
데이터 준비하기
- 데이터 시각화를 위한 탐색, 전처리, 결합은 매우 중요하다.
-
태블로에 올리기 위한 데이터 Shape 만들기 (피벗)
wide form data vs long form data
1) 데이터 해석기 사용 : 데이터를 태블로로 불러왔을때 컬럼명 등을 제대로 읽지 못하는 경우 사용
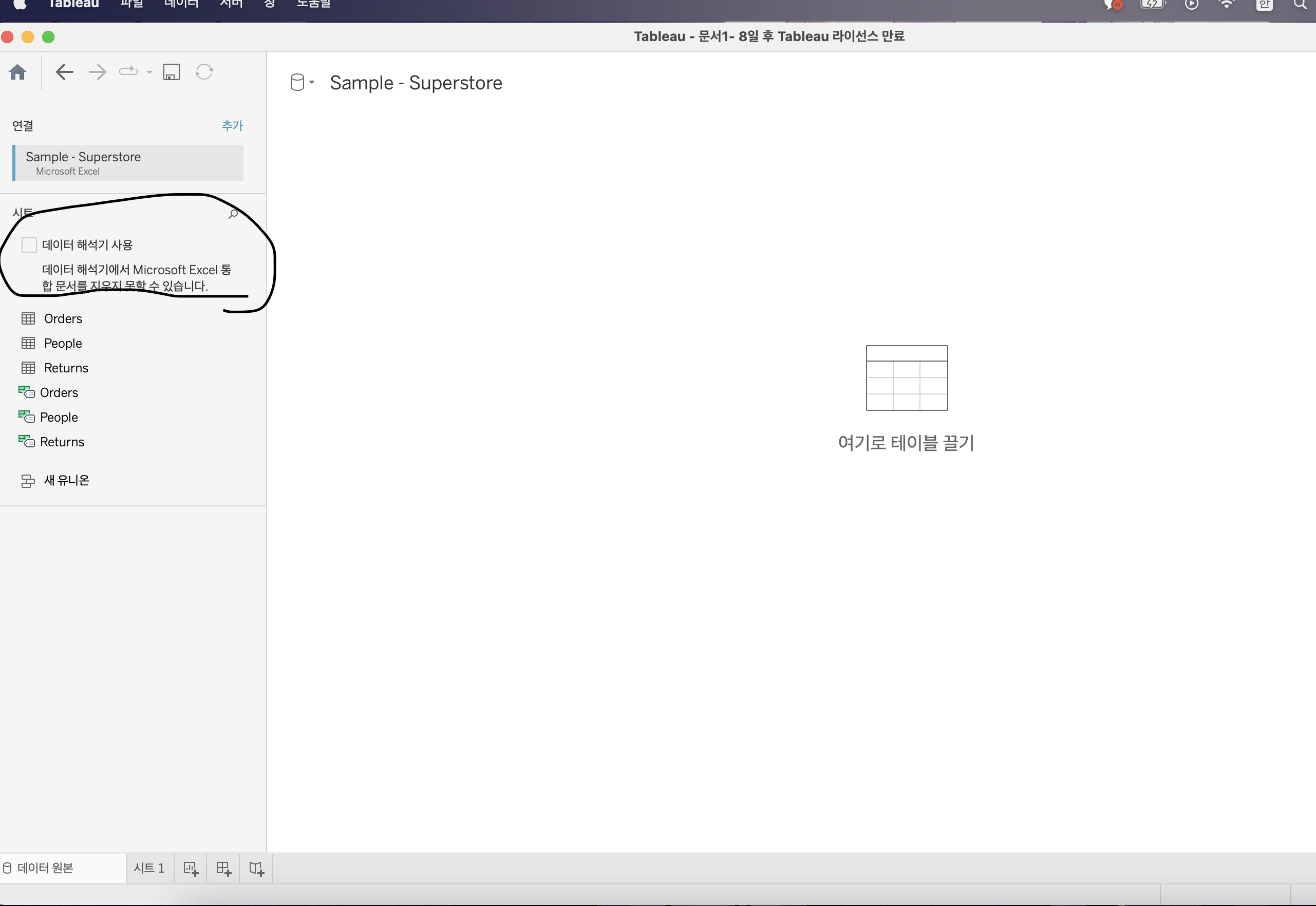
-> 태블로가 제대로 인식 가능한 데이터 or 2000 컬럼 이상의 데이터 or 3000로우 & 150컬럼 이상인 데이터는 데이터 해석기 사용 불가
