
<참고>
ARID 데이터셋 v1: https://xuyu0010.github.io/arid.html#papers-and-download
resent 101 github: https://github.com/kenshohara/3D-ResNets-PyTorch

이렇게 resnet101과 resnext101 모델을 돌려야한다.
ARID 데이터 셋으로 finetuning을 해야하는데 ARID 데이터셋을 다운받아서 내 서버의 가상환경에 다운로드해주었다. 그리고 3d resnet도 설치했다.
resnet 돌리기
conda activate resnet해줌
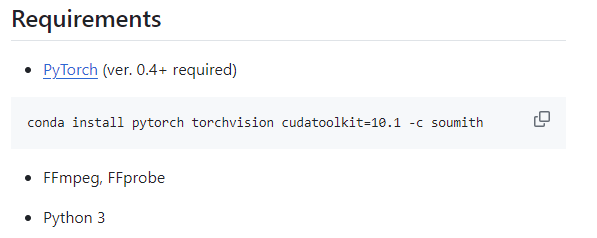
resnet을 돌리려면 필요한 코드도 실행해주었다.
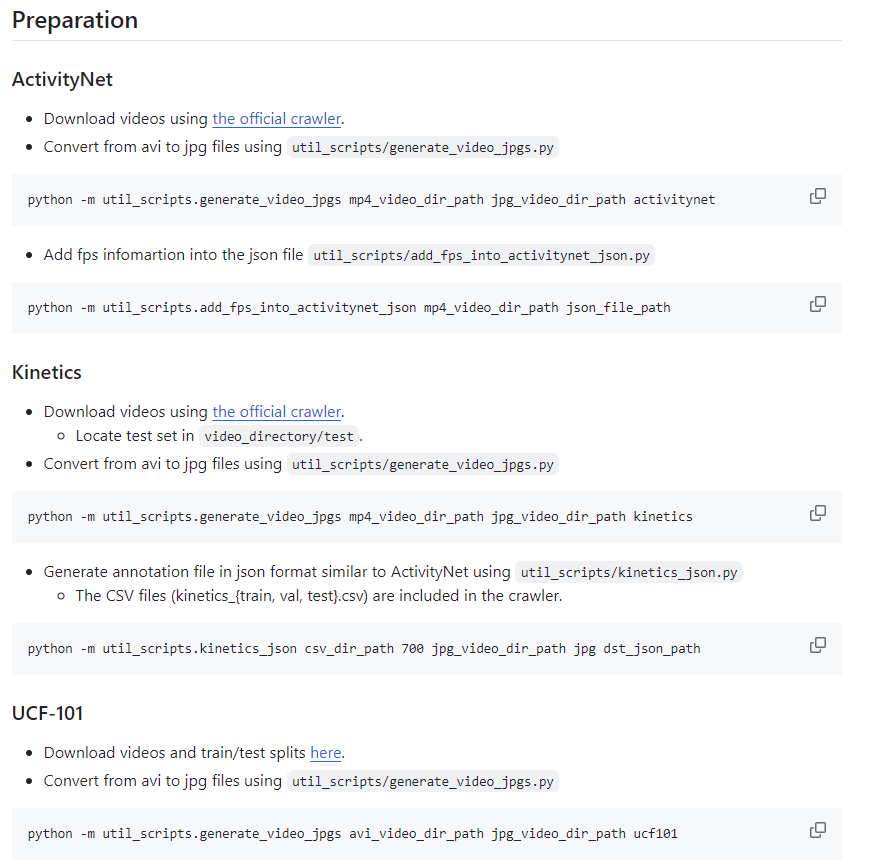
3d resnet을 실행해주려면 avi파일이나 mp4 파일을 jpg파일로 바꿔야지 resnet이 실행 가능하다.
나는 자꾸 없는 데이터셋인 arid로
python -m util_scripts.generate_video_jpgs mp4_video_dir_path jpg_video_dir_path arid로 해서 그런지 자꾸 에러가 났다. 그래서 나는 avi 파일로 하는 ucf101을 사용했다.
그리고 에러가 나는 이유가
ffmpeg -version
ffprobe -version확인해보니 이게 설치가 안되어있어서 비디오 분할을 못하는거였다.
그래서
sudo apt install ffmpeg이렇게 설치했다.
