Intel AI For Future WorkForce 7주차 회고록
미니 프로젝트 : 종이 헬리콥터 회귀문제
이번 7주차부터 매 주 정해진 각 주제를 가지고 이전에 학습했던 내용들을 복습할 겸, 미니 프로젝트를 진행한다.
첫 주차에 할당된 미니 프로젝트 주제는 종이 헬리콥터 회귀문제이다.
Goal of Project
- 최적의 변수 조합을 찾는다.
- 보다 정확한 체공 시간을 예측하는 모델을 완성한다.
Project Flow
프로젝트를 진행한 순서는 아래와 같다.
1. 데이터 수집(직접 헬리콥터를 만들고, 4개의 독립 변수와 1개의 종속 변수로 데이터를 구성)
2. 모델 학습, 예측
3. Shapley Value로 변수 공헌도 확인
결과
초 단위 체공시간(ex. 3초대, 2초대)은 비교적 잘 맞추는 편이었으나, 0.x초 단위에서 오차가 약간은 큰 편이었다.
Shapley Value로 모델 학습에 대한 변수 공헌도를 책정했을 때, 날개 길이 ➡️ 날개 폭 ➡️ 다리 길이 ➡️ 몸통 길이 순으로 공헌도가 낮아지는 것을 확인할 수 있었다.
상세 진행 과정
데이터 수집
직접 종이 헬리콥터를 만들고, 아래와 같이 데이터를 생성했다.
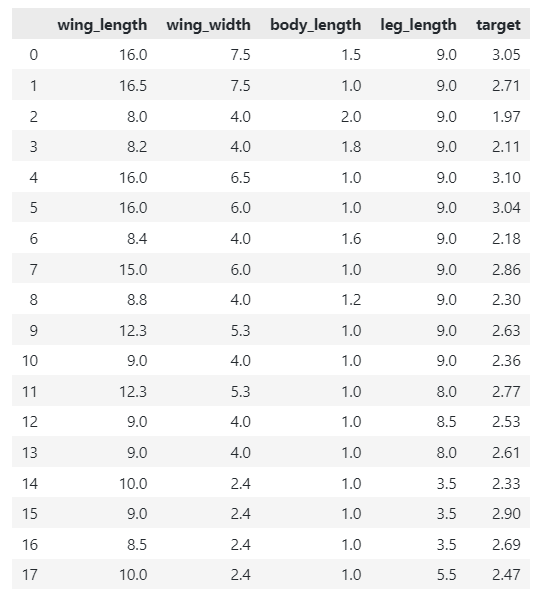
각 변수가 의미하는 것은 순서대로 날개 길이, 날개 폭, 몸통 길이, 다리 길이, 체공 시간을 의미하며 체공 시간의 경우 3번의 측정 후, 평균값을 구해 소수점 둘째 자리 미만의 숫자들은 버리고 사용했다.
모델 학습
모델의 경우 ANN과 Scikit-learn(SGDRegressor, SVR)을 사용하여 학습했다.
[ANN]
from keras.models import Model
from keras.layers import Dense, Input
from keras.optimizers import Adam
from keras.callbacks import ReduceLROnPlateau
input_layer = Input(shape = (4, ))
x = Dense(64, activation = "relu")(input_layer)
x = Dense(64, activation = 'relu')(x)
x = Dense(64, activation = 'relu')(x)
x = Dense(64, activation = 'relu')(x)
output_layer = Dense(1, activation = "sigmoid")(x)
optim = Adam(learning_rate = 0.001)
model = Model(input_layer, output_layer)
model.compile(optimizer = optim, loss = "mean_squared_error")
model.fit(X, y, epochs = 500, callbacks = [ReduceLROnPlateau(monitor = 'loss', mode = "min", factor = 0.3, patience = 5)])데이터의 경우 MinMaxScaler로 정규화를 진행하되, 몸통 길이가 1.0인 경우 0으로 변환되어 학습에 방해가 되는 상황을 방지하기 위해 feature_range를 0.1 ~ 1로 지정하여 정규화를 진행했다.
이후 입력층과 은닉층, 출력층을 정의하고 훈련을 진행했다.