2) 하나의 컬럼이 하나의 속성을 나타내게 한다 : 피벗을 사용하여 가로형 데이터를 세로형으로 변경
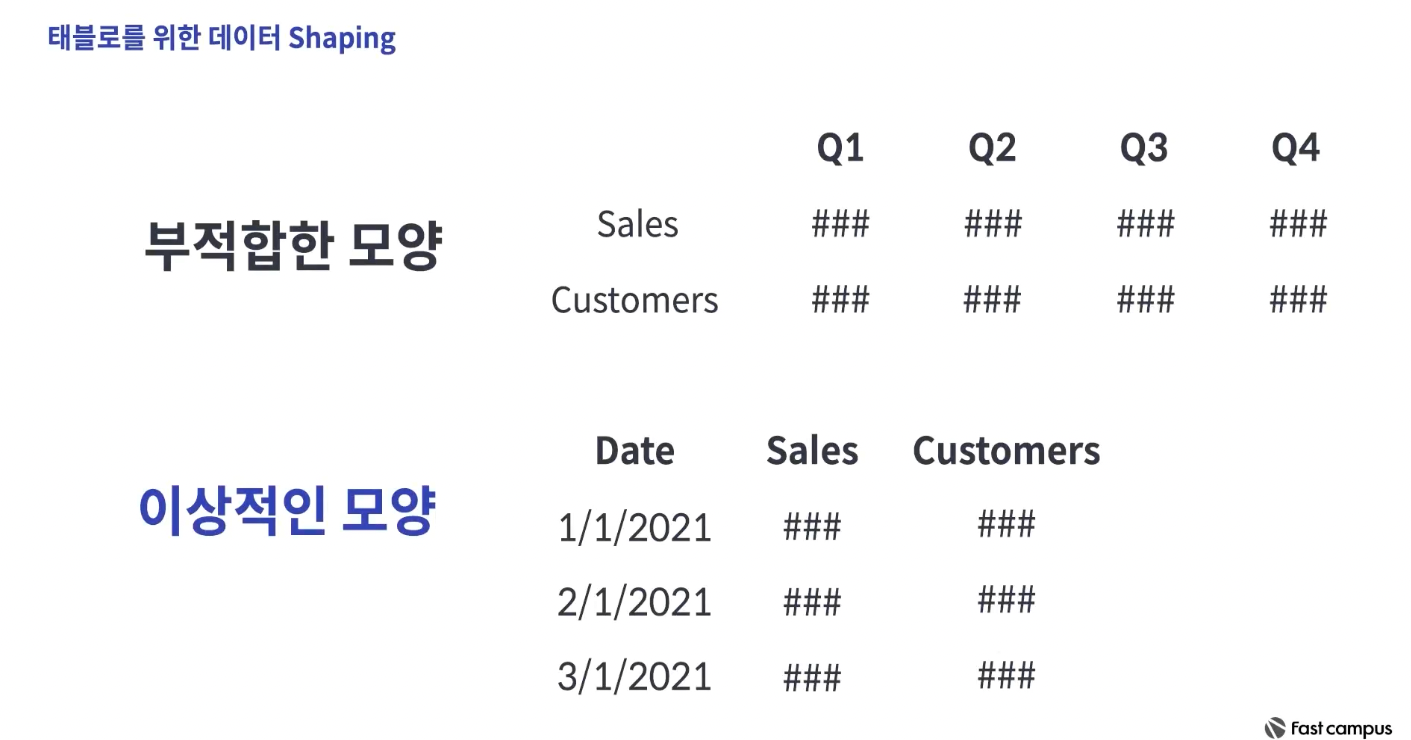
-
데이터 탐색 방법
데이터를 시각화 전 체크리스트
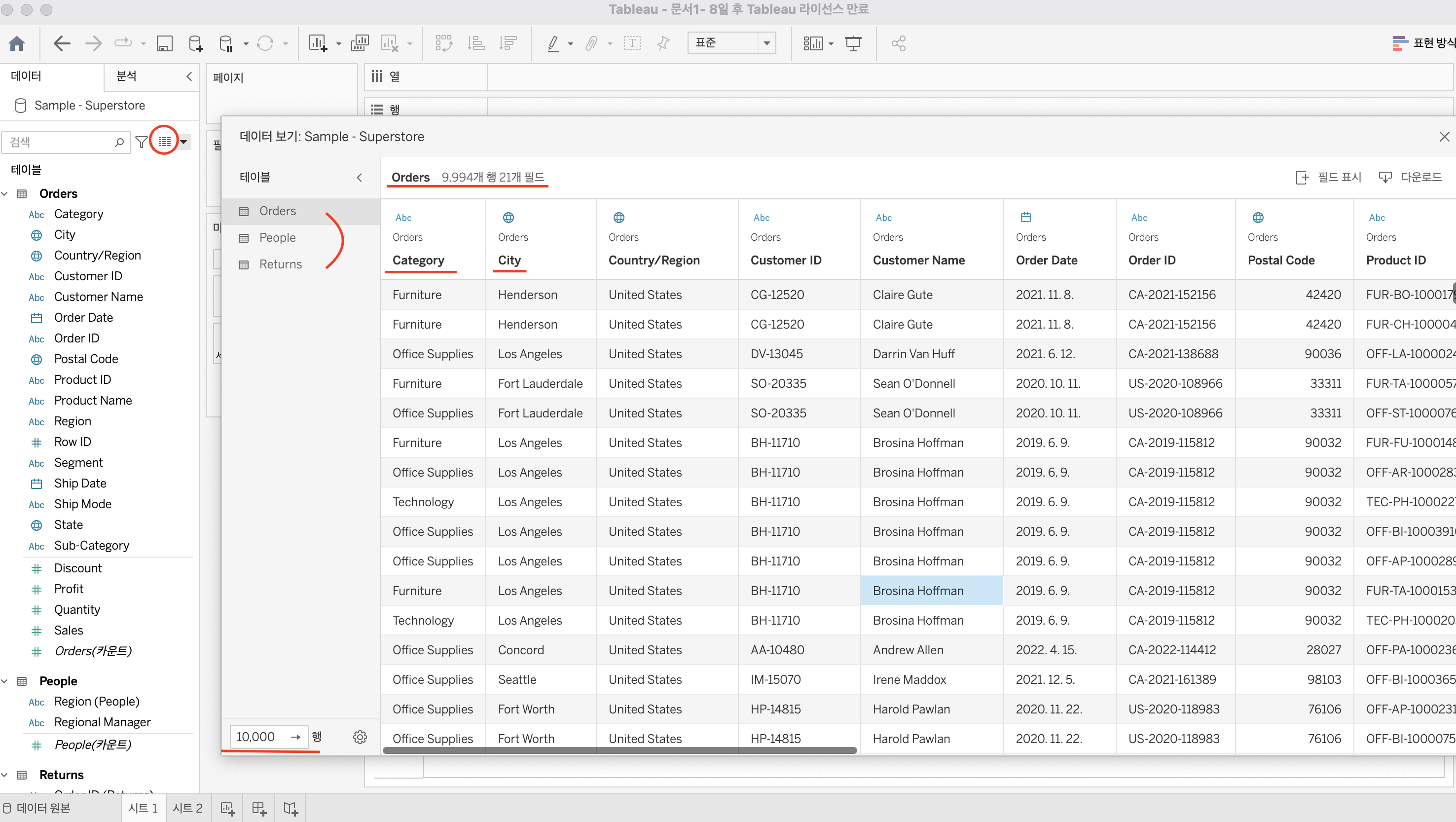
1) 데이터 보기
데이터 보기를 클릭하여 전체 데이터의 수, 로우의 수, 컬럼명 등을 확인하여 분석하고자 하는 데이터를 맞게 불러왔는지 검증해야한다. 만약 다르다면 데이터를 불러오기 위한 SQL 쿼리문 오류를 체크하거나 엔지니어와 해당 건에 대해 논의하는 등 작업이 필요할것이다.