그리고
python generate_video_jpgs.py /home/geunyoung/gy/clips_v1.5 /home/geunyoung/gy/mp4_jpg ucf101이 코드를 실행하니깐 다음 그림처럼 잘 실행이 되었다~!!
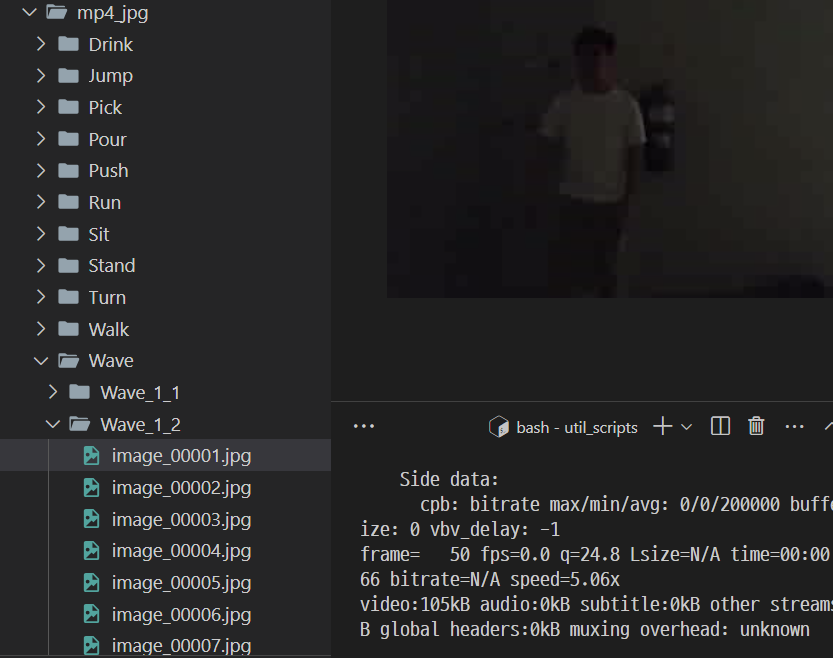
이 github의 코드들은 다 특정 데이터셋으로 맞춰놓은 기준에서 돌아가는 resnet코드여서 Arid데이터셋에 대해서 학습할려고 하니깐 잘 되지 않았다. annotationfile도 json으로 만들어야하는데 코드가 에러가 많이 났다. 그래서 기존 ucf 데이터셋의 annotation file을 만드는 코드를 수정해봤는데도 에러가 계속 났다. split index가 안맞거나 segment가 안들어가는 에러가 계속 났다.
그래서 찾아보다가 이 resnet 전에 옛날 resnet 코드가 있어서 그걸로 해봤는데도 에러가 떴다.
결국 어쩔수 없이 내 데이터셋을 이 ucf데이터셋 형식으로 맞춰주는 수 밖에 없었다. 그래서 ucf split 폴더의 형식을 다운받아서 보니, 
이렇게 classind 텍스트 파일과 test,train셋이 총 3개가 있었다. 나는 리스트가 하나 뿐이기 때문에 나의 train과 validation set을 각각 ucf train과 test의 형태에 맞춰서 넣어주었다.
그래서 형태 맞추는 코드도 짜서 수정해주고 annotation파일을 생성해주는 코드를 돌렸다. 근데 이번에는
from .utils import get_n_frames이 부분에서 계속 parent 의존성을 못찾겠다는 에러가 떴다. 구글링 해보니 얘가 그 경로를 못찾아서 생기는 오류 같았다. 그래서 상대 경로를 쓰지 않고 직접 경로를 쓰는 형식처럼 바꾸었다.
다 고치고 나니깐

이런식으로 json 파일이 만들어졌다. (ucf101_01.json파일)
데이터 형식은 최대한 
이런 식으로 맞춰주었다.
그럼 이제 학습 할 차례다!!
갑자기 학습 할려고 하니깐 맞는 콘다가 없다고 해서 또 오류를 찾아보니, conda랑 pytorch 버전이 안 맞아서 생기는 오류였다. 그래서 pytorch를 없애고 다시 맞는 버전으로 깔아주었다.
