Sound Classification 정리 2. PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation
0
Sound Classification
목록 보기
3/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation
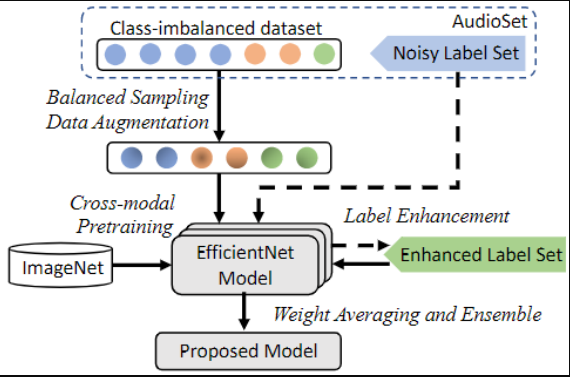
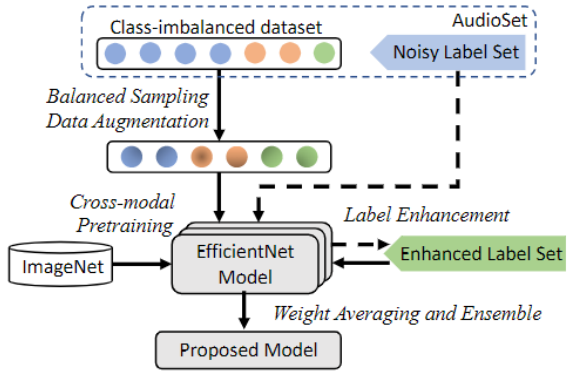
Main Proposal
- 이전 논문들의 애매모호했던 실험 환경 설정 부분을 지적하며 구체적으로 정리함
- Scratch 보다 ImageNet pre-trained weight initialization 이 효과적임을 보임
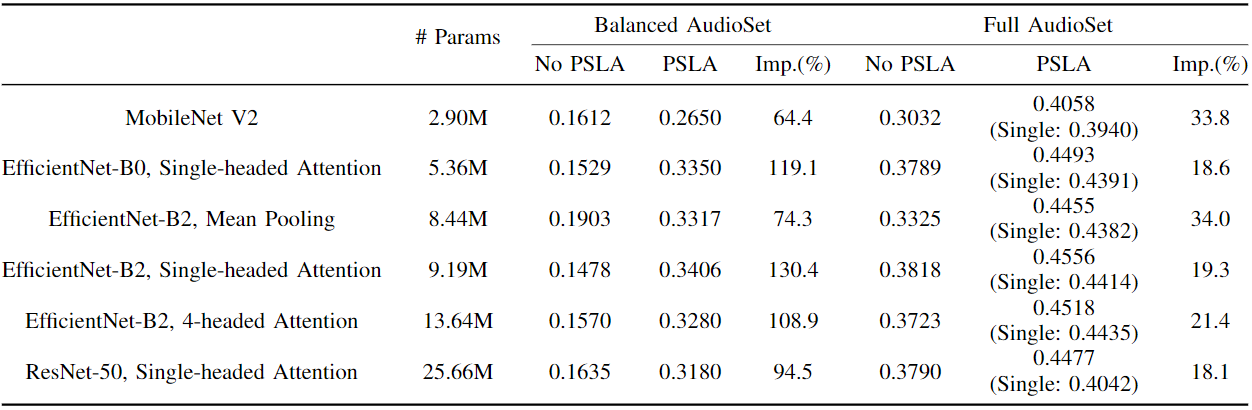
- EfficientNet(B2)를 BackBone 모델로 사용하고, Back-end에 다양한 Aggregation Method 실험결과와 Attention 기반 Aggregation 방법 제안
- AudioSet의 Noise Label 문제를 완화하기 위한 Label Enhancement 방법 제안
- 다양한 Ensemble 기법 적용 및 제안
모델 향상 관점
-
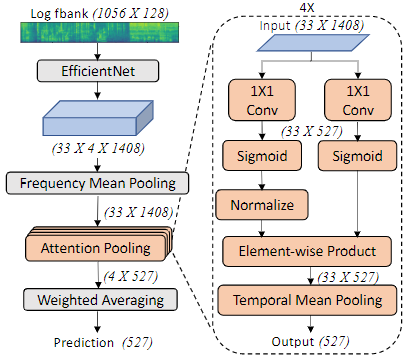
Acoustic Feature
- PANNs 동일하게 Log-Mel Feature를 사용하는데 64보다 큰 128 dimension 사용
-
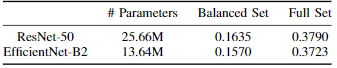
Backbone 모델
- EfficientNet 중 Efficient-B2 모델을 사용
- ImageNet으로 학습된 Efficient-B2 모델의 Weight 값으로 초기화하여 사용
- ResNet-50 보다 적은 파라미터로 유사한 성능을 보임
-
Aggregation Method
- Backbone 에서 32 Stride로 Pooling된 특징을 효과적으로 Aggregation 해야함
- 이전 PANNs 동일하게 Frequency Mean Pooling 사용
- 이후 PANNs 에서는 max+mean pooling을 적용했지만 본 논문에서는 Mean Pooling, Single-headed Attention, 4-headed Attention을 적용하여 비교함
- Single 모델 (Ensembel 전) 기준으로 4-headed Attention 가장 좋은 성능을 보이며, Ensemble 이후에도 Attention 방법이 Mean Pooling 보다 높은 성능을 보임 (Full Set 기준)
Label Enhancement
-
사용 이유
- 기존 AudioSet은 Multi-label Classification Task로 종종 라벨에 오류가 존재한다고 합니다. 데이터 수가 많은 Class의 경우는 치명적이지 않지만 적은 데이터 Class에 대해서는 치명적입니다.
-
알고리즘
- Teacher-student model
