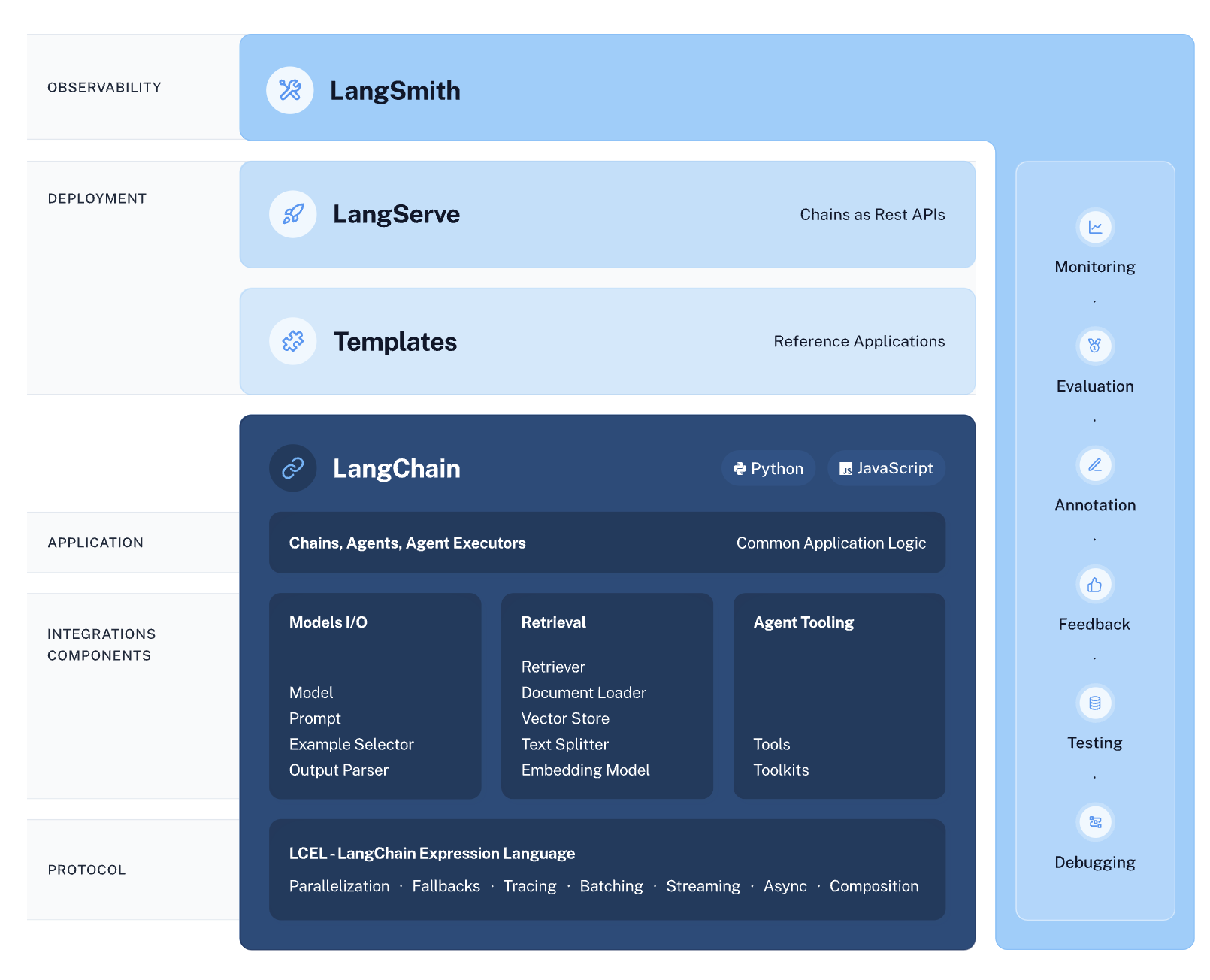
🎥 유튜브 내용 요약 프로그램 개요
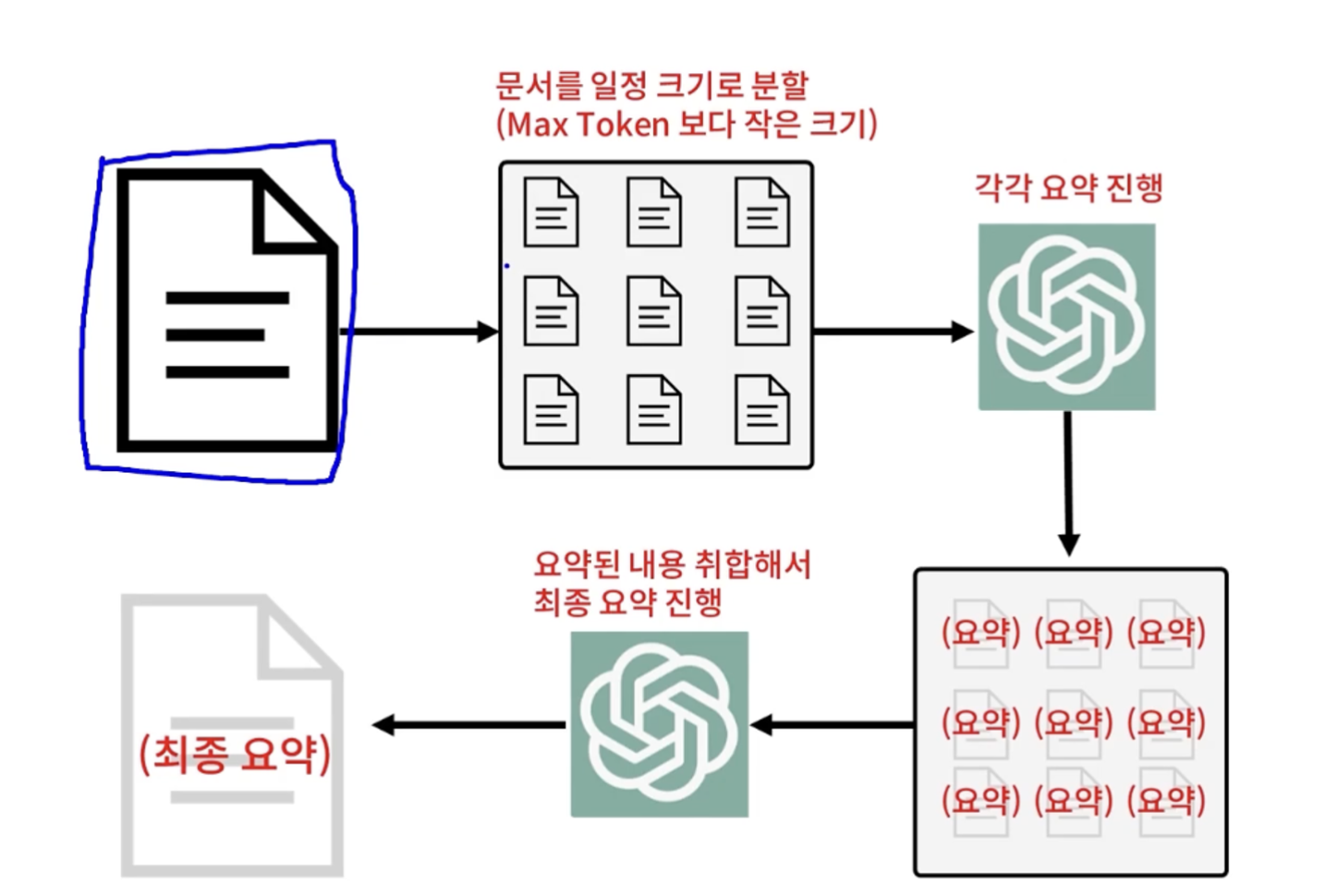
- chatGPT로는 요약할 수 있는 문서의 토큰수가 제한적임
- Langchain을 이용해 문서를 일정 크기로 분할하여 각각 요약진행하고, 마지막에 최종요약으로 나올 수 있도록하는 시스템을 만들고자함
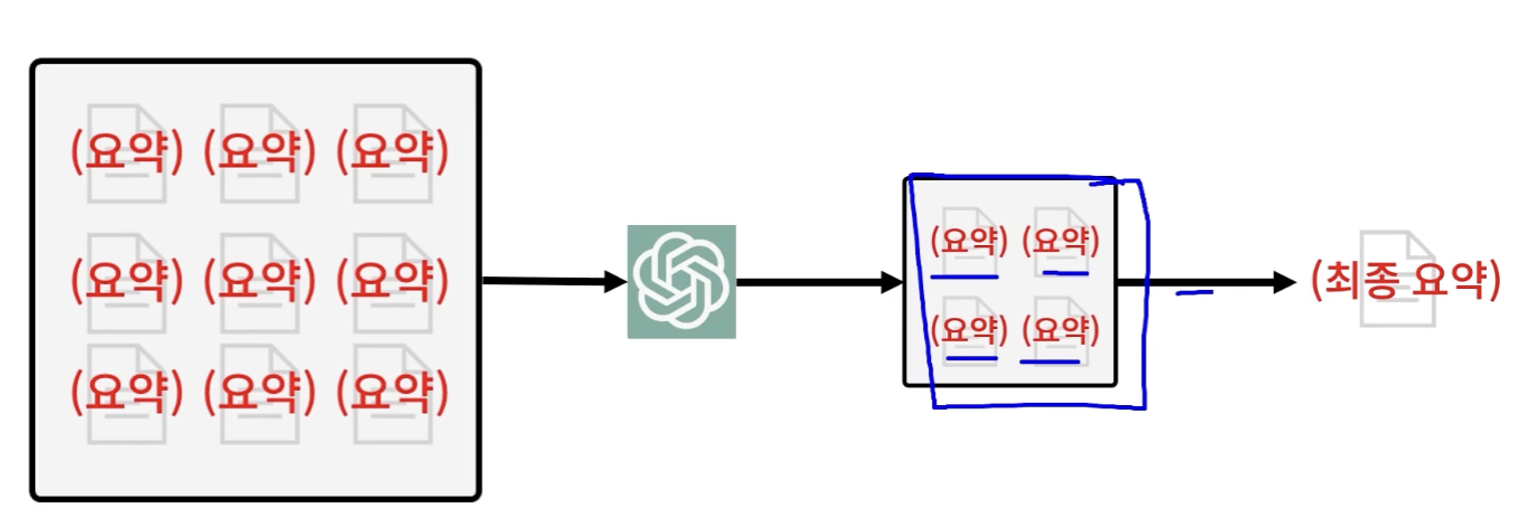
요약된 작은 문서들의 집합을 또 요약해서 결국에 최종 요약본을 만들어내는 형태
🎥 Langchain 소개 및 유튜브 대본 추출
🔗 Langchain 이란?
# 랭체인 설치
pip install langchain
- 랭체인에서 MODEL 모듈을 활용하면 다양한 LLM 모델을 아주 쉽게 갈아끼울 수 있음
- 랭귀지 + 체인 ⇒ 랭체인이라고 명명함
⤬ 메타의 라마트, 알파카, 비쿠냐 등 좋은 성능을 보이는 다른 언어모델로도 쉽게 활용가능함
⤬ 또한 API 요금이 부담된다면 다른 언어모델로도 사용 가능
🔗 유튜브 영상대본 추출 과정
- 패키지 설치 후
loader.load-method를 실행해 대본이 추출되도록 함 - 추출된 대본을
transcript라는 변수에 저장함.