그리고
import torch
print(torch.cuda.is_available())이 코드를 실행해서 pytorch가 잘 돌아가는지 확인했고 True가 나왔다.
train을 해야하는데 명령어는
python /home/geunyoung/gy/3D-ResNets-PyTorch-master/main.py --root_path /home/geunyoung/gy/dataa --video_path /home/geunyoung/gy/dataa/resnet_videos/mp4_jpg --annotation_path /home/geunyoung/gy/dataa/ucf101_01.json --result_path /home/geunyoung/gy/dataa/results --model resnet --model_depth 101 --n_classes 11 --batch_size 128 --n_threads 4 --checkpoint 5 --dataset ucf101이렇게 실행해주니깐 epoch1부터 해서 잘 실행되는것을 볼수 있었다.
총 에폭은 200으로 해주었다.
그래서 validation은 생략하고 test랑 train으로 실행중이다.
train은 총 하루반정도 걸렸던거 같다. 생각보다 오래 걸리지는 않아서 다행이었다.
이제 test만 돌려보면 된다!!
top5 class 확률을 체크해야한다.
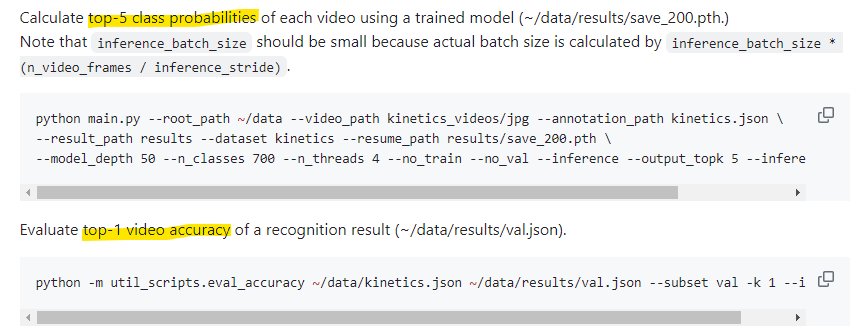
python main.py --root_path ~/data --video_path ucf_videos/jpg --annotation_path ucf101.json --result_path results --dataset ucf101 --resume_path results/save_200.pth --model_depth 50 --n_classes 700 --n_threads 4 --no_train --no_val --inference --output_topk 5 --inference_batch_size 1result에 다 돌아간 save200 path를 이용해서 validation 파일(test값들)을 측정하는 것이었다. 돌리고 나니깐 results 폴더에 val.json이라는 파일이 생겼다. 이건 돌리는데 한 30분정도 걸린거 같다.

이제 마지막으로 evaluate top1 video accuracy를 측정 해야한다. 그래서 아까 나온 val.json을 이용해서 gt json 파일인 ucf101.json파일과 함께 비교해서 accuracy를 뽑아내야한다.
python -m util_scripts.eval_accuracy ~/data/ucf.json ~/data/results/val.json --subset val -k 1 --ignore근데 이거 분명히 코드도 다 맞고 디버깅도 올바르게 했는데 오류가 떴다.
zero value에러가 떴는데 gt 파일이 자꾸 개수가 하나도 없다는 에러가 떠서 엥 뭐지?? 하면서 체크했는데 분명히 gt파일도 틀린 부분이 없어서 출력도 중간중간 해봤는데 그냥 gt파일을 똑바로 읽어오는데 개수가 0이라고 떴다.
보니깐 원래 gt파일은 subset이 validation이라고 적어져있는데 디버깅할때는 subset val이라고 해서 나는 오류였다. 그래서 디버깅할때
python -m util_scripts.eval_accuracy ~/data/ucf.json ~/data/results/val.json --subset validation -k 1 --ignore으로 수정하니깐 잘 됐다. 너무 기뻤다!!!! 우히히
issue를 읽어보다가 해결했다.
역시 issue 최고다. 다들 오류 생기면 issue부터 보는것을 추천합니다...
resnext 돌리기
데이터 쪼개고 json파일 만드는건 resnet돌릴때 다 되어 있으니 그냥 resnext 학습만 시작하면 된다.
