머신러닝

-
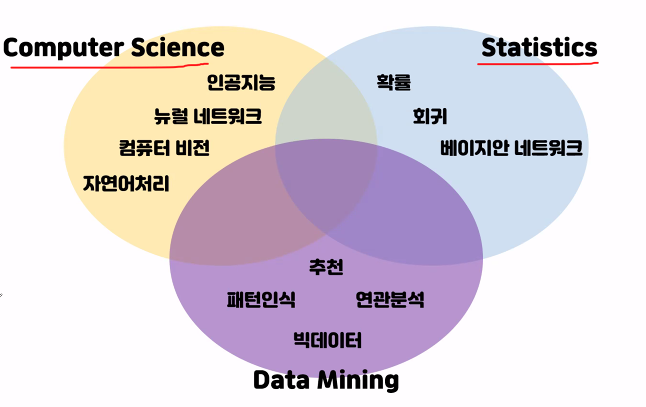
Data Mining : 대용량의 데이터를 수집하고, 유의미한 데이터를 만들어냄
-
기존의 알고리즘 :

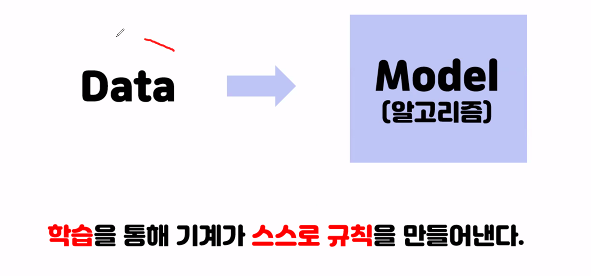
모델(알고리즘)에 학습을 시킨다 -
문제점


머신러닝 종류
머신러닝에서 클래스는 정답이다
속성은 문제 == 특성 == 특징

지도학습 분류(범주형데이터), 회귀(연속성데이터)로 나뉨
- 대부분 지도학습을 이용함
예)스팸메일분류, 집 가격예측

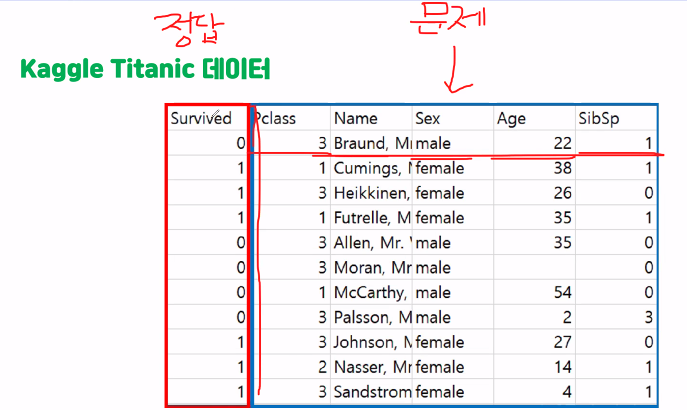
- 분류 :

이진분류는 둘중 하나, 다중분류는 세개이상의 여러개 중 하나
정확한 답이 있음 - 회귀 :

정답의 데이터타입에 따라 회귀, 분류로 나뉘어진다.
예측값(답)과 미묘한 차이는 중요하지않음
일반화,과대적합,과소적합
- 과대적합 : 많은 특성을 학습시키면 다른 것을 예측못함
- 과소적합 : 너무 적은 특성을 학습시켜서 다른 것을 예측x
- 일반화가 되어야함

훈련데이터를 학습하고 테스트데이터로 예측함-성능확인!

모델복잡도가 클수록 과대적합
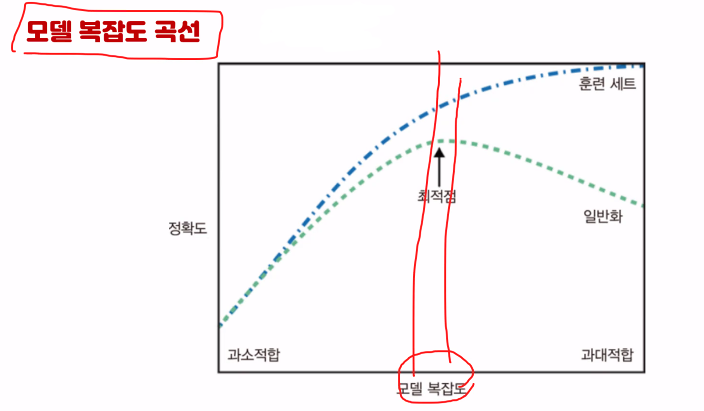
- 해결방법 :

