데이터분석
- 기존 DataBase 도구를 넘어 서버를 여러대 나누어 처리하는 분산처리 기술 이 중요함 (ex 라즈베리파이)
==> 가치 추출 ! data mining 하는 게 정보 홍수 시대에 필요함
올바른 가치추출을 위해서는 업무에 대한 도메인지식이 필요하게됨 -> 그 분야에 준 전문적 지식이 있어야 분석에 용이함 - 분석 후 결과 도출!
분석만으로 끝나지 않고, 의미 있는 가치를 추출하여 기업의 의사결정이 이루어지는 행동으로 이끌어낼 수 있어야됨
분석결과를 서비스화(Web Service, Mobile Service, Desktop Application) --> End user에게 제공 - 데이터 과학
데이터과학:통계학 분석방법론, 머신러닝, 딥러닝, 텍스트마이닝, 추천시스템 등
데이터를 분류, 분석하고, 데이터속 패턴, 미래예측에 도움이 되는 신호를 찾음 - 필요 스킬 ?
프로그래밍,수학,통계학적 지식, 분야의 전문지식 - 데이터 과학 과정
데이터수집 - 데이터전처리 - 데이터분석 - 데이터예측 - 데이터시각화/서비스화
- 데이터수집

- 데이터 전처리
- 결측치 처리 : 데이터 삭제, 다른값 대체,최대,최소 중앙값등 예측모델활용해 값 삽입
- 이상치 처리 : 입력오류(데이터삭제, 다른값대체), 자연발생(featur추가)
- Feature Engineering : scaling(feature의 단위를 변경), binning (수치형->범주형),transform(feature를 분리하거나 연산 - 날짜 주중이거나 주말), encoding(범주형 -> 수치형)
- 데이터분석

4.데이터예측
5.시각화


모듈 (라이브러리)
- 확장자 .py
- 함수, 클래스, 변수 모아놓음
- 분석에 특화된 모듈
NumPy : 고성능 과학계산을 위한 데이터분석라이브러리 _ 연산 Pandas : 표형식 데이터 지원 라이브러리
Matplotlib : 2D 그래프 시각화 가능함

쥬피터에서 해보깅
Numpy 모듈(라이브러리) import하고 np라는이름으로 부른다
import numpy as np

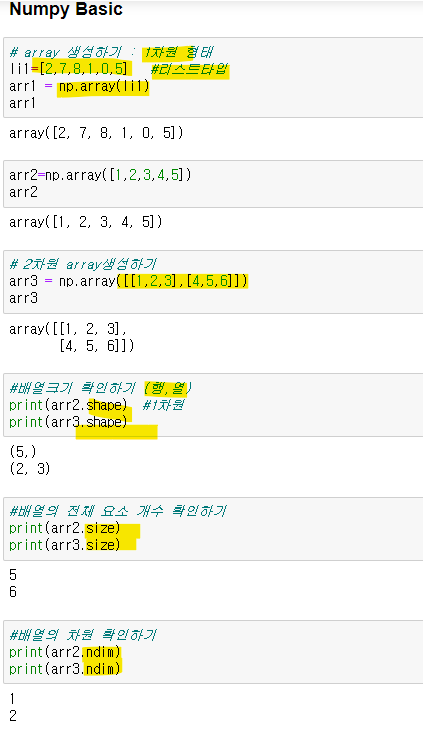
배열크기확인하기 - .shape 결과는 (행,열)로 나옴
전체 요소 개수 확인 - .size
몇차원인지 .ndim

