비지도 학습 (Unsupervised Learning)

지도학습은 문제와 답이 있었음 (X,y)

강화 학습 (Reinforcement Learning)

ex)

머신 러닝의 과정

1. 문제 정의
2. 데이터수집 --->데이터가 가장 중요!
3. 데이터 전처리 (가공)
4. 탐색적 데이터분석 ( 가공 데이터의 특징, 상태확인하는 작업, 통계, 시각화 등)
5. 모델선택 (ex knn모델 등)
6. 학습 (모델을 학습)
7. 평가 (잘못되면 다시 처음부터 반복함. 유의미한 결과를 얻을때까지..---> 주관적이기때문에 분석가에 따라 다름)
- 문제정의

- 데이터 수집

- 데이터 전처리 (여러형태로 가공함)

- EDA 탐색적 데이터 분석

- 모델선택
hyper parameter -> knn 모델의 k 값
- 학습
문제 X 답y
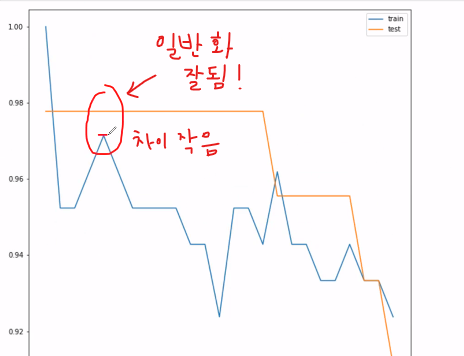
훈련후 성능 평가를 하게 되는데,훈련데이터와 테스트 데이터로 나누게 되는데 . . .
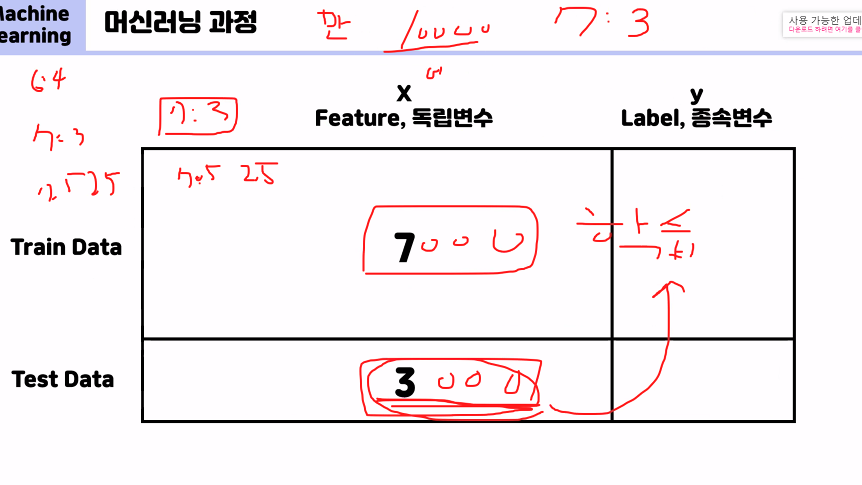
1만개 데이터를 학습을 하는데, 7000개로 학습, 3000개는 학습데이터기반으로 테스트함 --> 성능 훈련도 하게 됨, (평가는 학습이 안된 데이터로 해야됨!!)
모델에 train 데이터를 100% 학습시킨 후 test 데이터에 모델을 적용했을 때 성능이 안나오는 경우가 많기 때문 (=Overfitting 되었다고함) 모델이 학습 데이터에 너무 과적합되도록 학습해서 이를 조금이라도 벗어난 케이스에 대해서 예측율이 떨어짐!
훈련데이터는 전체데이터를 대표할 수 있게 표본을 잘 뽑아야됨
분류모델에서-라벨이 고루 뽑히게, 회귀에서-이상치를 제외한 데이터들이 고루 뽑혀야됨

