

1. NLTK 자연어 처리 패키지
2. 한글 형태소 분석과 워드 클라우드
3. 인공신경망
4. 케라스를 이용한 인공신경망 구현
5. RNN
6. LSTM
딥러닝
비선형
인공신경망
tensorflow는 학습, keras는 구현 활용
-
tensor ( 다차원 배열, 변수 ) 의 flow
영상처리, 신호처리
RNN: 어휘, 구문 분석
-
시계열 처리
-
자연어 처리
↑
머신러닝: 자동완성기능, 예측, 문자 간 거리를 계산, 귀여운 강아지 vs 귀여운 바퀴벌레, wegiht
-
회귀분석, 분류분석
-
군집분석
-
선형
1. NLTK 자연어 처리 패키지
텍스트 마이닝: 자연어에서 의미 있는 정보를 찾는 것, 비정형 문서 데이터로부터 문서별 단어의 행렬, 통찰, 의사결정을 지원, 말뭉치
문서: 비정형 데이터 -> Corpus: 저장된 문서 -> TermDocument Matrix: 구조화된 문서 -> 분석: 분류, 군집 분석, 연관, 감성 분석
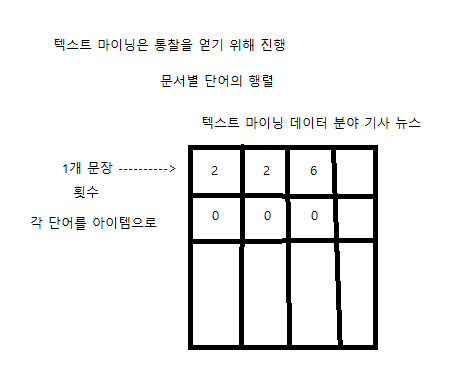
자연어 처리 학습 주제, 선형 결합, 희소 행렬
-
텍스트 전처리
-
개수 기반 단어 표현
-
문서 유사도
-
토픽 모델링
-
연관 분석
-
딥러닝을 이용한 자연어 처리: RNN, LSTM
-
워드 임베딩: Word2vec 패키지
-
텍스트 분류: 스팸 메일 분류
-
태깅
-
번역
NLTK ( 영어권 자연어 처리 ), KNLPy ( 한국어 자연어 처리 ) 패키지가 제공하는 주요 기능
-
말뭉치(corpus)
-
토큰 생성(tokenizing)
-
형태소 분석(morphological analysis): 어근 분석, 명사
-
품사 태깅(POS tagging)
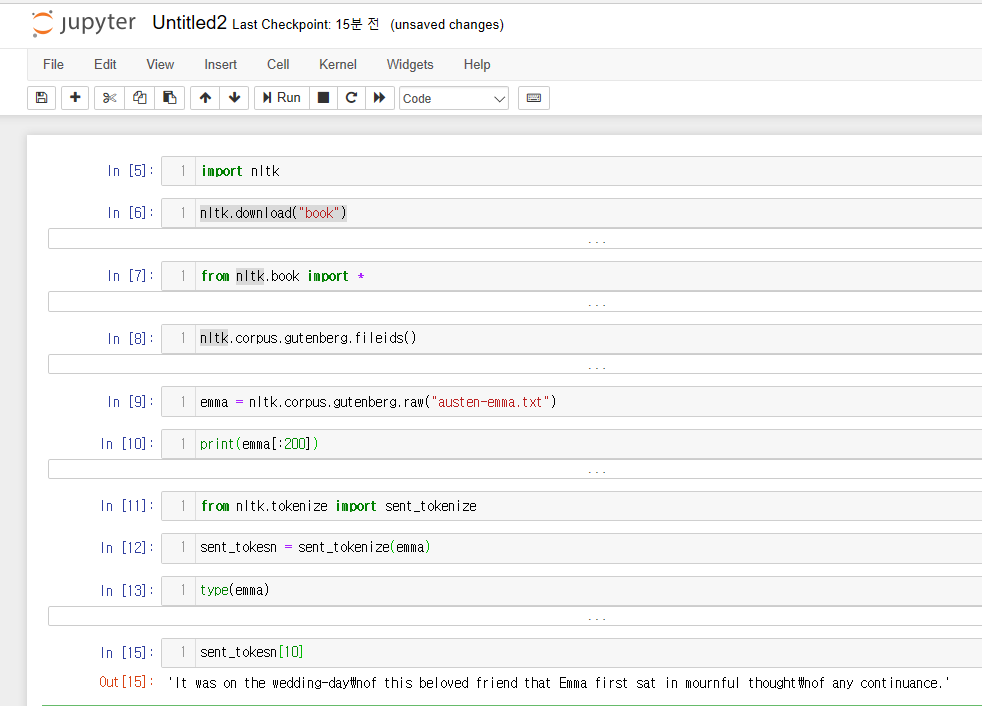
말뭉치 다운로드
nltk.download("book")
형태소 분석
from nltk.tokenize import word_tokenize
->
from nltk.tokenize import RegexpTokenizer
ret = RegexpTokenizer("[\w]+") // 영문자 숫자에 해당하는 것만 토큰으로 만듬
ret.tokenize(emma[50:100])
형태소 분석의 예
-
어간 추출: Stemming
-
원형 복원: Lemmatizing
-
품사 태깅

어간 추출 vs 원형 복원
품사 태깅


Text 클래스, 한글 미지원
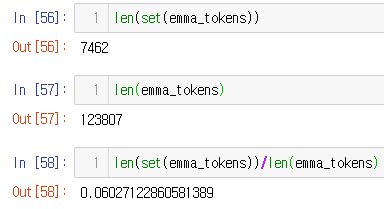
- 단어 개수

- 소설 책 내 단어 개수, 6%
. 탭키


2. 한글 형태소 분석과 워드 클라우드
자연어 처리 용어
-
형태소
-
용언
-
어근
-
어미
-
자모
-
품사
-
어절 분류
-
불용어
-
n-gram
형태소
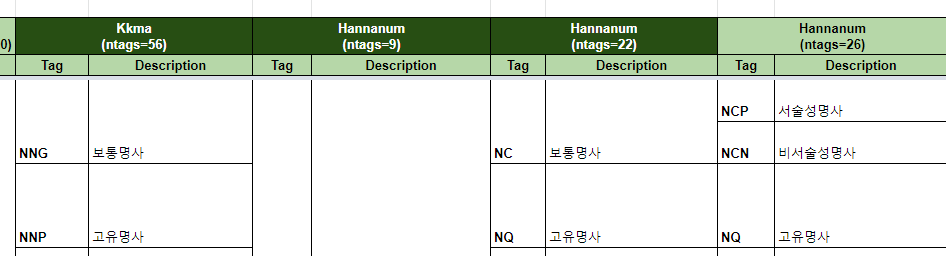
KoNLPy: Korean NLP in Python
https://konlpy.org/en/latest/#api
https://konlpy.org/en/latest/morph/#comparison-between-pos-tagging-classes

https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0


어절 -> 전처리 -> 분석 후보 생성 -> 결합 제약 검사 -> 분석 후보 선택 -> 형태소
형태소 분석 엔진
-
KoNLPy
-
KOMORAN
-
HanNanum
-
KoNLP: KoNLPy는 JPype1 패키지에 의존
https://www.oracle.com/java/technologies/
-> Java SE 8u251
형태소 분석기
Hannanum
-
morphs
-
nouns
-
pos
Komoran
-
morphs
-
nouns
-
pos
KKma
-
morphs
-
nouns
-
pos
법률 말뭉치



워드 임베딩: 단어를 벡터로 표현
-
희소 표현
-
밀집 표현: 단어와 단어 거리
-
워드 임베딩: 위 과정
Word2Vec
-
CBOW: 주변 단어로 중간 단어 예측
-
Skip-Gram: 중간 단어로 주변 단어 예측
pip install gensim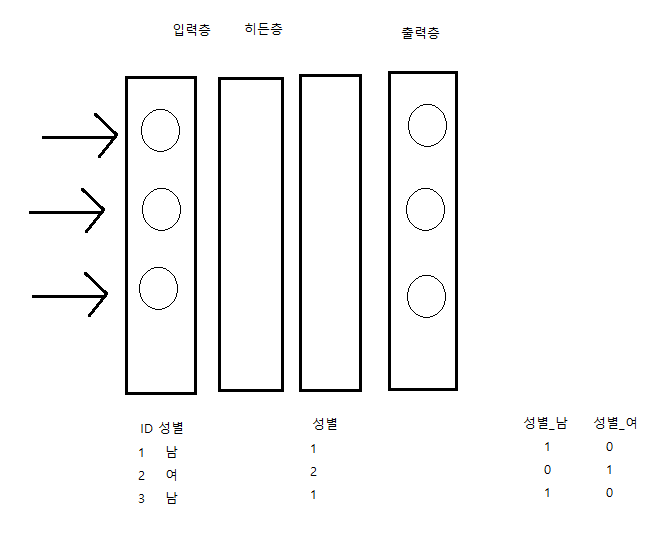
import nltk
nltk.download("book")
from nltk.book import *
nltk.corpus.gutenberg.fileids()
emma = nltk.corpus.gutenberg.raw("austen-emma.txt")
print(emma[:200])
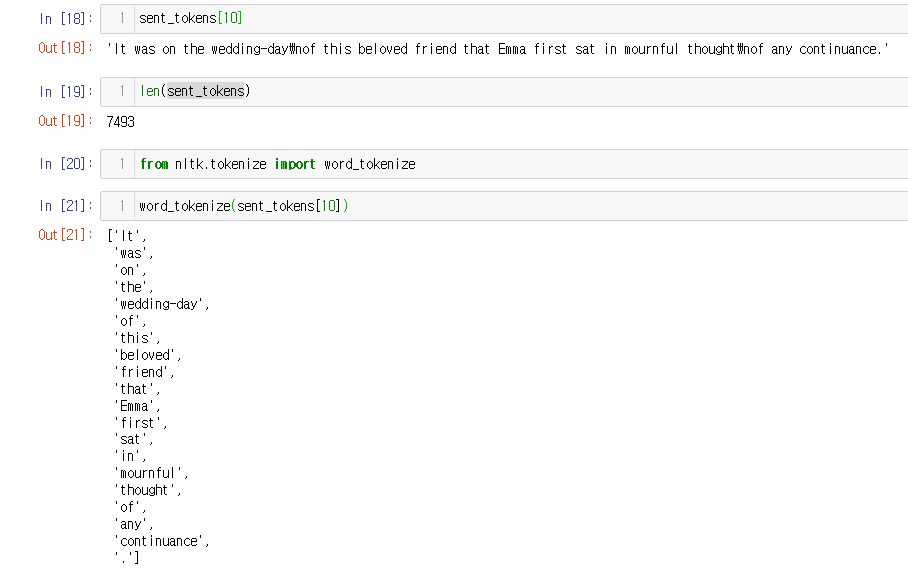
from nltk.tokenize import sent_tokenize
sent_tokens = sent_tokenize(emma)
type(emma)
sent_tokens[10]
len(sent_tokens)