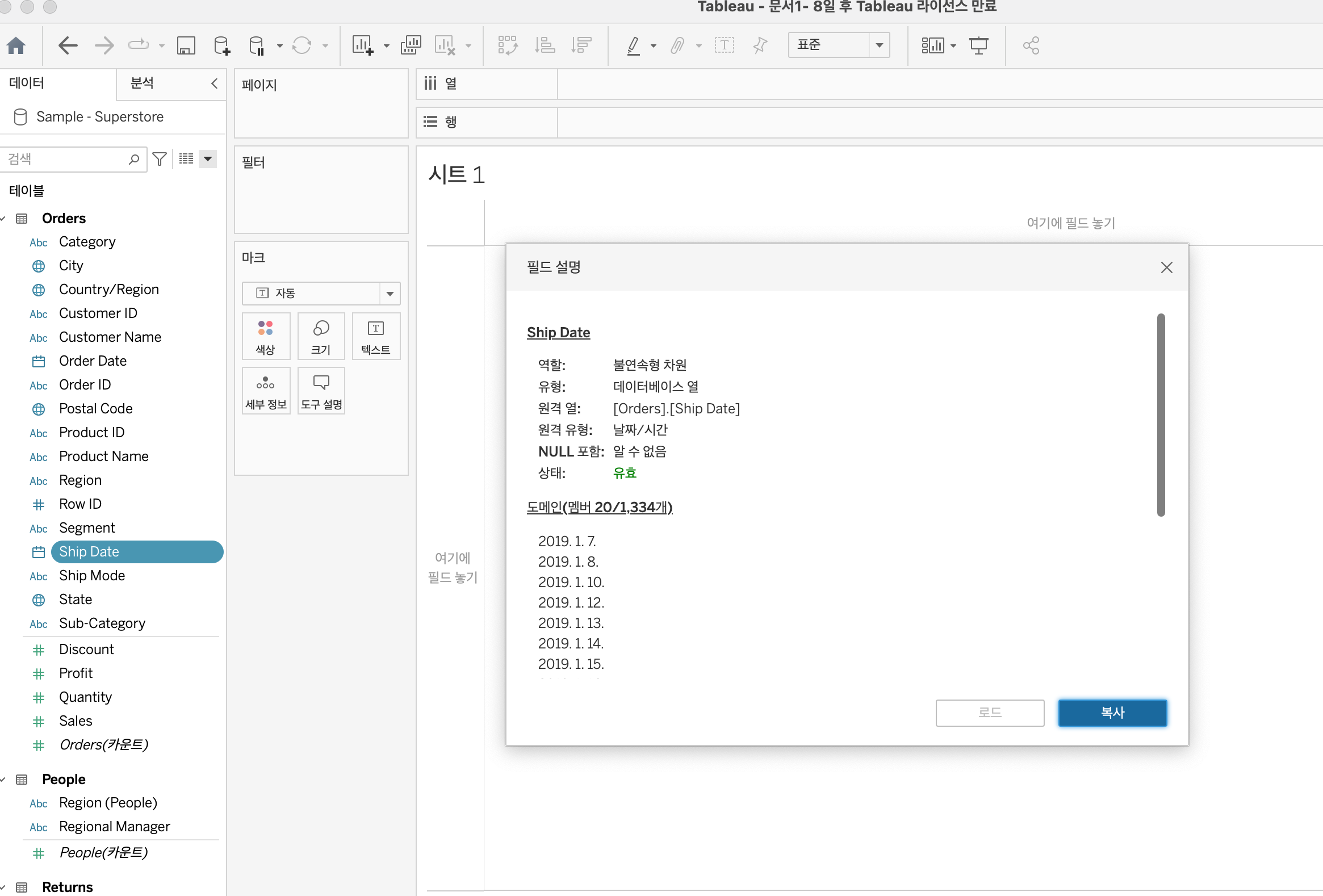
2) 필드 설명 보기
다음으로는 데이터 레이블을 우클릭 -> 설명 으로 들어가 필드 설명을 확인하는게 좋다. 역할과 유형, 도메인 등을 미리 확인할 수 있다.
3) 차원과 측정값 분류
차원은 집계되지 않는것 ( 연산하여 나오는 결과가 의미 없는것 ), 측정값은 집계할수 있는것으로 구분한다. 제대로 분류되지 않았다면 수정해준다.
4) 기본 속성 조정하기
숫자형식(통화, 비율 등) 미리 조정해서 반복조정을 줄인다.
5) 레코드 수 확인하기
어떤 항목을 key로 사용할지, 어떤 항목이 측정값을 가장 세분화 하여 나눌 수 있을지 등등을 파악한다.