아까 코드랑 거의 똑같고
python /home/geunyoung/gy/3D-ResNets-PyTorch-master/main.py --root_path /home/geunyoung/gy/dataa --video_path /home/geunyoung/gy/dataa/resnet_videos/mp4_jpg --annotation_path /home/geunyoung/gy/dataa/ucf101_01.json --result_path /home/geunyoung/gy/dataa/resnext_results --model resnext --model_depth 101 --n_classes 11 --batch_size 128 --n_threads 4 --checkpoint 5 --dataset ucf101그냥 resultpath만 다른 폴더로 해주고, model만 resnet에서 resnext로 바꾸면 된다.
이렇게 해서 실행했는데 아니 또 에러가 떴다.
n_planes오류가 떠서 체크해보니 resnet.py에서의 층을 만드는 make_layer함수에서는 in_planes를 쓰는데 resnext.py에서는 파라미터가 inplanes로 설정되어있어서 나는 오류였다. 그래서 resnext도 in_planes로 고쳐주고 다시 돌렸다.
이렇게 돌리고 나니깐 cuda memory가 없다는 에러가 떴다.
RuntimeError: $ Torch: not enough memory: you tried to allocate 263GB.
그래서 이렇게 메모리 없다는 에러 뜨면 batch size를 줄여야된다고 해서 기존 batchsize 128에서 64,32,8,4까지 줄여봤는데도 다 같은 메모리 에러가 떴다. 그래서 다른 문제인가 해서 다시 issue를 찾아보았다.
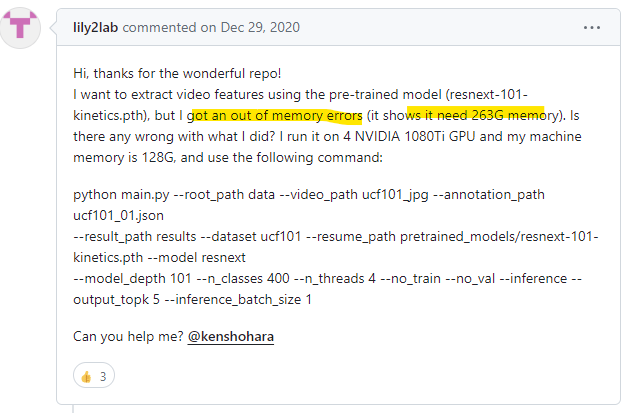
나 같은 사람이 여러명 있었다!!
밑에 해결한 사람을 보니 4개의 문제점이 있었다.
<참고링크>
에러 관련 issue 링크
- 첫번째 문제점
On the file resnext.py the widen_factor(1.0) was being replaced by n_classes (400) in the block ResNet on the file "resnet.py" class ResNet. On the line 118 [int(x * widen_factor) for x in block_inplanes] rather than [128, 256, 512, 1024] as defined on function get_inplanes on file "resnext.py", it was being multiplied by 400 or other n_classes passed, geting [51200, 102400, 204800, 4096000] in_planes and resulting out of memory.
Hypotesis: This happend because widenresnet might be seted up after resnext, and this parameter widen_factor was placed before n_classes.
해결방법:
On the file "resnext.py" line 51
super().__init__(block, layers, block_inplanes, n_input_channels,
conv1_t_size, conv1_t_stride, no_max_pool,
shortcut_type, n_classes)에서
super().__init__(block=block, layers=layers, block_inplanes=block_inplanes, n_input_channels=n_input_channels,
conv1_t_size=conv1_t_size, conv1_t_stride=conv1_t_stride, no_max_pool=no_max_pool,
shortcut_type=shortcut_type, n_classes=n_classes)로 수정하기
- 두번째 문제점
The block ResNeXtBottleneck was seted with the parameter "inplanes" but ResNet _make_layer function uses "in_planes".
이게 내가 말한 inplane문제다.
_make_layer function in resnet.py file:
layers.append(
block(in_planes=self.in_planes,
planes=planes,
stride=stride,
downsample=downsample))이렇게 in_planes로 되어있다.
