1. Sequence-to-Sequence Learning
Sequence to Sequence model의 문제점은 입력은 sequential data인데 output이 different sequential data라는 점이다. 이의 응용으로는 대화 시스템, 대화 인식, 번역 등이 있다.
input과 output의 길이는 다르므로 일대일 대응이 아니다.
고정되어 일치하지 않는다.

Text generation Modeling by Prediction/ Synthesis
w1부터 wt까지 주어지면 w(t+1)을 예측하는 것
simple recurrent neural network model이다. 즉, 출력을 다시 입력으로 쓰는 것이다.
모델의 입력으로는 unique 원핫 인코딩 벡터가 들어간다. 이런 벡터들이 더 밀도 있고, 낮은 차원의 표현으로 된다.
이 모델의 메커니즘으로는 LSTM unit을 은닉층으로 활용한다. LSTM unit은 긴시간 동안 의존성을 잘 캡쳐한다.
출력으로는 각 단계마다 그 연속해서 오는 단어를 예측하는 확률분포를 만들어낸다.
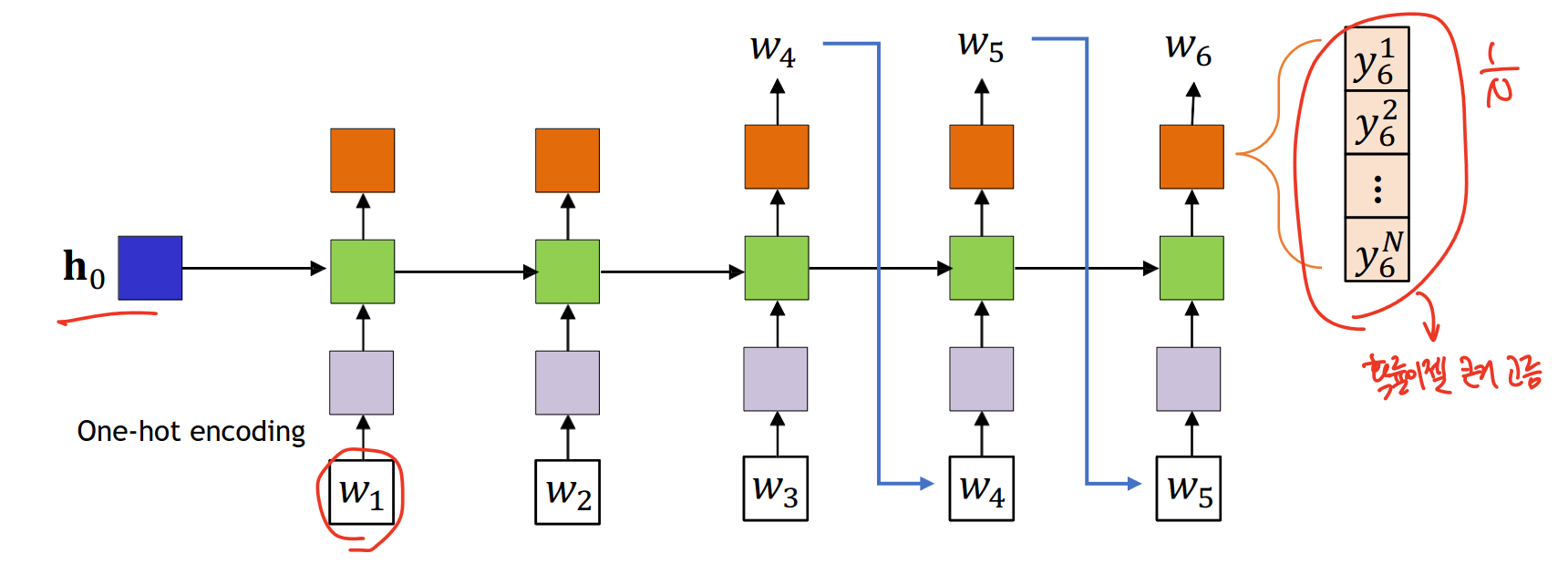
이러한 과정을 반복적으로 수행한다. 그렇다면 우리는 언제 이 과정을 멈추는가?
