- 계산된 필드와 기본 계산
- 계산된 필드 오류 해결과 집계 방식
- 테이블 계산
- LOD 표현식
계산된 필드로 할 수 있는 것
-
데이터 소스에서 새로운 칼럼 생성 (Create)
-> 에디터에 필드를 끌어다 놓기
-> 함수 더블클릭으로 식 자동완성 -
새롭게 추가된 컬럼을 저장 (Save)
-> 식을 필드로 드래그하여 저장 가능 -
새롭게 추가된 컬럼을 분석에 사용 (Use)
-> 계산된 필드를 분석에 사용
기본 계산의 방식
-
행 수준 계산, 집계 계산
-
숫자, 문자열, 날짜, 유형 변환(숫자형 -> 문자형), 논리 함수 (if-else & case), 집계 함수 ( countd * )
계산된 필드 오류 해결
-
집계되지 않은 인수 혼합
ex) SUM(profit)/sales
- 집계된 것과 집계되지 않은것의 혼합으로 오류 발생
- SUM(profit)/SUM(sales) or profit / sales 로 수정
-
IF 식에서 집계 및 집계되지 않은 비교 또는 결과 혼합
ex) IF [Region] = "West" THEN SUM([Sales]) END
- west의 총 매출액
- SUM(IF [Region] = "West" THEN [Sales] END) 으로 수정
ex) IF [Order Date] = #2022-06-28# then COUNTD ([Customer Name]) END
- 주문 일자별 주문 고객 수 집계
- 집계되지 않은 주문일자와 집계된 고객명 결과 혼합으로 에러 발생
