Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
NAS에 데이터 정리해서 올리기
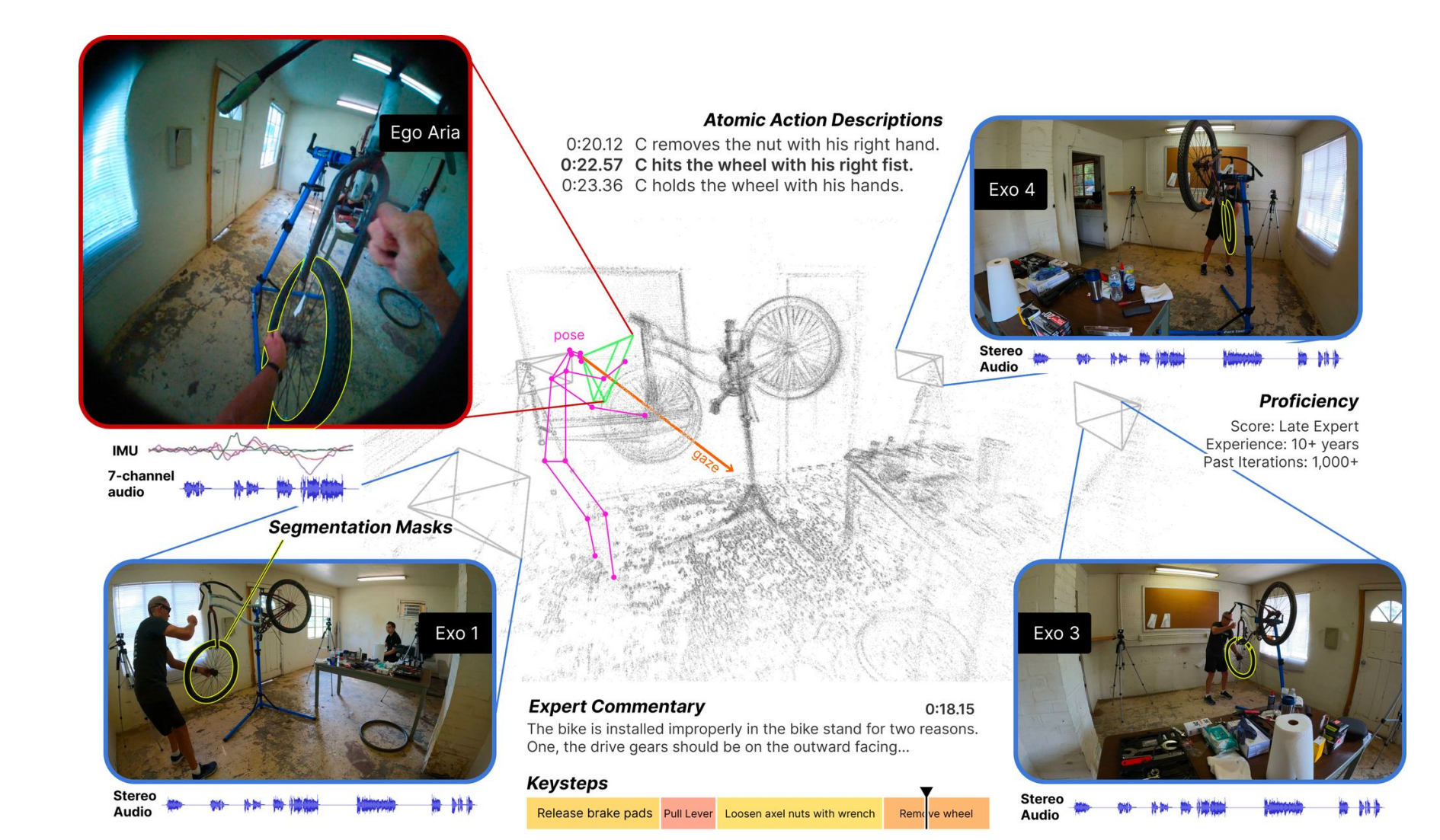
다양하고 대규모인 멀티모달 멀티뷰 비디오 데이터셋
전세계 13개 도시에서 800명 이상의 참가자 131개 다양한 자연환경 1422시간의 비디오 생성
비디오는 expert commentary 여러 쌍의 언어설명과 함께 제공
Introduction
사람의 기술 습득을 할려면 자아중심(ego), 외부중심적(exo) 시각은 필수적, 두 시각은 서로 상호보완적임, 기술 습득시 서로 원활하게 번역할 수 있어야함
Ego-Exo4D: ego-exo 비디오 학습 및 다중 모달 지각에 대한 연구를 지원하기 위한 데이터 셋
단일 인물 활동에 중점, 다중뷰 멀티모달
Related Work
- Egocentric datasets: 스크립트 되지 않은 일상 활동에 대한 자아중심 비디오가 증가, ego-exo4D는 숙련된 활동의 도메인에 중점을 둔다.
- Multiview and ego-exo datasets: 최근에는 특정활동에 중점을 둠 (실험실에서 조립), ego-exo4D는 참가자 수, 위치 다양성, 영상 시간의 다양성, 이 다양성을 이용해서 3d body pose dataset을 보완하도록 함
- Ego-exo cross view modeling: 이 데이터셋은 여러 cross view 모델링의 testbed를 제공, 새로운 시점 합성 과제 제공
Dataset
Ego-exo camera rig
exo camera: 4~5개의 고정된 GoPro가 배치되어 있음
Domains and environments
총 8개의 domain인 skilled activity(43개의 활동)를 2가지의 category로 나눔

