1️⃣ BERT
BERT(Bidirectional Encoder Representations from Transformers)는 2018년 구글에서 제안한 ‘사전 훈련 언어 모델’로 11개 이상의 다양한 태스크에서 좋은 성능을 내는 범용 언어 모델이다. 즉, 특정 태스크를 위한 전이 학습 이전 단계인 임베딩 단계에 집중한 모델이다.
-
훈련에는 위키피디아에서 얻은 25억 개 단어 규모의 데이터와 Book Corpus에서 얻은 8억 개 단어 규모의 데이터가 활용되었다.
-
활성화 함수로는 ReLu가 아닌 GELU, 옵티마이저로는 Adam을 사용하였다.
-
BERT를 통한 NLP는 Unsupervised 방식으로 대용량 Corpus를 통해 임베딩을 학습하는 Pre-train단계와 특정 태스크에 대해 Fine-tuning하는 2단계로 이뤄진다.
💡 BERT의 구조
BERT다음과 같은 3가지 요소로 Input을 임베딩한다.
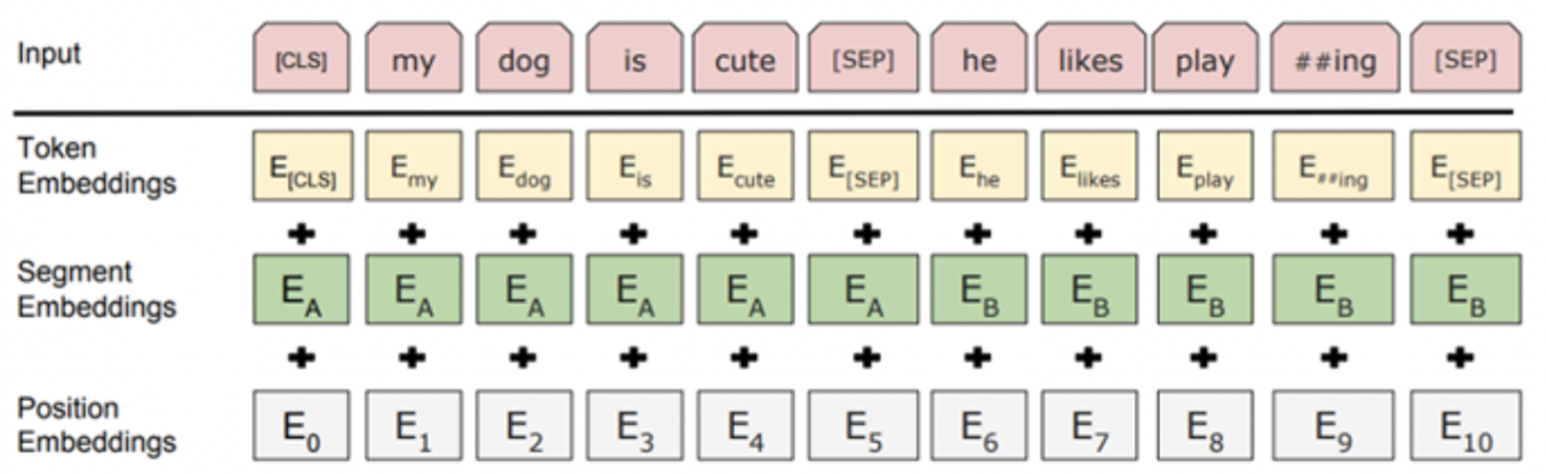
출처 : https://happy-obok.tistory.com/23
⭐️ Token Embedding
Token Embedding은 자주 등장하면서 가장 긴 길이의 Sub-Word인 Word Piece 단위로 이뤄진다. 즉 ‘감사합니다’라는 한 구절은 ‘감사-’와 ‘-합니다’라는 Word Piece로 나뉘어 임베딩된다. 이를 통해 자주 등장하지 않는 단어를 전부 Out-of-Vocabulary(OOV)로 처리했던 문제를 해결할 수 있다.
⭐️ Segmentation Embedding
Segmentation Embedding은 토큰으로 나누었던 단어들을 다시 합치고, 첫번째 [SEP](Seperation, 즉 문장의 끝) Token까지는 0, 이후 Token까지는 1로 마스킹하여 각 문장들을 구분하기 위한 임베딩이다.
⭐️ Position Embedding
Position Embedding은 모델에게 토큰의 순서를 알려주기 위해 쓰인다. BERT는 Self Attention을 사용하는 Transformer의 인코더를 도입했기 때문에, 순서를 고려하기 위해서는 추가적인 임베딩이 필요하다.
💡 BERT의 사전 훈련
⭐️ Masked Language Model
BERT의 사전 훈련 방법 중 Masked Langague Model(MLM)은 신경망에 입력되는 텍스트의 15%를 임의로 정해 Masking한 후, 이를 예측하는 방식으로 이뤄진다. 가령, ‘나는 [MASK]에 가서 사과와 [MASK]를 샀다’라는 문장에서 Masking된 ‘슈퍼’와 ‘바나나’를 맞추게 하는 것이다.
Fine Tuning 단계에서는 [MASK] 토큰이 사용되지 않아 사전 훈련과 Fine Tuning 단계의 태스크에 차이가 나타난다는 점을 보완하기 위해, 임의로 선택된 15%의 토큰 중 80%만 실제로 [MASK]로 변경하고, 나머지 10%는 임의의 단어로 변경, 남은 10%는 동일하게 둔다.
