
TCP는 인터넷 전송 계층의, 연결 지향, 신뢰성 있는 데이터 전송 프로토콜이다. 이 섹션에서는 TCP의 에러 검출, 재전송, 누적 ACK, 타이머, SEQ/ACK 헤더 필드에 대해 알아본다.
1. The TCP Connection
TCP 프로토콜은 연결 지향적 프로토콜로, 서로 통신할 두 프로세스는 실제 데이터를 주고 받기 전에 핸드셰이크 과정을 통해 연결을 수립해야 한다. 이 연결과정에서 두 프로세스는 이후 데이터 전송에서 필요할 매개 변수를 설정하는데, 연결을 마친 두 프로세스가 꼭 서로 물리적 회선으로 연결된 것만 같다는 의미에서 가상 회선 방식이라고도 부른다.
TCP의 연결에 대해 몇 가지를 짚고, 어떻게 연결이 이루어지는지 알아 보자.
- TCP 프로토콜은 종단 시스템에서만 실행된다.
- 라우터, 스위치와 같은 중간 네트워크 요소는 TCP 연결을 전혀 알지 못하고, 그냥 데이터그램을 처리할 뿐이다.
- TCP는 전이중(full-duplex) 서비스를 제공한다.
- 서로 TCP 연결을 맺은 두 서비스는 모두 서로에게 데이터를 주고 받을 수 있다.
- TCP 연결은 항상 점대점 연결이다.
- 항상 한 송신자-한 수신자 사이에서만 연결이 이루어지며, 멀티캐스팅은 불가능하다.
이제 연결이 어떻게 이루어지는지 간단하게 보자. 연결을 시작하는 프로세스를 클라이언트, 나머지 한 쪽을 서버 프로세스라 하면,
- 클라이언트 애플리케이션은 클라이언트 전송 계층에 서버 프로세스와의 연결 수립을 원한다고 알린다.
- 클라이언트 TCP는 서버 TCP와의 연결 수립을 위한 절차를 진행한다.
- 클라이언트가 연결 요청 TCP 세그먼트를 보낸다.
- 서버는 요청에 대한 응답 TCP 세그먼트를 보낸다.
- 클라이언트가 응답에 대한 응답 TCP 세그먼트를 보낸다.
여기서 처음 두 TCP 세그먼트에는 페이로드가 담겨있지 않고, 세 번째 세그먼트에는 페이로드가 있을 수도 있다. 위와 같이 세 개의 세그먼트가 두 호스트 사이에서 오가기 때문에, 위 세그먼트 교환 과정을 흔히 3-way 핸드셰이크라 부른다.
이렇게 TCP 연결이 수립되고 나면 두 애플리케이션 프로세스는 서로에게 데이터를 보낼 수 있게 된다. 예를 들어 클라이언트가 서버에게 데이터를 보낸다고 해보자.
- 클라이언트 애플리케이션은 소켓을 통해 데이터 스트림을 전달한다.
- 소켓을 통과한 데이터는 클라이언트 TCP의 송신 버퍼로 들어간다. 이 버퍼는 3-way 핸드셰이크 동안에 따로 마련된다.
- TCP는 송신 버퍼에서 데이터를 조각내서(chunk) 캡슐화해 네트워크 계층에 전달한다.
- 수신자는 TCP 세그먼트를 받으면 데이터를 추출해 수신 버퍼에 넣는다.
- 수신자 애플리케이션은 수신 버퍼로부터 데이터 스트림을 읽는다.
이때 버퍼링된 데이터를 언제 전송할지에 대해서는 프로토콜에 명시된 제한이 없고, 편의에 따라(in convenience) 전송하면 된다.
2. TCP Segment Structure
TCP에서는 데이터를 조각내고, 각 조각에 TCP 헤더를 붙여 TCP 세그먼트를 만든다.
이때 TCP 세그먼트에 담을 수 있는 최대 데이터량, 즉 세그먼트에 들어가는 데이터 조각의 최대 크기를 MSS(Maximum Segment Size)라 하는데, 다음과 같은 절차를 통해 정해진다.
- 로컬 송신 호스트가 전송할 수 있는 가장 큰 링크-계층 프레임의 크기(MTU)를 찾음
- 데이터를 TCP 캡슐화, 이후 IP 캡슐화한 후에도 해당 크기 안에 들어갈 수 있도록 설정
소스에서 목적지까지의 경로 상에 있는 모든 링크에서 전송 가능한 최대 크기 프레임(경로 MTU)를 찾아내고, 그 값을 기준으로 MSS를 설정할 수도 있다.