- IF ATTR([Order Date]) = #2022-06-28# then COUNTD ([Customer Name])
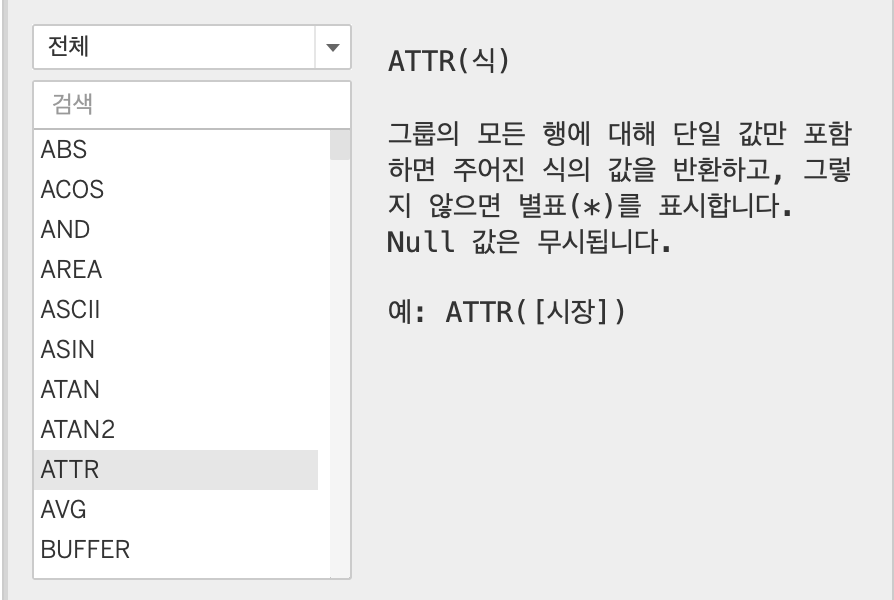
차원과 측정값의 집계
- 차원 집계 5종
- MIN
- MAX
- COUNT
- COUNTD
- ATTR
- 측정값 집계
- SUM
- AVG
- VAR
- VARP
- 등등
테이블 계산
현재 Visualization에 표시된 항목을 기반으로 계산 ( LOOKUP | RANK | RUNNING | WINDOW )
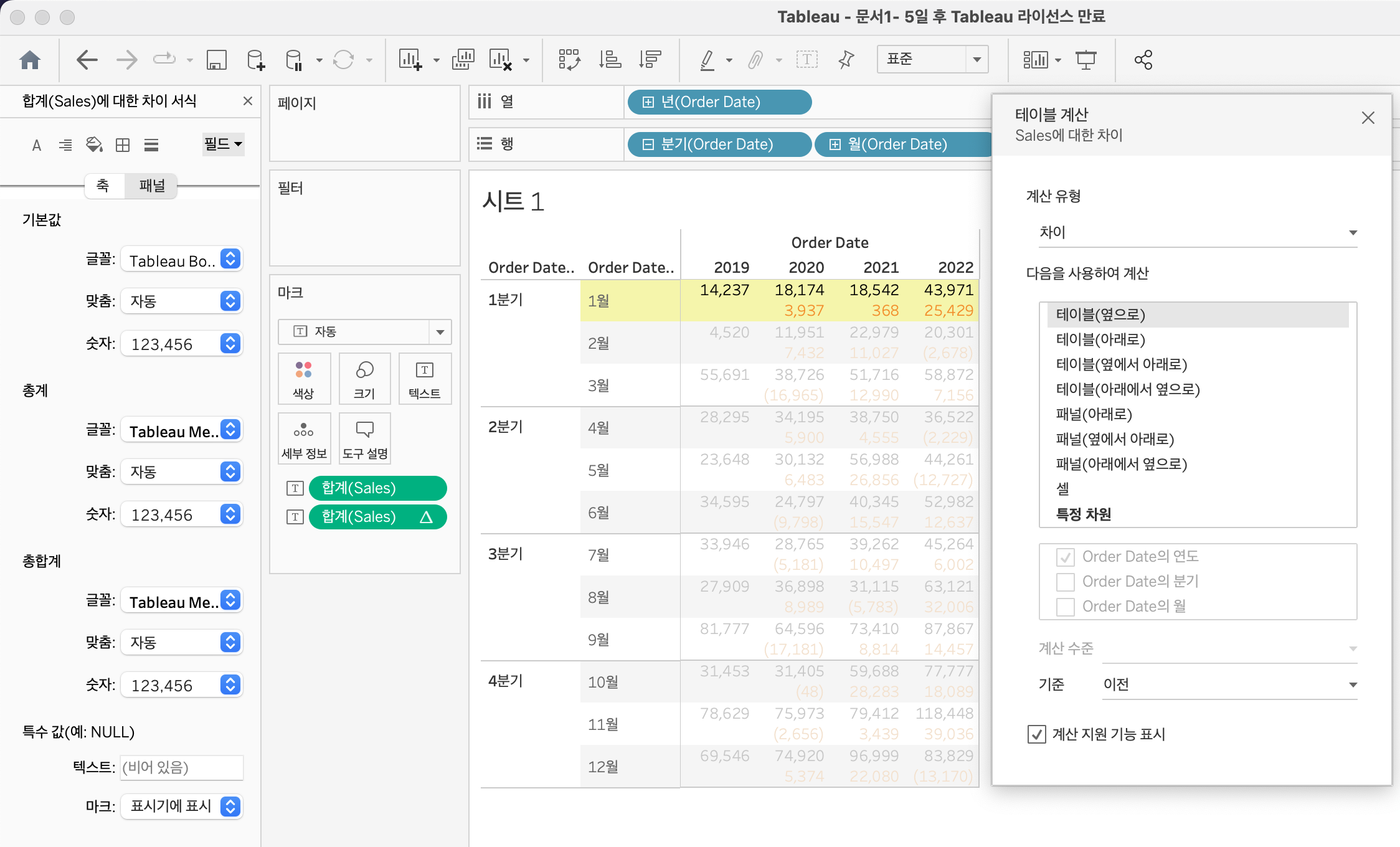
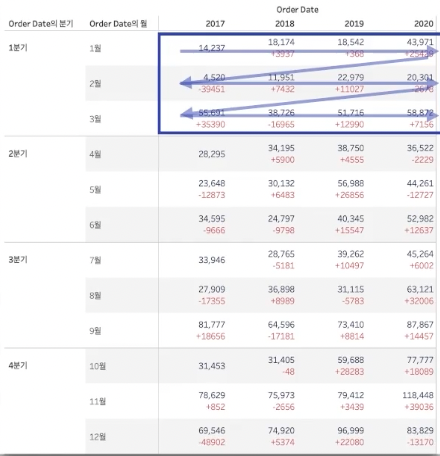
위 사진에서는 테이블 옆으로 를 선택하고 연도 단위에 체크했기 때문에 좌우의 차이를 계산하고 노란색 색칠된 년단위 계산후 계산을 마친 뒤, 아래 행 계산을 새롭게 시작한다.
만약테이블 옆에서 아래로 를 선택하고 연,분기,월 을 모두 선택했다면 아래 사진과 같은 계산 흐름을 갖게된다.
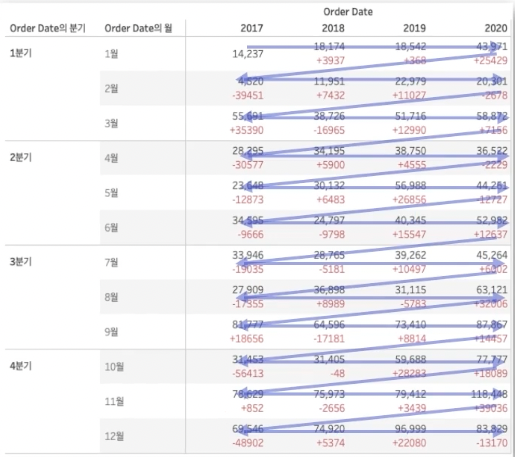
만약테이블 옆에서 아래로 를 선택하고 연,월 만 선택했다면 아래 사진과 같은 계산 흐름을 갖게된다.
즉, 계산을 다시 시작하는 기준을 정하는 것이다.
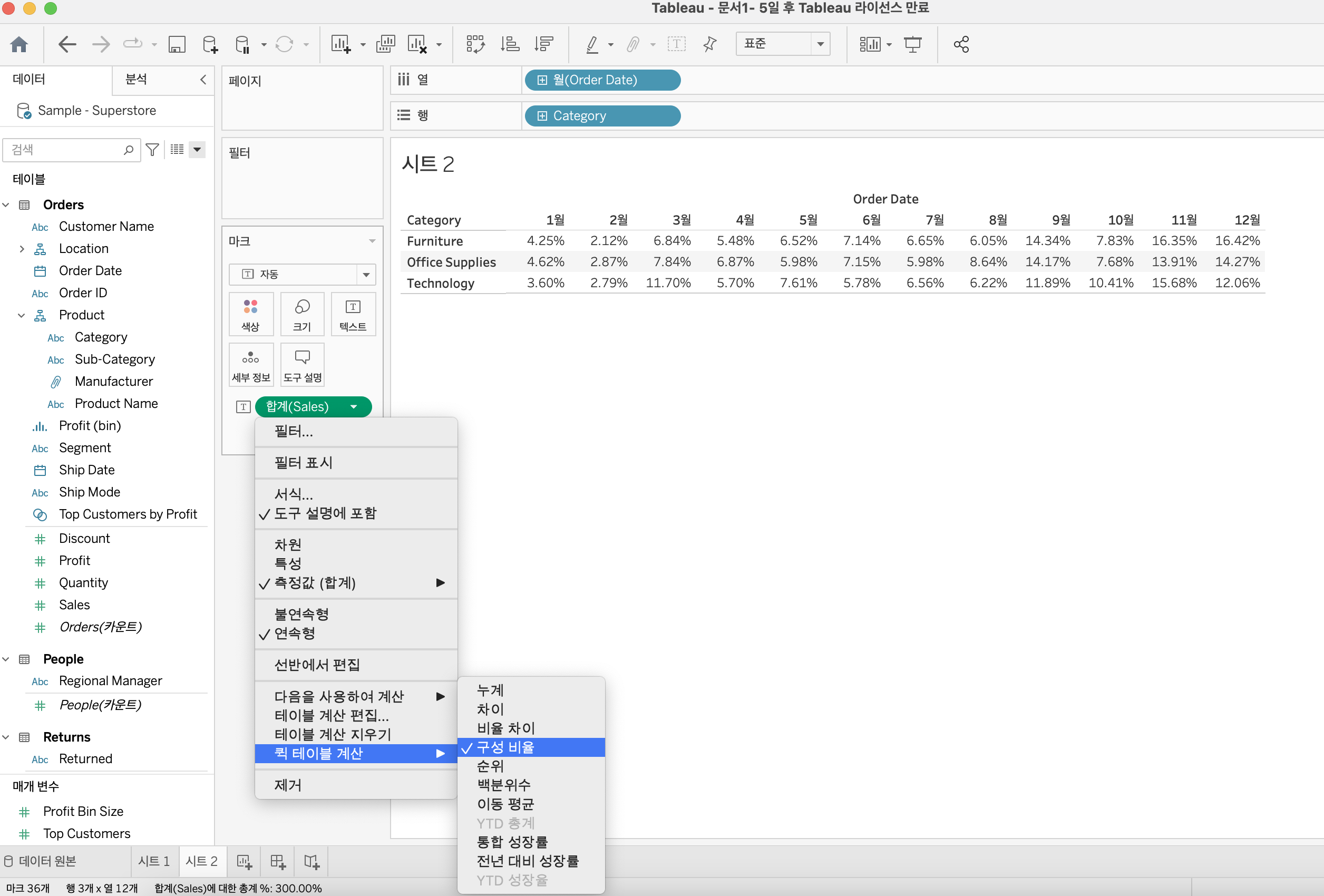
퀵 테이블 계산
자주 쓰이는 테이블 계산을 쉽게 쓸 수 있도록 미리 저장해둔것.
