당 키워드 집합으로 소비한 적이 없다면 추천되지 않음
- 추천 아이템의 다양성을 감소시키는 경향이 있음
- 신규 유저에 대한 추천에는 비효과적임
- 신규 유저는 평가 기록이 없기 때문 (학습에 사용할 데이터가 없음)
- 명백한 추천을 함
- 해결
- 사용자가 프로필에 키워드를 표시 → 추천 가능
- 평가를 사용하지 않기에 초기 시나리오에서 유용함
- 지식 기반 시스템으로 보여질 수 있음
- 사용자가 프로필에 키워드를 표시 → 추천 가능
Knowledge Based Recommender Systems
- 자주 구매하지 않는 품목과 관련하여 특히 유용함
- ex. 부동산, 자동차, 사치품 등
- 구매가 적기 때문에, 충분한 평가 자료가 없음 → cold start problem
- 시스템이 아직 충분한 정보를 수집하지 않은 사용자 또는 항목에 대한 추론을 할 수 없음
- Retrieval process 동안 규칙과 유사성 기능을 포함한 지식 기반 데이터를 사용
- 사용자가 원하는 것을 명시적으로 지정할 수 있음

Type
- Constraint-based recsys
-
사용자는 항목 속성에 대한 요구사홍 또는 제약을 지정 (ex. 상한/하한)
-
사용자 속성을 항목 속성에 관련 짓는 규칙을 종종 생성함 (ex. 고령투자자는 초고위험 제품에 투자안함)
-
검색 프로세스에서 사용자 속성을 지정할 수도 있음
(사용자가 원하는 결과에 도달할 때까지 대화식으로 반복됨 -
규칙은 검색을 안내하는데 사용됨

