Sound Classification 정리 7. CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
Audio Pattern RecognitionAudio TaggingCMKDKD-ASTKD-CNNKnowledge distillationML/DLSound Classificationaudiospeechteacher-student
0
Sound Classification
목록 보기
8/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
Main Proposal
- Consistent Teaching 과 함께 Knowledge Distillation(KD) 를 적용하여 실험함
- CNN 계열 (Efficient-B(0,2,4,6), DenseNet-121) 과 Transformer 계열 (AST-(Tiny,Small,Base)) 간에 모든 Combination 에 대한 KD 실험 결과 보여줌
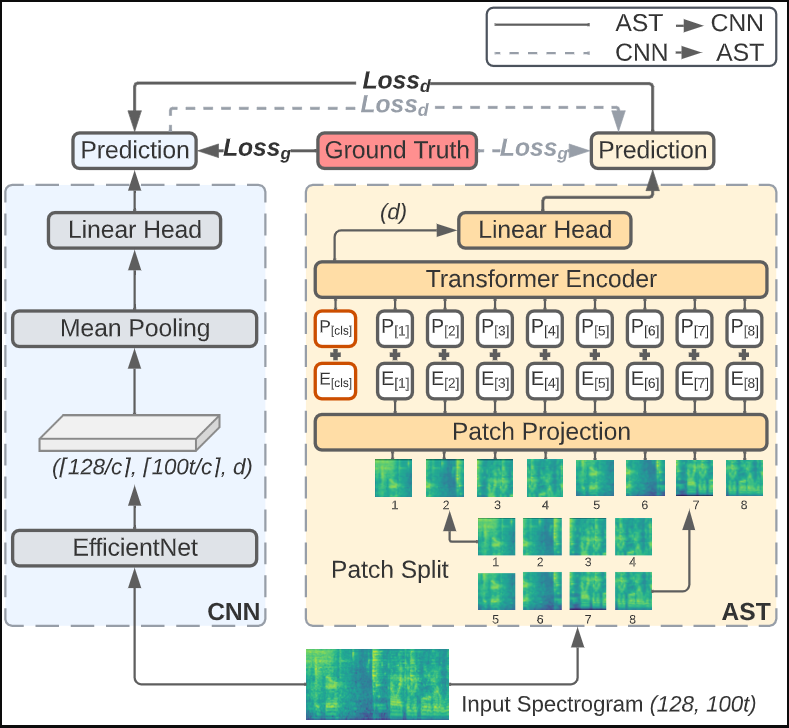
Knowledge Distillation with Consistent Teaching
- 알고리즘
- 우선 기존 방식으로 학습하여 Teacher Model을 생성
- 일반적인 KD 방법과 동일하게 Prediction 값에 대해 Temperature 적용후 Kullback–Leibler divergence 을 이용해 Auxiliary Loss 계산 (아래 식 우측 Term)
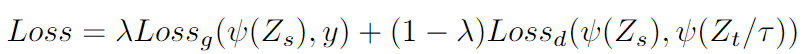
-
Consistent Teaching
- 말그대로 일관성 있도록 학습시키는 방법입니다. Teacher와 Student에 같은 입력을 넣어주되, 추가적으로
Data Augmentation방법 각각 적용하여 학습하는 방법입니다.
- 말그대로 일관성 있도록 학습시키는 방법입니다. Teacher와 Student에 같은 입력을 넣어주되, 추가적으로
-
Architecture
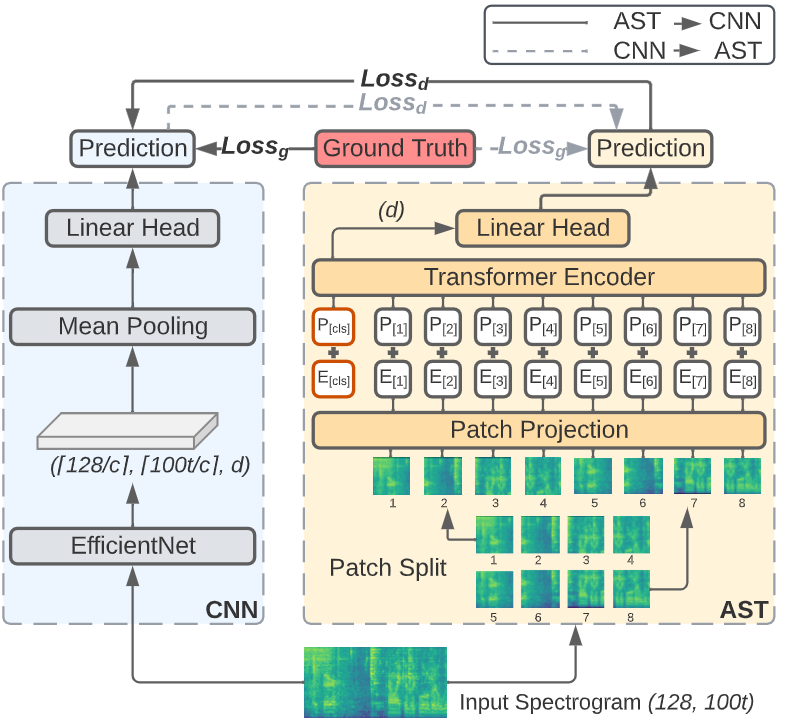
-
Comment
- 복잡한 Distillation 전략 (attention distillation strategy) 보다 단순한 KD 전략이 좋았다고 합니다.
