
Data Science란?
-
Business에 대한 의미있는 통찰을 추출하기 위한 Data에 대한 연구
-
방대한 양의 Data를 분석하기 위해 mathematics, statistics, artificial intelligence, and computer engineering 등등 다양한 분야로부터 개념과 원리들을 결합한 다중학적 접근
-
무슨 문제가 일어났는지, 왜 일어났는지, 무슨 문제가 일어날 것인지,
결과를 가지고 할 수 있는 것들과 같은 질문들을 Data Scientist들에게 묻고 답하는데 이러한 분석이 도움이 된다.
Why Data Science?
Data의 텍스트대부분의 중요한 결정들은 부분적인 정보나 불확실한 결과들을 가지고 만들어진다.
그러나, 많은 결정들에 대한 불확실성의 정도는 방대한 Data sets에 대한 접근과 Data sets을 효율적으로 분석하기 위해 요구되는 계산적인 tool들에 의해 많이 줄어든다.
Data 기반 결정과정은 finance, advertising, manufacturing, and real estate를 포함한 산업의 방대한 분야에서 이미 많은 변화가 되어왔다.
Literacy Characters
텍스트를 로드한 후, 우리는 책의 특정 문자나 내용들이 각각 몇 번씩 언급되었는지 빠르게 시각화할 수 있다. 다음 예시는 허클베리핀의 소설 내용 중 일부를 분석하여 Jim, Tom, Huck이란 이름들의 빈도수를 체크하는 내용이다. 이 내용은 추후에 전문적으로 다룰 예정이니 참고만 바란다.
#Count how many times the names Jim, Tom, and Huck appear in each chapter.
counts = Table().with_columns([
'Jim', np.char.count(huck_finn_chapters, 'Jim'),
'Tom', np.char.count(huck_finn_chapters, 'Tom'),
'Huck', np.char.count(huck_finn_chapters, 'Huck')
])
# Plot the cumulative counts :
#how many times in Chapter 1, how many times in Chapters 1 and 2, and so on.
cum_counts = counts_cumsum().with_column('Chapter',np.arange(1, 44, 1)
cum_counts.plot(column_for_xticks=3)
plots.title('Cumulative Number of Times Each Name Appears', y=1.08);
그래서 실제로 Pandas를 통해 분석해본 결과는 이렇다
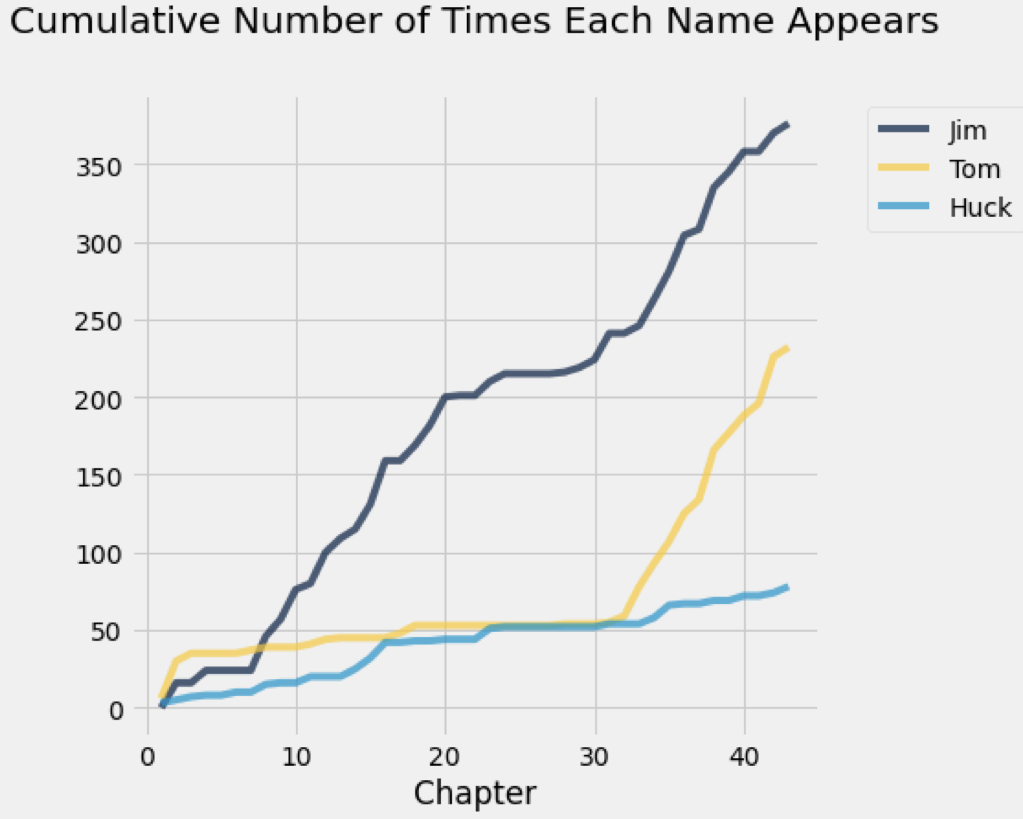
허클베리핀의 모험이란 소설에는 Huck이 주인공인데 Huck이란 이름의 빈도수가 높지 않은걸 확인할 수 있다. Huck이 주인공이기 때문에 1인칭 주인공 시점에서 Jim과 Tom를 바라보기 때문에 당연한 결과라고 할 수 있다.