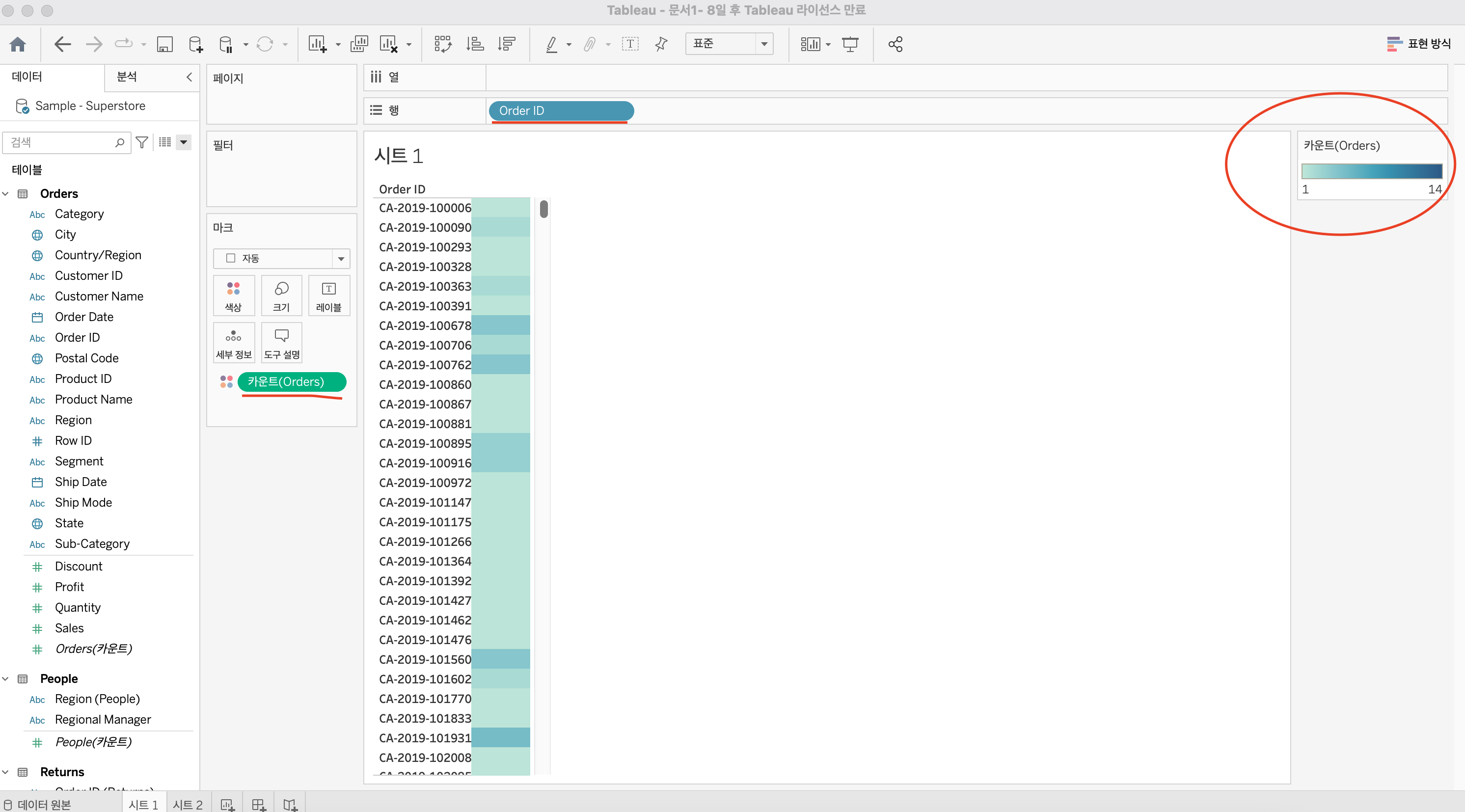
주문번호를 조회했을 때 카운트는 최소 1개에서 최대 14개까지 조회된다. 이 말은 주문번호가 데이터에 1:1로 매칭되지 않고 같은 주문번호를 갖는 데이터가 최대 14개까지 있다는 뜻이다. 따라서 주문번호만을 PK로 사용하긴 힘들다.