그래서
On the file resnext.py line 16
class ResNeXtBottleneck(Bottleneck):
expansion = 2
def __init__(self, inplanes, planes, cardinality, stride=1,
downsample=None):
super().__init__(inplanes, planes, stride, downsample)
mid_planes = cardinality * planes // 32
self.conv1 = conv1x1x1(inplanes, mid_planes)
self.bn1 = nn.BatchNorm3d(mid_planes)
self.conv2 = nn.Conv3d(mid_planes,
mid_planes,
kernel_size=3,
stride=stride,
padding=1,
groups=cardinality,
bias=False)
self.bn2 = nn.BatchNorm3d(mid_planes)
self.conv3 = conv1x1x1(mid_planes, planes * self.expansion)을
class ResNeXtBottleneck(Bottleneck):
expansion = 2
def __init__(self, in_planes, planes, cardinality, stride=1,
downsample=None):
super().__init__(in_planes, planes, stride, downsample)
mid_planes = cardinality * planes // 32
self.conv1 = conv1x1x1(in_planes, mid_planes)
self.bn1 = nn.BatchNorm3d(mid_planes)
self.conv2 = nn.Conv3d(mid_planes,
mid_planes,
kernel_size=3,
stride=stride,
padding=1,
groups=cardinality,
bias=False)
self.bn2 = nn.BatchNorm3d(mid_planes)
self.conv3 = conv1x1x1(mid_planes, planes * self.expansion)로 수정하기
- 세번째 문제점
Loading pretrained resnext-101-kinetics.pth missmatch the state_dict from the new ResNeXt. Old format started with module like this 'module.conv1.weight' and the new one is in this format 'conv1.weight'. Some, we need to remove all "module." from the state_dict.
On the file model.py line 97
def load_pretrained_model(model, pretrain_path, model_name, n_finetune_classes):
if pretrain_path:
print('loading pretrained model {}'.format(pretrain_path))
pretrain = torch.load(pretrain_path, map_location='cpu')
model.load_state_dict(pretrain['state_dict'])
tmp_model = model
if model_name == 'densenet':
tmp_model.classifier = nn.Linear(tmp_model.classifier.in_features,
n_finetune_classes)
else:
tmp_model.fc = nn.Linear(tmp_model.fc.in_features,
n_finetune_classes)
return model을
def load_pretrained_model(model, pretrain_path, model_name, n_finetune_classes):
if pretrain_path:
print('loading pretrained model {}'.format(pretrain_path))
pretrain = torch.load(pretrain_path, map_location='cpu')
if pretrain_path.name == 'resnext-101-kinetics.pth':
pretrain['state_dict'] = {str(key).replace("module.", "") : value for key, value in pretrain['state_dict'].items()}
model.load_state_dict(pretrain['state_dict'])
tmp_model = model
if model_name == 'densenet':
tmp_model.classifier = nn.Linear(tmp_model.classifier.in_features,
n_finetune_classes)
else:
tmp_model.fc = nn.Linear(tmp_model.fc.in_features,
n_finetune_classes)
return model로 수정하기
- 네번째 문제점
Load state dict mismatch.
On the file resnet.py line 119
self.in_planes = block_inplanes[0]self.in_planes = 64 #block_inplanes[0]로 수정하기
이렇게 네개를 수정하고 다시 학습을 돌리니깐 (batch size 128로)
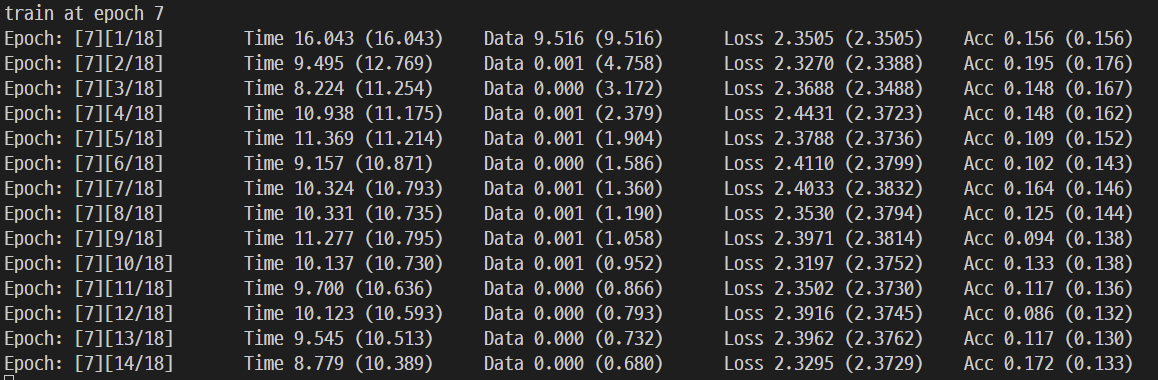
이렇게 잘 됐다.
train이 하루정도 하니깐 다 돼서 이제 top 5개를 inference 할 차례다!
