2023년 12월에 나온 논문
논문 링크
github
Introduction
brain segmentation MR image는 4개의 모달리티가 존재한다.
T1, T1c(대조를 강조한 T1), T2, Flair
만약 모달리티가 누락되거나 쓸수 없을 경우, 최적의 성능을 얻기가 힘들다.
몇개의 논문은 이미지 합성 방법을 설명
다른 논문은 불변한 이미지를 학습함으로써 불완전한 다중 모달 MR 이미지에서 뇌 종양을 분할 방법을 설명
=> 이러한 방법들은 여러 가지 누락된 모달리티 케이스가 있기 때문에 각 경우에 대해 여러 네트워크를 훈련하거나 고정된 통합 네트워크를 훈련해야 하므로, 높은 계산 비용 또는 최적의 성능을 얻지 못함
- 따라서, 이 논문은 하나의 통합 및 적응형 다중 모달 MR 이미지 합성 네트워크인 "hyper-GAE"를 제안
hyper-GAE의 구성요소: shared encoder, fusion block, shared decoder
방법: 다중 모달 MR 이미지를 공통 특징과 모달리티별 특징으로 분해하여 각각 대상의 공통 구조와 스캐너의 이미징 매개변수를 모델링함
하이퍼넷 기반 변조 (HBM) 모듈을 사용하여 입력 모달리티 조합에 대해 완전한 모달리티 종양 세그멘테이션 네트워크를 조절함
관련 연구 내용
Missing MR Modality Synthesis
- 일대일 합성
정의: 하나의 모달리티를 다른 모달리티에서 합성, GAN 사용
예시: T1w 이미지에서 T2w 이미지를 합성
문제: 두 개 이상의 기존 모달리티가 있는 경우 모든 사용 가능한 모달리티 정보를 충분히 활용할 수 없음 - 다대일 합성
정의: 모든 사용 가능한 모달리티에서의 정보를 결합하여 누락된 모달리티를 추정, collaborative GAN 사용
문제: 다양하게 누락된 모달리티 케이스에 대해서 여러 네트워크를 훈련해야 함 - 다대다 합성
정의: multi-input multi-output GAN 사용-fixed network를 사용하므로 다양하게 누락된 모달리티에 취약함
N MR 모달리티에서 missing modality case는 총 2^N-2 개 존재
(2=다 존재, 다 없는 경우)
이 논문은 통합적이고 적응적인 다대다 합성 방법을 사용
다대일에 비해서는 하나의 네트워크만 훈련하면 되고, 다대다에 비하면 다양하게 누락된 모달리티 케이스에 적응 가능한 매개변수를 가진 적응적인 네트워크
UNIFIED MULTI-MODAL MR IMAGE SYNTHESIS
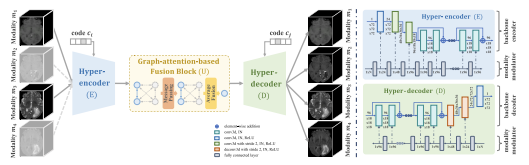