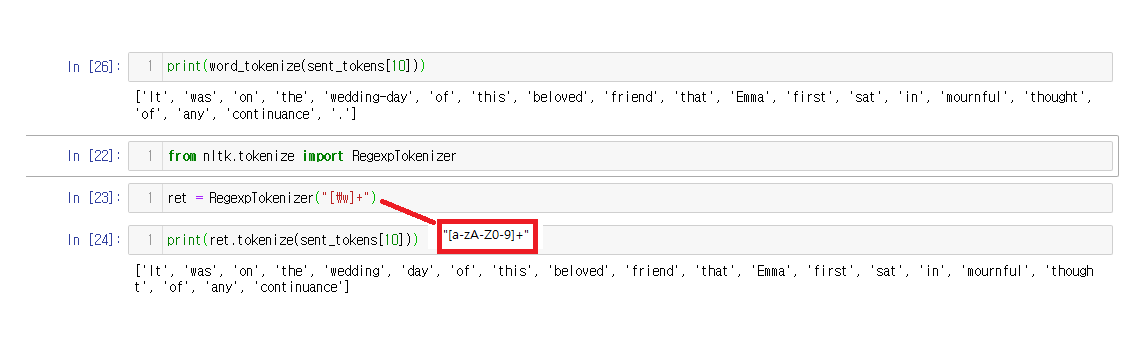
from nltk.tokenize import word_tokenize
print(word_tokenize(sent_tokens[10]))
from nltk.tokenize import RegexpTokenizer
ret = RegexpTokenizer("[\w]+")
print(ret.tokenize(sent_tokens[10]))
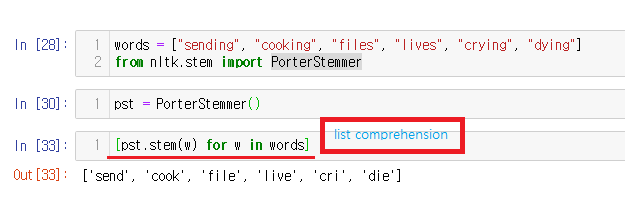
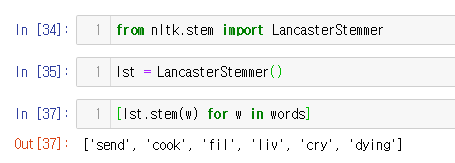
words = ["sending", "cooking", "files", "lives", "crying", "dying"]
from nltk.stem import PorterStemmer
pst = PorterStemmer()
[pst.stem(w) for w in words]
from nltk.stem import LancasterStemmer
lst = LancasterStemmer()
[lst.stem(w) for w in words]
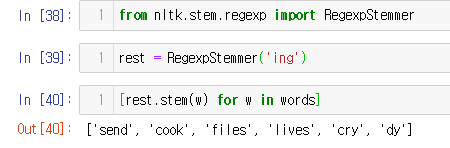
from nltk.stem.regexp import RegexpStemmer
rest = RegexpStemmer('ing')
[rest.stem(w) for w in words]
words = ["sending", "cooking", "files", "lives", "crying", "dying"]
from nltk.stem.snowball import SnowballStemmer
sbst = SnowballStemmer("english")
[rest.stem(w) for w in words]
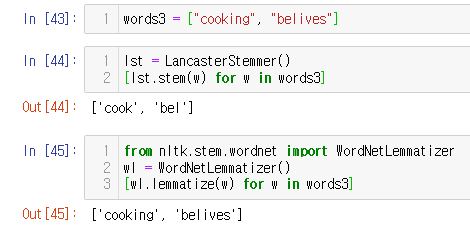
words3 = ["cooking", "belives"]
lst = LancasterStemmer()
[lst.stem(w) for w in words3]
from nltk.stem.wordnet import WordNetLemmatizer
wl = WordNetLemmatizer()
[wl.lemmatize(w) for w in words3]
from nltk.tag import pos_tag
sent_tokens[10]
tagged_list = pos_tag(word_tokenize(sent_tokens[10]))
print(tagged_list)
nouns_list = [ t[0] for t in tagged_list if t[1]=='NN' ]
nouns_list
ret = RegexpTokenizer("[a-zA-Z]{3,}")
emma_tokens = ret.tokenize(emma)
nouns_list = [ t[0] for t in tagged_list if t[1]=='NN' ]
len(set(emma_tokens))
len(emma_tokens)
len(set(emma_tokens))/len(emma_tokens)
from nltk import Text
emma_text = Text(emma_tokens)
type(emma_text)
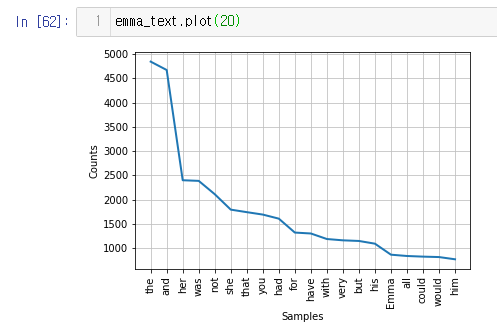
emma_text.plot(20)
emma_text.concordance("Emma", lines=5)
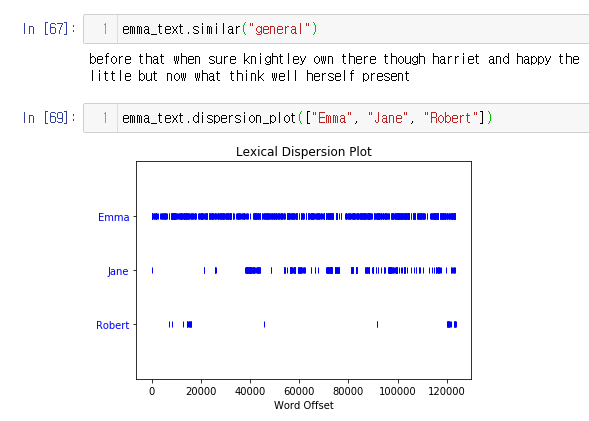
emma_text.similar("general")
emma_text.dispersion_plot(["Emma", "Jane", "Robert"])
ret = RegexpTokenizer("[a-zA-Z]{3,}")
emma_tokens = ret.tokenize(emma)
nouns_list = [ t[0] for t in tagged_list if t[1]=='NN' ]
emma_text = Text(emma_tokens)
emma_text.plot(20)
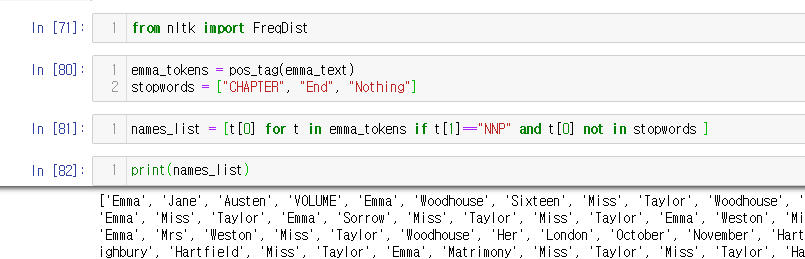
from nltk import FreqDist
emma_tokens = pos_tag(emma_text)
stopwords = ["CHAPTER", "End", "Nothing"]
names_list = [t[0] for t in emma_tokens if t[1]=="NNP" and t[0] not in stopwords ]
emma_df_names = FreqDist(names_list)
emma_df_names
!pip install konlpy
from konlpy.tag import Hannanum
han = Hannanum()
text = "아름답지만 다소 복잡하기만 한 한국어는 전세계에서 13번째로 많이 사용되는 언어입니다."