근데 갑자기
(resnet) geunyoung@jt-ds-1:~$ python /home/geunyoung/gy/3D-ResNets-PyTorch-master/main.py --root_path /home/geunyoung/gy/dataa --video_path /home/geunyoung/gy/dataa/resnet_videos/mp4_jpg --annotation_path /home/geunyoung/gy/ucf101.json --result_path /home/geunyoung/gy/dataa/results_resnext --dataset ucf101 --resume_path /home/geunyoung/gy/dataa/results_resnext/save_200.pth --model_depth 101 --n_classes 11 --n_threads 4 --no_train --no_val --inference --output_topk 5 --inference_batch_size 1하라는데로 명령어를 쳤는데 갑자기 checkpoint가 맞지 않는다는 오류가 떴다.. main.py에는
def resume_model(resume_path, arch, model):
print('loading checkpoint {} model'.format(resume_path))
checkpoint = torch.load(resume_path, map_location='cpu')
assert arch == checkpoint['arch']이런 부분이 있는데 여기서 assertion error가 떴다. 그래서 보니깐 실행하려는 모델은 resnet이고 resume path의 checkpoint는 resnext.pth여서 맞지 않아서 오류가 생긴거였다. 그래서 저기 명령어 뒤에 --model resnext를 붙여주니깐 아주 실행이 잘되었다! 우히히 똑똑행~!~!
그러고 이제 top1 accuracy를 측정해서
python /home/geunyoung/gy/3D-ResNets-PyTorch-master/util_scripts/eval_accuracy.py /home/geunyoung/gy/ucf101.json /home/geunyoung/gy/dataa/results_resnext/val.json --subset validation -k 1 --ignore
top-1 accuracy는 69%가 됐당! 오예~!
직접 만든 데이터셋으로 test하기
해당 데이터는 ARID 데이터와 동일한 클래스의 액션을 우리의 light condition에서 수행한 것으로, 우리의 조도 환경이 ARID 보다 어두운 환경임을 증명하고 또 그럼에도 해결 가능한 수준의 어려움임을 보이기 위함
그래서 직접 만든 데이터인
- Scene 환경
- A,B : 저조도 환경(농구장)top1_acc": "17.78",
- C : 극저조도(백호관)
- D : 테니스장 옆 공원
- E : 중조도 환경( ARID랑 유사한 조도, 좀 더 밝은 환경에서 촬영)
=> 총 196개 샘플
그래서 이제 arid로 학습한 resnet path를 가지고
Brio-A,B/ Brio-C/ Brio-E
Realsense-A,B/ Realsense-C/ Realsense-E
데이터셋을 각각 inference하였다.
그런 결과, 성능은 그다지 좋지 못했다.