이렇게 생성된 모델을 기반으로 최적의 변수 조합을 찾기위해 아래와 같이 실행했다.
best_flight_times = []
best_conditions = []
for _ in range(5000):
random_array = np.random.rand(4).reshape(1, -1)
predicted_time1 = model.predict(random_array)
X = train_X_scaler.inverse_transform(random_array)
y_pred = train_y_scaler.inverse_transform(predicted_time1)[0][0]
if y_pred >= 2.9:
best_flight_times.append(y_pred)
best_conditions.append(X)랜덤한 4개의 인수를 받아 (1, 4)의 형태로 reshape하고, 모델에 넣어 예측을 진행한 다음 입력값과 출력값을 inverse_transform으로 비정규화 후 체공 시간을 2.9초 이상으로 예측한 값들을 각 리스트에 담아 구해봤다.
print(max(best_flight_times))
print(best_conditions[np.argmax(best_flight_times)])체공 시간 리스트 중 가장 큰 값을 구하고, 그 값의 인덱스를 가지고 독립변수 조합을 참조하여 아래와 같은 결과를 얻었다.
3.1027317 # 예상 체공 시간
[[16.46627483 4.63141677 3.22032149 8.06453777]] # 예상 최적 변수조합모델이 반환한 결과값을 기반으로 헬리콥터를 만들어 체공 시간을 측정한 결과, 2.78초의 체공 시간을 얻을 수 있었다.
[Scikit learn (SGDRegressor, SVR)]
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import SGDRegressor
lin = SVR()
lin2 = SGDRegressor(random_state = 22)
params = {
'epsilon' : np.logspace(-2, 2, 5),
'C' : np.logspace(-3, 0, 4),
'max_iter' : list(range(0, 3001, 500)),
'kernel' : ['linear', 'poly', 'rbf', 'sigmoid']
}
lin_grid = GridSearchCV(lin, param_grid = params, n_jobs = -1, cv = 10)
lin_grid.fit(X, y)
params2 = {
"alpha" : [0.001, 0.0001, 0.005, 0.0005, 0.01],
'epsilon' : [0.0001, 0.0005, 0.0003, 0.0007, 0.0009],
'l1_ratio' : [0.05, 0.1, 0.15, 0.2, 0.25]
}
lin2_grid = GridSearchCV(lin2, param_grid = params2, n_jobs = -1, cv = 5)
lin2_grid.fit(X, y)이로 얻은 값들은 아래와 같다.
=========================SVR + GridSearch=========================
변수들 : [[5. 3.5 1. 5. ]]
실측값 : 1.633333333333333
예측값 : [0.55763502]
=========================SVR + GridSearch=========================
변수들 : [[5. 3.5 1. 2.5]]
실측값 : 1.6499999999999997
예측값 : [0.58991533]
=========================SGDRegressor + GridSearch=========================
변수들 : [[5. 3.5 1. 5. ]]
실측값 : 1.633333333333333
예측값 : [0.4389756]
=========================SGDRegressor + GridSearch=========================
변수들 : [[5. 3.5 1. 2.5]]
실측값 : 1.6499999999999997
예측값 : [0.38554578]사용한 모델들의 특성은 아래와 같다.
- SVR : 패턴인식, 자료 분석을 위한 모델이며, 데이터에 대한 초평면과, 그에 대한 서포트 벡터들을 생성하여 문제를 해결하는 SVM의 회귀 계열 모델이다.
자세한 내용은 https://ko.wikipedia.org/wiki/%EC%84%9C%ED%8F%AC%ED%8A%B8_%EB%B2%A1%ED%84%B0_%EB%A8%B8%EC%8B%A0 에서 참고하자.
- SGDRegressor : 정규화된 경험적 손실을 최소화 하여 피팅된 선형 모델로, 확률적 경사 하강법을 적용한 모델이다.
자세한 내용은 https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html 를 참고하자.
해당 모델들에 GridSearchCV를 적용해 하이퍼 파라미터를 튜닝했고, 두 번 정도의 시도가 있었으나 오차값이 너무 큰 것을 확인하고 추가적인 튜닝은 하지 않았다.
Shapley Value
- Shapley Value란, 게임 이론을 바탕으로 Game에서 각 플레이어의 기여분을 계산하는 방식이다.
- 하나의 feature에 대한 중요도를 얻기 위해 다양한 feature의 조합을 구성하고, 해당 feature의 유무에 따른 평균적인 변화를 통해 얻은 값이다.
- 따라서 Shapley Value는 전체 성과(판단)을 창출하는데 각 Feature가 어느정도로 공헌했는지 수치로 표현할 수 있다.