han.analyze(text)
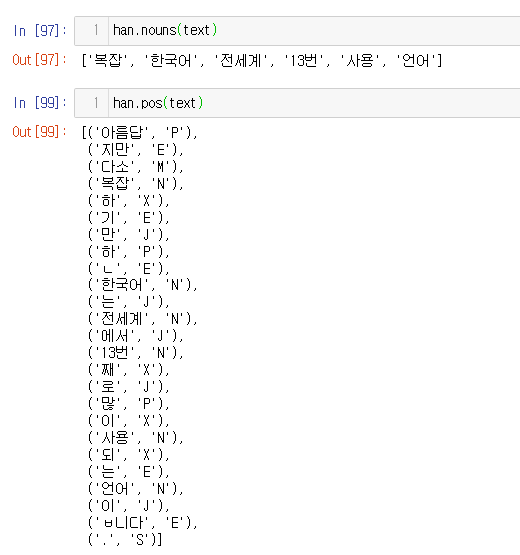
han.nouns(text)
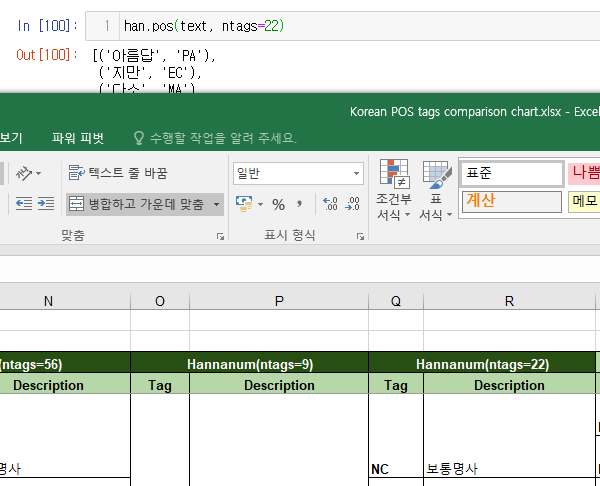
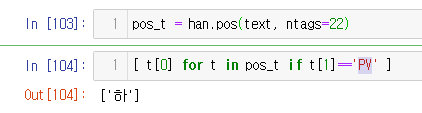
pos_t = han.pos(text, ntags=22)
[ t[0] for t in pos_t if t[1]=='PV' ]
!pip install wordcloud
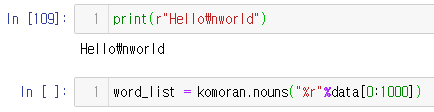
print(r"Hello\nworld")
word_list = komoran.nouns("%r"%data[0:1000])
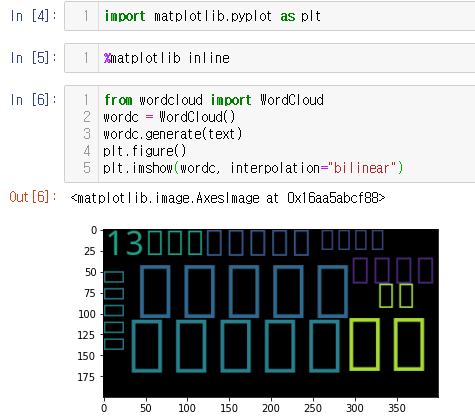
import matplotlib.pyplot as plt
%matplotlib inline
from wordcloud import WordCloud
wordc = WordCloud()
wordc.generate(text)
plt.figure()
plt.imshow(wordc, interpolation="bilinear")
!pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install
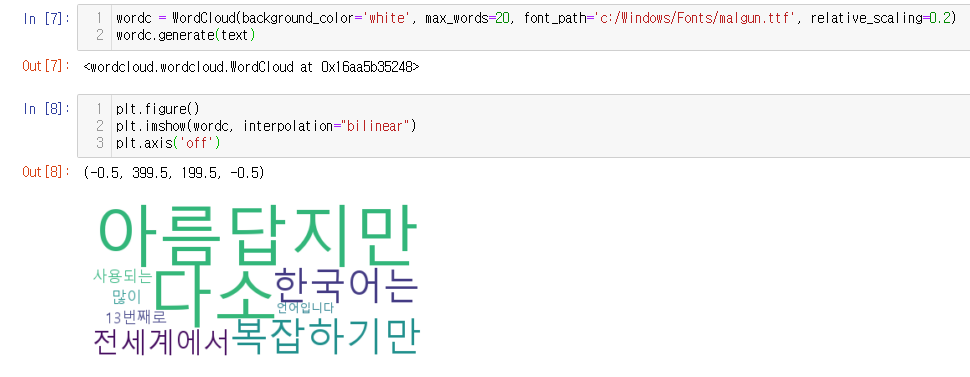
wordc = WordCloud(background_color='white', max_words=20, font_path='c:/Windows/Fonts/malgun.ttf', relative_scaling=0.2)
wordc.generate(text)
plt.figure()
plt.imshow(wordc, interpolation="bilinear")
plt.axis('off')
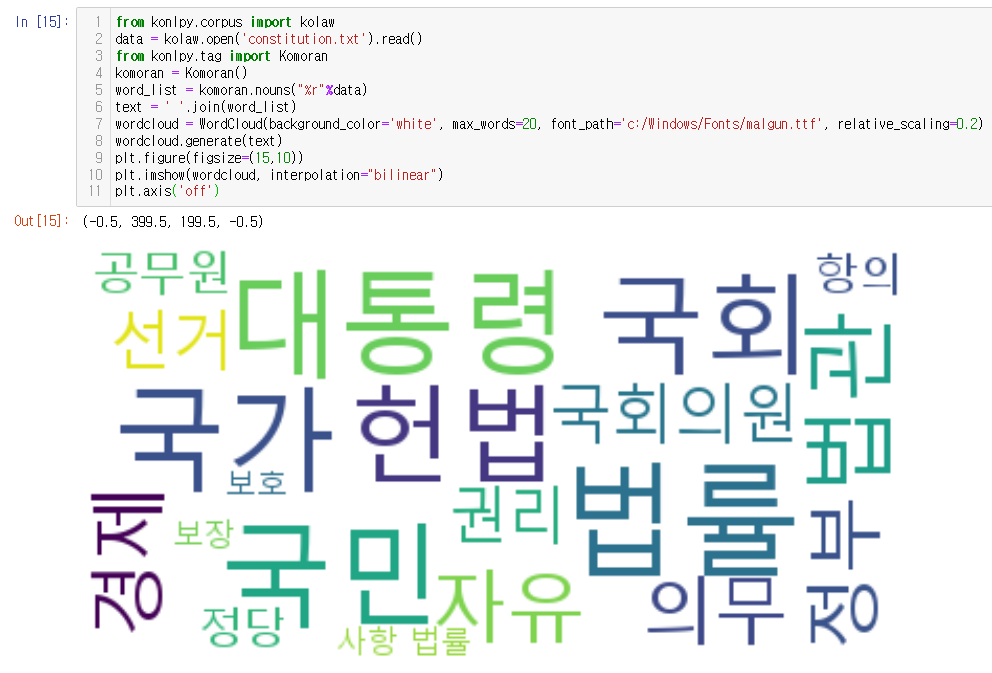
from konlpy.corpus import kolaw
data = kolaw.open('constitution.txt').read()
from konlpy.tag import Komoran
komoran = Komoran()
word_list = komoran.nouns("%r"%data)
text = ' '.join(word_list)
wordcloud = WordCloud(background_color='white', max_words=20, font_path='c:/Windows/Fonts/malgun.ttf', relative_scaling=0.2)
wordcloud.generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
from PIL import Image
import numpy as np
img = Image.open("south_korea.png").convert("RGBA")
mask = Image.new("RGB", img.size, (255,255,255))
mask.paste(img,img)
mask = np.array(mask)
wordcloud = WordCloud(background_color='white', max_words=2000, font_path='c:/Windows/Fonts/malgun.ttf', mask=mask, random_state=42)
wordcloud.generate(text)
wordcloud.to_file("result1.png")
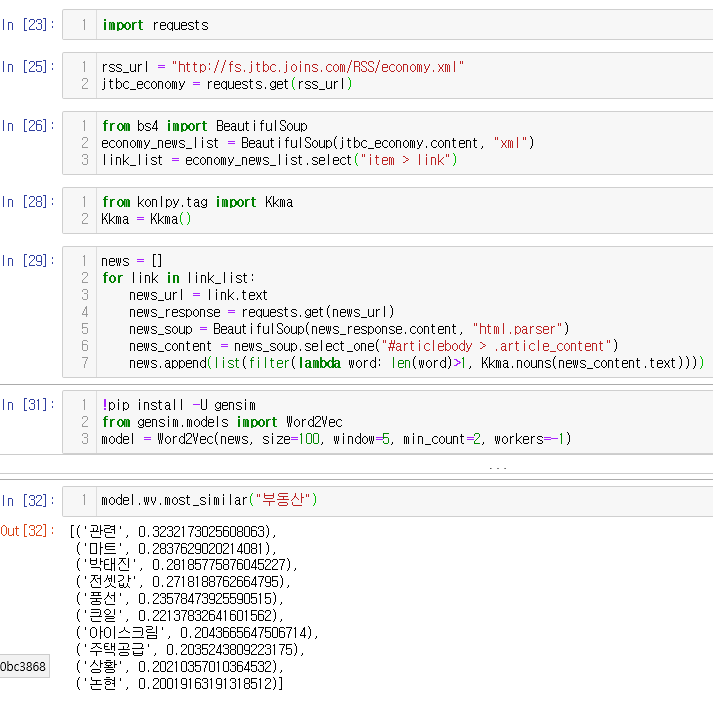
import requests
rss_url = "http://fs.jtbc.joins.com/RSS/economy.xml"
jtbc_economy = requests.get(rss_url)
from bs4 import BeautifulSoup
economy_news_list = BeautifulSoup(jtbc_economy.content, "xml")
link_list = economy_news_list.select("item > link")
from konlpy.tag import Kkma
Kkma = Kkma()
news = []
for link in link_list:
news_url = link.text
news_response = requests.get(news_url)
news_soup = BeautifulSoup(news_response.content, "html.parser")
news_content = news_soup.select_one("#articlebody > .article_content")
news.append(list(filter(lambda word: len(word)>1, Kkma.nouns(news_content.text))))
!pip install -U gensim
from gensim.models import Word2Vec
model = Word2Vec(news, size=100, window=5, min_count=2, workers=-1)