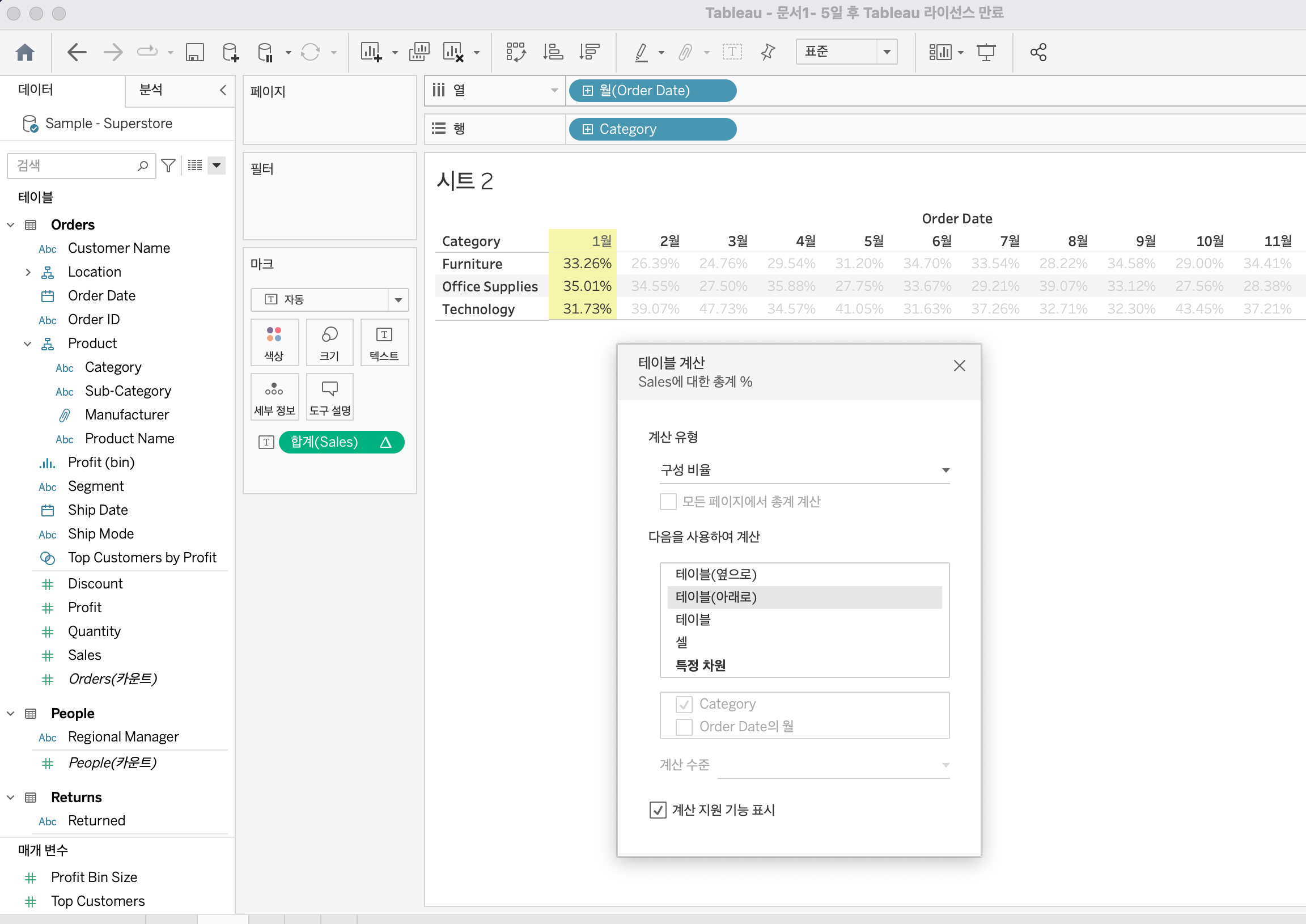
카테고리별 월단위 매출액을 구성비율로 퀵테이블계산한 결과이다. 테이블(옆으로) 설정이 기본으로 되어있지만 테이블 편집을 통해 월별 구성비율을 볼수 있도록 편집할 수 있다.