- physical-축구, 농구, 댄스, 음악 등, 신체 자세와 움직임 뿐만 아닌 물체와의 상호작용을 강조
- procedural-요리, 자전거 수리 등, 목표를 달성하기 위해 여러 단계들을 수행, 여러 물체를 손으로 조작(복잡함)을 필요로 함
Participants
839명의 참가자를 모집, 대부분이 10년 이상의 경험을 가지고 있음(실수가 없기 때문), 초보자~전문가 기술의 진화를 묘사하기도 함
Privacy and ethics
개인정보 보호, 윤리 기준 준수하여 수집함, 모든 데이터가 폐쇄된 환경에 있으므로 모든 비디오는 모자이크 없이 이용 가능
Natural language descriptions
ego-exo4d는 비디오와 함께 시간에 따라 3가지의 자연어 데이터 셋을 제공함

- 전문가 코멘터리
목표: 비전문가는 모르는 기술에 대해서 서술
과정: 녹화된 비디오를 보고 참가자의 특정 행동(손, 체의 자세)이 결과에 어떤 영향을 미치는지 설명, 52명의 전문가 모집
모든 비디오에 동일한 콘텐츠에 다양한 관점을 제공하기 위해 2~5명의 전문가가 코멘트를 하는 방식
이를 통해 미래에 AI 코칭 같은 프로그램을 만들 수 있음 - 참가자 자신들이 나레이션한 설명
참가자가 무엇을 하는지, 이유 설명 - 기본적인 행동 설명
나레이션에서 영감을 받아 제3자가 모든 기본적인 행동에 대해 타임스탬프가 찍힌 짧은 진술을 적음
Ego-Exo4D benchmark tasks
4가지 도전과제- 관계, 인식, 숙련도, ego-pose
Ego-exo relation
- Correspondence

ego와 exo 시점 사이의 객체의 대응을 확립해야함,
ego-exo 비디오 쌍과 하나의 비디오에서의 관심 객체의 마스크가 주어지면 다른 뷰의 프레임에서 동일한 객체에 대응하는 마스크를 예측하는 작업
- Translation