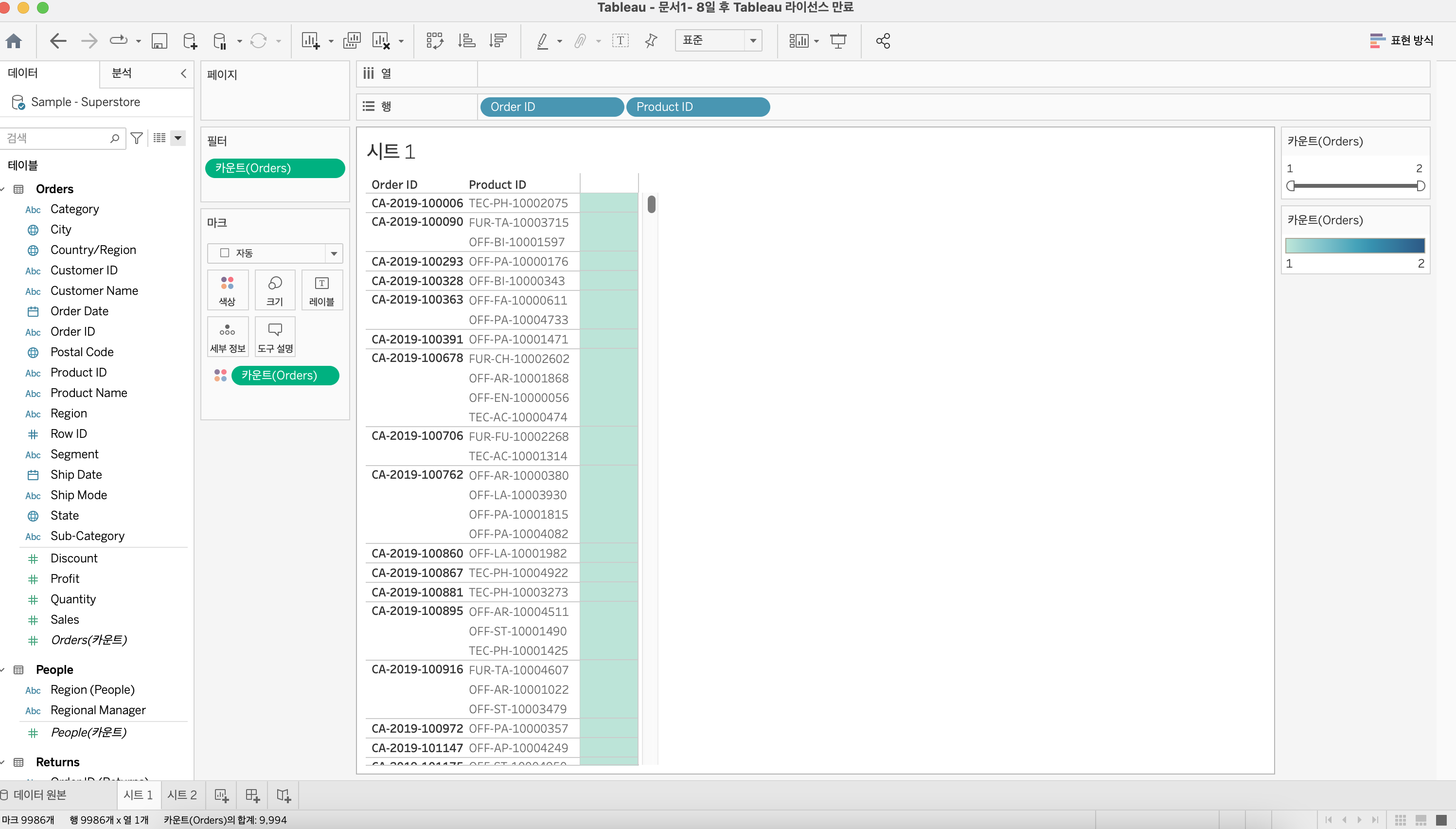
주문번호 만으로는 사용이 어렵기때문에 제품코드를 함께 넣어줬더니 최대 중복되는 데이터가 2개까지로 줄어들었다. 이런식으로 세분화 할 수 있는 분류를 확인하고 시각화 하는 것이 좋다.
2개씩 분류되는 데이터가 뭔지는 위해 필터를 추가하여 확인할 수 있다. -
데이터 전처리 기본
1) 데이터 변형