테이블 계산의 종류
-
Partition

-
Running
괄호 안에는 집계된 값이 들어가야한다. ex) RUNNING_AVG(SUM([sales]))

-
Window
Running 함수와 다르게 시작위치와 끝 위치를 지정할 수 있다.

-
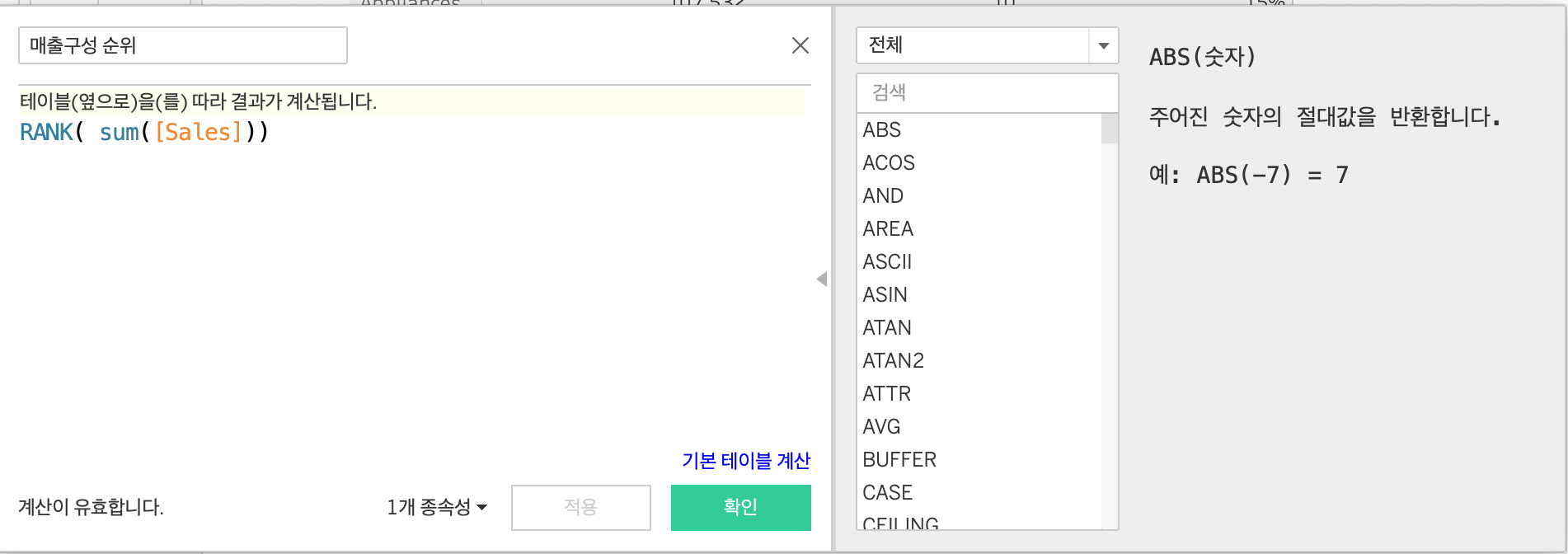
Rank
집계된 필드의 순위를 반환한다.

테이블 계산의 활용
- 구성 비율과 순위
- Rank() 함수의 이용
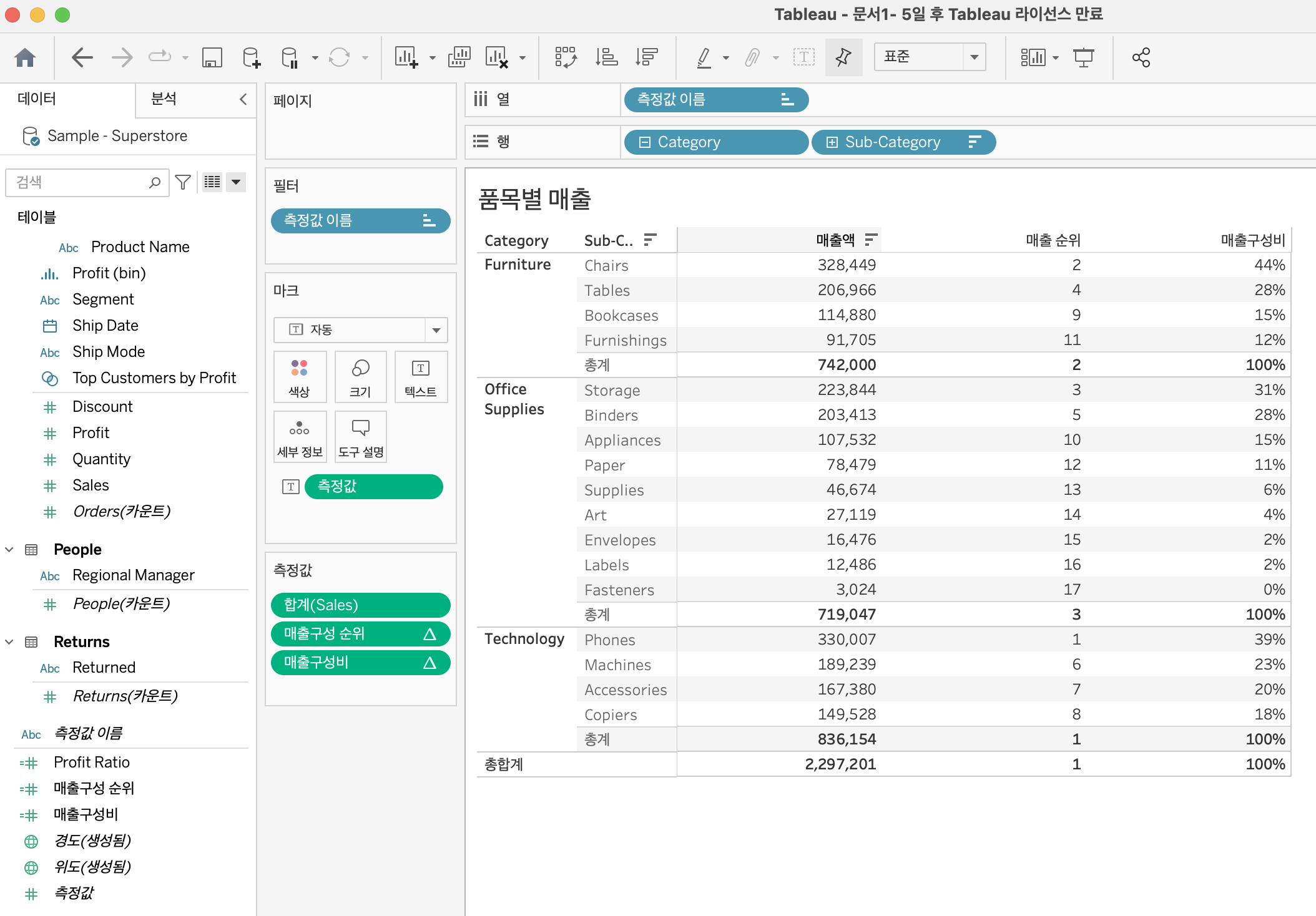