# 유튜브 대본 불러오는 api
pip install youtube-transcript-api🎥 Langchain을 활용하여 긴 글 요약하는 방법 익히기
글을 쪼개서 MAX Token 이하의 여러 문서들로 만들자
🔗 요약 방법의 흐름
- 문서를 max token보다 작도록 여러개의 덩어리로 분할
- 여러개의 덩어리들 각각의 요약을 진행
- GPT에게 요약 조각들을 합쳐서 최종 요약을 해달라고 요청
- 최종 요약본 완성
🔗 Langchain 안에 모든 기능이 모듈화되어 쉽게 구현 가능
# flag 요약되는지 확인, api 저장, summerize 저장
if "flag" not in st.session_state:
st.session_state["flag"] = True
if "OPENAI_API" not in st.session_state:
st.session_state["OPENAI_API"] = ""
if "summerize" not in st.session_state:
st.session_state["summerize"] = ""1. 문서 쪼개기
# 대본 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=0)
text = text_splitter.split_documents(transcript)
- chunk size = 각각의 분할한 문서의 사이즈
- overlap = 문서를 분할 할 때 앞과 뒤의 문서의 내용을 겹치는 것의 양
→ 긴 글을 요약할때는 굳이 오버랩 필요 없음
2. 요약
#요약 실행
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False,
map_prompt=prompt, combine_prompt=combine_prompt)
st.session_state["summerize"] = chain.run(text)
st.session_state["flag"]=False
🎥 기능 구현 함수 (Main 함수)
- 번역을 위한 패키지 추가
#번역을 위해 추가
from googletrans import Translator
# 영어 번역
def google_trans(messages):
google = Translator()
result = google.translate(messages, dest="ko")
return result.text-
LLM 모델 설정
-
GPT 3.5 Turbo 모델로 지정해 실습 넣기
-
chain 이라는 이름의 인스턴스 생성
-
chain 안에는 텍스트가 스플릿된 결과가 들어있음
-
chain.run 안에 요약을 진행할 텍스트 리스트를 넣어주면 요약 진행 완료
_[인프런]초보자를 위한 ChatGPT API 활용법 - API 기본 문법부터 12가지 프로그램 제작 배포까지_

@fragrance_0의 개발로그