
개념
1. Tokenization
-
토큰화 : 주어진 corpus에서 토큰이라 불리는 단위로 나누는 작업 / 토큰의 단위가 상황에 따라 다르지만 보통 의미있는 단위로 토큰을 정의
-
단순히 띄어쓰기로 단어를 구분하게 되면 숙어, 구문, 지명 등이 나눠져서 의미를 잃게되므로 토큰화 규칙을 이에 맞게 변경해야한다
-
they've , I've, we've 등 have를 분리하여 사용해야 한다
-
대표적인 라이브러리
- Nltk의 tokenizer (word_tokenize) : 간단하지만 주문제작 불가
- SpaCy의 tokenizer : 러닝커브가 있지만 주문제작 가능
2. Dropping Common Terms: Stopwords
- 말뭉치 속 단어를 빈도수가 높은 순으로 역정렬하면 그래프가 언어에 관계없이 다음 형태를 띈다
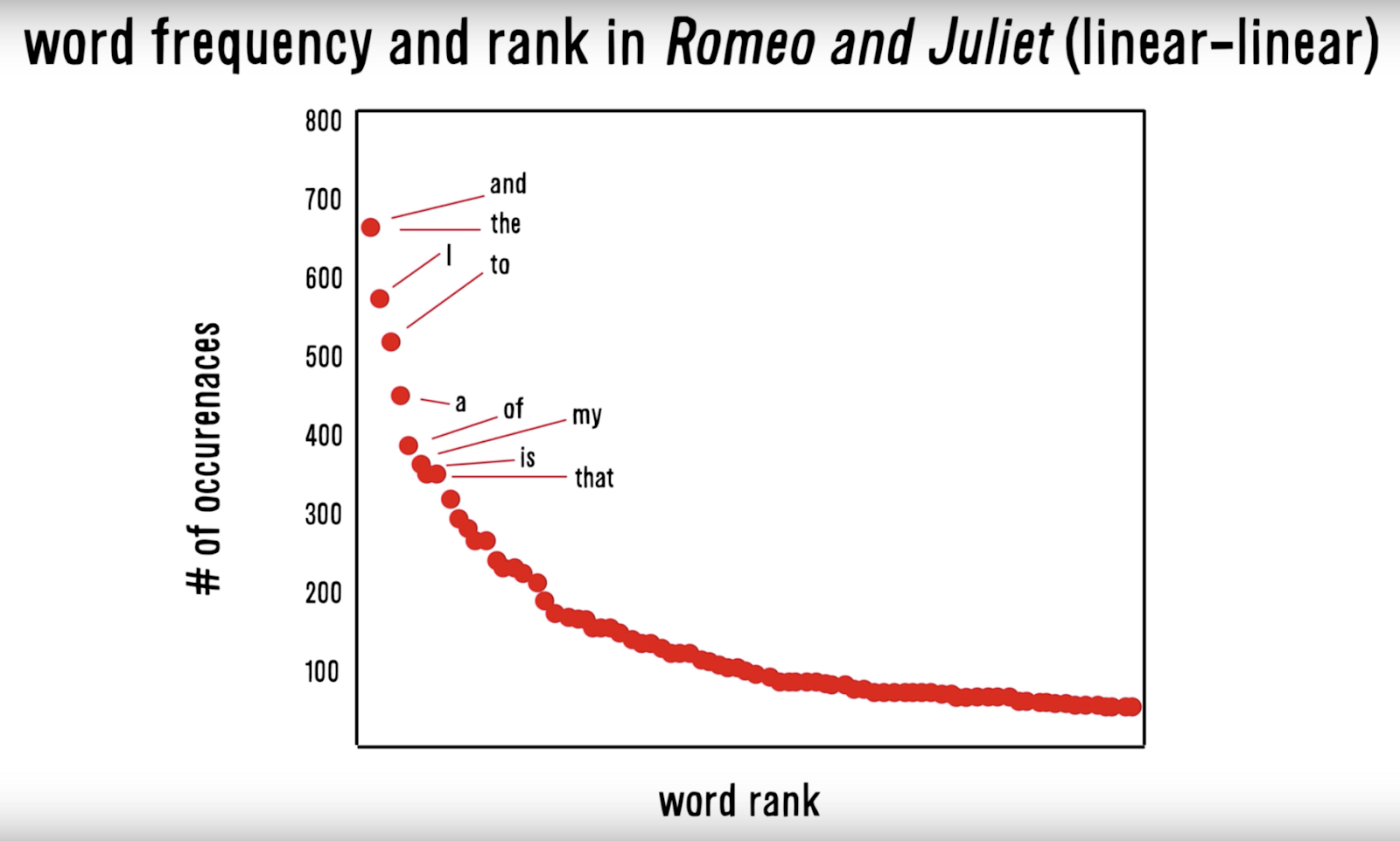 From: The ZIpf’s Mystery (Vsauce, 2015)
From: The ZIpf’s Mystery (Vsauce, 2015)
- 이 그래프에서 어느 정도를 불용어로 지정하여 삭제하면 중요한 단어를 얻을 수 있다
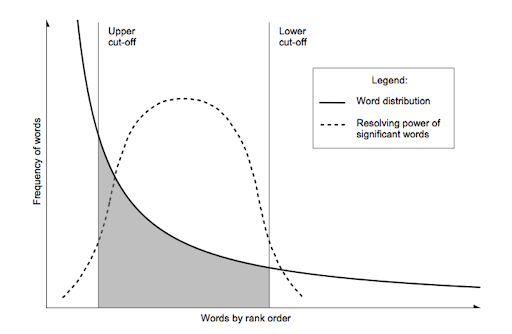 From: The ZIpf’s Mystery (Vsauce, 2015)
From: The ZIpf’s Mystery (Vsauce, 2015)
단점 :
-
라이브러리 별로 stopwords의 리스트가 다르므로 제거를 원치않는 불용어가 있는지 미리 ㅣ확인해야한다
-
불용어를 없애버리면 문장의 구조가 파괴되기 때문에 문장의 의미가 훼손될 수 있다
3. NormalisingWords: Stemming & Lemmatization
- Stemming : 어간(stem)을 추출하는 작업
-
대표적인 stemming 알고리즘으로 Porter Stemmer가 있음
Porter Stemming Algorithm -
단순 규칙에 기반하므로 제대로된 일반화를 하지 못할 수 있다
- Lemma : 표제어 또는 기본 사전형 단어를 의미
-
is,are, were → be
-
Count-based 기법으로 문제를 풀고자 하는 Bag of Words 표현을 사용하는 자연어 처리 문제에서 사용된다
-
눈으로 봤을 때는 서로 다른 단어들이지만 하나의 단어로 일반화 시킬 수 있으면 문서 내의 단어 수를 줄일 수 있다
-
Corpus의 복잡성을 줄이는 일이다 ( Corpus를 더 밀도 있게 하고 낮은 차원의 벡터가 되도록 한다 )
출처
광주 인공지능사관학교 - 김유빈 강사님