Another Kind of Character
실제로, 이러한 양(Quantities)들 간의 관계는 다양한 예측을 야기할 수 있다. 불완전한 정보를 기반으로 정확한 예측을 만들고, 불특정 다수의 정보들의 결합을 통해 결과값이나 결정들을 하기 위한 방법들을 개발 및 발전시킬 수 있다.
다음은 'The Adventures of Huckleberry Finn'과 'Little Women'이란 책들 속에 문자의 길이와 마침표의 수를 분석하는 Python코드다. 역시나 추후에 제대로 분석할 예정이니 참고만 바란다.
chars_periods_huck_finn = Table().with_columns([
'Huck Finn Chapter Length', [len(s) for s in huck_finn_chapters],
'Number of Periods', np.char.count(huck_finn.chapters, '.') ])
chars_periods_little_women = Table().with_columns([
'Little Women Chapter Length', [len(s) for s in little_women_chapters],
'Number of Periods', np.char.count(little_women.chapters, '.') ])
그래서 각각 Table로 결과값을 보자면
chars_periods_huck_finn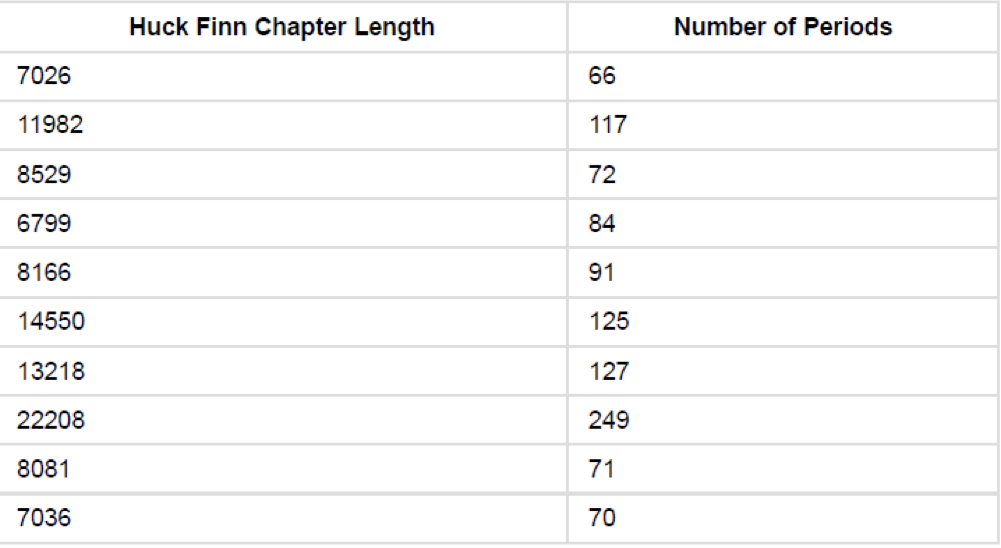
chars_periods_little_women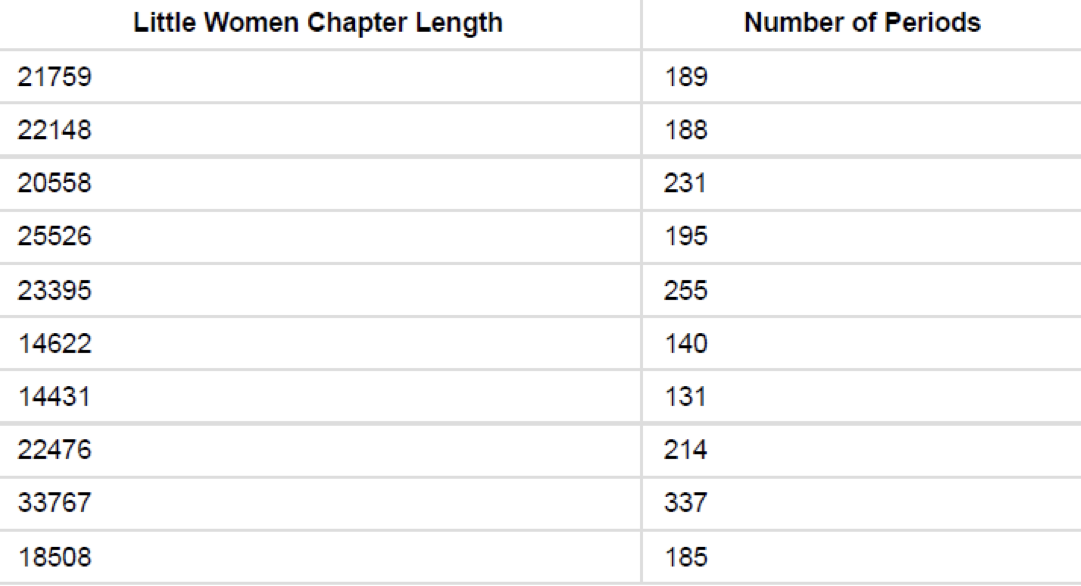
두 개의 표를 분석하면 거의 2~3배 차이로 'Little Women'의 길이가 길고 마침표의 숫자도 많다. 그렇다면 이 두 개의 표를 plot으로 합쳐서 비교해보면 다른 결과값도 알아낼 수 있을까? 한번 알아보자.