문맥 없이는 주어진 문장으로는 그 끝이 언젠지를 모른다. 그래서 두개의 distinct marker를 사용한다.
sos는 문장의 시작을, eos는 문장의 끝을 의미한다.
sos는 굳이 안해도 되지만 eos는 필수적으로 써야한다. 가끔 eos가 문장의 끝이자 시작임을 말하기도 한다.
input의 끝부분 블록은 모든 정보를 다 가지고 있다.
Seq2Seq model with RNN Encoder and Decoder
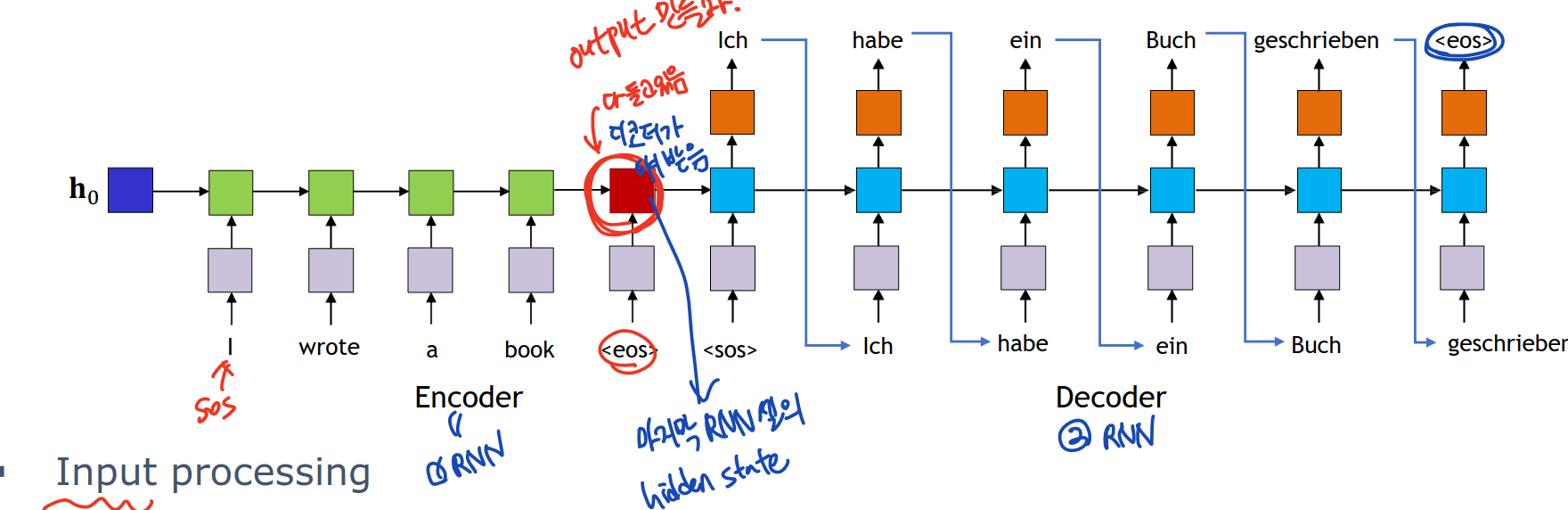
eos의 hidden activation은 문장에 대한 모든 정보를 다 가지고 있다. 즉 encoder의 마지막 hidden state인 eos는 전체 입력 문장을 encapsulate한다.
두번째 RNN인 decoder 부분은 encoder의 마지막 부분을 초기화하고 출력을 생성한다. 각각의 출력이 그 다음 부분에서의 입력이 된다. 이 과정은 decoder output이 eos일 때까지 반복된다.
Encoder
각 단어를 임베딩 층 사용해서 dense vector representation으로 만들고 context를 capture한다.
Decoder
각각의 embedding layer를 사용하여 target word를 벡터로 바꾼다. FC layer가 RNN 결과를 원하는 단어 사이즈로 만든다.
Training Seq2seq Model
Forward Process, Backward Process가 있다.
Forward Process는 모델의 출력이 확률 분포로 나와서 각 단어마다 젤 큰걸로 선택한다.