느낀점
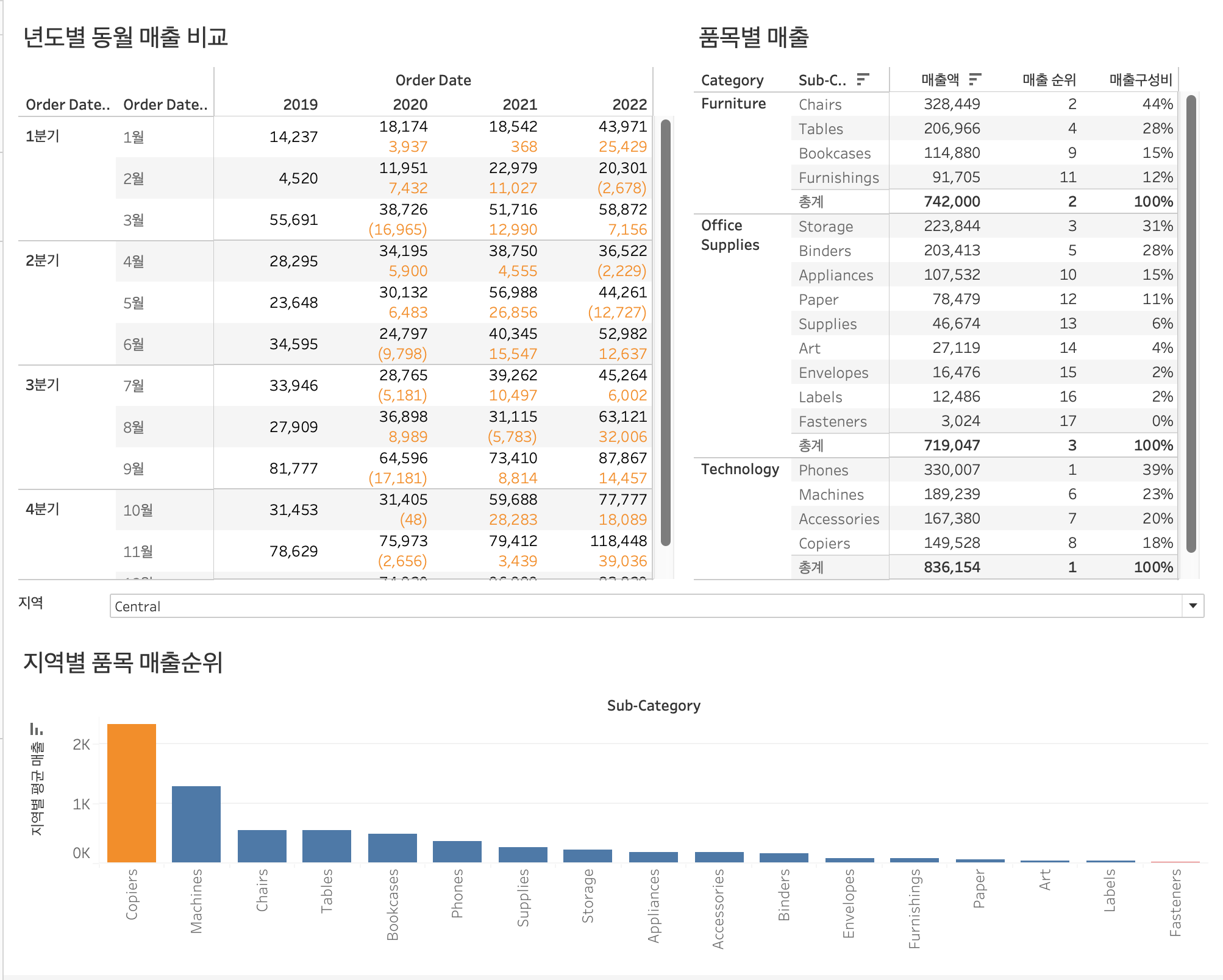
이커머스 업체처럼 다양한 품목을 판매하는 기업에서는 항상 궁금한 데이터일듯 하다. 상품 하위 카테고리별 매출액과 상위 카테고리 단위에서 매출 구성비, 전체 품목에서 매출 순위를 표시했다. 인터렉티브 대쉬보드를 활용해 하위 카테고리에서 다시 세부 품목(품목 아이디별)으로 조회할 수 있으면 가장 잘 팔린 아이템을 개별적으로 뽑을 수 있어 MD의 성과나 제거해야할 품목 등을 확인할 때 좋은 데이터가 될 것 같다.