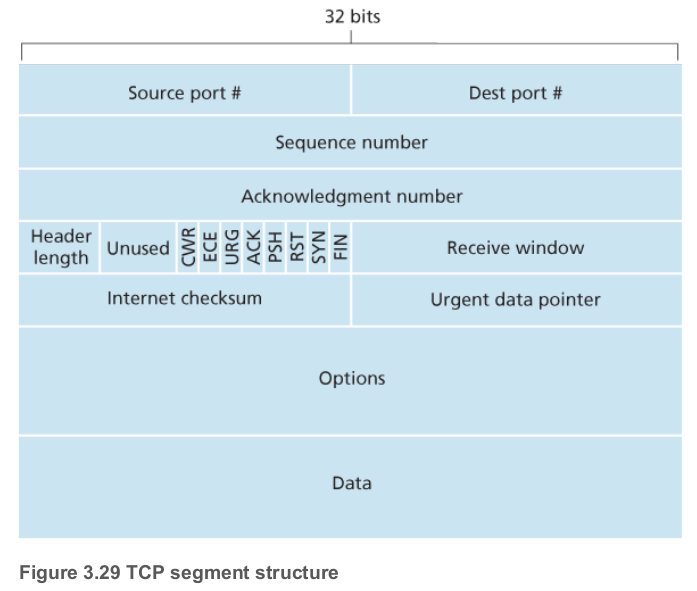
UDP와 마찬가지로 상위 애플리케이션 계층을 식별하고 데이터를 멀티플렉싱/디멀티플렉싱하는 데 쓸 수 있는 포트 번호가 있고, 데이터 오류 확인을 위한 체크섬 필드도 있다. 이외에도 여러 필드들도 있는데 간단히 알아보자.
| 필드 | 길이(비트) | 설명 |
|---|---|---|
SEQ 번호/ ACK 번호 | 32/32 | 송수신자 간 신뢰성 있는 데이터 전송 서비스 구현에 사용 |
| 수신 윈도우 | 16 | 흐름 제어에서 사용. 수신자가 수용 가능한 바이트 수를 표시 |
| 헤더 길이 | 4 | 실제 데이터가 어디서 시작하는지를 4바이트 단위로 표시. 보통은 옵션 헤더를 사용하지 않기 때문에 20바이트 = 5 * (4 바이트) = 0101 |
| 플래그 | 6 | - ACK: ACK 번호 필드가 유효함- SYN/RST/FIN: 연결 설정 및 해제에 쓰임 - CWR, ECE: 명시적 혼잡 알림 - PSH: 수신자는 즉히 데이터를 상위 계층으로 전달 - URG: 긴급 데이터가 있음 |
| 옵션 | 가변 | MSS 협상, 타임스탬프 옵션 등 추가 옵션이 필요한 경우 |
| 데이터 | 가변 | 실제 전달할 데이터 |
Sequence Numbers and Acknowledgment Numbers
TCP 세그먼트에서 가장 중요한 필드는 SEQ 번호 필드와 ACK 번호 필드로, 신뢰성 있는 데이터 전송 서비스 구현의 핵심이다.
TCP에서는 데이터를 순서가 있는 바이트 스트림으로 보는데, 세그먼트의 SEQ에는 해당 세그먼트에 들어가는 첫 번째 바이트의 바이트 스트림 상 번호가 들어간다.
예를 들어 500,000 바이트 크기의 파일을 보낸다고 하자. MSS가 1,000바이트라 하면 파일은 500개의 세그먼트로 나뉠 수 있다. 첫 번째 바이트가 0번부터 시작한다고 가정하면, 첫 번째 세그먼트의
SEQ는 0, 두 번째는 1000, 세 번째는 2000, ...이 된다.
ACK 번호는 조금 더 까다로운데, TCP에서 ACK은 데이터 스트림 내에서 처음으로 누락된 바이트다. 다시 말해 호스트 A가 B에게 전송하는 세그먼트의 ACK 번호는 A가 B로부터 받기를 기대하는 바이트 번호를 의미한다. 예를 들어 A가 바이트 번호 0 ~ 535를 받고 536을 다음으로 받기를 원하는 경우, ACK 번호 필드에는 536이 들어간다. 데이터 스트림에서의 첫 누락 바이트의 번호이기 때문에 수신된 바이트 각각에 대해 ACK를 보내지는 않으며, 누적 ACK 방식으로 동작한다.
TCP에서 수신자가 순서에 어긋난 세그먼트를 받는 경우, 어떻게 세그먼트를 처리해야 하는지에 대한 규칙은 정해져있지 않다. 일반적으로는 다음의 두 개의 선택지가 있고,
- 순서가 어긋난 세그먼트 즉시 버림(GBN).
- 수신자가 보관해뒀다가, 나중에 누락된 바이트가 오면 재구성(SR).
네트워크 대역폭의 측면에서 두 번째 방법이 효율적이기 때문에, 실제 대부분의 구현에서는 이 방식을 사용한다.