결과
- 아무래도 저널논문이라 실험이 굉장히 많습니다. 컨셉 위주로 설명해보겠습니다.
- 설명 편의를 위해
->기호를Teacher -> Student로 KD 하는 것으로 사용하겠습니다.
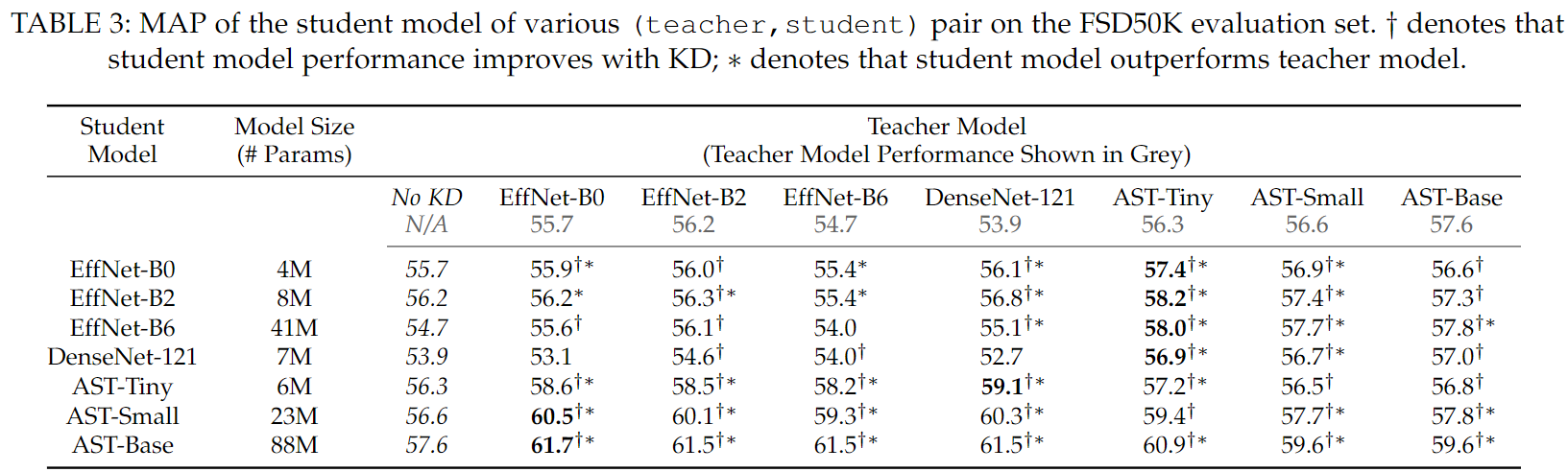
KD (CNN -> AST, AST -> CNN)
- 다른 성향의 모델(Cross-Model)과 KD를 한 경우 성능 향상을 보임
- 일반적으로 Student 모델이 Teacher의 성능을 능가함
The Strongest Teacher is not the best Teacher
- Teacher 성능이 높다고 해서 좋은 결과를 보여주지 않았다고 합니다.
- 위에서도 오히려
Teacher 모델이 가벼운 경우(EffNet-B0, DenseNet-121, AST-Tiny)가 성능이 더 좋았습니다.
Self-KD (CNN -> CNN, AST -> AST)
- 비슷한 성향의 모델과 KD를 한 경우 소폭 향상 또는 유지가 되었다고 합니다.
Iterative KD
- no-KD를 Teacher로 사용하는 것 대신 KD가 된 Teacher를 사용한 경우 성능향상 없었다고 합니다.