Visualization code
plots.figure(figsize(6, 6))
plots.scatter(chars_periods_huck_finn.column(1),
chars_periods_huck_finn.column(0),
color='darkblue')
plots.scatter(chars_periods_little_women.column(1),
chars_periods_little_women.column(0),
color='gold')
plots.xlabel('Number of periods in chapter')
plots.ylabel('Number of characters in chapter');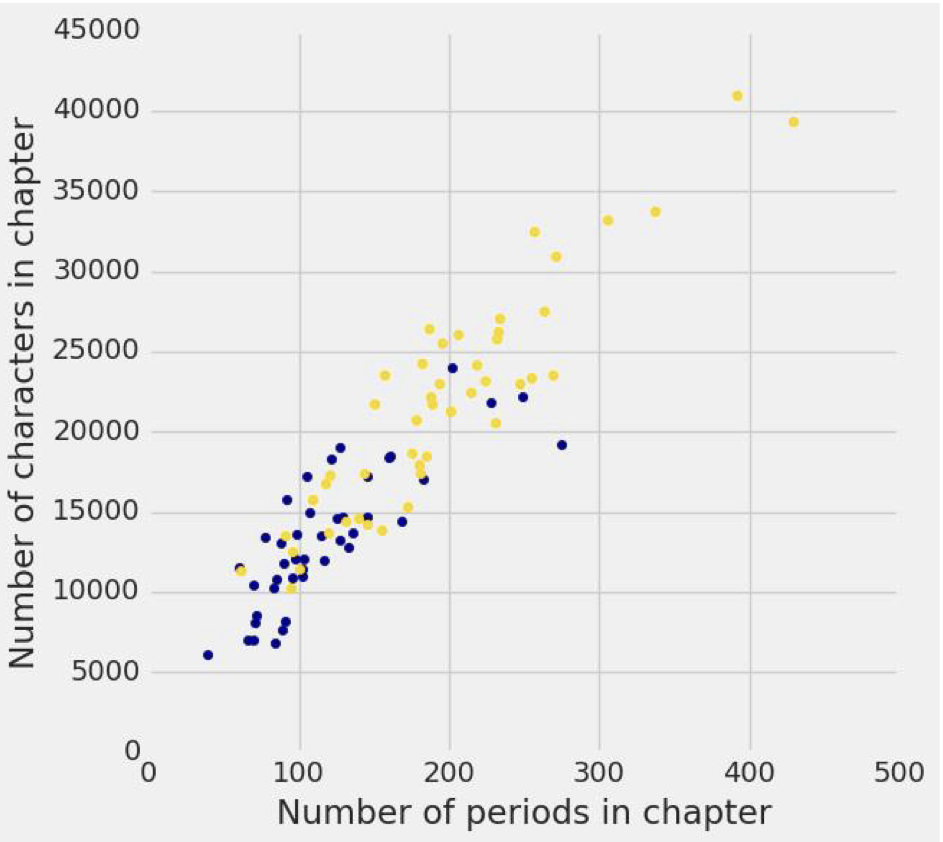
Scatter plot(산점도)로 표현해보면 총글자수와 마침표의 수가 정비례하면서 증가하는 추이를 볼 수 있다. 그래서 이를 자세히 분석해보면 두 개의 책 모두 100~150자 당 하나의 마침표를 쓴다고 분석할 수 있다. 이렇게 데이터 분석이 이루어진다는 것을 확인할 수 있다.
이러한 결과를 토대로, 현재 X(이전 트위터)에서 140자 제한을 걸었던 것도 이를 통해 분석한 결과를 보고 도입하지 않았을까란 생각이다.
