📂 PDF 내용 질문 프로그램 개요
- 내가 넣어주는 pdf 내용 안에서 대답을 해주는 질문 프로그램 만들기
- 거짓 정보를 생성하는 할루시네이션 없이 정확한 답변을 얻을 수 있음
- 내 질문에 대한 답변이 어디에 있는지도 알려줌
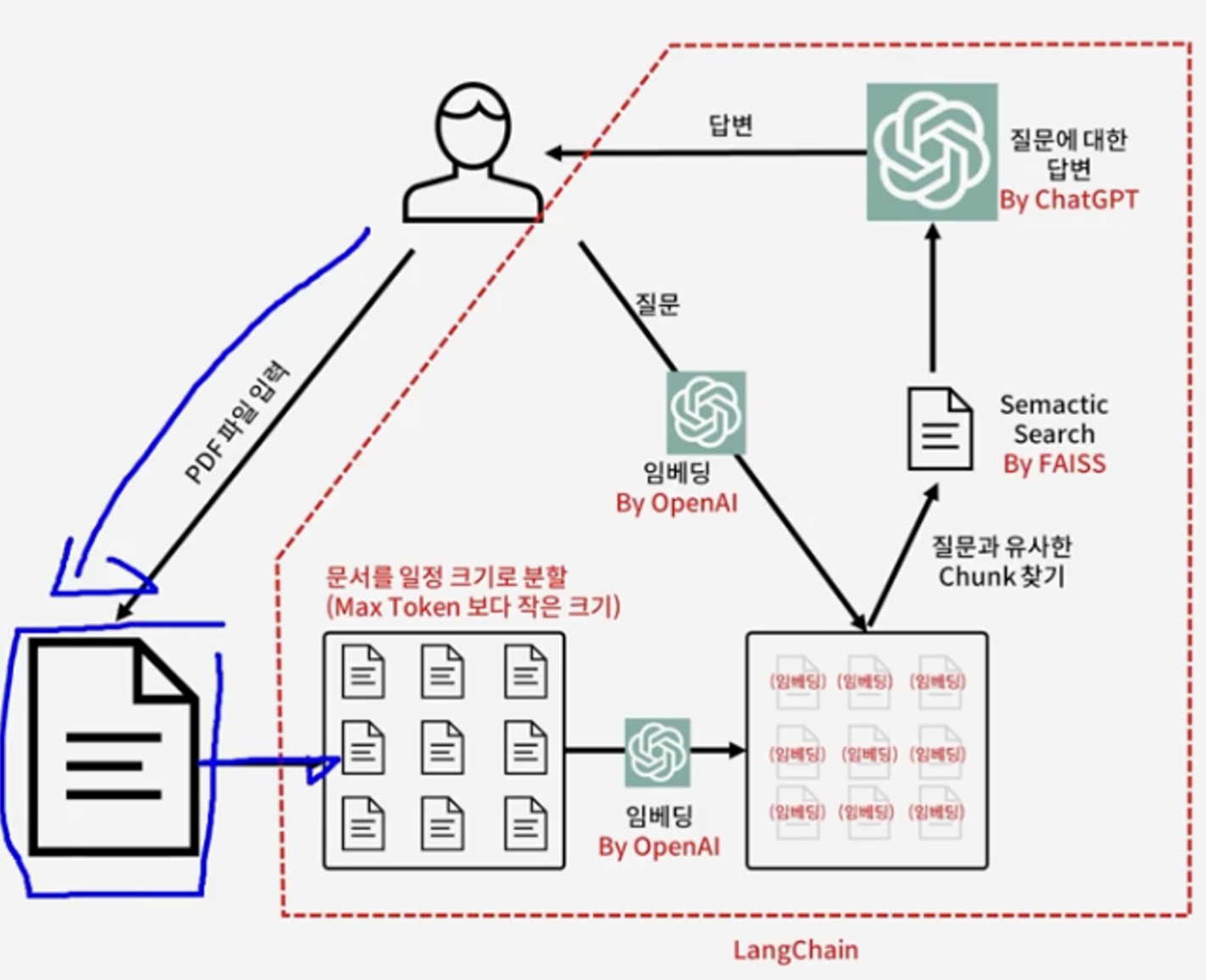
프로그램의 구조
1) pdf에서의 텍스트를 chunk 단위로 분할
2) 인간의 자연어를 컴퓨터 언어인 vector로 번역하는 임베딩 작업 실시
3) 유저의 질문과 유사한 내용이 포함된 chunk를 찾는 실시
📂 텍스트 임베딩/벡터 유사도 개념
오픈AI 임베딩
- 임베딩 모델도 다양함
- text-embedding-aida-002모델 자주 사용

📎 임베딩 과정
- 6개의 문장으로 구성된 DF 생성 (pandas로 다루기 가능)
- Embedding Func함수 생성
- 문자 -> Input
- 결과 벡터 -> Output
- 결과 벡터를 저장
📎 시멘틱 서치
- Cosine 유사도 구하기
- 가장 유사한 벡터를 찾는 과정 -> Similarity
- 가장 유사한 문장 찾기
코사인 시뮬러리티가 아닌 랭체인 프레임워크를 활용해서 더 고급화된 방법 사용 가능
🦜️ Langchain을 활용한 PDF 내용 질문 방법 익히기
1. PDF 텍스트 추출 위해 PYPDF2 패키지를 가상환경에 설치
2. PDF 리더 클래스 안에 PDF 경로 작성
