1. 모든 데이터셋에 대해 성능이 좋은 알고리즘이 존재하는가?
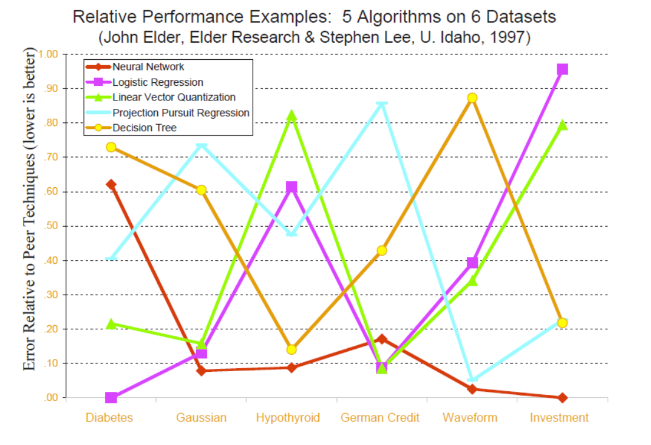
- 결론 : 항상 모든 데이터셋에 대해 1등인 알고리즘은 없다.
- 이유 : 어떤 알고리즘이 성능이 우수할 것인지 열등할 것인지에 대해서는 항상 예측할 수 없기 때문이다. 상황에 따라 적합한 알고리즘은 경험적으로 또는 정량적인 평가를 통해 정해진다. 그렇기에 특정한 상황에서 더 좋은 성능을 나타낸다는 것은 알고리즘의 본질적인 특성이 항상 우월해서가 아니라 현재 풀고있는 문제와 fit이 잘 맞기 때문이다. 하나의 알고리즘만 알기보다는 여러 알고리즘을 공부하는 이유이다.
- review : 부트캠프 수업에서 점점 더 성능이 좋은 알고리즘 모델들을 알게되었을 때, 왜 이렇게 좋은 알고리즘 모델이 있었는데 처음부터 이것들을 알려주지 않은 것인가?! 라고 의문이 들 때가 있었다. 여러가지 알고리즘 문제를 알고 배워야 하는 이유에 대해 의문점이 풀린 것 같다.
2. 개별 모델 vs 앙상블 모델
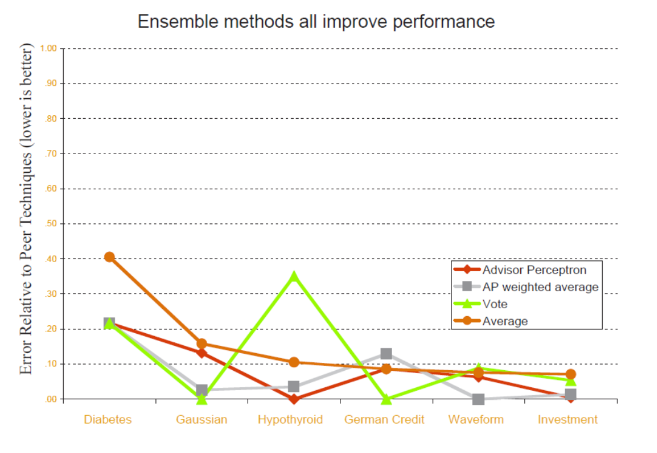
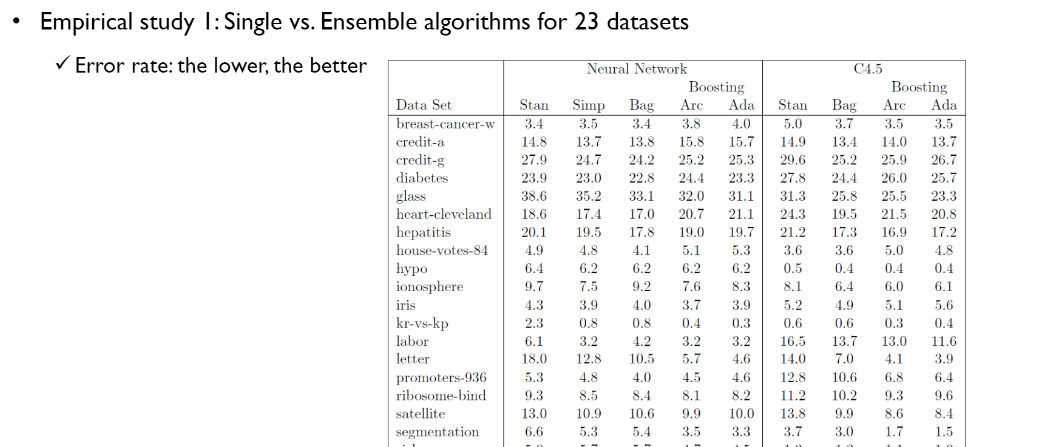
- 결론 : 모델들을 적절히 결합했을 때 대체적으로 기존 모델보다 성능이 좋았다.
"Ensenbles almost always sork better than the single best model"
3. 논문
Journal of Machine Learning Research 15 (2014) 3133-3181
<Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?>
https://jmlr.org/papers/volume15/delgado14a/delgado14a.pdf
어마어마한 실험을 통해 결론을 내린 그 당시에는 독보적인 top journal 이었음.
알고리즘 179개 X 121개 데이터셋 X 30번 반복수행 의 실험을 함
모든 알고리즘을 데이터셋마다 랭크를 매기고 총 평균 랭크를 내려 순위를 매김
✔논문 결론 : 모든 랭크가 1인 알고리즘이 존재하지 않음. (No Free Lunch Theorem) 그럼에도 불구하고 순위의 편차가 존재함. 상위권 랭크의 알고리즘은 대체적으로 성능이 좋다. (RF와 SVM계열의 알고리즘 분류성능이 높게 나타남)
✔한계 : Boosting 계열을 모두 사용하지 않음.(Ada Boosting만 있음) 또한 같은 알고리즘이어도 구현이 다른 알고리즘을 각각 표현함.
참고

https://gggggeun.tistory.com/