exo clip에서 ego clip을 합성하는 것
(손가락이) 관찰된 exo clip에서 관찰되지 않은 ego 프레임에서 객체의 분할 마스크를 추정함
ego-exo 번역은 AR 코칭이나 로봇 인식에서 응용 될 수 있음
과정: 1) ego 클립에서 객체의 위치와 모양을 예측하고, 2) 지면 실제 위치를 고려하여 외관을 합성함
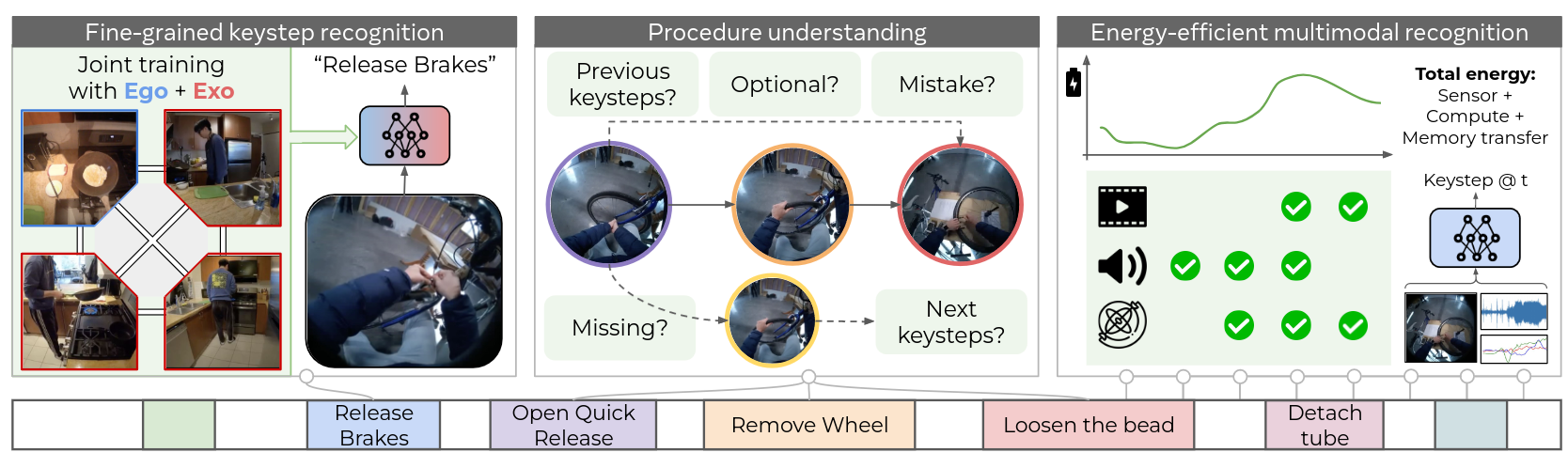
Ego-exo keystep recognition
-
Fine-grained keystep recognition(세부)
짝을 이룬 영상 데이터를 보고 보완성 활용하여 (오물렛 만드는)절차들을 구분
ego 중심의 비디오 clip만 보고 여러 key step들을 식별해야 함 -
Procedure understanding
비디오에서 절차의 구조를 자동으로 이해하는 것
이전 절차 결정, 선택사항인지, 절차적 실수인지, 누락된 절차인지, 다음 절차는 뭔지 예측을 해야함 -
Energy-efficient multimodal keystep recognition
현실세계 하드웨어에서 실행 가능성을 높이기 위해 에너지 효율적인 비디오 모델을 구축하는데 초점을 둠 (ex. 배터리)
Ego-exo proficiency estimation

사람이 무엇을 하는지 인식하는거를 넘어서 사용자의 기술 수준을 측정하는 것을 목표로 함
=> 새로운 기술을 효과적으로 배울 수 있고, 인간의 성과를 평가 하는데 사용될 수 있음
Ego pose

ego 뷰에서 사람의 신체 상태를 추정하는 것
비디오에서 참가자의 숙련된 신체 움직임(가려지거나 시야에서 벗어난 신체부위)을 복원하는 것
Sensor
Aria glasses- including 8 MP RGB camera, 2 slam camera, IMU, 7 microphones, eye tracking
4~5개의 GoPro