과정
-
인코딩 단계 (Hyper-Encoder): 각 입력 모달리티에 대해 하이퍼-인코더는 개별적으로 깊은 특징을 추출
-
퓨전 블록 (Graph-Attention-Based Fusion Block): 추출된 각 특징은 그래프-주의 기반 퓨전 블록을 통해 상호 작용하고 집계됩니다. 각 모달리티의 정보를 결합하여 퓨전된 특징을 생성
-
디코딩 단계 (Hyper-Decoder): 퓨전된 특징은 공통 특징 공간을 모델링하여 목표 모달리티의 이미지를 재구성하는 공통 하이퍼-디코더에 입력
구체적 설명
A. Hyper-Encoder and Hyper-Decoder
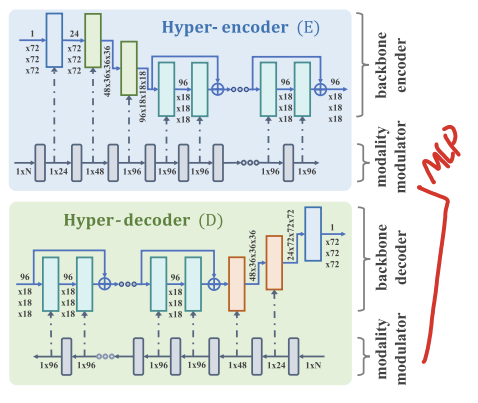
modality modulator는 모달리티 코드를 입력으로 받는 MLP(다층 퍼셉트론)
각 레이어는 백본 인코더/디코더의 각각의 instance modualtor(IN) 레이어에 연속적으로 대응
해당 레이어의 파라미터를 tuning
B. Graph-Attention-Based Fusion Block
각 그래프 노드는 각 모달리티의 특징
노드 번호는 사용 가능한 모달리티의 수에 동적으로 할당
그래프 엣지는 각 사용 가능한 모달리티 쌍 간의 연결을 모델링
각 노드는 (모달리티 코드와 모달리티 가용성 벡터에 의해 조절되는) 어텐션 기반 message passing 연산을 통해 다른 노드로부터 보완적인 정보를 빌리고, 업데이트된 노드 특징은 averge fusion에 의해 집계됨
C. Adversarial Common Feature Constraint
추출된 퓨전 특징이 서로 다른 누락된 모달리티 케이스에 공유되는 공통 공간에 존재하도록 하는 ACF constraint를 제안
퓨전된 특징이 C에 의해 어떤 모달리티에 속하는지 명확히 식별되지 않도록 적대적인 학습을 통해 공통 특징 공간 내에 유지되도록 함
(ACF 제약은 이러한 퓨전된 특징이 특정한 모달리티에 속하는지를 정확하게 분류하는 데 어려움을 겪도록 학습합니다. 이렇게 함으로써 모델은 특정한 누락된 모달리티에 특화된 특징을 생성하지 않고, 대신 공통된 구조를 나타내는 특징을 만들게 됩니다.)
D. Training Loss for MR Image Synthesis
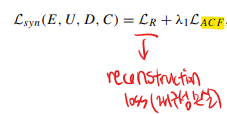
총 train loss에는 재구성 손실과 적대적 공통 특징(ACF) 제약이 포함되어 있음
MISSING-MODALITY MR IMAGE SEGMENTATION
