
이번 글에선 '데이터과학기초'란 과목에서 Pandas를 다루기 때문에 그거에 대한 기초적인 부분을 다룰겸 적어보겠다. 아직 배워가는 과정이라 틀린부분이 있을 수 있기 때문에 이해바란다.
Pandas란?
- 데이터를 효과적으로 처리하고, 보여줄 수 있도록 도와주는 라이브러리
- Numpy와 함께 사용되어 다양한 연계적인 기능을 제공
- 인덱스(Index)에 따라 데이터를 나열하므로 사전(Dictionary) 자료형에 비교적 가까운 편이다.
- 시리즈(Series)를 기본적인 자료형으로 사용한다.
시리즈(Series) : 인덱스와 값으로 구성된다.
Core components of pandas
Pandas의 핵심요소는 Series와 DataFrame이라고 할 수 있다.
Series는 기본적인 column이고, DataFrame은 Series 여러 개가 합쳐진 다차원의 table이라고 할 수 있다.
Basic of Pandas - Series
간단한 예시를 보여주겠다.
import pandas as pd
array = pd.Series(['사과', '바나나', '당근'], index = ['a', 'b', 'c'])
print(array)
print(array['a'])
array이렇게 하면 출력결과는 다음과 같다.
a 사과
b 바나나
c 당근
dtype: object
사과
a 사과
b 바나나
c 당근
dtype: object그렇다. 문법 및 작성형식은 python과 동일한 형식으로 print(array)와 array는 동일한 형식의 출력을, print(array['a'])라고 하면 index a에 저장된 '사과'를 출력하는 결과를 얻을 수 있다.
또한 pd.Series()로 따로 정의를 하지 않으면, 일반 Dict 자료형으로 저장되는데 이를 Series로 바꾸는 방법은 다음과 같다.
import pandas as pd
data = {
'a' : '사과'
'b' : '바나나'
'c' : '당근'
}
#Dict 자료형을 Series로 바꾸기
array = pd.Series(data)
print(array['a'])
array사과
a 사과
b 바나나
c 당근
dtype: object이렇게 하면 Dict 자료형에 저장된 index a,b,c가 Series로 자료형이 바뀐것을 확인할 수 있다.
Basic of Pandas - DataFrame
처음에 설명했듯이, DataFrame은 Series의 집합체다. 그러면 곰곰히 생각해보면 충분히 응용가능한 부분이다.
간단한 예시는 다음과 같다.
import pandas as pd
word_dict = {
'Apple' : '사과',
'Banana' : '바나나',
'Carrot' : '당근'
}
frequency_dict = {
'Apple' : 3,
'Banana' : 5,
'Carrot' : 7
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
#이름(Name) : 값(Values)
summary = pd.DataFrame({
'word' : word,
'frequency' : frequency
})
print(summary) word frequency
Apple 사과 3
Banana 바나나 5
Carrot 당근 7이렇게 Dict 자료형으로 word와 frequency를 생성한 후 Series를 생성해 Dict 자료형을 Series로 변환한 후, Series들을 DataFrame에 넣어서 DataFrame을 생성하였다.
그러면 DataFrame은 처음부터 정의하는게 안될까?
한번에 정의하는 법은 다음과 같다.
import pandas as pd
data = {
'apples' : [3, 2, 0, 1],
'orange' : [0, 3, 7, 2]
}
purchases = pd.DataFrame(data)
purchases apples oranges
0 3 0
1 2 3
2 0 7
3 1 2이렇게 한번에 선언할 수도 있다. 다음은 이제 응용버전이다.
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David'])
print(purchases) apples oranges
June 3 0
Robert 2 3
Lily 0 7
David 1 2Series의 연산
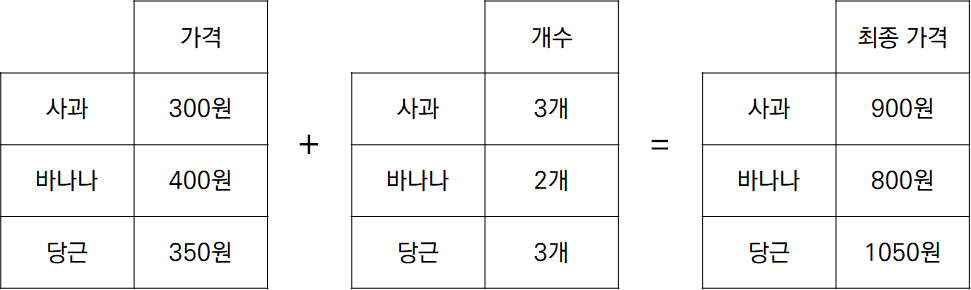
위의 그림을 pandas를 이용하여 나타내어보겠다.
