Motion Capture and Character Animation
1. Introduction
- Motion Capture(MoCap)
- actor의 움직임을 찍은 후 digital data로 변환한 것
- 사실적이고 자연스러운 애니메이션을 생성 가능하다.
- performance capture
- 얼굴이나 손가락 등의 캡쳐가 까다로운 부분을 캡쳐하는 기술
- Character animation을 만드는 여러가지 방식
- Key frame animation
- key frame마다 특정 포즈를 만들고 key frame 사이는 linear interpolation으로 만드는 기술
- 애니메이터가 많은 시간을 사용하여 캐릭터 모델의 조인트 값 등을 조절하여 만들어야 한다.
- 사람 형태가 아닌 모델에 있어서도 사람 형태와 유사하게 구현할 수 있어 제한이 없다.
- Procedural animation
- 수학적 계산과 알고리즘을 통해 애니메이션을 생성하는 기술
- 물리기반 애니메이션이나 IK 등을 포함한다.
- 애니메이터가 직접 만들기에 너무 복잡한 모션을 만들때 사용하여 시간 절약을 할 수 있지만, 원하는 모션이 나오기 까지 추가적인 처리가 필요하다.
- Mocap
- 장점
- Realism
- Efficiency
- Consistency
- 액터의 연기에 따라 캐릭터의 스타일을 유지할 수 있다.
- Performance-driven
- 단점
- Cost
- Mocap 기술의 가장 큰 문제점
- 카메라, 수트, software 등 다양한 장비들이 필수적이다.
- Limited flexibility
- 사람 형태의 애니메이션이 아닌 다리가 많거나 판타지 세계에 나오는 생물들은 액터가 연기하기에 적합하지 않다.
- Cleanup and refinement
- 찍은 데이터를 가공하여 애니메이션으로 만들기 위해서 여러 후처리가 필요하다.
- Dependence on performer
- 연기자의 실력에 따라 다른 결과물이 나오게 된다.
2. Mocap Method
1. Optical Motion Capture (OMC)
- Intro
- capture 공간에 있는 여러대의 카메라를 통해 marker의 움직임을 tracking 하는 기술
- triangulate 방식을 통해 marker의 position을 측정한다.
- 카메라로 marker의 위치를 찍으면 2D 형태로 나오게 된다.
- 이때 여러대의 카메라를 이용해서 찍은 후 카메라로부터 물체까지의 거리를 분석하여 3D 상의 위치를 알아내는 방식을 사용한다.
- 카메라가 많아질 수록 특정 방향에서 가려진 부분을 찍을 수 있어서 정확하게 측정할 수 있다.
- 종류
- Passive optical motion capture
- marker가 스스로 무언가 하지 않는 방식
-> 스스로 빛을 내지 않고, 별다른 power가 필요하지 않음
- 외부에서 쏘는 빛을 marker가 반사하여 marker의 위치를 측정하게 된다.
- marker가 빛을 받아서 반사한 빛이 카메라로 들어가게 되어 marker를 detect 하고 track 할 수 있다.
- detect : 주어진 frame 에서의 위치
- track : 연속된 frame 동안의 위치
- 이 방식의 가장 큰 문제점은 각각의 marker의 위치는 알 수 있지만, 특정 marker가 실제 사람의 몸의 어느 부분에 해당하는 것인지 알 수 없어서 추가적으로 분석이 필요하다. (unique ID가 없다)
- Active optical motion capture
- marker가 스스로 빛을 내는 방식
-> 각각의 marker들은 power가 필요하고, 전자 회로를 가지고 있어 빛을 낸다.
- marker들이 unique ID를 가지고 있어서 각각이 몸에 어떤 부위에 해당하는 것인지 알아보기 쉽다.
- Passive VS. Active
- Cost
- Passive 방식이 더 저렴하다.
- marker에 추가적인 기능이 없기 때문에
- Marker complexity
- Passive가 더 간단하다.
- Active는 unique ID가 있기 때문에 해당하는 부위에 정확하게 붙여야 한다.
- Lighting dependency
- Passive의 경우 반사시키기 위한 빛을 쏴야하기 때문에 캡쳐하는 공간이 어두워야 한다.
- 다른 빛이 들어오는 것을 막아야 하기 때문에..