위에서는 초기 시퀀스 번호(ISN)를 0으로 가정했지만, 실제로는 TCP 연결을 맺을 때 임의로 정한다. 이전에 종료된 연결에서 네트워크 어딘가에 세그먼트가 남아 있다가 나중에 같은 호스트끼리의 연결에서 유효한 세그먼트로 오인되는 상황을 방지하기 위함이다.
3. Round-Trip Time Estimation and Timeout
TCP에서도 타임아웃/재전송 메커니즘을 사용한다. 그렇다면 타임아웃 간격은 얼마나 길어야 할까?타임아웃 간격이 1RTT보다 작으면 불필요한 재전송이 일어나므로 적어도 1RTT보다는 커야한다. 그렇다면 RTT는 어떻게 계산/추정할 수 있을까? 각 세그먼트마다 타이머를 따로 둬야 할까?
Estimating the Round-Trip Time
- SampleRTT
- 세그먼트를 네트워크 계층으로 내려보낸 시점에서 해당 세그먼트에 대한
ACK를 받은 시점 사이의 시간이다. - 이때 전송된 모든 세그먼트에 대해 RTT를 측정하는 건 아니고, 대부분 한 번에 한 세그먼트에 대해서만 RTT를 측정한다.
- 재전송된 세그먼트에 대해서는 SampleRTT를 계산하지 않는다.
- 라우터가 혼잡하거나 종단 시스템 부하 변화가 일어나는 경우 세그먼트마다 변동이 발생할 수 있고, 대표성을 띄지 못할 수도 있다.
- 세그먼트를 네트워크 계층으로 내려보낸 시점에서 해당 세그먼트에 대한
- EstimatedRTT
- 전형적인 RTT를 추정하기 위해 SampleRTT의 평균을 구한 것.
- 정확한 평균치를 구하는 것은 아니고 최근 샘플에 더 많은 가중치를 두는, 가중 평균값이다. 최근 샘플일수록 현재 네트워크 혼잡 상태를 더 잘 반영하기 때문이다.
- 아래와 같이 계산한다.
α는 최신값에 부여하는 가중치에 해당하고, 보통은 0.125 정도를 추천한다고 한다.
EstimatedRTT = (1 − α) ⋅ EstimatedRTT + α ⋅ SampleRTT- DevRTT
- RTT 평균뿐만 아니라, RTT의 변동성은 어떻게 되는지 측정하는 것도 중요한 일이다.
- SampleRTT에 변동이 적으면 DevRTT는 작아지고, 변동이 커지면 DevRTT도 그만큼 커진다.
- 아래와 같이 계산하며,
β는 최근 RTT 변동에 얼마나 민감하게 반응할지를 조절하기 위한 가중치로, 보통 0.25로 둔다.
DevRTT = (1 − β) ⋅ DevRTT + β ⋅ |SampleRTT − EstimatedRTT|타임아웃 간격 설정
EstimatedRTT와 DevRTT 값이 주어졌다면, 타임아웃 간격은 어떻게 설정해야 할까?
일단 EstimatedRTT보다는 크거나 같아야 한다. 이보다 작으면 불필요한 재전송이 자주 발생할 수도 있기 때문이다. 반대로 너무 크면 손실 발생 시 세그먼트 재전송을 너무 늦게 시작하기 때문에 전송 지연이 발생한다.
때문에 타임아웃은 EstimatedRTT에 조금의 여유 마진을 더한 값으로 정한다. 이때 DevRTT 값이 활용되는데, SampleRTT의 변동성을 추적해, 값이 많이 흔들리면 마진을 크게, 조금 흔들릴 떄에는 마진을 작게 설정한다.
TimeoutInterval = EstimatedRTT + 4 ⋅ DevRTT초기 타임아웃 간격으로는 보통 1초를 두고, EstimatedRTT, DevRTT 값을 가지고 조정을 해나가되, 타임아웃이 발생하면 재전송 후 타임아웃 간격을 두 배로 증가시키고, ACK를 받으면 기존대로 재계산한다.
Q. 왜 타임아웃이 발생했을 때 간격을 두 배로 증가시킬까?
A. 타임아웃이 발생했다면 현재 네트워크가 느린 상태일 것이라 판단할 수 있다. 만약 이 상태에서TimeoutInterval조정 없이 그대로 재전송하면, 또 타임아웃이 발생하고, 또 재전송하고, ...., 계속해서 불필요한 재전송이 발생할 수 있다.타임아웃이 발생했을 때 임시로 간격을 증가시키면 위와 같은 불필요한 재전송 문제를 해결할 수 있다. 이는 제한적인 형태의 혼잡 제어(congestion control)라 할 수 있다.