model.wv.most_similar("부동산")3.인공신경망
답이 있어야 함
분류, 회귀, 군집 (X, y가 없음)
인공지능 암흑기
-
과적합
-
지역최적값
-
오차가 점점 줄어들어야 하나 줄어들지 않는 현상, wegiht 가 그대로, 학습이 안됨
의사결정나무, 선형 데이타
CNN, ImageNet Challenge 2012
얇은 인공지능: 딥러닝, 머신러닝
-> 깊은 인공지능
인간의 뉴런 구조
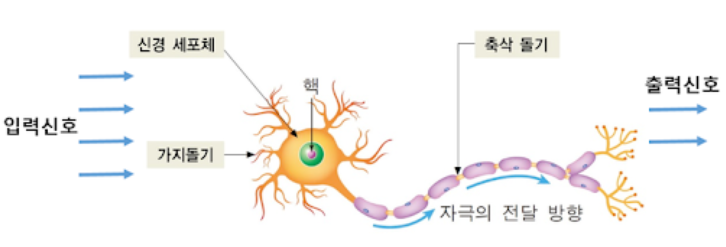
인공 뉴런의 구조
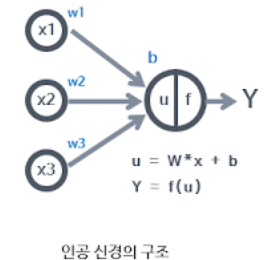
weight: 학습을 통해서 얻어야 할 값
f: 활성화 함수, 함수 선택이 적절해야 함
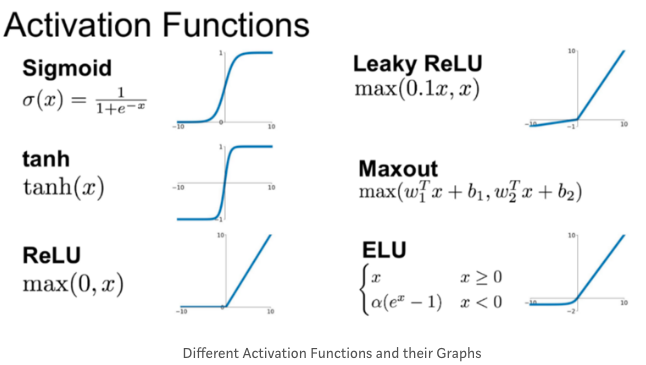
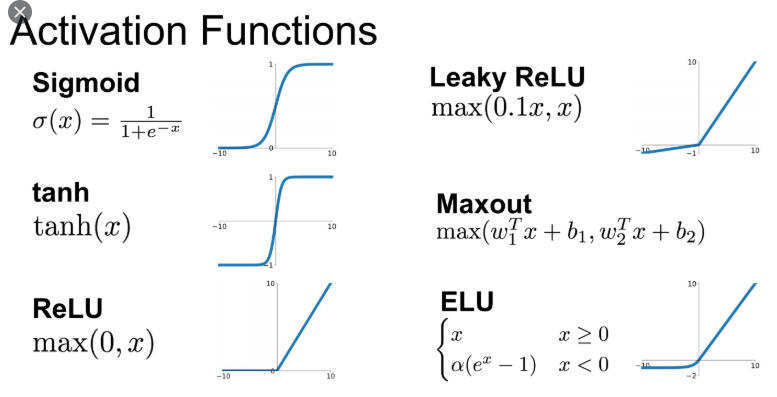
대표적인 활성화 함수 종류: 뉴런이 다음 출력으로 내보내기 위해 사용
-
Softmax: y를 합치면 1이 됨, 분류의 출력 체계에서 활용
-
Sigmoid
-
tanh(x)
-
Binary step
-
Gaussian
-
ReLU
인공신경망: 입력층, 은닉층, 출력층
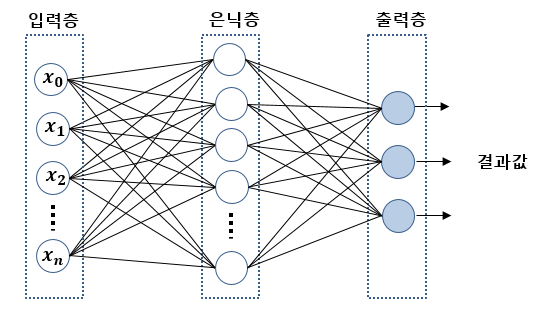
입력층: 입력하는 변수의 수
출력증:
은닉층:
다층 신경망(MLP, DNN): 은닉층이 여러개
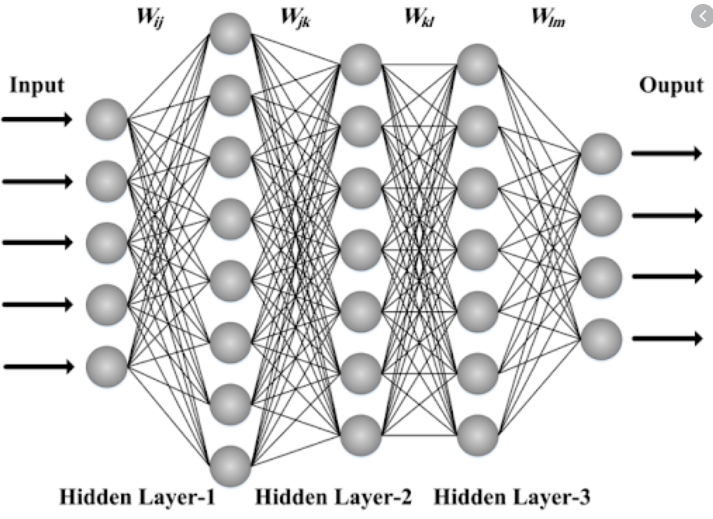
DNN Layer
Hidden1: 뉴런의 수 50개, 활성화 함수->relu
Hidden2: 뉴런의 수 30개, 활성화 함수->relu
Output: 뉴런의 수 10개, 활성화 함수->softmax
손실 함수: 크로스엔트로피
옵티마이저: 경사하강법, 차이=미분, 기울기, 미분값이 작을수록 오차가 적음, 학습률: 0.001
배치 크기: 100,
학습 횟수: 200회
-
MAE
-
MSE
-
RMSE: 표준편차
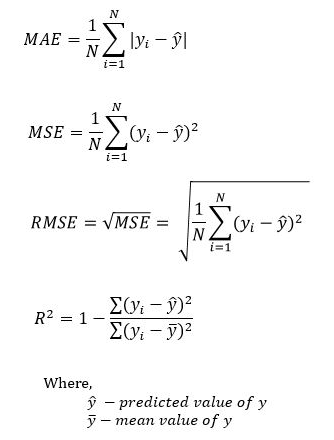
MLPClassifier
import seaborn as sns
iris = sns.load_dataset("iris")
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(iris.species)
iris.species = le.transform(iris.species)
from sklearn.model_selection import train_test_split
iris_X = iris.iloc[:,:-1]
iris_y = iris.species # iris.iloc[:,-1]
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size=0.3, random_state=1)
train_X.shape, test_X.shape
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(50,50,30), max_iter=500)
mlp.fit(train_X, train_y)
pred = mlp.predict(test_X)
pred
mlp.score(test_X, test_y)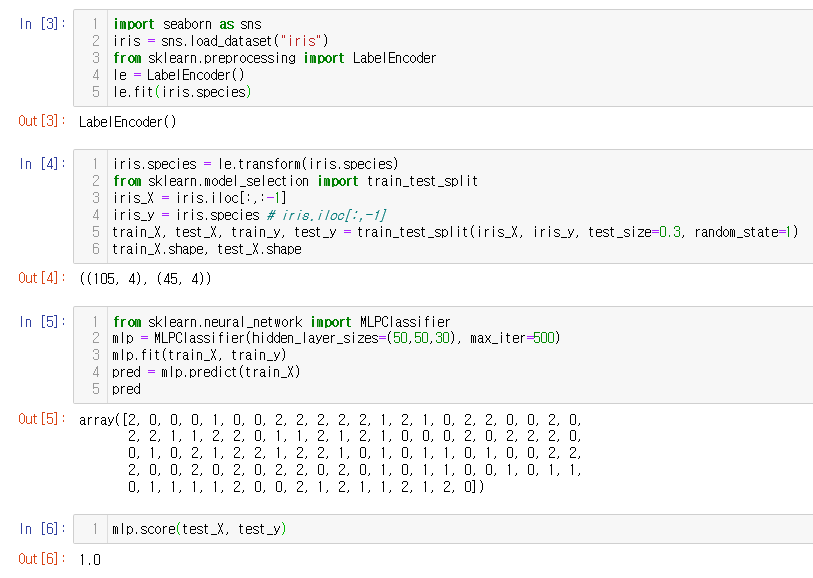
https://archive.ics.uci.edu/ml/index.php
https://archive.ics.uci.edu/ml/datasets/wine+quality
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
MLClassifier를 이용한 winequality 데이터 등급 분류
#from IPython.core.display import display, HTML
#display(HTML("""<style>div."""))
import pandas as pd
redwine = pd.read_csv("winequality-red.csv", sep=";")
redwine.head()
redwine_X = redwine.iloc[:, :-1]
redwine_y = redwine.quality # redwine.iloc[:, -1]
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(redwine_X, redwine_y, test_size=0.3, random_state=1)
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(hidden_layer_sizes=(50,50,30), max_iter=500) #, verbose=true)
model.fit(train_X, train_y)
model.score(test_X, test_y)
pred = model.predict(test_X)
pd.crosstab(test_y, pred) 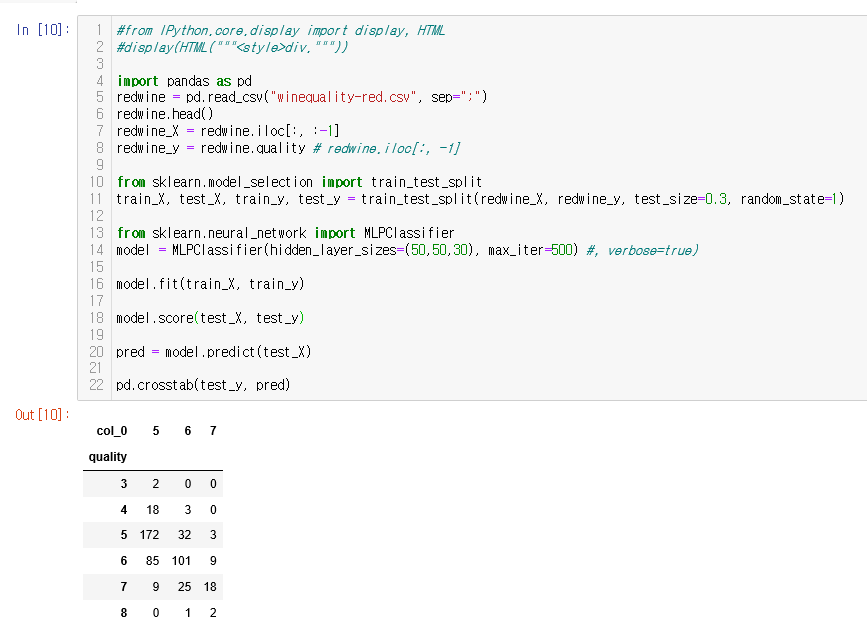