Backward Process는 예측한 출력값과 실제 target 순서 차이를 계산한다. backpropagation 이용
Greedy Search for Output Sequence Generation
greedy search를 통해서 가장 확률 높은 애를 선택한다. suboptimal함
틀린 예시도 있음

Exhaustive Search for Output Sequence Generation
모든 가능한 순서 결과를 계산해서 가장 높은 확률의 순서를 고르는 것, 계산 비용이 아주 많이 듦
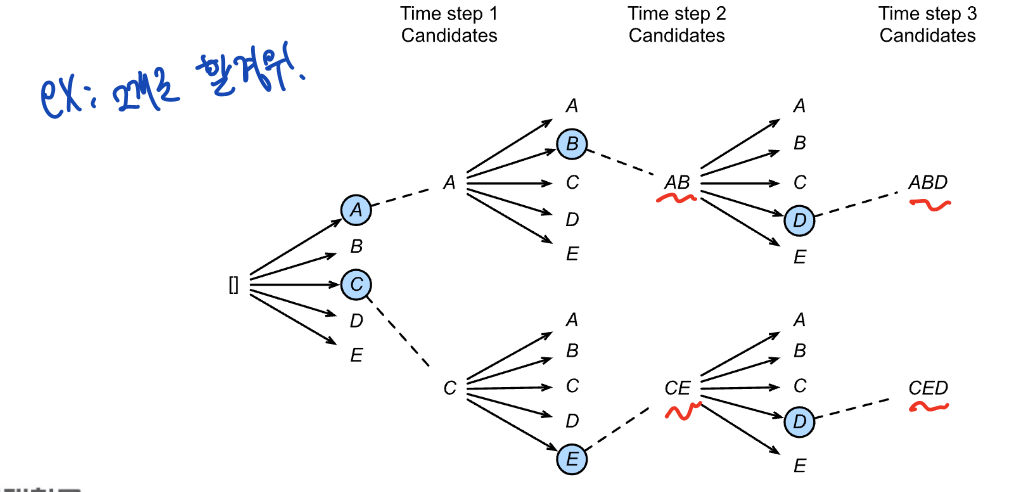
Beam Search for output Sequence Generation
beam search는 휴리스틱 search 알고리즘이다. 가장 확률이 높은 top k sequence들을 계속 유지하면서 서치하는 것
이점: exhaustive 보다 효율적이고, greedy보다 더 나은 sequence를 찾을 확률이 크다.
2. Attention
Seq2seq model의 단점
입력의 전체 정보가 하나의 vector에 담겨있으므로 information bottleneck이 일어난다.
긴 입력 문장 같은 경우에는 모든 필요한 정보를 다 가지고 있지 못한다.
출력은 항상 입력과 같은 길이의 벡터로 변환하므로 필요한 정보가 누락될 수도 있다.
입력은 출력과 directly 일치한다. 이는 direct correlation에서 loss가 발생 할 수 있다.
Enhance Seq2seq model
모든 encoder hidden state들의 값을 평균내서 결합하자!!