- 평가

BMI 학습
- 문제 정의
500명의 키, 몸무게, 비만도 라벨을 이용해 비만을 판단하는 모델을 만들어보기
- import

- 데이터 수집
.info()통해 데이터타입 등 확인하기


3. 데이터전처리(생략)
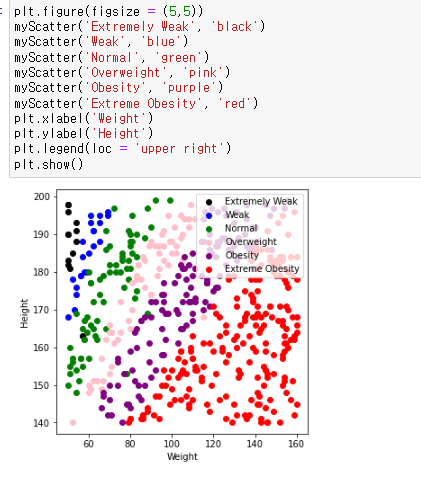
4. 데이터 시각화 (차트만들기) EDA ---등급별 시각화
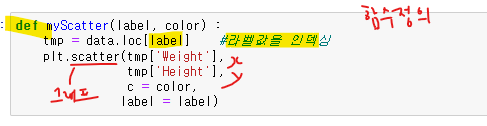
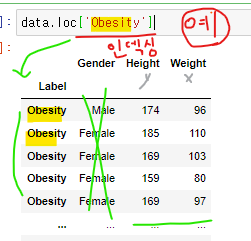
함수 안 tmp (인덱싱 예)
5. 모델링
모델생성, 하이퍼파라미터 조정하기
문제 정답으로 나누기
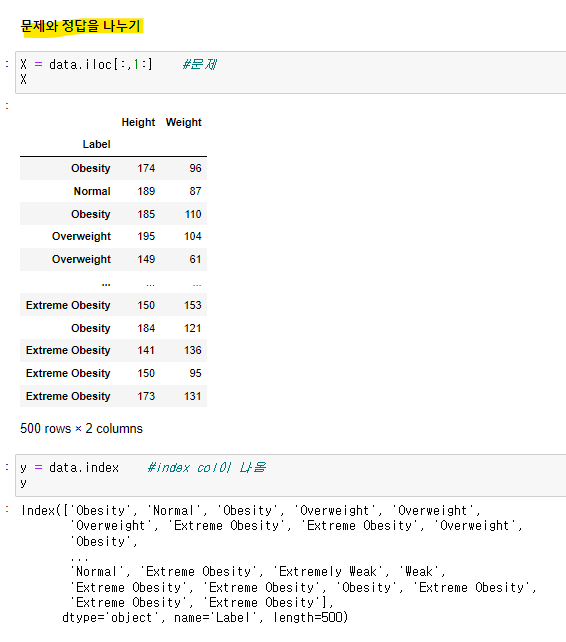
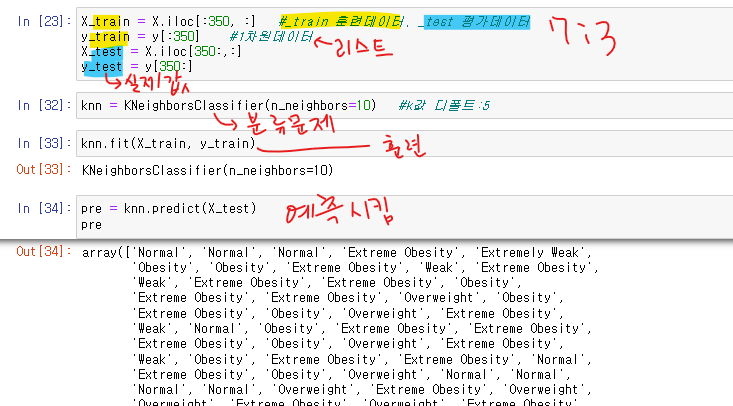
7:3의 비율로
훈련데이터-0~350행
테스트데이터 350~ 마지막행까지
predict 는 모델이 알려준 값
실제값: y_test
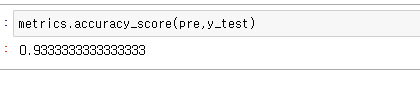
- 평가하기
메트릭스 라이브러리로 예측값(pre), 실제값(y_test) 넣어 정답률을 확인해 볼 수 있다.
성능을 더 높이고싶다면 ? 데이터 수를 수집해서 늘리거나, k값을 늘림 - 활용하기
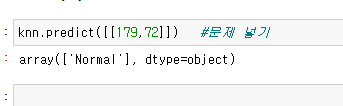