Hadoop, Spark
인공신경망 모형, 딥러닝 프레임워크, 정의 시 고려 사항
-
레이어의 수
-
뉴런의 수
-
활성화 함수
-
손실함수
-
옵티마이저
-
학습률
-
학습 횟수
-
배치크기
Scikit-learn MLPClassifier, 머신러닝 영역에 초점 VS Tensorflow DNNClassifier, 딥러닝에 초점
4. 케라스를 이용한 인공신경망 구현
Keras, https://keras.io/
-
유저가 손쉽게 딥 러닝을 구현할 수 있도록 도와주는 상위 레벨의 인터페이스
-
히든 레이어의 행렬 자동화
conda vs pip 로 텐서플로우 설치 시 서로 버전이 다름
Sequential model vs Functional API
dropout, 오버핏(overfit)을 줄임
conda install tensorflow
keras를 이용한 iris 데이터 종 분류
#from IPython.core.display import display, HTML
#display(HTML(
#"""<style>
#div.container { width:100% !import; }
#div.CodeMirror {font-family: Consolas; font-size: 16pt;}
#div.output { font-size:16pt; font_weight: bold;}
#div.input { font-family; Consolas; font-size: 16pt; }
#div.prompt { min-width: 100px; }
#</style>
#"""))
import tensorflow # conda install tensorflow
#tensorflow.__version__
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import seaborn as sns
iris = sns.load_dataset("iris")
iris_X = iris.iloc[:, :-1]
iris_y = iris.iloc[:, -1]
import pandas as pd
iris_onehot = pd.get_dummies(iris_y)
#iris_onehot.to_numpy()
model = Sequential()
model.add(Dense(4, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(3, activation="softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]) #metrics=["acc"])
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_onehot, test_size=0.3)
train_X.to_numpy().shape, train_y.to_numpy().shape
model.fit( train_X.to_numpy(), train_y.to_numpy(), batch_size=50, epochs=200, verbose=1 )
model.predict(test_X)
model.evaluate(test_X, test_y)
import numpy as np
pred = np.argmax(model.predict(test_X), axis=1) # 각 클래스별 확률을 출력하므로 argmax를 이용해서 가장 큰 값의 열 인덱스
pred # 예측한 값
np.argmax(test_y.to_numpy(), axis=1) # 테스트 데이터의 정답
pd.crosstab(np.argmax(test_y.to_numpy(), axis=1), pred) # 교차 분류표
model.evaluate(test_X, test_y) Optimizer
-
SGD
-
RMSgrop
-
Adagrad
-
Adadelta
-
Adam: 최적 값을 지나 좀 더 학습을 진행
-
Adamax
-
Nadam
Activation functions
-
softmax
-
elu
-
selu
-
softsign
-
relu
-
tanh
-
sigmoid
-
hard_sigmoid
Advanced Activation functions
-
LeakyReLU
-
PReLU
-
ELU
-
ThresholdedReLU
-
Softmax: 출력층에서 사용
-
ReLU: 영상처리
배치 정규화
불안정화가 일어나는 이유 - Internal Covariance Shift
분산이 0인 열은 학습에서 제외 시켜야 함, weight = 0
Dense, 은닉층 -> Dropout -> BatchNormalization -> Dense, 은닉층

손실함수
-
mean_squared_error
-
mean_absolute_error
keras를 이용한 winequality 데이터 등급 분류
import pandas as pd
import numpy as np
redwine = pd.read_csv("winequality-red.csv", sep=";")
redwine_X = redwine.iloc[:, :-1].to_numpy()