import pandas as pd
word_dict = {
'Apple' : '사과',
'Banana' : '바나나',
'Carrot' : '당근'
}
frequency_dict = {
'Apple' : 3,
'Banana' : 5,
'Carrot' : 7
}
importance_dict = {
'Apple' : 3,
'Banana' : 2,
'Carrot' : 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict_
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word' : word,
'frequency' : frequency,
'importance' : importance
})
score = summary['frequency'] * summary['importance']
summary['score'] = score
print(summary) word frequency importance score
Apple 사과 3 3 9
Banana 바나나 5 2 10
Carrot 당근 7 1 7위와 같은 형태로 결과값이 나온다.
DataFrame에서 Slicing
특히나 DataFrame에선 특정 행렬만 출력되게 설정할 수 있는데, 이를 슬라이싱(Slicing)이라 부른다. 응용형태는 다음과 같다.
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
# 이름을 기준으로 슬라이싱
print(summary.loc['Banana':'Carrot', 'importance':])
# 인덱스를 기준으로 슬라이싱
print(summary.iloc[0:3, 1:]) word frequency importance
Apple 사과 3 3
Banana 바나나 5 2
Carrot 당근 7 1
Durian 두리안 2 1
importance
Banana 2
Carrot 1
frequency importance
Apple 3 3
Banana 5 2
Carrot 7 1이렇게 print(summary.loc['Banana':'Carrot', 'impotance':]) 를 살펴보면
summary.loc이란 명령어를 통해서 슬라이싱할수 있다.
0번째 index부터 탐색하여 'Banana'를 찾으면 'Banana'에서부터 'Carrot'까지 탐색하여 결과값을 도출한다.
그리고 print(summary.iloc[0:3, 1:]) 에서
summary.iloc은 summary.loc와 다르게 index를 정수형으로 찾는다.
그래서 0번째 index에서 3번째 index까지, 1번째 행인 importance의 값을 출력하게 된다.
DataFrame에서 Data 추가/변경하는 방법
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근',
'Durian': '두리안'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7,
'Durian': 2
}
importance_dict = {
'Apple': 3,
'Banana': 2,
'Carrot': 1,
'Durian': 1
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
importance = pd.Series(importance_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency,
'importance': importance
})
print(summary)
print("---------------------------------------------------")
summary.loc['Apple', 'importance'] = 5 # 데이터 변경
summary.loc['Elderberry'] = ['엘더베리', 5, 3] # 새 데이터 삽입
print(summary) word frequency importance
Apple 사과 3 3
Banana 바나나 5 2
Carrot 당근 7 1
Durian 두리안 2 1
---------------------------------------------------
word frequency importance
Apple 사과 3 5
Banana 바나나 5 2
Carrot 당근 7 1
Durian 두리안 2 1
Elderberry 엘더베리 5 3summary.loc['Apple', 'importance'] = 5
를 우선 살펴보면 Apple의 importance를 5로 바꾸는 것을 확인할 수 있다.
그리고
summary.loc['Elderberry'] = ['엘더베리', 5, 3]
를 살펴보면 현재 index에 Elderberry를 추가하고 현재 column에 저장된 정보에 맞게 'word' = '엘더베리', 'frequency' = 5, impotance = 3
를 등록하는 부분을 출력결과를 통해 볼 수 있다.
Excel로 내보내기/불러오기
import pandas as pd
word_dict = {
'Apple': '사과',
'Banana': '바나나',
'Carrot': '당근'
}
frequency_dict = {
'Apple': 3,
'Banana': 5,
'Carrot': 7
}
word = pd.Series(word_dict)
frequency = pd.Series(frequency_dict)
summary = pd.DataFrame({
'word': word,
'frequency': frequency
})
summary.to_csv("summary.csv", encoding="utf-8-sig")
saved = pd.read_csv("summary.csv", index_col=0)
print(saved) word frequency
Apple 사과 3
Banana 바나나 5
Carrot 당근 7위의 출력결과를 확인해보면,
summary.to_csv("summary.csv", encoding="utf-8-sig")
를 통해서 summary.csv라는 Excel파일을 저장한다.
또한 saved라는 변수를 통해서 summary.csv에 저장된 Excel정보를 불러오게 된다.