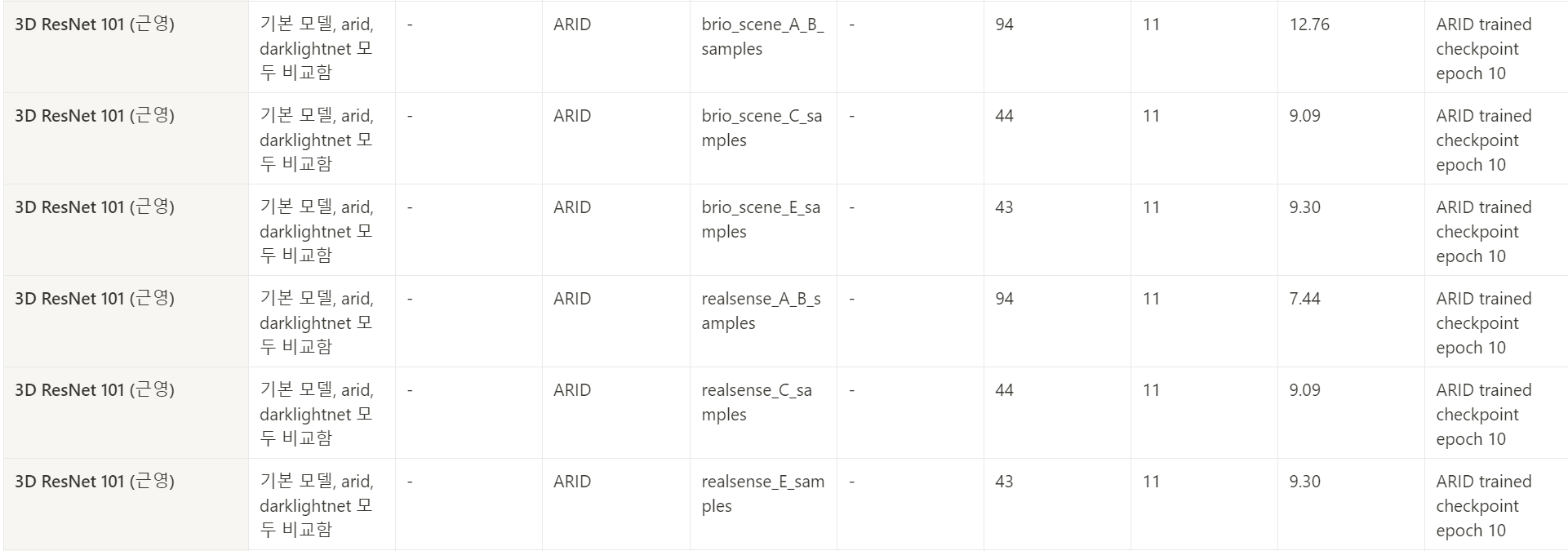
kinetics로 학습된거 arid로 finetuning
이제 해야할것은
1. kinetics dataset으로 학습된 resnext를 arid datset으로 finetuning해서 직접 만든 dataset(brio,realsense) test해서 inference 결과 적기
- kinetics dataset으로 학습된 resnet을 arid dataset으로 finetuning해서 직접 만든 dataset(brio,realsense) test해서 inference 결과 적기
그럼 resnext부터 해보겠다. 다행히도
resnet github에 들어가보면 이렇게
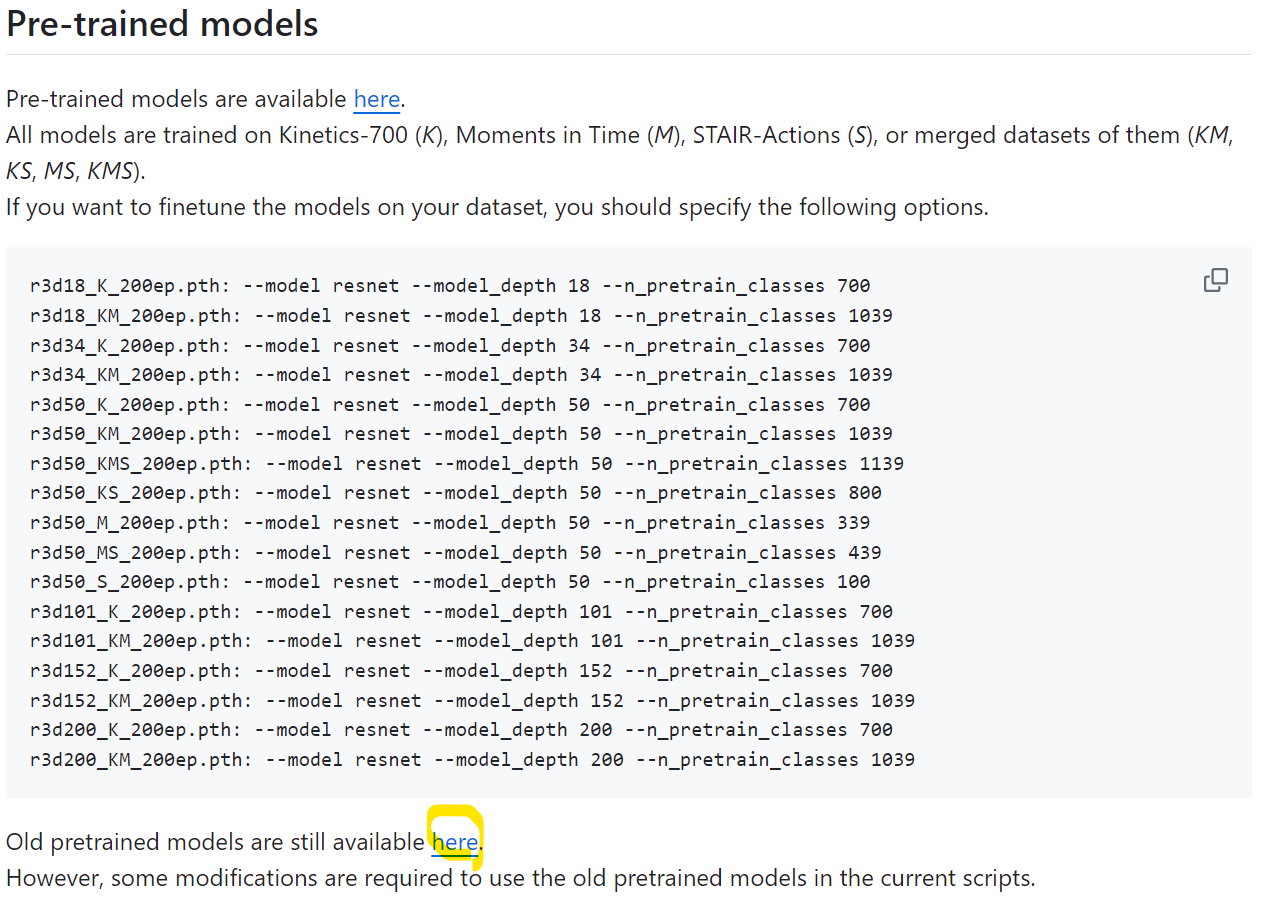

이렇게 kinetics로 학습한 resnet과 resnext path 파일이 존재한다. 그래서 이 파일에다가 arid dataset을 pretrain를 하면 된다.

이렇게 코드도 예시로 주기 때문에 거기에 맞춰서
python /home/geunyoung/gy/3D-ResNets-PyTorch-master/main.py --root_path /home/geunyoung/gy/dataa --video_path /home/geunyoung/gy/dataa/resnet_videos/mp4_jpg --annotation_path /home/geunyoung/gy/ucf101.json --result_path /home/geunyoung/gy/dataa/kinet+arid_results --dataset ucf101 --n_classes 400 --n_pretrain_classes 400 --pretrain_path /home/geunyoung/gy/data2/path/resnext-101-kinetics.pth --ft_begin_modu
le fc --model resnext --model_depth 101 --batch_size 128 --n_threads 4 --checkpoint 5여기서 디버깅창에 칠때 pretrain class와 n_class를 pretrain한 kinetic dataset에 맞게 400으로 해야지 오류가 안난다.