- 최대 / 최소 카테고리
- 매개변수와 WINDOW 함수 활용
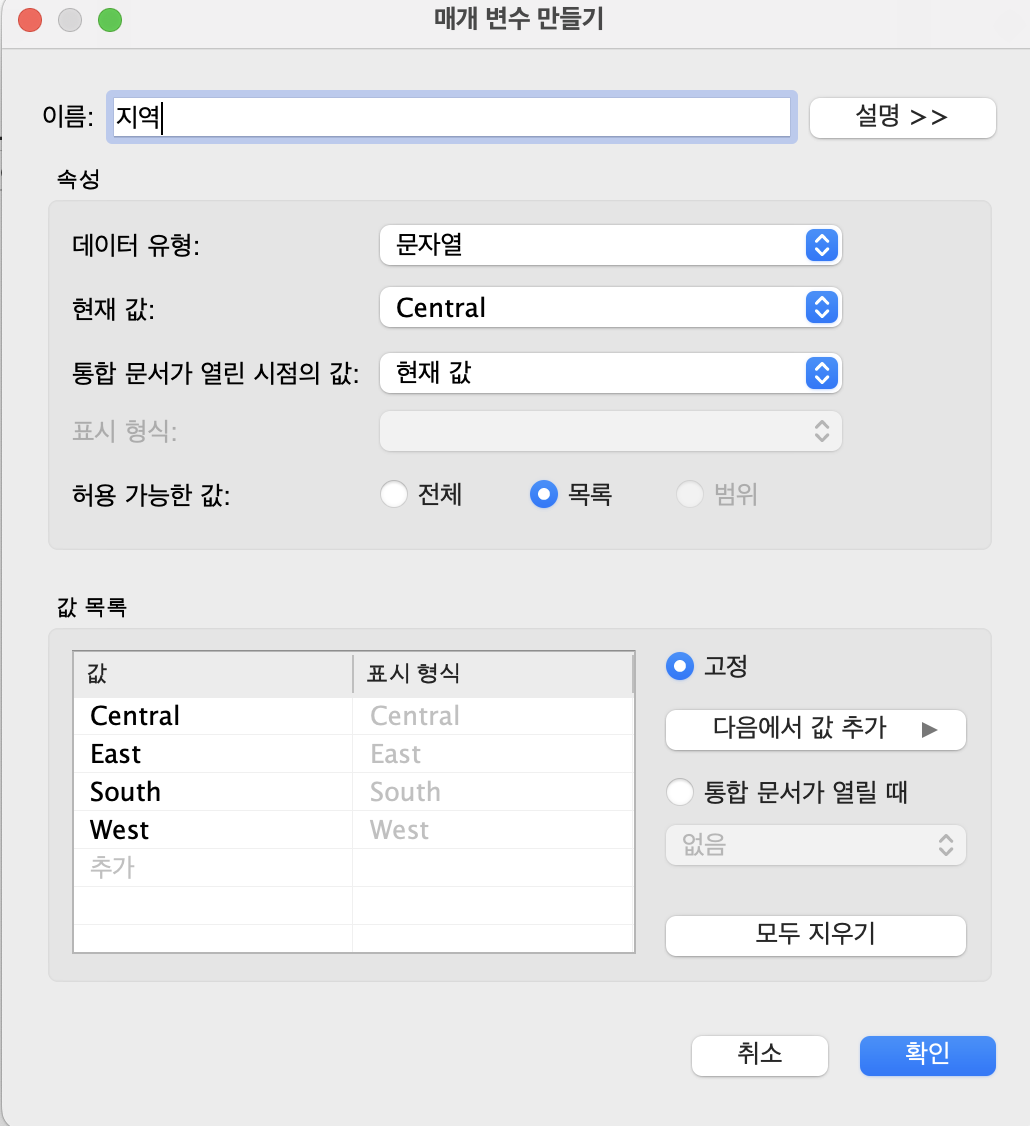
지역별로 선택하여 데이터 결과를 바꿔볼 수 있도록 지역을 매개변수로 만든다.
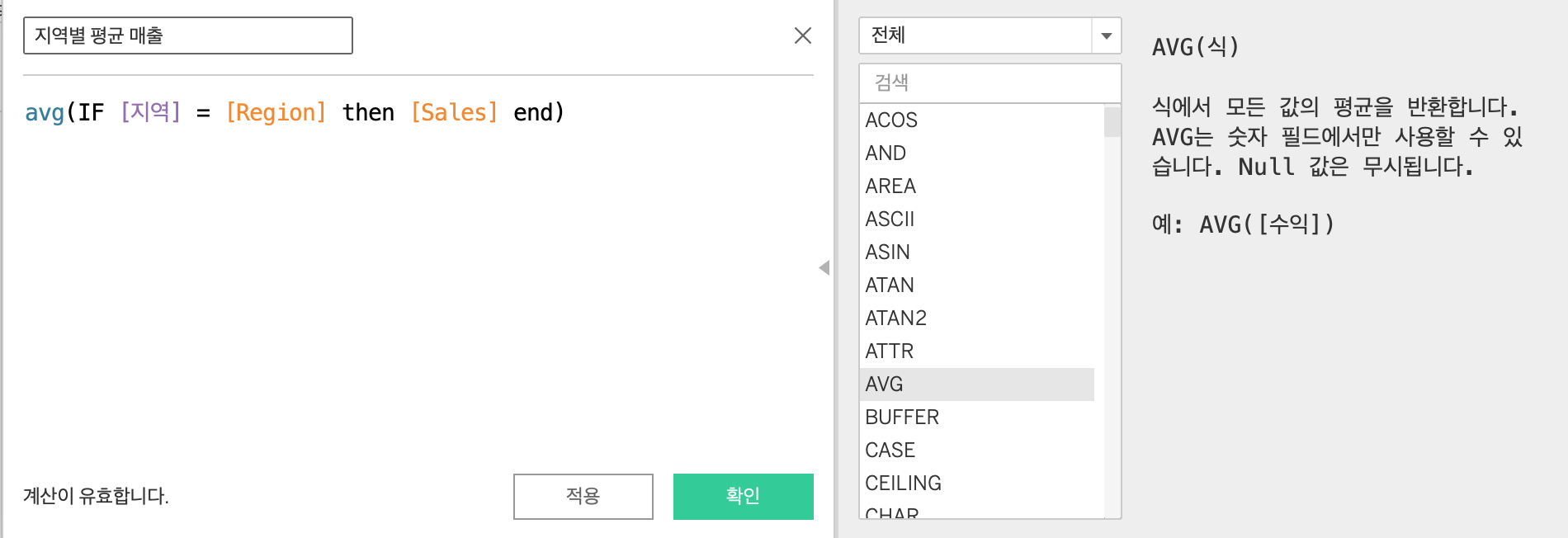
만든 매개변수를 활용하기 위해서는 항상 계산된필드와 함께 사용해야한다. 여기서는 선택된 지역의 sales 평균을 반환하도록 만들었다.