- 사전에 Full-set으로 학습된 Teacher Model이 있다고 할때, 이 Teacher 모델로 부터 모델을 Update 하는 방식
- Teacher Model로 부터 각 라벨에 대한 평균 값을 계산함 (꼭 평균이 아니더라도 됨, Procedure 1)
- AudioSet이 제공하는 Class 별 부모 자식 Ontology를 이용하여, 부모 자식 관계와 Teacher에서 계산된 Threshold를 이용하여 Label Update 진행 (Procedure 2)
- 부모 자식 관계는, 2가지 Error 상황으로 정의합니다.
- Type I Error
- Parent Class가 label이 되어 있는데 Child 중 label이 되어 있지 않은 경우
- Type II Error
- Child Class가 label이 되어 있는데 Parent 가 label이 되어 있지 않은 경우

- Child Class가 label이 되어 있는데 Parent 가 label이 되어 있지 않은 경우
- Teacher-student model
-
결론
- AudioSet Eval Set에 대해서는 Label Enhancement 시 오히려 성능 저하가 일어남
- 본 저자는 Speech와 같은 Major Class에서는 소폭 성능 저하를 보이지만, Minor Class 들에 대해서는 소폭 성능 향상이 존재했다고 주장함
- 확실이 DownStream Task (ESC-50, FSD50k)에서는 성능 향상을 보임
Ensemble Strategy
-
거의 뭐 줘어짜는 방법입니다. 크게 4가지로 볼 수 있습니다.
-
Model Weight Average
- 말그대로 Model Weight 들을 평균하여 사용하는 방법
- 각 모델 출력 (Prediction)을 평균하는 것이 성능 향상에 좋지만, Inference Time 기준으로는 좋지 않습니다.
- 어느 정도 안정된 Epoch(논문에서는 10 Epoch 이후)부터 Weight 값을 평균하여 사용한 것이 Single Model 보다 높은 성능을 보입니다.
- 결론
- Prediction 평균 보다는 성능이 떨어지지만, Inference 속도 저하 없이 Single Model 보다 좋은 성능을 보임
-
Checkpoint Average
- Prediction 평균 값을 사용하는 전략입니다. Inference 속도가 저하됩니다.
-
Difference Random Seeds
- 정말 쥐어짜는 방법입니다. 다양한 Random Seeds로 부터 학습된 모델의 출력 값을 평균하여 사용합니다.
-
Average Models Trained with Different Setting
- ImageNet Pre-trained used or not
- Different Mixup rates and Mixup \alpha
- Different Augmentation (SpecAugment)
- Different Label Enhancement Strategies

Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!