redwine_y = redwine.iloc[:, -1]
redwine_onehot = pd.get_dummies(redwine_y).to_numpy()
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(redwine_X, redwine_onehot, test_size=0.3)
from tensorflow.keras.models import Sequential
model = Sequential()
from tensorflow.keras.layers import Input, Dense
model.add(Input(11))
model.add(Dense(50, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(6, activation="softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(train_X, train_y, batch_size=200, epochs=200, verbose=1)
import numpy as np
pred = np.argmax(model.predict(test_X), axis=1)
pred+3 # 등급이 3등급부터이므로 예측한 값을 보정해 줘야 함
pd.crosstab(np.argmax(test_y, axis=1)+3, pred+3) # 교차 분류표
model.evaluate(test_X, test_y)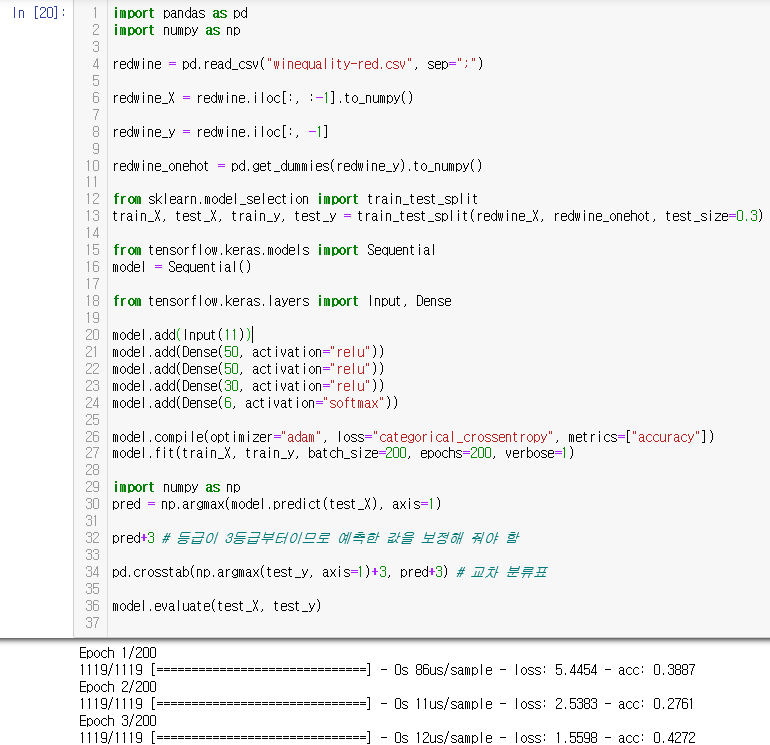
Callback: 학습 시 특정 조건이 되면 실행되는 객체
-
ModelCheckPoint
-
EarlyStopping
-
LearningRateScheduler
-
TensroBoard
-
CSVLogger
import pandas as pd
import numpy as np
redwine = pd.read_csv("winequality-red.csv", sep=";")
redwine_X = redwine.iloc[:, :-1].to_numpy()
redwine_y = redwine.iloc[:, -1]
redwine_onehot = pd.get_dummies(redwine_y).to_numpy()
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(redwine_X, redwine_onehot, test_size=0.3)
from tensorflow.keras.models import Sequential
model = Sequential()
from tensorflow.keras.layers import Input, Dense
model.add(Input(11))
model.add(Dense(50, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(6, activation="softmax"))
from tensorflow.keras.callbacks import ModelCheckpoint #, EarlyStopping
checkpoint = ModelCheckpoint(filepath="redwine-{epoch:03d}-{val_acc:.4f}.hdf5", # or H5 확장자
monitor="val_acc", # 모니터링 할 val_ 테스트 데이터 지정 필요 , validation_split=0.2 or validation_data
save_best_only=True, # mode = 'auto', save_weight_only=False
verbose=1 # 로그를 자세히 , save_best_only=True
)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(train_X, train_y,
validation_data=(test_X, test_y), # 정답 데이타
callbacks=[checkpoint],
batch_size=200, epochs=200, verbose=1)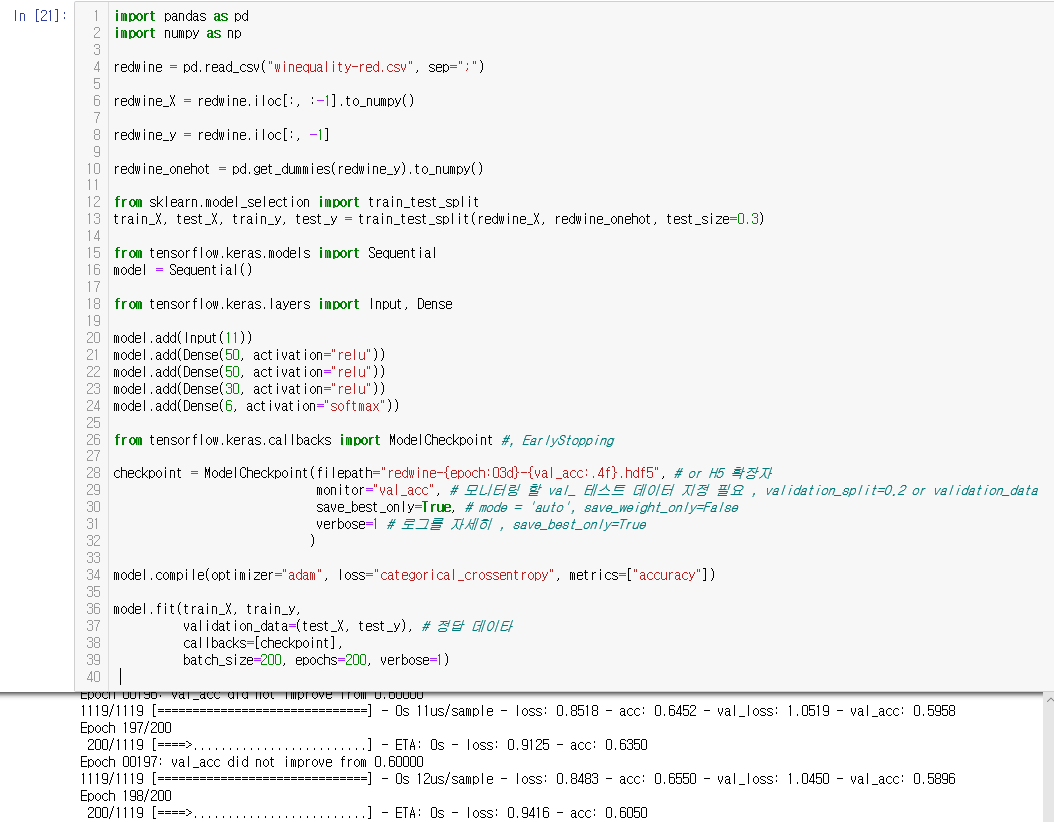
tensorflow install anaconda prompt install -> 1.x
pip -> 2.0
in anaconda prompt
텐서플로우 설치 확인
conda list tensorflow 텐서플로우 삭제
conda remove tensorflow
conda remove tensorflow-base
pip uninstall tensorflow-estimator pip로 텐서플로우 2.2.0 설치
pip install tensorflow==2.2.0
anaconda prompt install -> 1.x pip -> 2.0
in anaconda prompt
텐서플로우 설치 확인
conda list tensorflow 텐서플로우 삭제
conda remove tensorflow
conda remove tensorflow-base