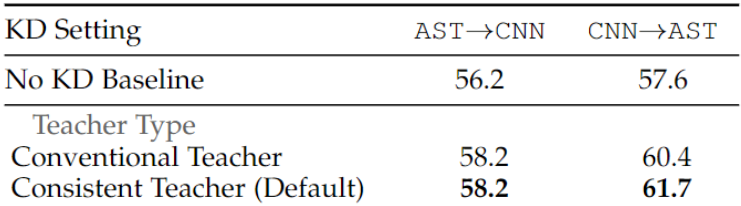
Consistent Teacher
- CNN->AST 에 대해서 높은 성능 향상을 보였다고 합니다. (FSD 50K 기준)
- AST->CNN 은 왜 성능 향상이 안보였는지 모르겠습니다. (딱히 설명 없음)
Separate KD Head
- CLS 대신 DeiT와 비슷하게 DIS Token를 분리하여 Distilation 한 경우 오히려 성능 감소
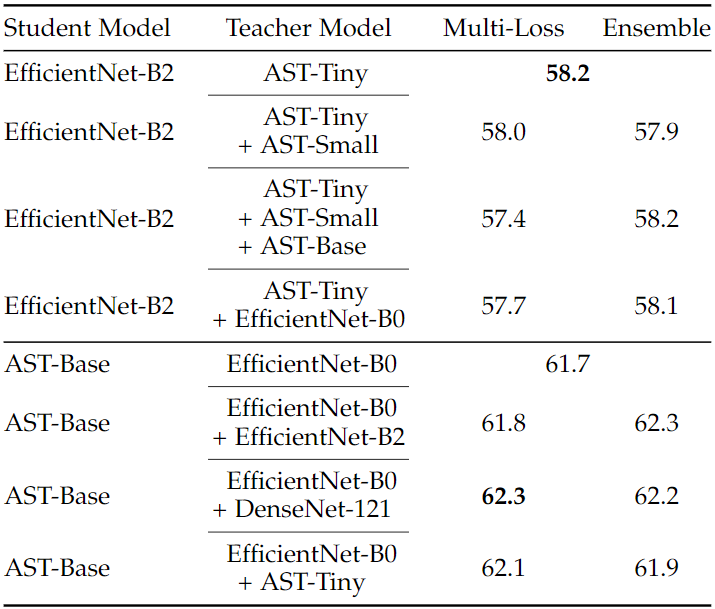
Multiple-Teacher Knowledge Distillation
-
Multi-Loss
- 여러 Teacher에 대한 KD Loss를 계산하여 사용하는 방법
-
Ensemble
- 여러 Teacher에 대한 Prediction 평균 값을 KD target으로 주는 방법
-
결과 분석
- AST에 대한 Multi-Teacher 사용은 딱히 효과를 보지 못함
- CNN 계열 모델들에 대한 Multi-Teacher 사용은 성능 향상 효과를 봄
- Multi-Loss와 Ensemble 방법에 대한 우위를 가리긴 애매해 보임
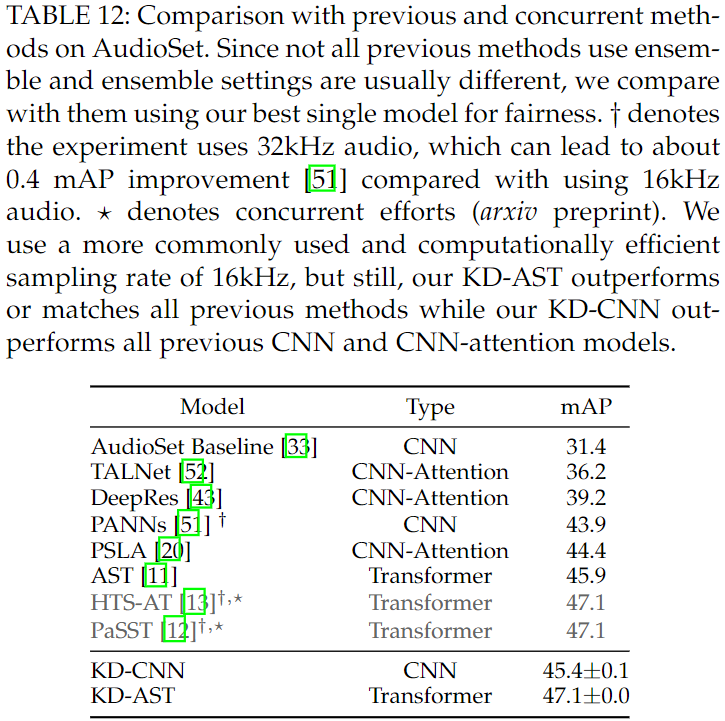
최종 성능 (AudioSet Full)
- HST-AT와 PaSST와 견주는 성능이 나옴
- 32kHz Sampling Rate 가 아닌 16kHz Sampling Rate 사용했음에도 좋은 성능을 보였다고 주장

Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!