- Marker occlusion
- Active 방식이 더 좋다
- Active 방식은 unique ID가 있기 때문에 몇몇 카메라에서 가려져서 찍히지 않더라도 Passive 방식보다 처리가 쉽다.
2. Interial motion capture (IMC)
- 웨어러블 센서를 부착하고 모션 캡쳐를 하는 방식
- 해당 센서는 가속력, 각속도, 자기장 방향 등을 측정하여 액터의 위치와 기준을 측정한다.
- 장점
- Portability and flexibility
- OMC 방식과 다르게 캡쳐공간이나 카메라가 필요 없다
- No Occulsion issues
- Faster setup
- Real-time feedback
- 단점
- Positional accuracy
- Magnetic interference
- 자기장 방향을 측정할 때 사용하기 때문에 주위의 자기장의 영향을 받을 수 있다.
- Battery life
3. Magnetic motion capture
- magnetic field 를 이용해서 tracking 하는 방식
- 아직 실험적인 방식
4. Mechanical motion capture
- 강화 외골격을 입고 찍는 방식
- 아직 실험적인 방식
5. Markerless motion capture
- 컴퓨터 비전 알고리즘을 이용하여 marker나 다른 기기들 없이 분석하는 방식
- 아직 실험적인 방식
3. Post-Processing of POMC
- Passive Optical Motion Capture 방식을 사용하는 이유
- less expensive
- simpler to use
- familar to end user
- post processing of POMC
- 결과물의 정확성과 퀄리티를 위해 post-processing이 필수적이다.
- Resolving marker ambiguity (marker labeling)
- POMC의 가장 큰 문제점이 point cloud가 추출된 후 정확한 위치 파악이 어렵다는 점이다.
- 추출한 점들을 캐릭터에 위치에 맞게 labeling 하는 작업이 필수적이다.
- Reducing noise
- Gap filling
- 원래 예상한 결과값의 갯수보다 적어진 점들을 만들어야 한다.
- 카메라에 가려진 marker 때문에 예상한 결과보다 적은 값이 나올 수 있다.
- 해결책
- interpolation
- adjusting the marker positions
- Rigging and retargeting
- motion capture 데이터를 애니메이션으로 만들기 위해서 skeleton 으로 mapped 하는 작업이 필요하다.
- Constraint enforcement
- 실제 사람과 유사하게 동작하게 만들기 위해서 constraints를 적용해야 하는 경우도 존재한다.
- physical limitations를 따르게 만들기 (range of joint..)
- Cleanup and optimization
- 예상보다 더 많은 데이터값이 나온 경우 없애는 작업이 필요하다.
- 너무 빠른 움직임을 가져가는 등의 경우에 더 많은 marker 들의 좌표가 측정될 수 있다.
4. Mocap Labeling Problem
- 위에서 언급한 가장 큰 문제점을 해결하기 위한 방식인 marker labeling에 대한 내용
- POMC에는 unique ID가 없기 때문에 발생하는 문제점
- 최근에 사용하는 방식으로 SOMA : Solving Optical Marker-Based MoCap Automatically 이 있다.
- Notation
- Mocap Point Cloud (측정한 결과로 나온 점들)
- {P1,...PT}
- Pt={Pt,1,...,Pt,nt}
- 첫번째 첨자는 frame 두번째 첨자는 갯수에 대한 index
- ex) 3 frame 에서 7번째 marker : P3,7
5. SOMA
1. Notation
- marker label
- L={l1,...lM,null}
- null은 ghost marker를 위해 존재 (예상보다 더 많은 값 나왔을 때 처리)
- three constraints
- C1 : 각 point Pt,i는 최대 하나의 label에 할당된다.
- C2 : 각 point Pt,i는 최대 하나의 tracklet에 할당된다.
- tracklet : 여러 프레임에 걸쳐 진행하는 과정을 하나의 track으로 저장하는 것
- C3 : null label은 예외적으로 하나 이상의 point를 가질 수 있고, 여러개의 tracklet에 포함될 수 있다.