pip uninstall tensorflow-estimator pip로 텐서플로우 2.2.0 설치
pip install tensorflow==2.2.0
pip install tensorflow-cpu
conda install tensorflow윈도우 cmd
pscp.exe model.py userid@ip-address:/home/userid/data/model.py리눅스 터미널
python model.py &
ps -ef | grep python윈도우 cmd 창에서
pscp userid@ip-address:/home/userid/data/...h5 model...h5Early Stopping Callback
import pandas as pd
import numpy as np
redwine = pd.read_csv("winequality-red.csv", sep=";")
redwine_X = redwine.iloc[:, :-1].to_numpy()
redwine_y = redwine.iloc[:, -1]
redwine_onehot = pd.get_dummies(redwine_y).to_numpy()
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(redwine_X, redwine_onehot, test_size=0.3)
from tensorflow.keras.models import Sequential
model = Sequential()
from tensorflow.keras.layers import Input, Dense
model.add(Input(11))
model.add(Dense(50, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(6, activation="softmax"))
from tensorflow.keras.callbacks import ModelCheckpoint #, EarlyStopping
checkpoint = ModelCheckpoint(filepath="redwine-{epoch:03d}-{val_acc:.4f}.hdf5", # or H5 확장자
monitor="val_acc", # 모니터링 할 val_ 테스트 데이터 지정 필요 , validation_split=0.2 or validation_data
save_best_only=True, # mode = 'auto', save_weight_only=False
verbose=1 # 로그를 자세히 , save_best_only=True
)
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor="val_acc", patience=10)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(train_X, train_y,
validation_data=(test_X, test_y), # 정답 데이타
callbacks=[checkpoint, early_stopping],
batch_size=200, epochs=2000, verbose=1)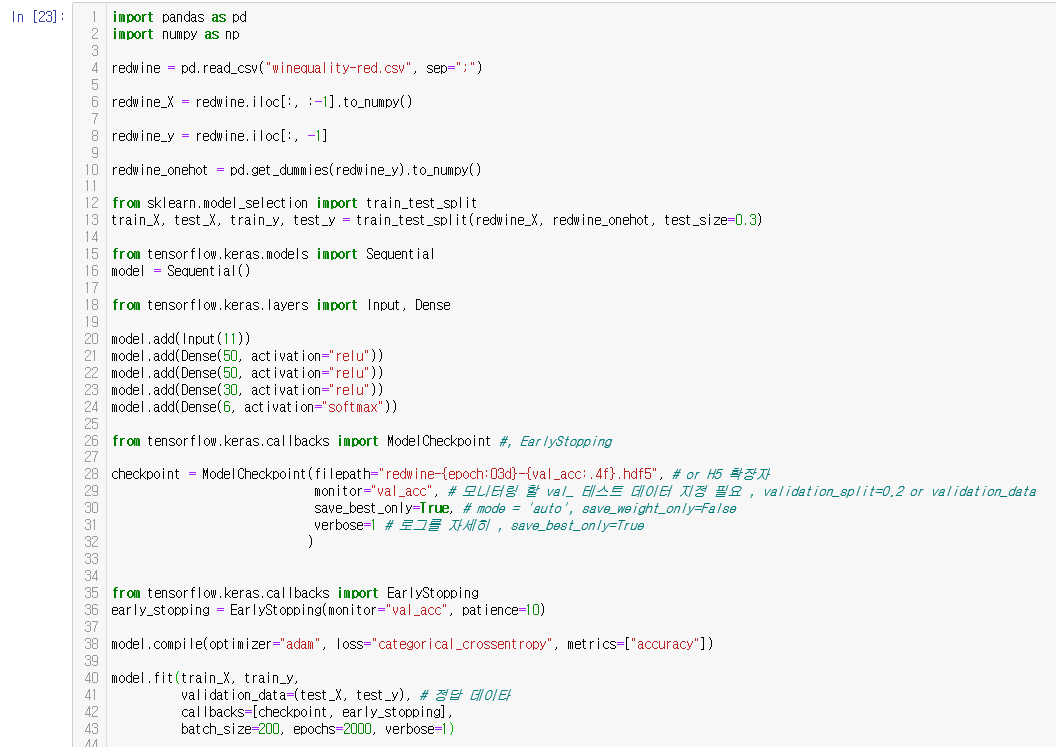
import tensorflow
import pandas as pd
import numpy as np
redwine = pd.read_csv("winequality-red.csv", sep=";")
redwine_X = redwine.iloc[:, :-1].to_numpy()
redwine_y = redwine.iloc[:, -1]
redwine_onehot = pd.get_dummies(redwine_y).to_numpy()
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(redwine_X, redwine_onehot, test_size=0.3)
from tensorflow.keras.models import Sequential
model = Sequential()
from tensorflow.keras.layers import Input, Dense
model.add(Input(11))
model.add(Dense(50, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(6, activation="softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.load_weights("redwine-062-0.5521.hdf5")
model.evaluate(test_X, test_y)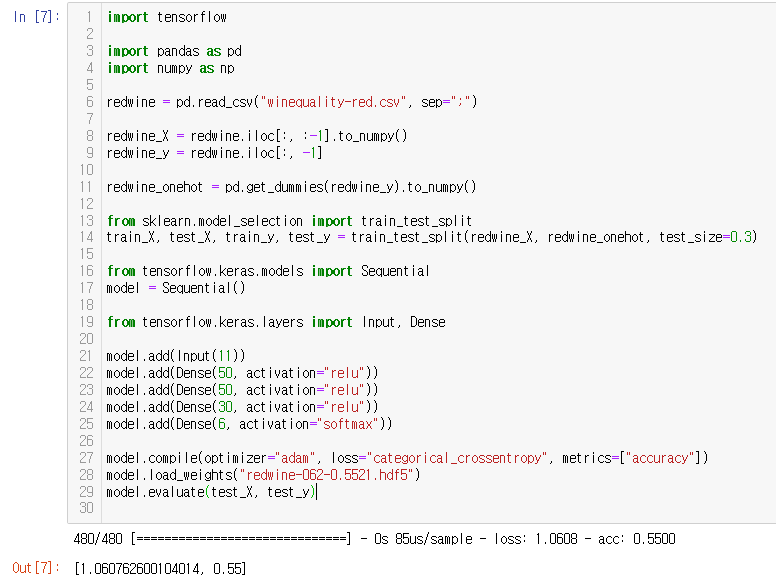
5. RNN
저장한 모델 불러와 예측하기
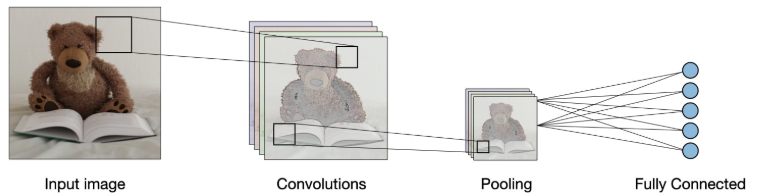
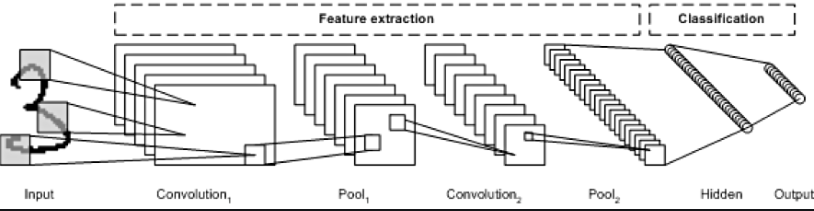
CNN, 영상 필터 학습, 합성곱
RNN, 순환 신경망