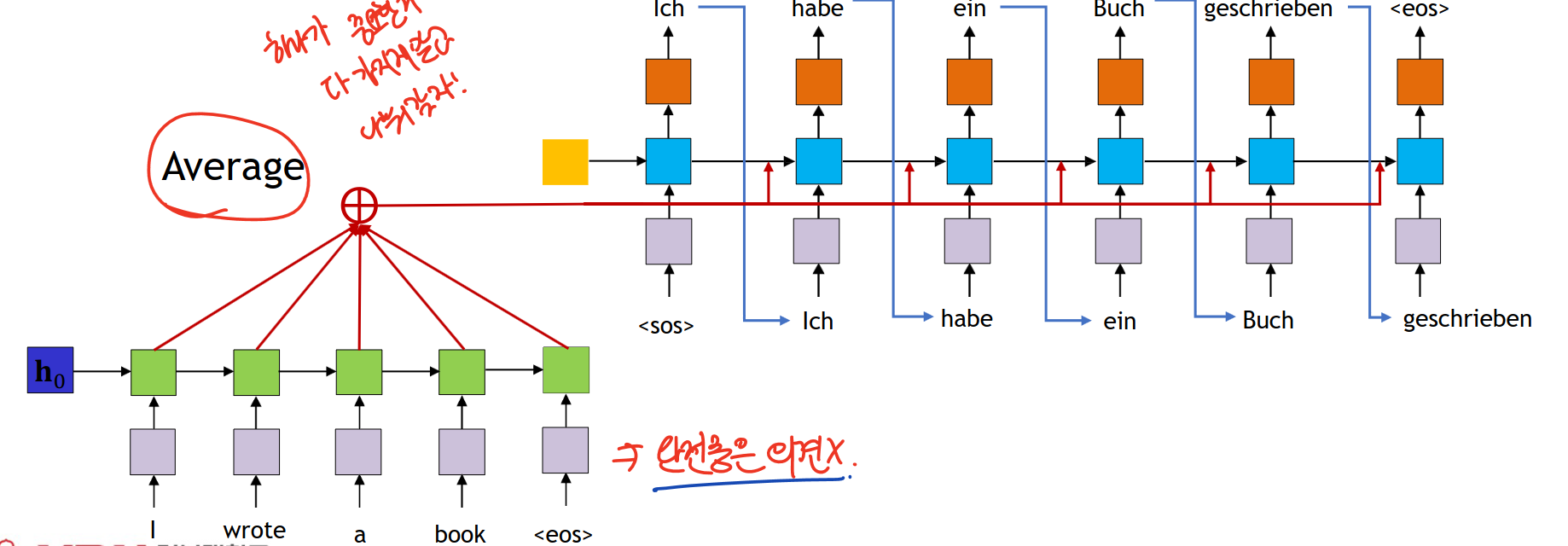
평균을 내는 바람에 same aggregated context으로 되는데 이를 위한 해결책으로는 각 출력 단어마다 다른 weighted average를 사용하자!
attention weight를 각기 다르게 하자
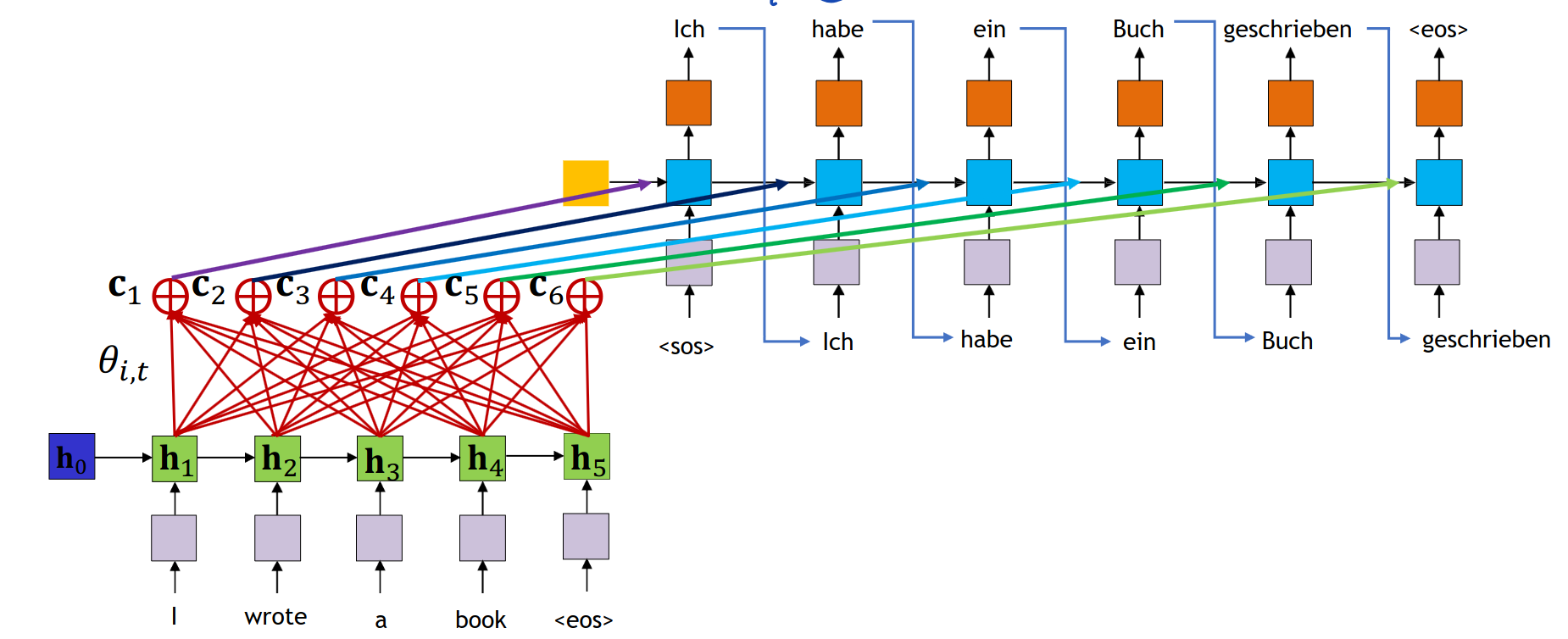
Attention model
attention weight -> 관계있는 input 값에는 높은 weight
관계없는 input 값에는 낮은 weight 값을 가짐
모든 weight 값은 다 0보다 크거나 같아야하고 합은 1이된다.
softmax를 취해서 weight를 분포로 바꾼다
3. Transformer
attention mechanism- 문장의 단어들을 중요도에 따라 weight를 부여함, 가중치를 보며 output 만들어냄.