2. Self-Attention on MPC
- pipeline of SOMA
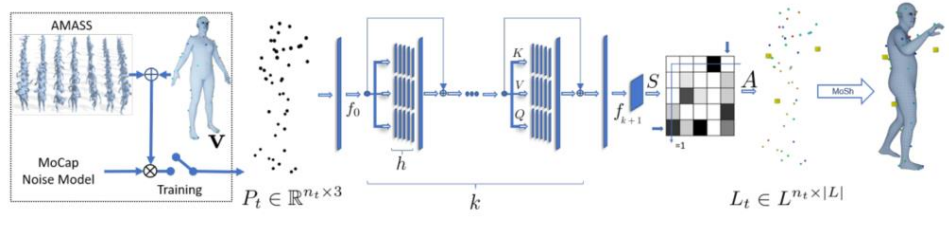
- input data : single frame of sparse point
- output data : ID를 부여한 point들
- multiple layer of self-attention를 이용해서 data processing을 진행한다.
3. Attention
- 사람이 생각함에 있어서 이해할 때 하는 집중을 모방한 방식이다.
- word embedding (예시)
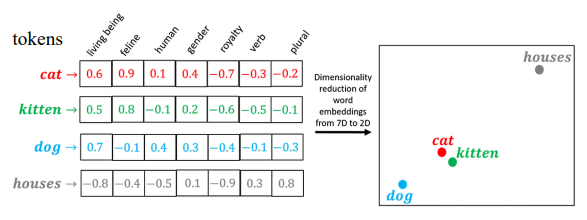
- 연관성이 높은 것을 찾는 과정! (value vector vi 찾기)
- 각 토큰들이 있을 때 word embedding을 통해 각 token과 연관성이 있는 축에 가중치를 준다
- 이후 축이 7개라면 7d -> 2d 공간으로 바꿔주면 특정 token끼리의 연관성을 구할 수 있다.
- Compute Weights
- attention의 output은 weight average
- ∑iwivi
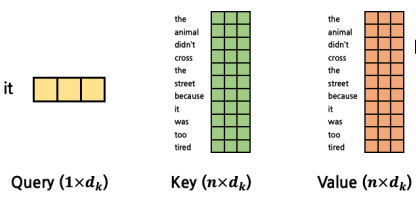
- weight를 구하기 위해서..(query-key mechanism 사용)
- Q : Query
- K : Key
- V : Value
- dk : embedded vector dimension
- Query's Attention(Q,K,V) = softmax(dkQKT)V
4. example
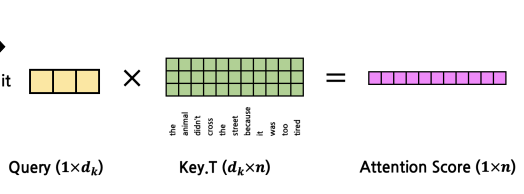
- word embedding을 통해 아래처럼 구성한다. (dk=3)
- QKT를 계산하여 attention score를 얻는다. (Query's attention의 분자를 구하는 것)
- 이후 attention score에 softmax를 취하고 Value를 곱하면 Query's Attention을 구할 수 있다.
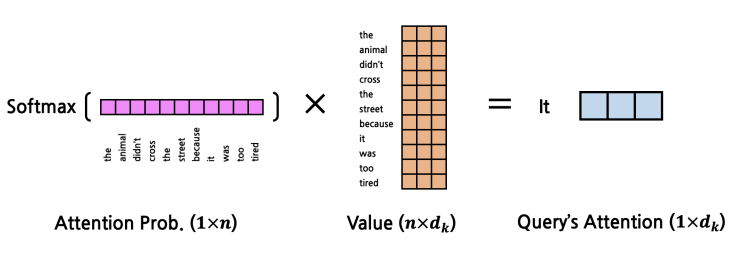
- 위와 같이 Q,K,V가 모두 같은 data에서 온 값들이라면 위의 방식을 통해 얻은 결과를 Self-Attention 이라고 한다.
-> 나하고 얼마나 가까운 값들인지..
-> 예시에서는 "it" 과 전체 문장에 대하여 얼마나 가까운지에 대한 값
5. multilayered multi-head self-attention
- 나하고 관련도가 있는 것과 관련된 것에 대한 것을 분석할 수 있으므로 기본적인 self-attention 보다 더 정확한 값을 구할 수 있다.