⭐️ Next Sentence Prediction
BERT는 QA(Question Answering)나 NLI(Natural Language Inference)와 같이 두 문장 간의 관계를 파악해야 하는 태스크를 위해 Next Sentence Prediction이라는 사전 훈련 방법을 사용한다. [SEP] 토큰으로 구분된 두 개의 문장을 준 후, 두 문장이 이어지는 문장인지를 맞추도록 학습시킨다.
💡 BERT의 Fine-tuning
⭐️ Single Text Classification
BERT는 문서 유형 분류 태스크를 위해 CLS라는 토큰을 사용한다. 이 토큰 위치의 Output에 Dense Layer를 추가하여 분류 예측을 하도록 한다.
⭐️ Tagging
각 단어의 품사 Tagging과 같은 태스크의 Fine Tuning은 각 단어의 Output 위치에 개별 Dense Layer를 추가하여 분류 예측을 하도록 하는 것으로 이뤄진다.
⭐️ Question Answering
질문과 본문이라는 2개의 텍스트 쌍을 입력받아, 본문의 일부를 추출해서 주어진 질문에 대한 답을 출력하게 한다. 이 태스크를 위한 대표적인 데이터셋으로는 SQuAD가 있다.
2️⃣ GAN
Generative Adversarial Networks
- GAN(생성적 적대 신경망)은 머신 러닝 분야에서 학문적으로 매우 중요한 의미를 지닌다.
- 2014년 Ian Goodfellow와 그의 동료들에 의해 소개된 이래로 많은 연구자들의 관심을 받았고, 다양한 세부 분야로 퍼져 발전, 적용되는 주요 기술이 되었다.
- GAN은 주어진 학습 Dataset과 매우 유사한 새로운 데이터를 생성하기 위한 강력한 프레임워크를 제공하는 생성 모델이다.
GAN을 통해서 사실적이고 다양한 샘플을 생성할 수 있고, 이는 이미지 합성, 텍스트 생성, 심지어 신약 개발 등 다양한 적용 분야에서 활용된다.
💡 판별자, 생성자
- GAN의 두 가지 주요 구성 요소는 판별자(Discriminator)와 생성자(Generator)이다.
- 판별자와 생성자는 신경망이며, 서로 경쟁 관계에 있다.
- 판별자는 실제 데이터와 생성된 데이터를 구분하는 이진 분류기이다.
- 생성자는 판별자를 속일 수 있는 합성 데이터를 생성하는 역할을 한다.
- 판별자는 실제 데이터 샘플과 생성자에서 생성된 샘플을 학습하여 정확하게 분류하는 것을 목표로 한다.
- 동시에 생성자는 실제 데이터와 구별할 수 없는 샘플을 생성하도록 훈련받는다.
이러한 판별자와 생성자 간의 적대적 관계가 GAN의 학습 과정을 주도한다.
💡 손실 함수
생성자와 판별자 두 모델은 각자의 손실 함수를 가지고 있다.
판별자 손실은 판별자가 실제 샘플과 생성된 샘플을 얼마나 잘 구별할 수 있는지를 측정한다. 일반적으로 이진 교차 엔트로피 손실로, 이 손실 함수로 학습하여 판별자가 데이터를 정확하게 분류하도록 한다. 반면 생성자 손실 함수는 생성자가 판별자를 얼마나 잘 속일 수 있는지를 정량화한다. 생성자는 판별자가 실제 데이터와 구분할 수 없는 샘플을 생성하기 때문에 이 손실을 최소화하는 것을 목표로 한다.
각각의 손실 함수에 따라 판별자와 생성자의 가중치를 반복적으로 업데이트함으로써 GAN은 생성자가 실제 샘플을 생성하는 능력을 향상시키고 판별자는 이를 더 잘 구별할 수 있는 동적 균형을 이룬다.
💡 활용 분야
GAN은 다양한 영역에서 활용되고 있으며, 그 다양성과 영향력을 입증하고 있다.

⭐️ 이미지 합성
얼굴, 풍경, 사물과 같은 사실적인 이미지를 생성하는 데 사용되어 왔다. 실제 이미지의 Dataset로 생성기를 학습시킴으로써 GAN은 유사한 특성과 시각적 일관성을 나타내는 새로운 이미지를 생성할 수 있다.
⭐️ 데이터 증강
새로운 샘플을 생성하여 훈련 데이터를 보강할 수 있다. 이는 사용 가능한 Dataset가 제한되어 있을 때 특히 유용하며, GAN은 모델의 일반화 및 성능을 향상시킬 수 있는 추가 데이터 포인트를 생성할 수 있다.
⭐️ Style Transfer
한 이미지의 스타일을 다른 이미지로 전송하는 데 사용할 수 있다. 학습된 GAN을 사용하면 한 이미지의 콘텐츠는 유지하면서 다른 이미지의 예술적 스타일을 채택한 이미지를 생성할 수 있다.
⭐️ 텍스트-이미지 합성
텍스트 입력에 따라 생성기를 조절하여 주어진 텍스트 입력에 해당하는 시각적 표현을 생성할 수 있다.
⭐️ 이상 감지
데이터의 이상 징후를 감지하는 데 활용할 수 있다. 정상 데이터 샘플에 대해 GAN을 훈련시킴으로써 유사한 인스턴스를 재구성하고 생성하는 방법을 학습하고, 비정상적인 데이터가 제시되면 이상 징후를 탐지할 수 있다.
사실적인 특성을 가진 새로운 데이터를 생성하는 능력과 창의적이고 생성적인 작업의 한계를 뛰어넘을 수 있는 잠재력으로 인해 GAN은 머신러닝 분야에서 활발하고 흥미로운 연구 분야로 존재하고 있다.
[출처 | 딥다이브 Code.zip 매거진]