-
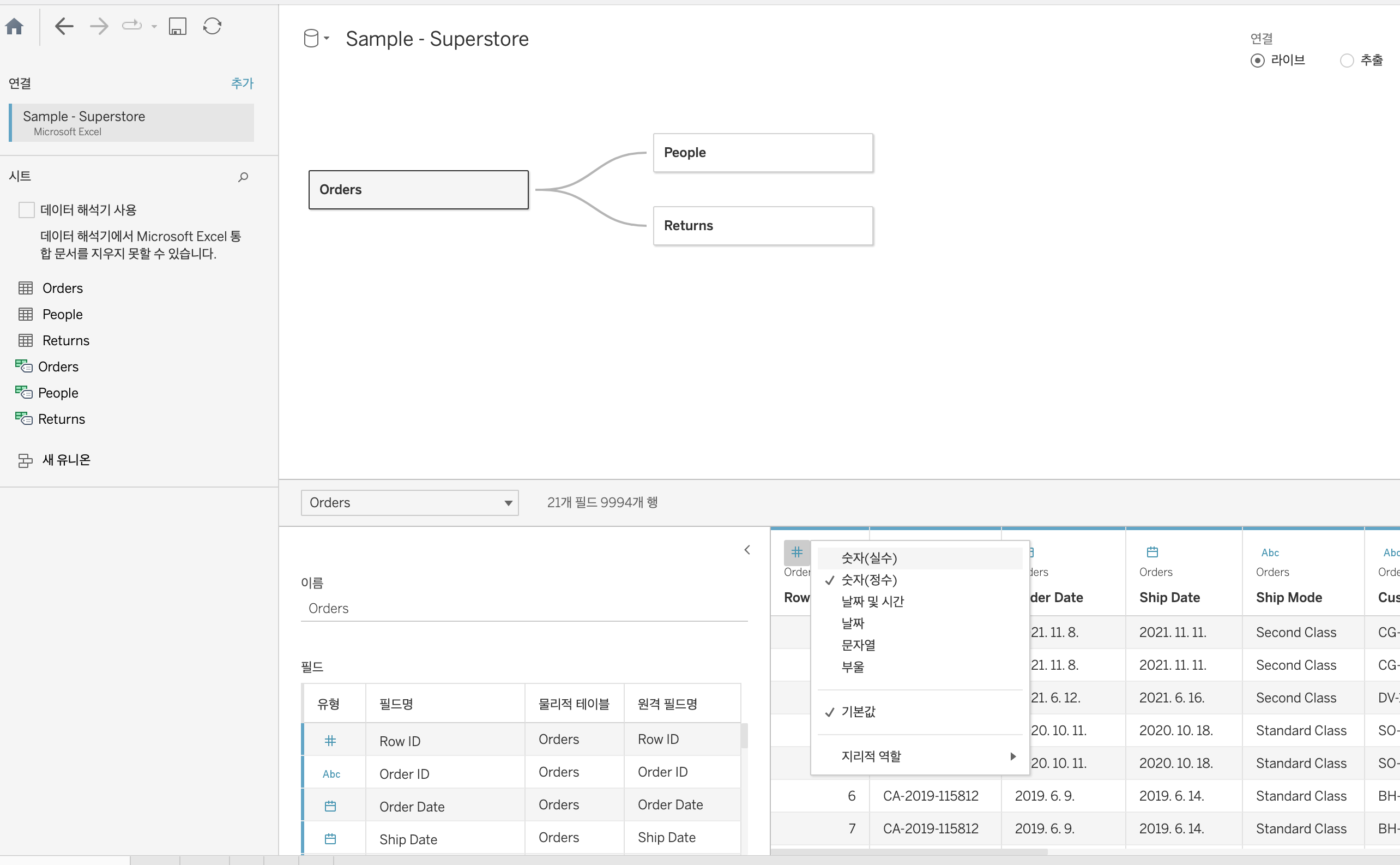
데이터 타입 변경
-
필드명 수정
-
새로운 계산된 필드 생성
-
피벗
-
Split
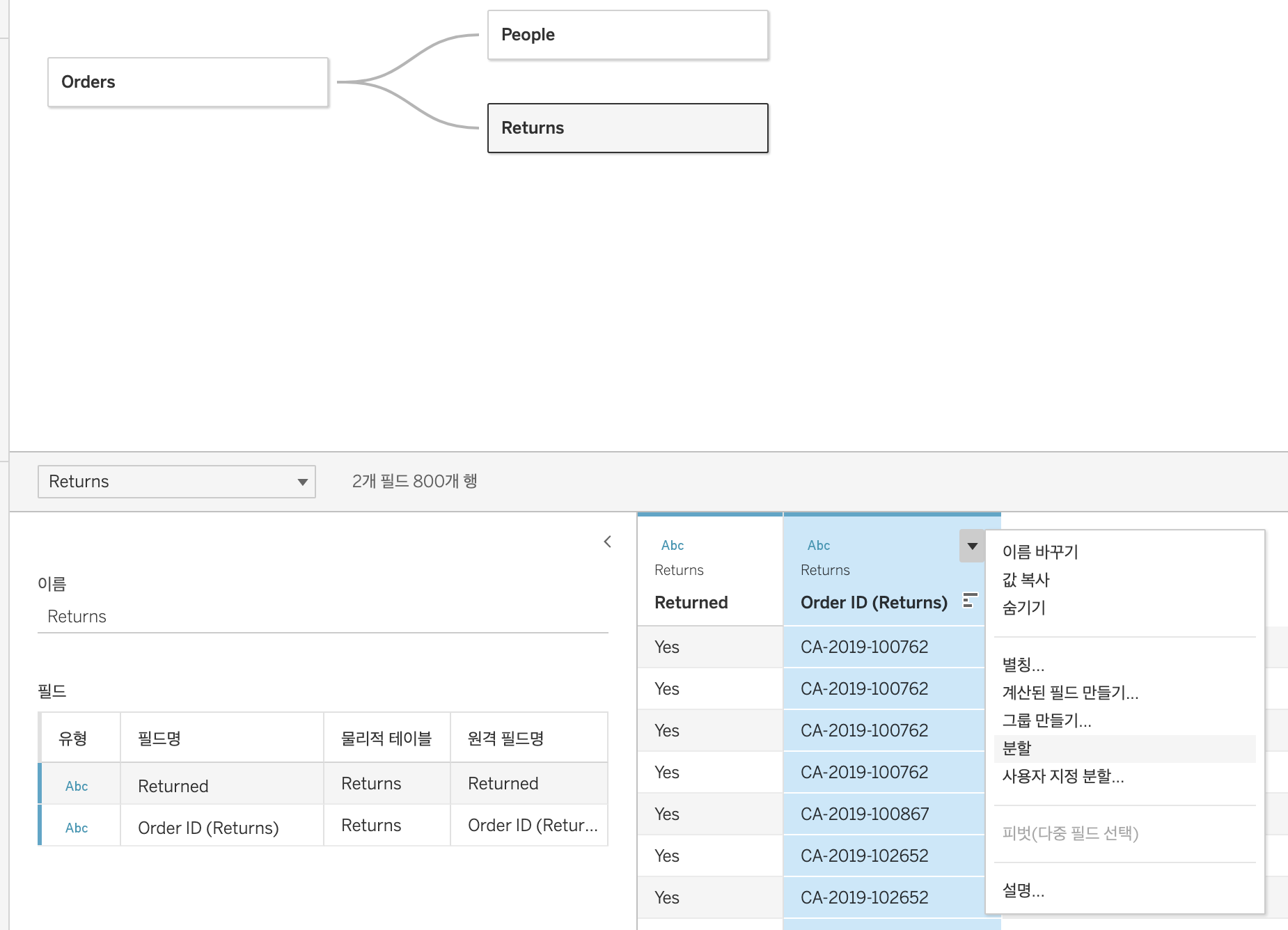
위와같이 분할해주면 아래와같이 자동으로 분할되고, 자동분할 결과가 마음에 들지 않으면 사용자 지정 분할을 사용 가능하다.