3. TotalText 변수 안에 PDF 페이지별 정보 누적 저장
4. 텍스트 추출 후, Chunk size로 문서 쪼개기 (overlap 주기 )
# PDF 파일 받기
pdf = st.file_uploader(" ", type="pdf")
if pdf is not None:
# PDF 파일 텍스트 추출하기
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# 청크 단위로 분할하기
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
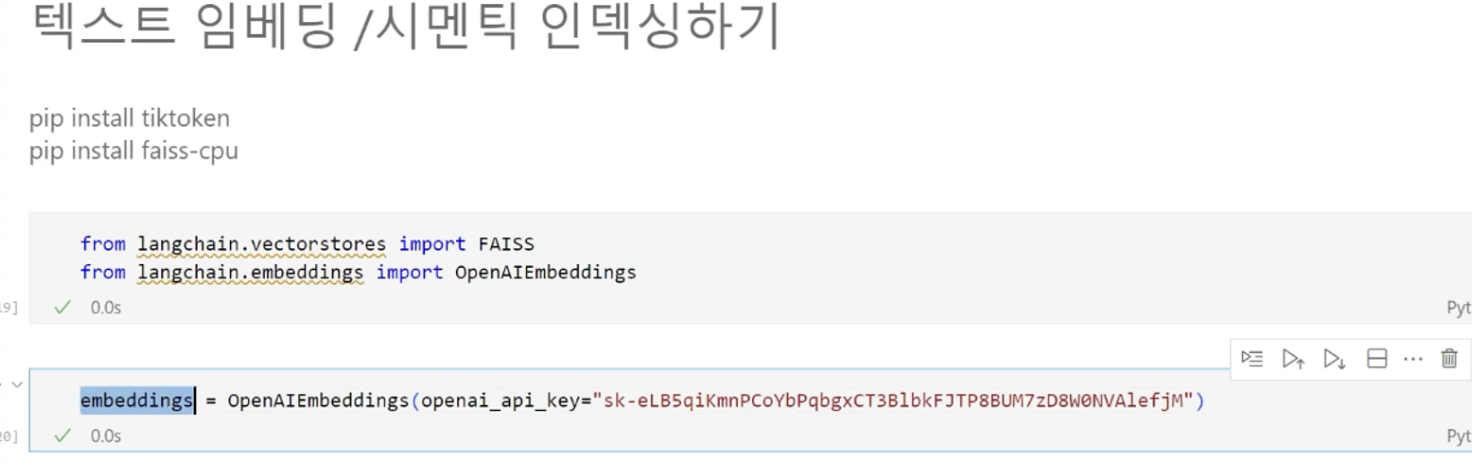
chunks = text_splitter.split_text(text)5. 각 chunk들을 OpenAI의 임베딩 모델을 이용해 임베딩 진행
- Langchain에서 해당작업을 수행하기 위해 TIK 토큰과 FAI-SS CPU 패키지 설치
- TIK 토큰: 랭체인 안에서 OpenAI의 토큰 수를 계산할 때 사용
- FAI-SS CPU 패키지: Similarity를 계산하는 패키지!
6. 마지막으로 추출한 chunk와 유저의 질문을 합쳐서 요약해달라고 질문
[인프런]초보자를 위한 ChatGPT API 활용법 - API 기본 문법부터 12가지 프로그램 제작 배포까지

@fragrance_0의 개발로그