K Nearest Neighbors(KNN)
K-최근접이웃알고리즘

기존 훈련데이터에서 k와 근접한 값을 찾아서 예측하는것
예)
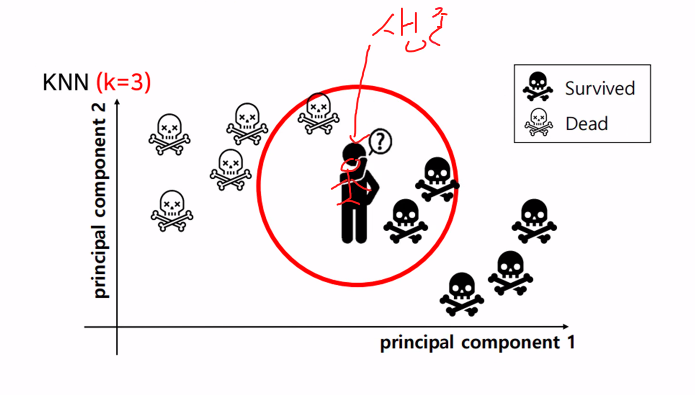
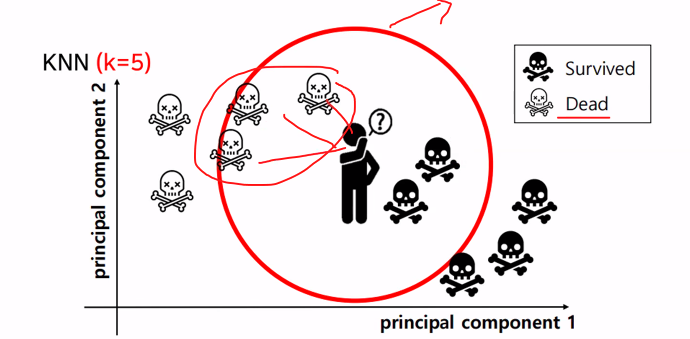
- k - 최근접 알고리즘

k가 작을수록 훈련데이터만 학습해서 --->과대적합 복잡함
노이즈값-이상치
k값 = n_neighbors
AND 연산 학습
-
1과 1이 만났을 때만 1이 되는 AND연산
-
pandas import
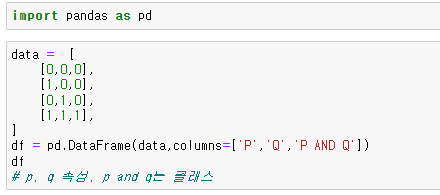
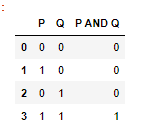
-
X : 문제(대문자 X를쓴다-약속)
y : 정답
데이터프레임에서 슬라이싱해서 각 변수에 담아줌
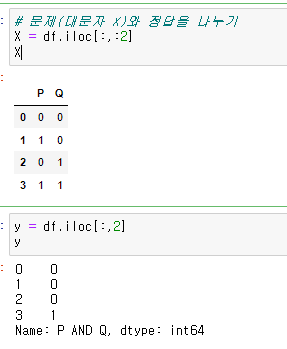
-
sklearn : 파이썬에서 머신러닝 분석을 유용하게 사용되는 라이브러리, 여러가지 머신러닝 모듈로 구성됨
정답을 분류하기 때문에 Classifier
성능 측정 라이브러리 metrics

-
모델 객체 생성

-
fit에 문제, 정답순으로 넣기

-
예측할 값을 넣어주는 .predict()
확인해보면
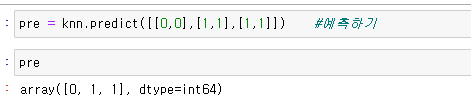
-
실제값을 변수에 담아주고