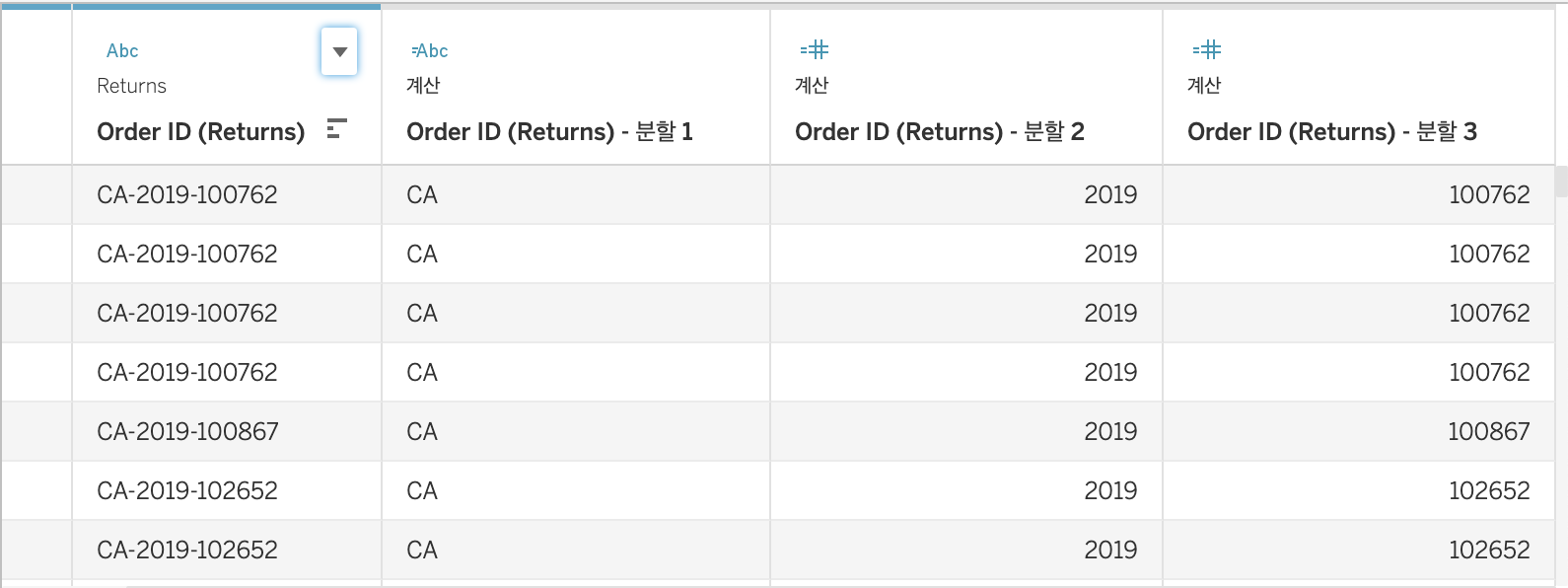
-
데이터 정렬
태블로 데이터 전처리 자동화는 태블로 프랩에 대해 알아보자
-
-
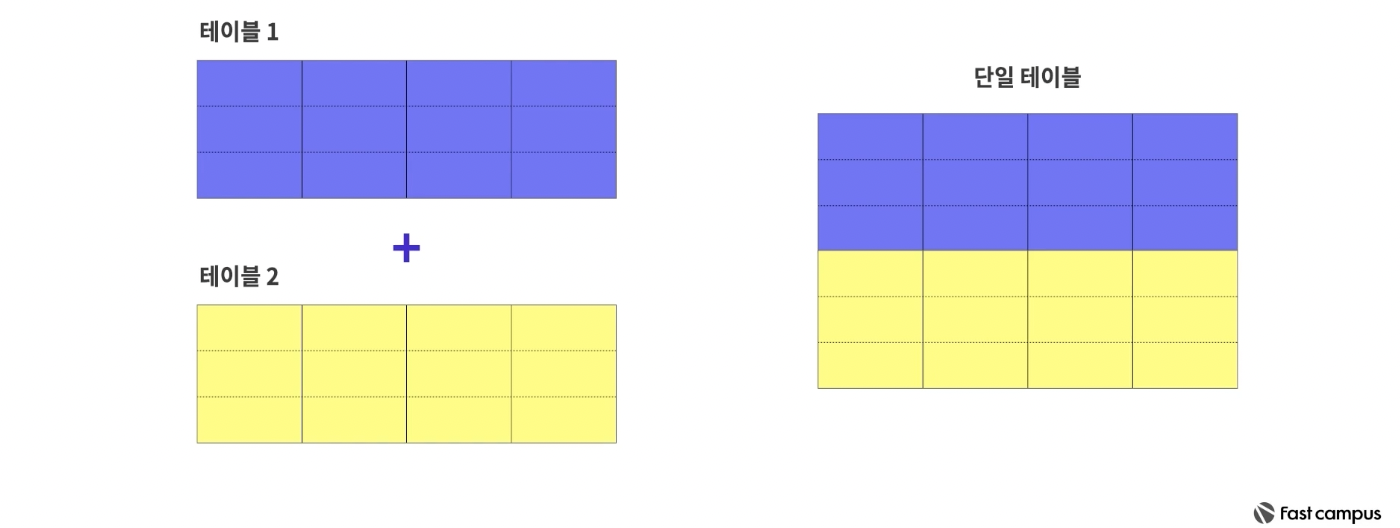
테이터 유니온
- 세로병합
- 같은 데이터 연결 타입이어야함 ( excel과 구글스프레드시트 유니온 불가능 )
- 모든 테이블에서 필드명과 데이터 타입이 같아야함
- 월별로 분할되어있는 동일 레이아웃의 데이터 병합 등에 유리하다.