.zeros : 0초기화
.ones : 1로 초기화
.full : 특정값 초기화 5행5열 7로 채워줌
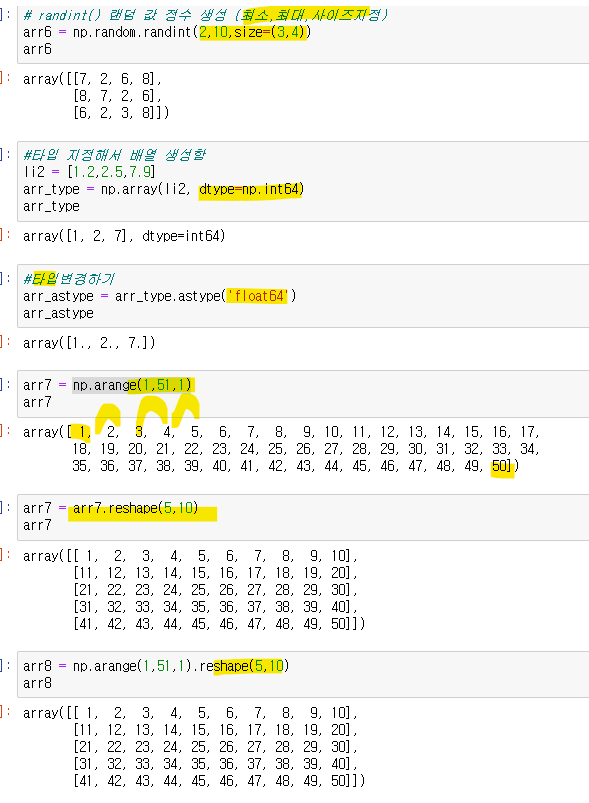
.arange(시작, 끝, 증가)
.random.rand(2,3) 2행 3열 0~1까지 랜덤 값 실수형태
.randint() 랜덤값 정수생성(최소,최대,size=(행,열)-사이즈지정)
타입지정은 (넘파이배열이름, dtype=np.int64)
.astype('flaoat64') 타입변경
인덱싱
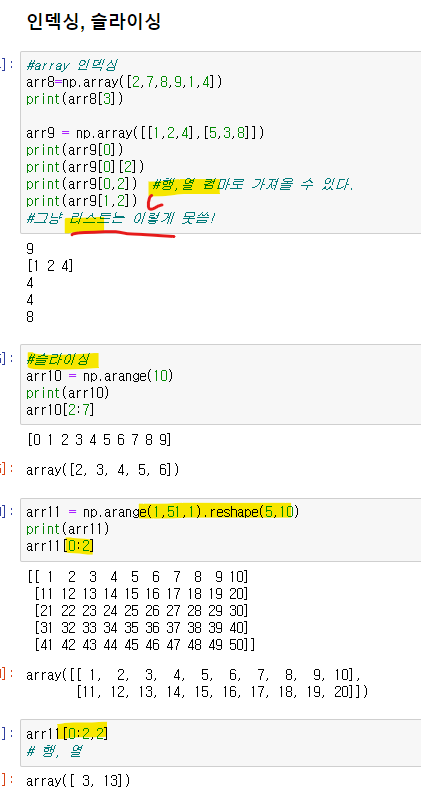

넘파이배열은 행,열을 컴마로 가져올 수 있음
슬라이싱도
특정부분만 행열로 가져올수있다
요소별 연산하기
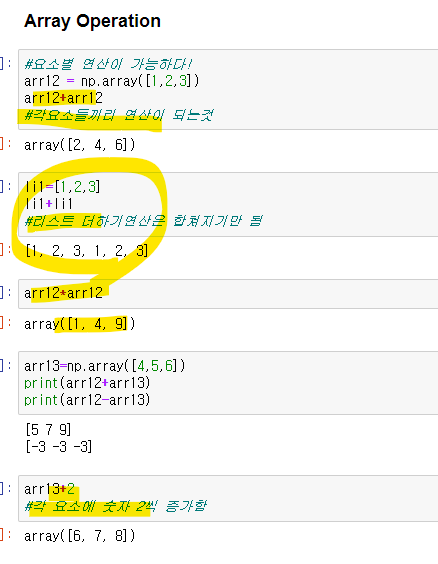
각요소끼리 연산이 가능하다
불리언 색인
True에 해당하는 값들만 불러오는 것
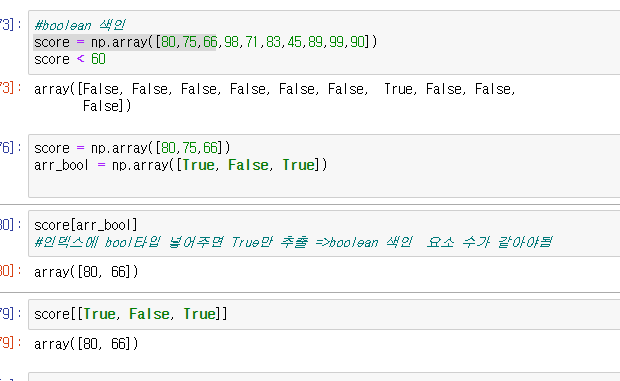
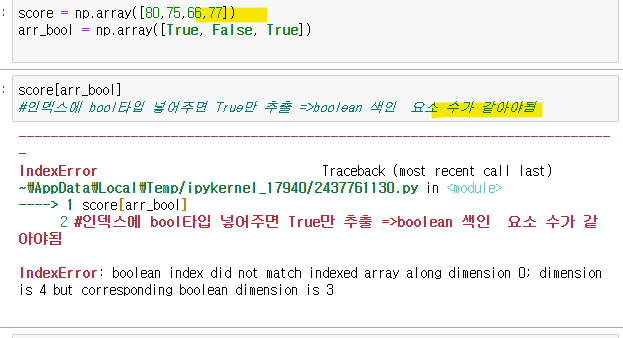
요소 수가 같아야 됨!
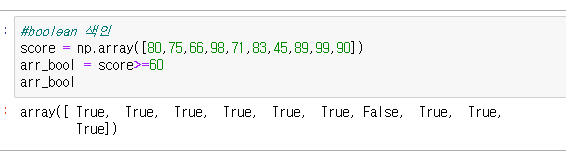

<-색인해온 결과값