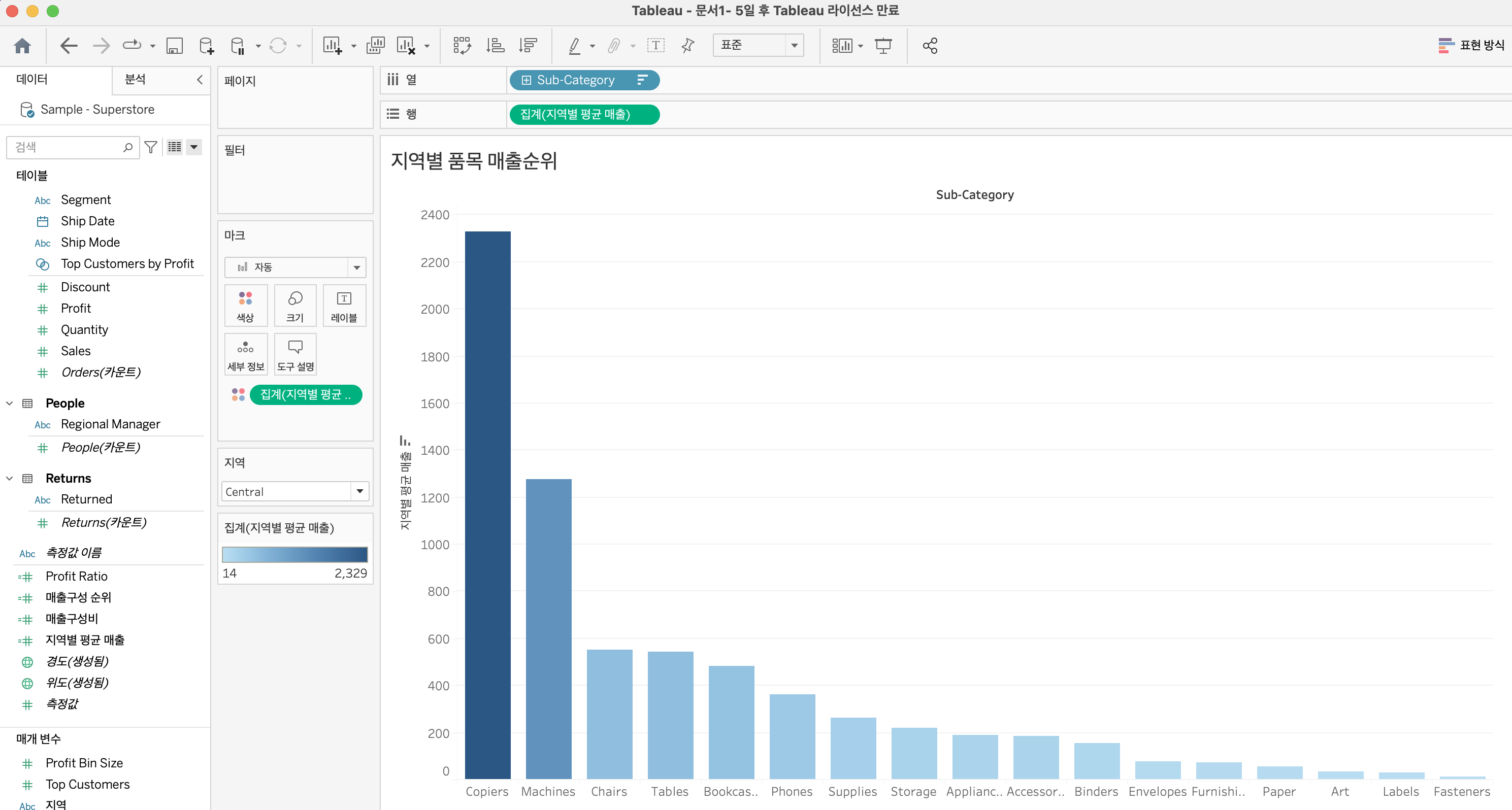
위처럼 단계별 색상을 통해 높은 순위의 품목을 보여주는 것도 좋지만 조금 더 강조를 하기 위해 최고 매출 품목과 최저 매출 품목에만 색을 주려고 한다.
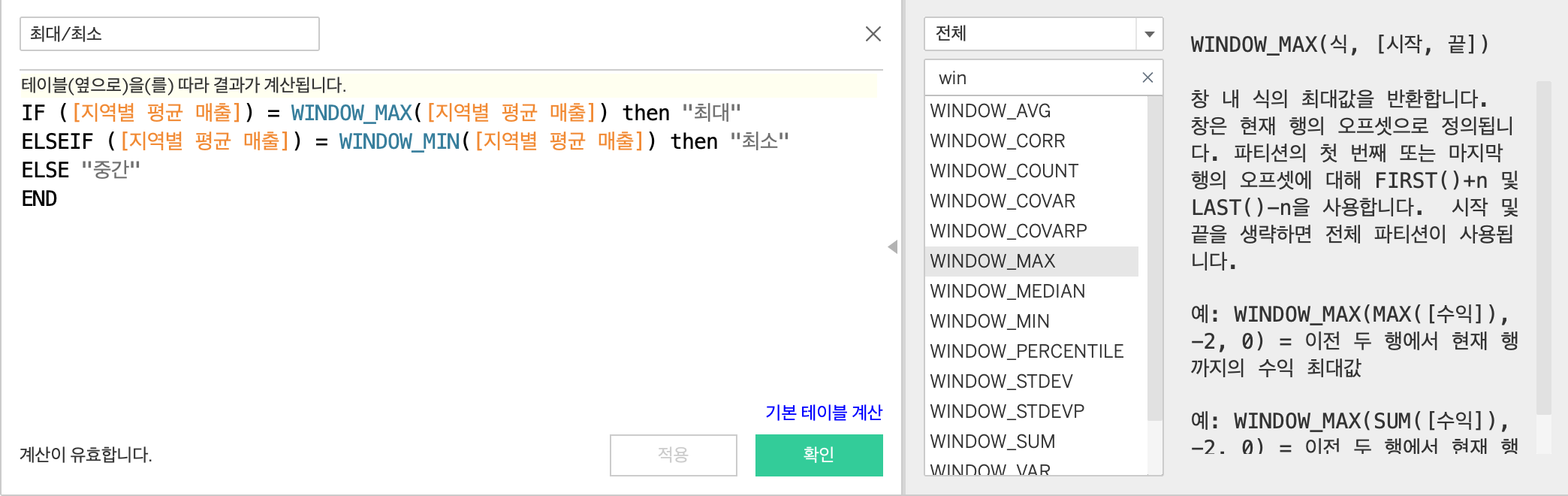
위처럼 창 내의 최대 / 최소값을 구분하는 차원을 만들어놓고 색상카드에 드래그하면 최종적으로 아래와 같은 결과를 얻을 수 있다.
