오렐리앙 제롱, 『Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow』, 박해선, 한빛미디어-OREILLY(2020), p229-244.
Learned
결정 트리 (Decision Tree)
- 분류, 회귀, 다중 출력 작업 가능
- 한 샘플이 특정 클래스 에 속할 확률을 추정할 수 있음
- 훈련된 트리 시각화 가능 (w.
export_graphviz())from graphviz import Source from sklearn.tree import export_graphviz export_graphviz( tree_clf, out_file=os.path.join(IMAGES_PATH, "iris_tree.dot"), feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True ) Source.from_file(os.path.join(IMAGES_PATH, "iris_tree.dot"))
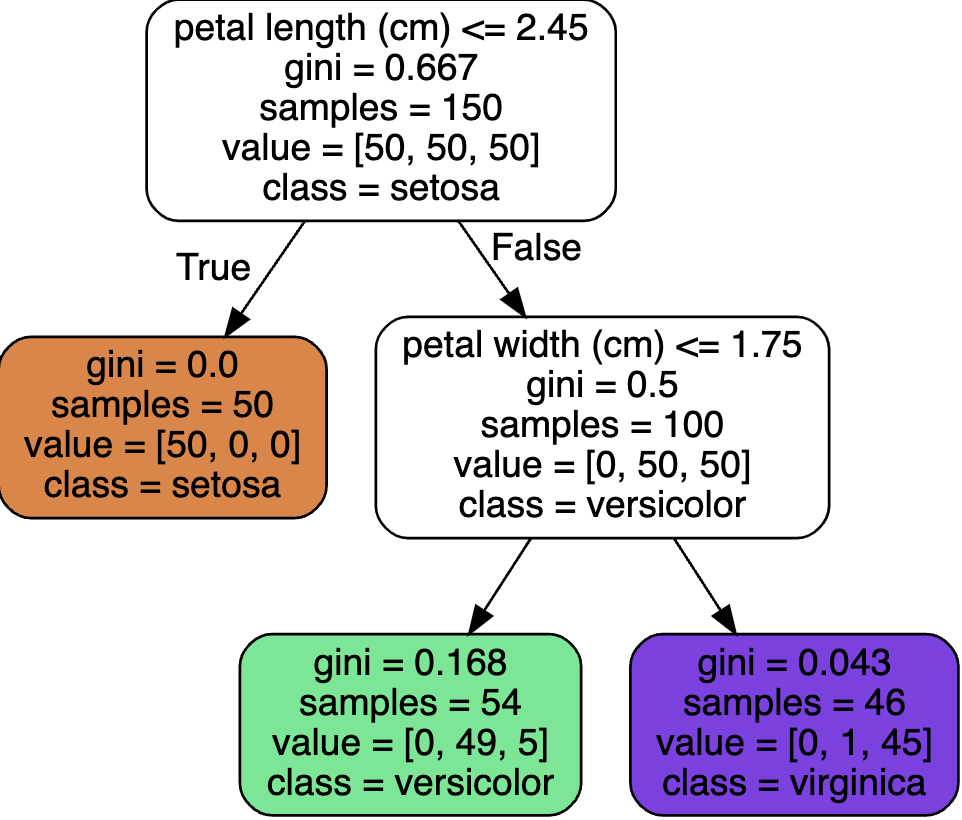
- 노드 종류
- 루트 노드 (root node): 최상단 노드
- 자식 노드 (child node): 파생된 노드 (자식 노드 or 리프 노드를 가질 수 있음)
- 리프 노드 (leaf node): 자식 노드를 가지지 않는 노드
- 장점
- 데이터 전처리가 거의 필요없음
- 해석이 직관적임 (위의 그래프처럼 육안으로 확인 가능)
- 예측 속도가 빠름
- 단점
- 작은 변화에도 매우 민감함
- 계단 모양의 결정 경계를 만들어서 모든 분할이 축에 수직이기 때문
- 과대적합되기 쉬움 → 규제 필요
- 작은 변화에도 매우 민감함
- 계산 복잡도
- 탐색: → 특성의 개수와 무관함 → 큰 훈련 세트를 다룰 때도 예측 속도가 빠름
- 각 노드에서 모든 샘플의 모든 특성을 비교할 경우:
불순도 (Impurity)
- 지니 불순도
- 한 노드의 모든 샘플이 같은 클래스에 속해 있다면, 그 노드를 순수(gini=0)하다고 함
- 위 그림 “보라색” gini 점수:
- 엔트로피
- 열역학 개념, 분자의 무질서함을 측정하는 것
- 새넌의 정보 이론도 엔트로피에 포함됨 → 감소되는 엔트로피의 양 = 정보 이득 (information gain)
- 머신러닝의 불순도 측정 방법으로 자주 쓰임
- 지니 불순도 VS 엔트로피
- 실제로 큰 차이가 없음, 둘 다 비슷한 트리를 만듦
- 지니 불순도가 조금 더 계산이 빠름
- 지니 불순도가 가장 빈도가 높은 클래스를 한쪽 가지로 고립시키는 경향이 있음
엔트로피는 조금 더 균형 잡힌 트리를 만듦
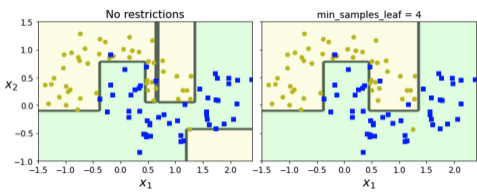