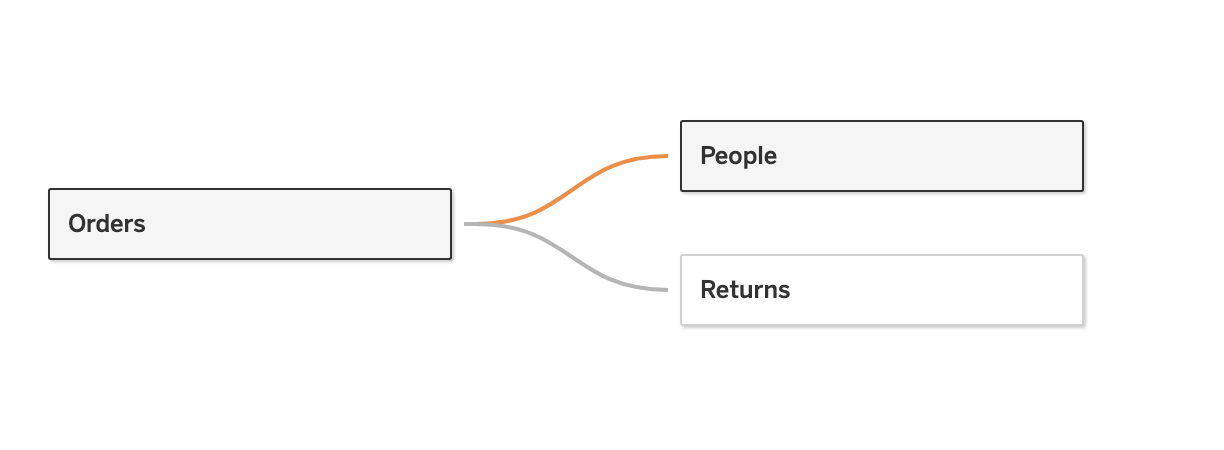
- 데이터 관계
-
데이터 관계의 특징
1) 두 테이블의 관계를 설명하지만 하나의 테이블로 Join 되지는 않음
2) 조인 유형 선택 안함 (자동으로 적절한 조인을 생성)
3) 모든 행과 열을 사용할 수 있음
4) 집계 값이 중복되지 않음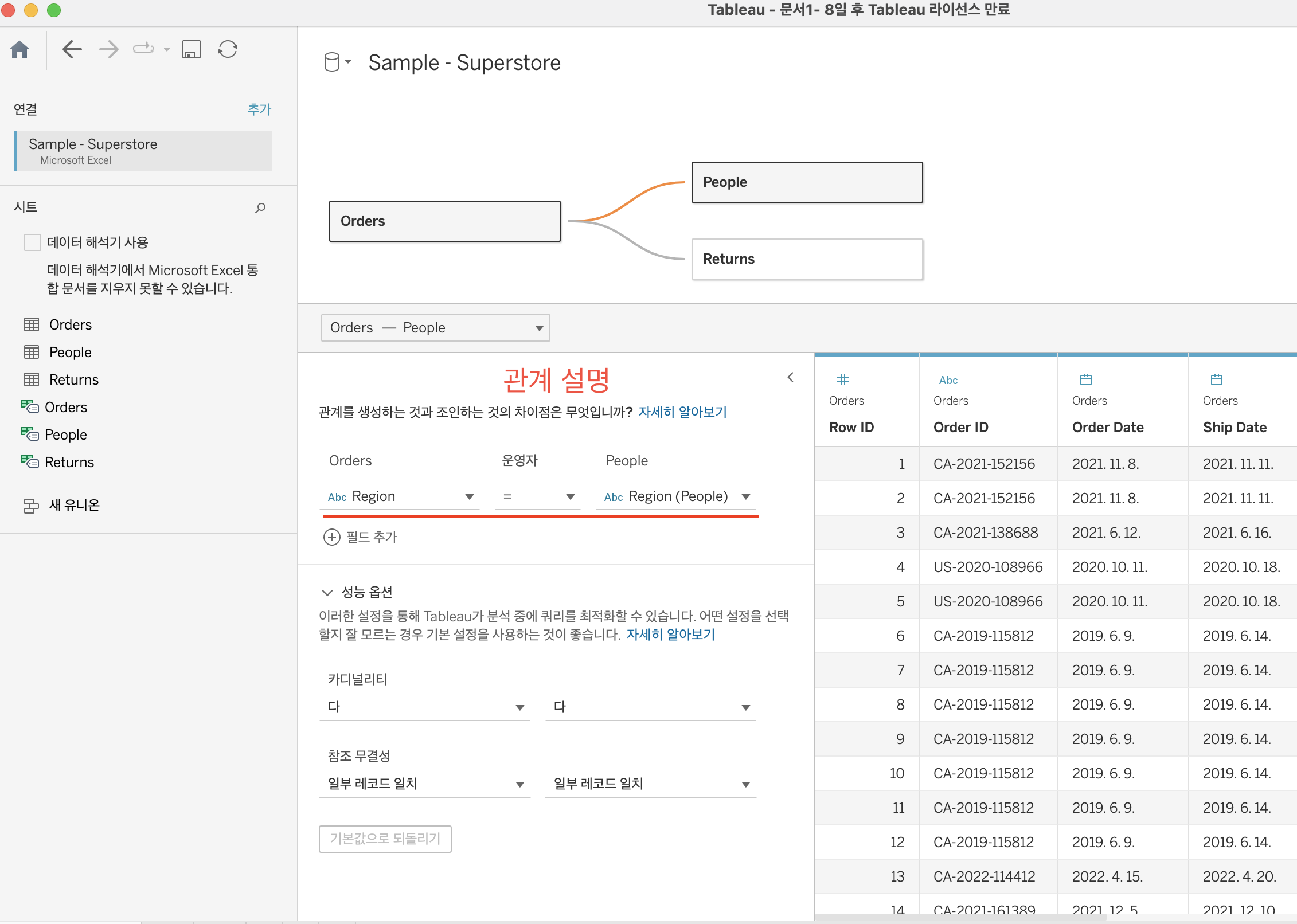
- Order of operations (쿼리 파이프라인)
-
태블로 계산과 필터의 작동 순서 = 쿼리 파이프라인
-
작동 순서와 사용자가 예상하는 순서가 다를 경우 변경이 가능하다.