문제를 넣으면 답을 알려줌, 훈련했던 것과 똑같은 형태로 넣어줘야됨 ! X_train 2차원형태였기땜에 같은 형태로 넣어줬음
iris 품종분류
- 문제정의
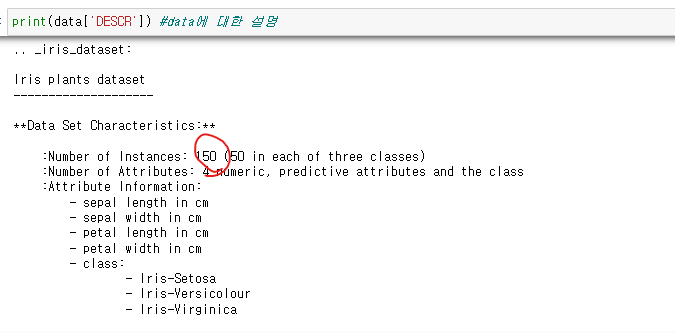
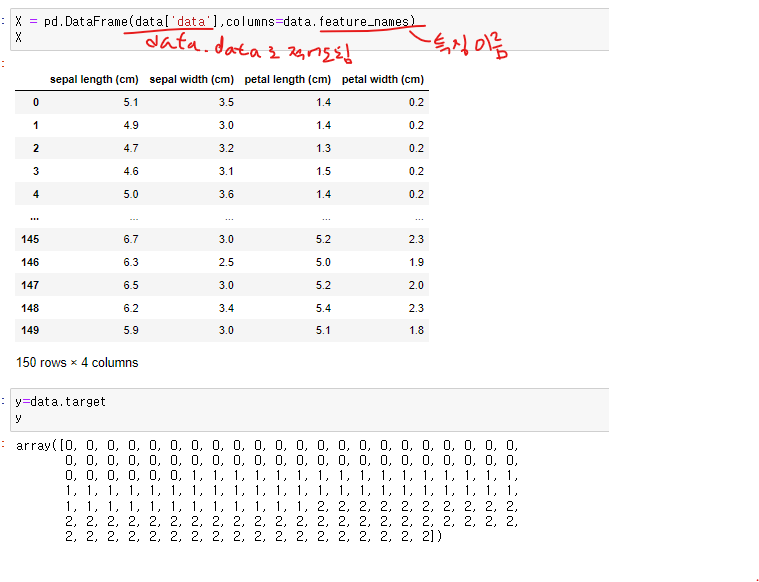
붓꽃의 꽃잎 길이, 꽃잎 너비, 꽃받침 길이, 꽃받침 너비 특징을 활용 3가지 품종 분류해보기
sklearn에서 제공해주는 데이터셋 - load_iris
knn분류, 메트릭스모델 임포트해주기
iris 데이터 실행시 딕셔너리(중괄호-키밸류) 형태인 것으로 알 수 있다.
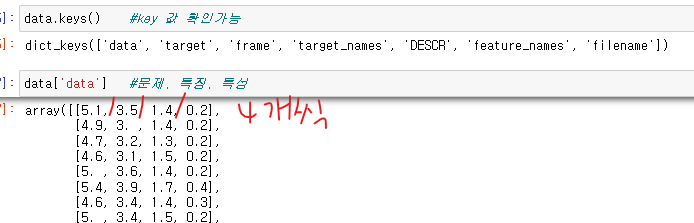
딕셔너리형태이므로 키값을 확인할 수 있고 '타겟'컬럼이 정답 즉 라벨이란걸 알 수 있음

- 데이터셋 구성하기
- 문제와답 분리
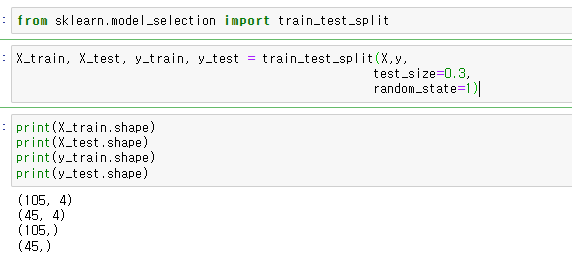
- 훈련셋, 평가셋 분리
그냥 슬라이싱으로 7:3으로 해버리면 뒷부분 2는 학습이 안되어서 답이 안나옴 --> 랜덤으로 뽑아야됨!!
y값을 보면

랜덤으로 섞어주는 sklearn의 model_selection패키지에 train_test_split함수 이용
test-size:전체데이터셋에서 테스트셋의 비율
random_state:데이터 분할시 셔플이 이루어지는데 이를 위한 시드값
-
모델링

-
하이퍼파라미터 튜닝