실제 또는 합성 입력 이미지 두 가지 유형이 있음
그 모달리티 조합들에 대해 파라미터를 조정하고 전체 모달리티 종양 분할 네트워크에 적응적으로 넣을 수 있는 hypernet-based modulation (HBM) 모듈을 설계
=> two-stage cascaded U-Net(TC-UNet)에 HBM module을 넣어서 two-stage cascaded hyper-segmentor을 만듦

Cascaded Hyper-Segmentors
hyper-segmentor 두개 S1, S2로 구성되어 있음
S1(첫 번째 hyper-segmentor)은 퓨전된 공통 특징(FMa)에서 굵은 분할 맵을 예측하는 데 사용됨
공통 특징 FMa와 완성된 이미지 I 및 추정된 굵은 레이블 yˆ의 결합이 S2(두 번째 hyper segmentor)로 전달되어 더 정확하게 예측
Experiment 결과
Dataset
BraTS 2019 Dataset, BraTS 2018 Dataset 사용
Evaluation Metrics
synthesis performance-> mean absolute error (MAE), peak signal-to-noise ratio (PSNR), structural similarity (SSIM) 사용
segmentation performance-> 3D Dice scores, 95% Hausdorff distance (HD95) 사용
학습
학습률이 0.0002이고 배치 크기가 2 인 상태에서 1200 에포크 동안 최적화
가중치 λ1 및 λ2는 각각 0.001 및 0.8로 설정
예측된 병변 볼륨의 voxel 수가 너무 작을 때(300 미만)-> 후처리 단계를 수행, 없는걸로 침
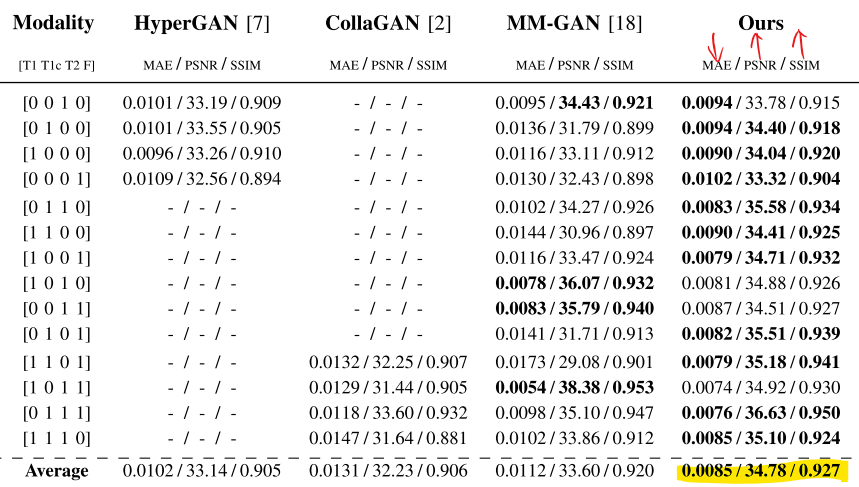
Multi-Modal MR Image Synthesis
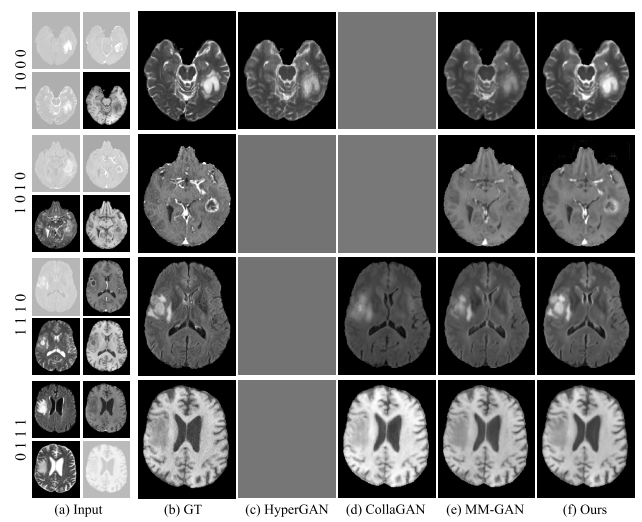
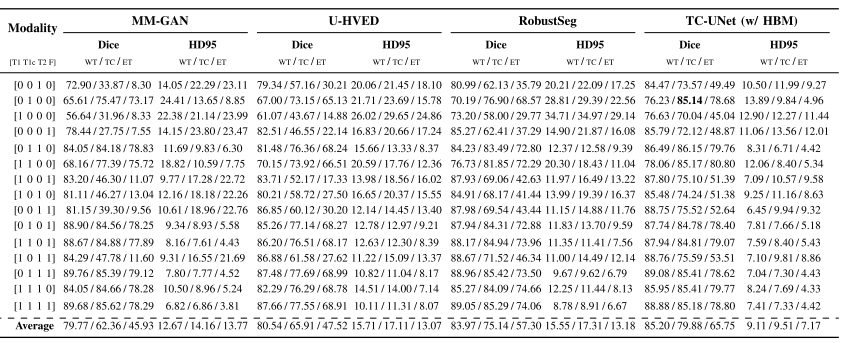
Missing-Modality MR Image Segmentation


Conclusion
몇 가지 실패 케이스
다중 모달 MR 영상 합성의 경우, 111개의 시험 주제 중 2개에서 실패
누락된 모달리티 MR 영상 세그멘테이션의 경우, 111개의 시험 주제 중 4개의 누락된 모달리티 케이스에서 실패
=> 일부 모달리티가 대조가 낮아서 이 모달리티만 사용 가능한 경우에는 만족스러운 종양 세그멘테이션 결과가 얻어지지 않기 때문일 것