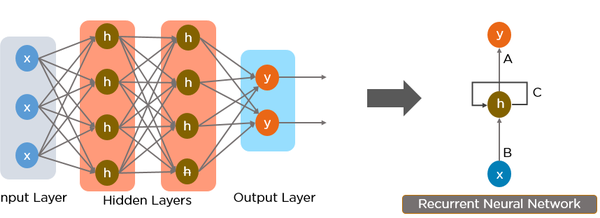
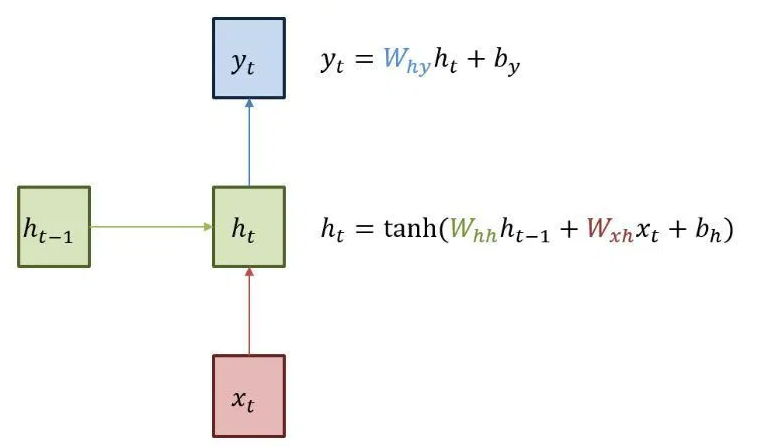
이전에 학습했던 y 값
이전 y 값
- 이전 학습한 내용을 다음 학습 할 내용에 전달
양방향 순환 신경망
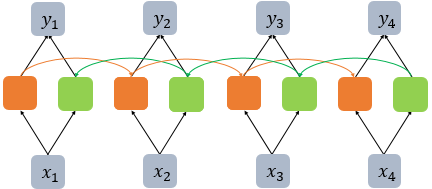
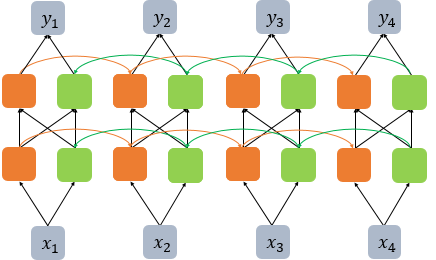
문맥을 예측해서 다음 단어 예측해보기
vocab_size 희소행렬, 한개의 문장을 가지고 여러개의 행을 만듬, index 1부터 시작 됨
Embedding
SimpleRNN
nltk, keras_preprocessing.text
형태소 분류
경마장에 있는 말이 뛰고 있다
-> 경마장에 있는 말이, 있는 말이, 말이 뛰고, ---
pad_sequences, padding='pre' 데이터의 앞을 0으로 채움
text = """경마장에 있는 말이 뛰고 있다\n
그의 말이 법이다\n
가는 말이 고와야 오는 말이 곱다\n"""
from keras_preprocessing.text import Tokenizer
t = Tokenizer()
t.fit_on_texts([text])
encoded = t.texts_to_sequences([text])[0]
vocab_size = len(t.word_index) + 1
print('단어 집합의 크기: %d' % vocab_size)
print(t.word_index)
sequences = list()
for line in text.split('\n'):
encoded = t.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)
print('훈련 데이터의 개수: %d' % len(sequences))
print(sequences)
print(max(len(I) for I in sequences))
from keras.preprocessing.sequence import pad_sequences
sequences = pad_sequences(sequences, maxlen=6, padding='pre')
import numpy as np
sequences = np.array(sequences)
X = sequences[:,:-1]
y = sequences[:,-1]
print(X)
print(y)
from keras.utils import to_categorical
y = to_categorical(y, num_classes=vocab_size)
print(y)
from keras.layers import Embedding, Dense, SimpleRNN
from keras.models import Sequential
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length=5))
model.add(SimpleRNN(32))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=200, verbose=2)
def sentence_generation(model, t, current_word, n):
init_word = current_word
sentence = ''
for _ in range(n):
encoded = t.texts_to_sequences([current_word])[0]
encoded = pad_sequences([encoded], maxlen=5, padding='pre')
result = mpdel.predict_classes(encoded, verbose=0)
for word, index in t.word_index.items():
if index == result:
break
current_word = current_word + ' ' + word
sentence = sentence + ' ' + word
sentence = init_word + sentence
return sentence
print(sentence_gwneration(model, t, '경마장에', 4))
print(sentence_generation(model, t, '그의', 2))
model_json = model.to_json()
with open("redwin.json", "r") as json_file:
loaded_model_json = json_file.read()
model = model_from_json(loaded_model_json)
model.evaluate(test_X, test_y) # compile 해야 사용할 수 있음6. LSTM
RNN, 전거만 기억하고 있음
LSTM, 이전것을 기억하고 있음
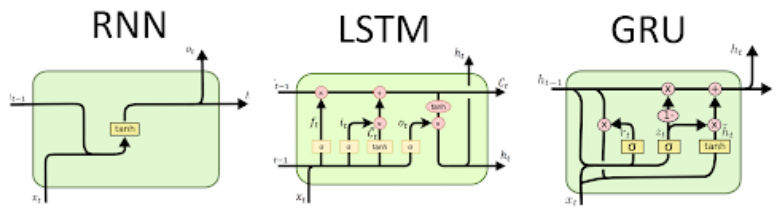
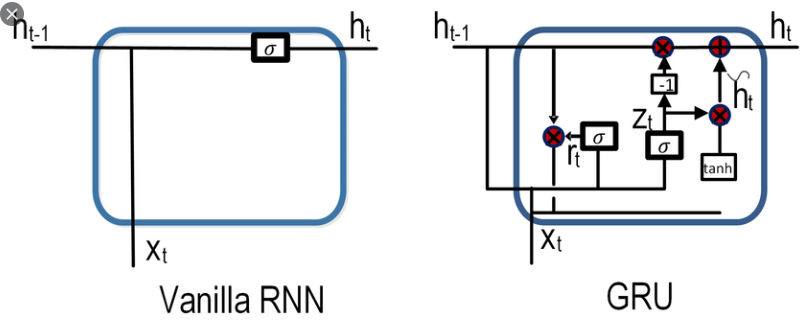
np.uint8
PIL
opencv-python
N차원 배열 다루기
데이터프레임
데이터 시각화
웹데이터 수집
