7. Convolutional Neural Networks
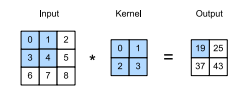
(nh − kh + 1) × (nw − kw + 1)
From Linear to Nonlinear
In order to realize the potential of multilayer architectures, we need one more key ingredient:
a nonlinear activation function σ to be applied to each hidden unit following the affine transformation. For instance, a popular choice is the ReLU (Rectified Linear Unit) activation function (Nair and Hinton, 2010) σ(x) = max(0, x) operating on its arguments element-wise.
The outputs of activation functions σ(·) are called activations. In general, with activation
functions in place, it is no longer possible to collapse our MLP into a linear model:
H = σ(XW(1) + b(1)),
O = HW(2) + b(2)
element-wise: 두 벡터와 행렬에서 같은 위치에 있는 원소끼리 덧셈과 뺄셈의 연산을 요소별 연산이라고 한다.
row-wise fashion: 행 우선 방식

DL 공부중