게임이론
- 여러 주제가 서로 영향을 미치는 상황에서 서로가 어떤 의사결정이나 행동을 하는지에 대해 이론화한 것
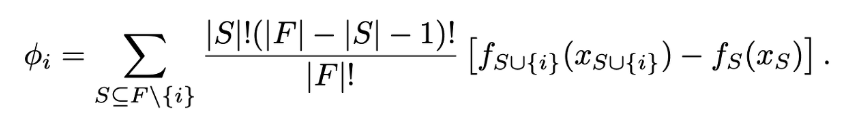
각 변수들이 의미하는 바는 아래와 같다.
- ɸi : i라는 데이터에 대한 Shapley Value
- F : 전체 집합
- S : 전체 집합에서, i번째 데이터가 빠진 나머지의 모든 부분집합
- fS⋃{i}(xS⋃{i}) : i번째 데이터를 포함한 전체 기여도
- fS(xS) : i번째 데이터가 빠진, 나머지 부분 집합의 기여도
python에서는 이 shap value를 손쉽게 사용할 수 있게 shap이라는 모듈을 제공한다.
!pip install shap해당 프로젝트에는 아래와 같이 적용할 수 있었다.
import shap
shap.initjs()
explaner = shap.explainers.Deep(model, X)
shap_value = explaner.shap_values(X)
shap.summary_plot(shap_value, X, plot_type = 'bar', plot_size = (9, 6)) 먼저 shap.initjs()로 js기반 시각화 코드를 내 jupyter파일에 로드하고, explainer 객체를 생성하여 딥러닝 모델과 데이터를 값으로 넣어준다. 이후 shap_value를 추출하여 시각화한다. 결과는 아래와 같다.
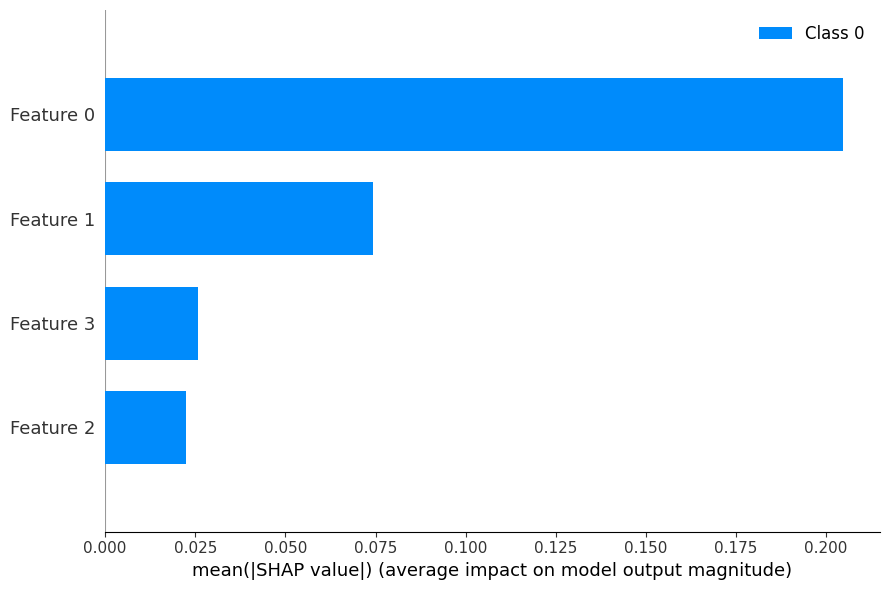
날개 길이 ➡️ 날개 폭 ➡️ 다리 길이 ➡️ 몸통 길이 순으로 변수의 공헌도를 파악할 수 있었다.
마무리
사실 막 그렇게 잘 된 케이스는 아니라고 생각한다. 하지만 이전에는 shap value에 대한 개념도 없었을 뿐더러, 회귀 분석이라고 하면 scikit-learn으로만 해결할 생각을 했는데, 일반적인 ANN으로도 해결할 수 있다는 점을 알기도 했으며, 다른 수강생들과 함께 그나마 정형화된 프로젝트를 처음부터 끝까지 느낀 것 같아 즐거운 일주일이었다. 다음주는 CNN을 이용한 가위바위보 게임을 만든다고 하니, CNN에 대한 추가적인 테크닉이나 정보들을 미리 정리해 두어야 겠다.
프로젝트 전체 코드는 https://github.com/LeeHeonWoo1/Intel/blob/master/projects/paper%20Helicopter/paper_helicopter.ipynb 에서 확인할 수 있다.