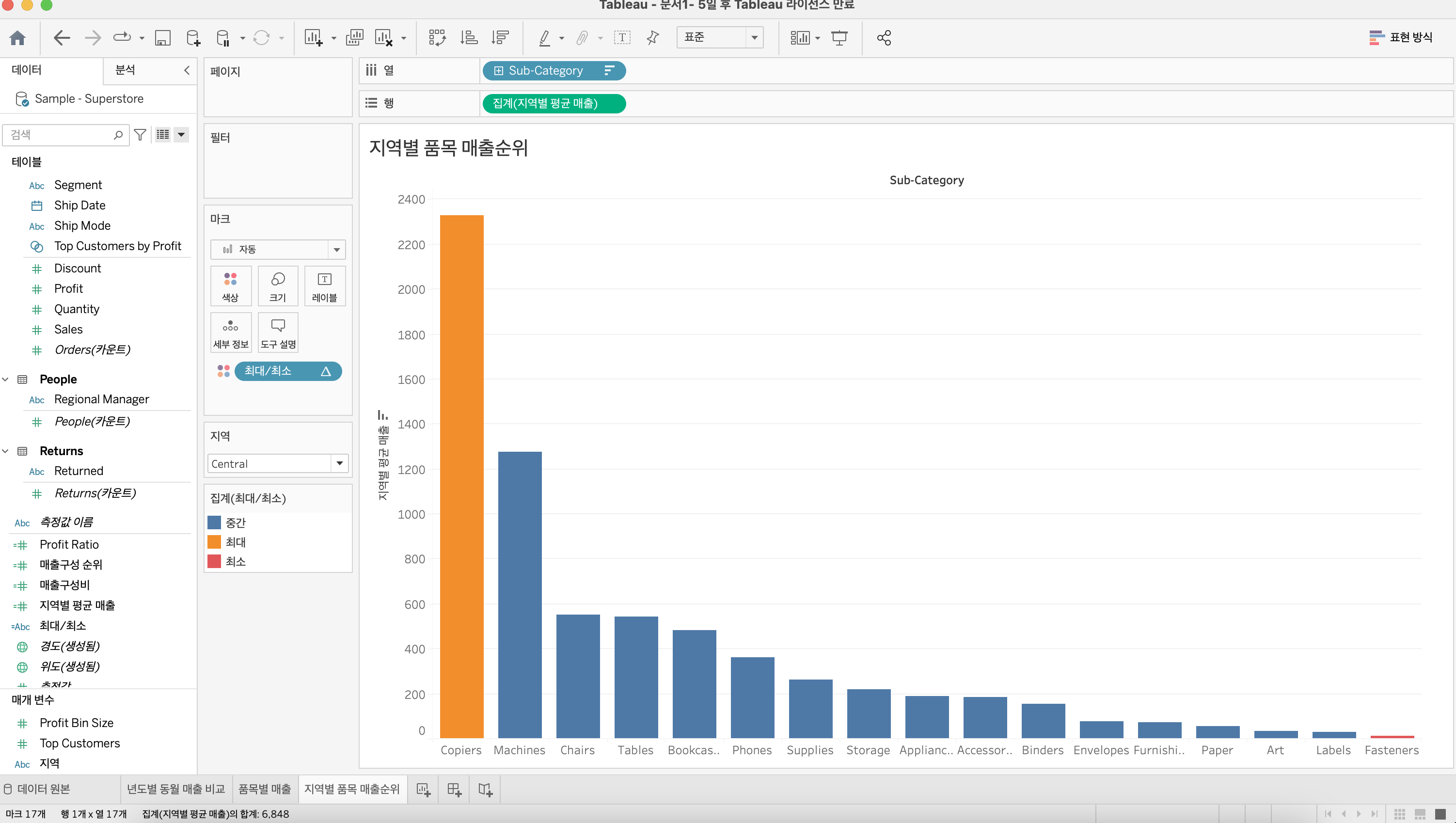
느낀점
물류 역량을 베이스로 하는 이커머스 업체에서 지역별 매출 품목 순위를 파악하는 것은 웨어하우스 관리에 아주 중요한 지표가 될 수 있을것 같다. 잘 팔리지 않는 품목을 구지 창고에 재고로 남겨둘 필요가 전혀 없기 때문이다. 또한 수요가 많은 품목을 창고에 미리 보관 함으로써 배송기간을 단축시켜 고객 만족도를 높히고 창고 내에 품목 순환이 잘 되게 할 수 있다.
이러한 품목에 대해서는 더 세부적인 분석을 하는게 좋을 것이다. 가령 각 지역의 일자별 주문량 등을 미리 예상할 수 있도록 한다던지 하는 것이다. 결국엔 머신러닝을 배워야 하는걸까 ? ^^;;
최종 대시보드