-
metrics.accuracy_score ()안에 매개변수로 실제값, 예측된 값을 넣어서 잘 나오는 지 확인해본다
accuracy_score() : 정답률 ( =정확도 ) 실제 데이터 중 맞게 예측한 데이터의 비율
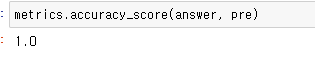
-
만약 n_neighbors=2 일때 (사진 잘못씀 ㅎ)
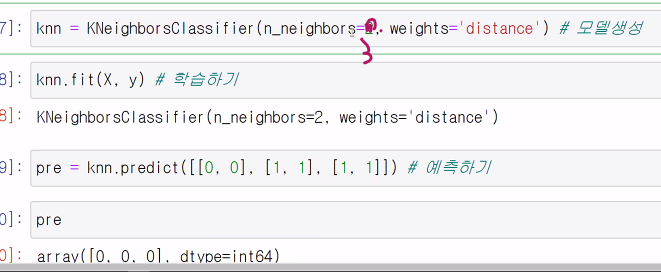
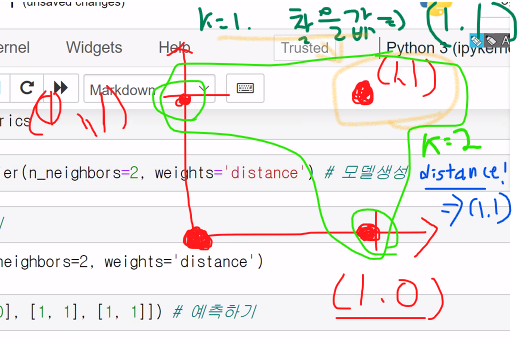
weight 없이 n_neighbors=2를 주면 0.3333 이되고
weight을 distance로 주면 가까운 값을 찾게되므로 값이 잘 나옴 (가까운 k=2가 됨)-->사진참조
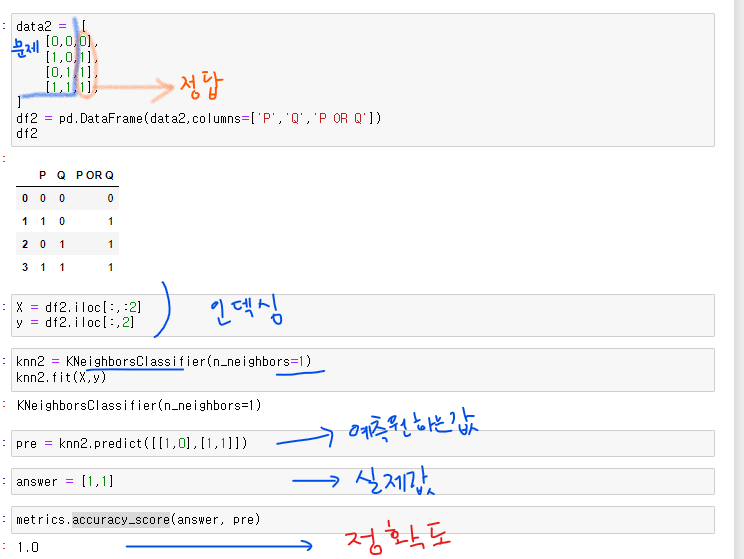
OR 연산 학습
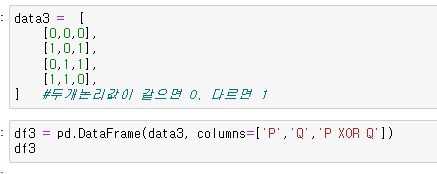
XOR 학습
- 두개논리값이 같으면 0, 다르면 1

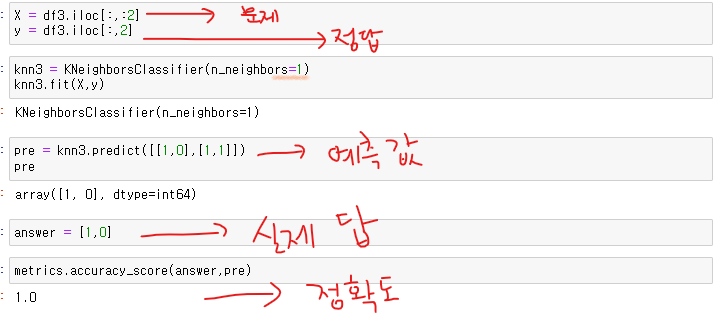
- 데이터포인터들간의 거리를 측정해서 예측한다


-장단점

훈련데이트 세트가 클수록 거리계산이 많아져서 예측 느려짐