이렇게 디버깅 창에 쳐서 학습을 했다. 그런 결과, 
이렇게 잘 학습이 되고 있다!!
kinetics -resnet 700
-resnext 400
KNU-1K로 찍은거 pretrain하기
resnext부터 돌리는 중
brio로 pretrain하기
pretrain 코드 쓰기 전에 새로 knu-1k 데이터셋부터 다운 받고 또 jpg로 잘라주고 split 폴더 안에 class.txt, val.txt, train.txt 파일 만들어주고, json 파일 만들어주고 학습 하면 된당!!
이 코드에 경로만 잘 넣어주고, n_classes를 12로 해주면 끝!
python main.py --root_path ~/data --video_path kinetics_videos/jpg --annotation_path kinetics.json --result_path results --dataset kinetics --model resnet
--model_depth 50 --n_classes 700 --batch_size 128 --n_threads 4 --checkpoint 5pretrain 코드는 이렇게 하면 됨
python main.py --root_path ~/data --video_path ucf101_videos/jpg --annotation_path ucf101_01.json --result_path results --dataset ucf101 --n_classes 11 --n_pretrain_classes 12 --pretrain_path models/resnet-50-kinetics.pth --ft_begin_module fc
--model resnet --model_depth 50 --batch_size 128 --n_threads 4 --checkpoint 5중간에 n_classes를 11로 pretrain_classes를 12로 해줘야지 에러가 안난다. knu-1k의 brio class가 총 12개이므로! 맞춰줘야한다.