규제 (Regulation)
- 훈련 전에 parameter 수가 결정되지 않음 (비파라미터모델)
- 모델 구조가 자유로움
- 과대적합이 발생하기 쉬움
- 과대적합을 피하기 위해 결정 트리의 자유도를 제한해야됨
- Hyper-parameter 종류
- max_depth: 트리 깊이
- min_samples_split: 분할되기 위해 노드가 가져야 하는 최소 샘플 수
- min_samples_leaf: 리프 노드가 가지고 있어야 할 최소 샘플 수
- min_weight_fraction_leaf: 가중치가 부여된 전체 샘플 수에서의 비율
- max_leaf_nodes: 리프 노드의 최대 수
- max_features: 각 노드에서 분할에 사용할 특성의 최대 수
CART Alogrithm
-
Classification And Regression Tree
-
Classification Cost function
- 최대 깊이가 되거나 불순도를 줄이는 분할을 찾을 수 없을 때 종료
- 탐욕적 알고리즘(greedy algorithm)에 속함 → 최적의 솔루션을 보장하지 않음
- 최적의 트리를 찾는 것은 NP-Complete 문제로 알려짐
- 의 시간이 필요
- 작은 훈련 세트에 적용하기 어려움
-
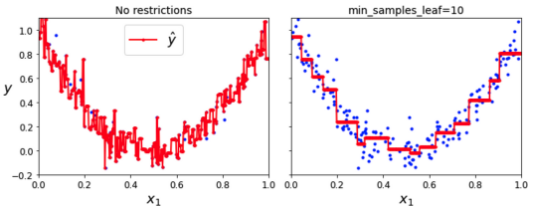
Regression Cost function
- MSE를 최소화하도록 분할함
화이트박스, 블랙박스
- 화이트박스 모델: 직관적이고 결정 방식을 이해하기 쉬운 모델 (ex. Decision Tree)
- 블랙박스 모델: 성능이 뛰어나고 연산 과정을 확인할 수 있으나, 예측의 원인을 파악하기 어려운 모델 (ex. 신경망)
Question
- 엔트로피와 지니 불순도의 차이는 무엇일까?
- 계산 방식에 차이가 있음
- 값의 범위에 차이가 있음 (지니: 0~0.5, 엔트로피: 0~1)
- 결과에는 차이가 거의 없음
- 엔트로피는 log 계산이 있어서 지니의 속도가 조금 더 빠름
-> gini가 scikit-learn에서 default인 이유
- 왜 엔트로피가 지니 불순도보다 균형 잡힌 트리를 만들까?
- 지니 불순도 방식이 불순도 값을 줄이기 위해 엔트로피보다 클래스 확률을 더 낮추어야 함 -> 엔트로피가 더 균형 잡힌 트리를 만들 가능성이 높음
- 쿨백 라이블러 발산이란?
- Kullback-Leibler divergence
- 두 확률분포의 모양이 얼마나 유사한지를 평가
- NP-Complete 문제?
- 아래 링크 참조
Reference
- 엔트로피
- 엔트로피 VS 지니
- 쿨백-라이블러 발산
- NP-Complete 문제
- 가지치기

Data Scientist, Data Analyst