-
- Case-based recsys
-
특정 사례는 사용자를 대상 or 기준점으로 지정함
-
유사성 행렬은 도메인별 구체적인 방식으로 신중히 정의됨
-
반환된 결과는 사용자와 상호작용을 통한 수정을 거쳐 새로운 타켓 케이스로 사용됨
-
규칙은 유사성 행렬과 함께 검색을 안내하는 기준점으로 사용됨
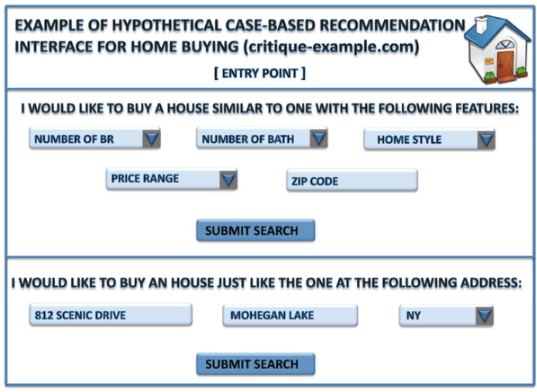
-
Interactivity
- Conversational systems
- 사용자 선호도는 피드백 루프의 맥락에서 결정됨
- 항목 도메인이 복잡하고 유저의 선호도는 대화 시스템에서만 얻을 수 있어서
- Search-based systems
- 미리 설정된 질문 시퀀스를 사용 (ex. 도시 지역을 선호하나요?)
- Navigation-based recommendation
- 현재 추천중인 항목에 대한 변경 요청 수를 지정함
- critiquing recommender systems로 불림
Utility-Based Recsys
- 적적한 효용 함수를 정의하는 것이 어려움
- 사전에 알려진 기능을 기반으로 효용 값을 산출
Demographic Recsys
- 인구통계학 정보는 특정 인구 통계를 평가 or 구매 성향에 매핑하는 classifer를 학습하는데 활용됨
- 독립적인 실행 기반에서 최상의 결과를 제공하지는 않음
- Hybrid, ensemble based 추천 시스템의 성능을 크게 향상 시킴
- 인구 통계 기술은 때때로 지식 기반 시스템과 결합하여 견고성을 높임
Hybrid & Ensemble Based Recsys
- 이전 3가지 방법
- 협업 필터링: 커뮤니티 등급에 의존 (사용 데이터가 많을 떄 효과적)
- 콘텐츠 기반: 텍스트 설명과 taget 사용자의 평가에 의존
- 지식 기반: 사용자와 지식 기반 맥락에서의 상호작용에 의존 (많은 양의 데이터를 사용할 수 없는 초기에 유용)
- 인구 통계 시스템: 사용자의 인구 통계 프로필 사용
- 앙상블 분석 분야와 밀접한 관련이 있음
- 여러 데이터 소스의 힘을 결합 가능
- 동일한 유형의 여러 모델을 결합하여 추천시스템 효율성을 향상
Evaluation of Recsys
- 추천 문제는 분류 문제의 일반화
- 누락된 값은 나머지 값으로부터 데이터 기반 방식으로 예측해야함
- Prediction → 분류 및 회귀 모델링과 밀접한 관련이 있음
- Ranking → 검색 및 정보 검색 응용프로그램의 검색 효율성 평가와 연관이 되어 있음
1.4 Domain-Specific Challenges in Recommender Systems
Context-Based Recsys
- 다양한 유형의 문맥 정보를 고려함
- 시간, 위치, 소셜 데이터가 포함될 수 있음
- 기본 아이디어가 다양한 도메인별 설정과 관련이 있기 때문에 관련이 있기 때문에 강력함
Time-Sensitive Recsys
- 추천은 시간이 지나면서 발전할 수 있음
- 협업 필터링 시스템에서 명시적 매개편수로 시간을 통합하여 생성됨
- 항목의 평가는 특정 시간, 월, 계절에 따라 달라질 수 있음
- 컨텐스트 기반 추천 시스템의 특수한 경우
Location-Based Recsys
- ex. 여행 중인 사용자는 다른 식당에 대한 이전 평가 기록을 기반으로 가장 가까운 식당을 결정할 수도 있음
- 장소 추천에는 항상 위치 정보가 부착됨
- Foursquare
- User-spcecific locality
- 사용자의 지리적 위치
- Item-specific locality
- 항목(ex. 식당)의 위치는 사용자의 현재 위치에 따라 항목의 관련성에 영향을 이침
- User-spcecific locality
Social Recsys
- 네트워크 구조, 소셜 cue, 태그 등과 같이 네트워크 측면의 조합을 기반으로 추천함
- 노드와 링크의 구조적 추천
- 소셜 네트워크를 비롯한 다양한 유형의 네트워크는 노드와 링크로 구성
- 노드와 링크를 추천하는 것이 바람직함
- 사회적 영향력이 있는 제품과 콘텐츠 추천
- 바이럴 마케팅: 입소문 시스템을 사용하여 제품을 추천함
- 네트워크에서 주제와 관련된 영향력 있는 엔터티를 결정하는 것이 중요함
→ 소셜 네트워크에서의 영향력 분석
- 신뢰할 수 있는 추천시스템
- 많은 소셜 미디어 사이트에서는 사용자가 직접 또는 다양한 피드백 메커니즘을 통해 신뢰/불신을 표현할 수 있음
- ex. 이 추천이 나에게 도움이 되었습니까? 와 같은 피드백으로 보여짐
- 이러한 신뢰 정보는 추천을 보다 강건하게 해줌
- 많은 소셜 미디어 사이트에서는 사용자가 직접 또는 다양한 피드백 메커니즘을 통해 신뢰/불신을 표현할 수 있음
- 추천을 위한 소셜 태깅 피드백
- 태그: 짧은 정보 키워드를 추가하는데 사용하는 메타 데이터
- 태그는 사용자의 관심사와 항목 콘텐츠 모두에 대해 유용한 정보를 제공함
1.5 Advanced Topics and Applications
The Cold-Start Problem in Recommender Systems
- 추천시스템의 주요 문제: 초기에 사용할 수 있는 평가 수가 상대적으로 적은 것
- 콘텐츠 기반, 지식 기반 방법은 cold-start에 강건함
- 참고
- Cold start: 추천 시스템이 새로운 or 어떤 유저들에 대한 충분한 정보가 수집된 상태가 아니라서 해당 유저들에게 적절한 제품을 추천해주지 못하는 문제
Attack-Resistant Recommender Systems
- 추천 시스템의 사용은 제품과 서비스 판매에 큰 영향을 끼침
→ 판매자는 추천시스템 결과를 조작하여 이익을 챙길 수 있음
- ex. 평가 부풀리기, 경쟁사 제품에 부정적인 리뷰 쓰기
Group Recommender Systems
- 사용자 그룹에게 특정 활동을 추천하도록 맞춤화함
- ex. 피트니스 센터에서 음악 선택, 관광객 그룹에 대한 여행 추천 등
- 초기 시스템은 그룹 추천을 하기 위해 개별 사용자의 선호도를 집계해서 사용했음
- 이후 다양한 사용자 간의 상호작용을 고려한 추천을 설계함
Multi-Criteria Recommender Systems
- 단일 사용자가 다른 기준에 근거하여 평가를 지정할 수 있음
- ex. 줄거리, 음악, 특수 효과를 기준으로 영화 평가
- 전체 평가만 사용하면 잘못된 결과를 얻을 수 있음
- ex. 전체 평가는 같아도 사용자별 세부 평가는 다를 수 있음 → 유사하지 않음
Active Learning in Recommender Systems
- 충분한 평가 데이터가 예측 성능을 높임
- 사용자에게 특정 항목을 평가하도록 인센티브를 제공할 수 있음
- 효율적인 평가 데이터 수집을 위해, 사용자의 평가가 적은 장르의 데이터를 제공받아야함
Privacy in Recommender Systems
- 데이터의 가용성은 추천 시스템의 발전에 매우 중요함
Application Domains
- 추천 시스템의 중요한 관점은 장기적인 사용자의 관심을 확인 및 추적하기 위해
강력한 사용자 식별 메커니즘이 존재한다고 가정함
- 많은 웹 도메인에서 강력한 사용자 식별을 위한 메커니즘을 사용하지 못할 수 있음
→ 추천 기술의 직접적인 활용이 불가능함
1.6 Summary
- 다양한 도메인 별 시나리오와 다양한 유형의 입력 정보의 맥락으로 공부할 것
- 추천 시스템의 문제는 풍부하며, 원천 input data와 시나리오에 따라 다양하게 발생 가능함
- 다른 알고리즘들의 상대적인 효과는 특정 문제의 setting에 따라 달라짐
- 이러한 trade-off는 책에서 다뤄질 것
Reference
- Recommender Systems: The Textbook, Charu Aggarwal, 2016

Data Scientist, Data Analyst