구성 요소- Query: 데이터에 있는 정보, Key: 그 query에 대응하는 포인트, Value: 찾고 있는 실제 데이터
과정- query랑 key는 곱해지고 attention score를 만들어냄. attention score은 그 값의 가중치를 결정함
Transformer 구조
encoder, decoder로 이루어져있음. 각각의 디코더는 final 인코더의 출력값을 가지고 있음
self attention mechanism
모든 인코더는 512 벡터를 가지고 있음
벡터의 길이 리스트는 가장 긴 문장에 매치함
Transformer는 인코더에서 각 단어의 위치에 독립적인 과정을 가짐 independent processing path for each word's position
의존성은 self attention layer에만 존재하고 feed-forward 층에는 의존적이지 않음
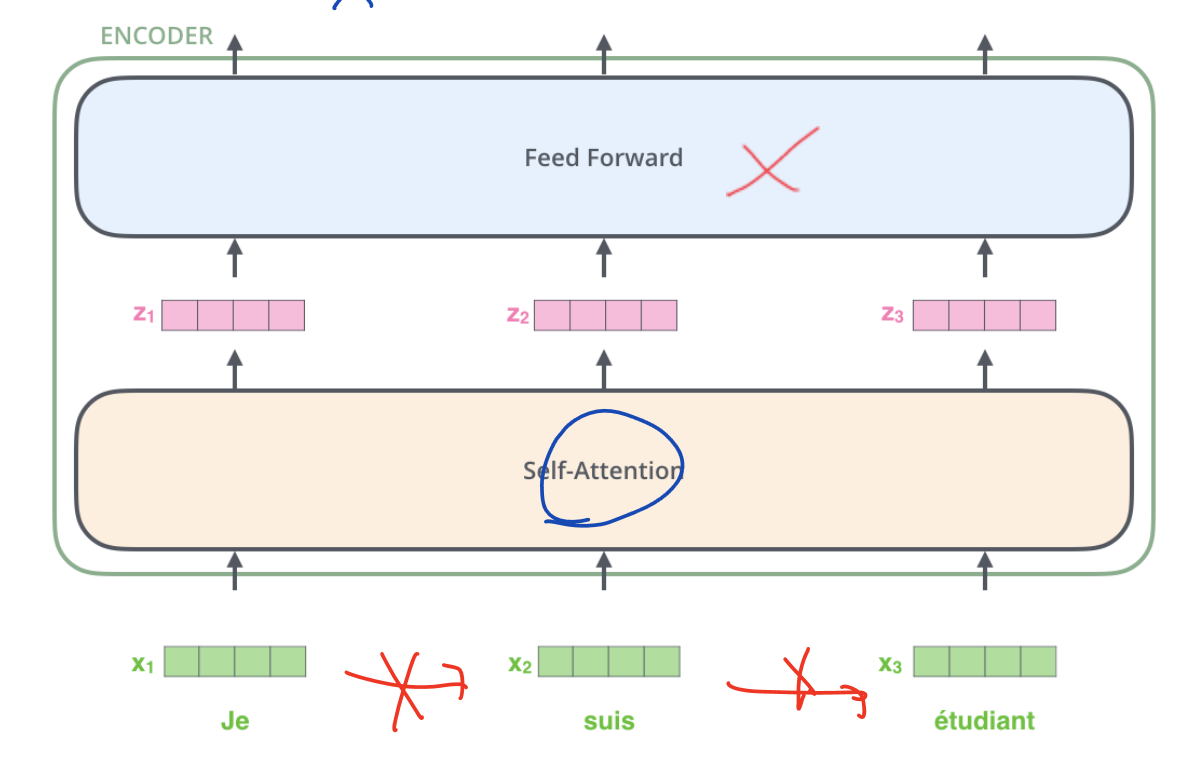
Self attention
transformer model에서 중요한 구성요소이다.
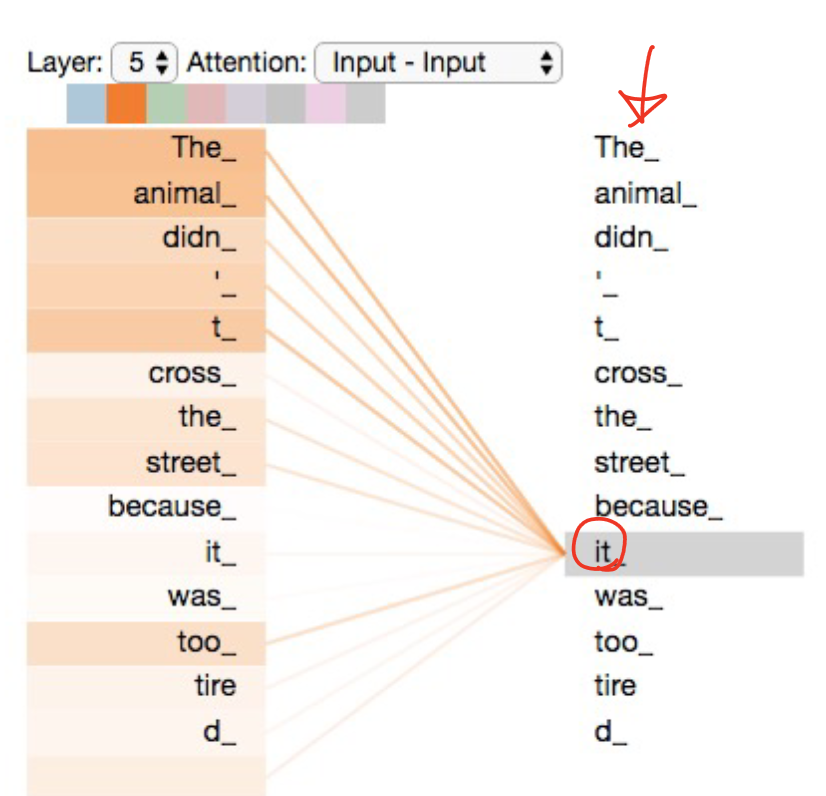
self attention은 단어의 모호함을 결정함. 즉 모호한 단어인 it이 무엇을 가리키는지도 맞힘
self attention의 메커니즘은 RNN과 비슷하다. RNN과 비슷하게 hidden state을 이용하여 그 전 단어로부터 정보를 결합하고, 현재 단어의 인코딩을 강화하기 위해서 모든 단어로부터의 내용을 합친다.
Matrix Multiplication
원래 차원은 512였는데 벡터는 64개로 줄어든다.
Normalize도 한다.
Positional Encoding
각 단어의 위치를 인식하고 그 sequence의 단어와의 상대적 거리를 계산

