[NANSY 리뷰] Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
소개
이 글은 논문을 읽고 정리하기 위한 글입니다.
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
음성 합성, 음성 변환 관련 지식이 부족해 부족한 부분이 많을 수 있습니다. 감안하여 읽어주시면 감사합니다🙏
Introduction
-
본 논문은 음성으로 부터 정보를 분석하고, 이러한 정보를 이용하여 다시 합성하는 Framework를 제안합니다.
-
Fully Self-Supervised 을 이용하여 기존 Voice Conversion의 Linguistic 모델링을 위해 사용하던 phonetic posteriogram(PPG)의 사전 ASR 모델 필요성 제거했을 뿐 아니라 Multi-Language 데이터를 사용하기 어려웠던 부분을 해결했습니다. SSL 만으로도 Zero-shot Voice Conversion, Pitch Shift, time-scale modification 등 에서 좋은 성능을 보였다고 합니다.
-
음성 분석(Neural Analysis)은 크게 4가지 Linguistic(Language), Pitch, Speaker(Timbre), Energy로 정의했습니다. 이러한 각 성분들을 효과적으로 추출하기 위한 SSL 전략과 모델을 제안합니다.
-
음성 분석의 성분을 추출하기 위해서, 특징으로는 사전에 학습된 Wav2Vec2(XLSR-53)과 Yin Algorithm에서 영감을 받아 새롭게 제안한 YinGram 을 사용했습니다.
-
음성 합성(Neural Synthesis)은 Soure-Filter 이론과 비슷하게 source generator와 filter generator를 각각 구성하고 이 두 출력을 더하는 형태로 사용했습니다.
-
학습하지 않은 언어를 사용하기 위해서, Test-time Self-Adaptation(TAS) 학습 전략을 제안합니다. TAS는 별도의 model finetuning 과정을 필요로 하지 않고, languistic feature 입력에 대해서 self-adaptation을 진행하는 방법입니다.
Proposed Method
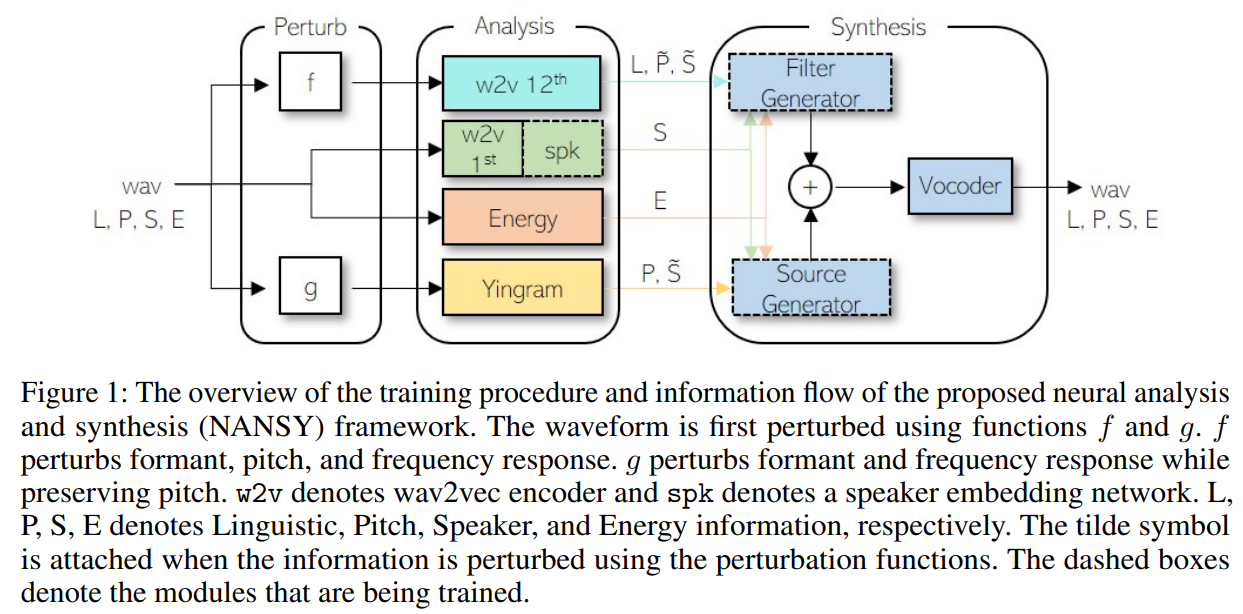
전반적인 NANSY framework는 위 그림과 같습니다. 크게 Information Perturbation, Analysis, Synthesis 3부분으로 구성되어 있습니다.
Information Perturbation
본 논문에서 음성의 중요성분을 4가지로 가정하였습니다. 이러한 4가지의 음성 성분을 Explicit 하게 학습시키는 것은 모호합니다. 기존에 Content와 Style의 정보를 나누기 위해서 사전의 학습된 ASR 또는 Information Bottleneck 전략을 사용했다면, 여기서는 두가지 Information Perturbation 전략을 제안합니다.
-
Perturbation funtion (
f) for Linguistic input- perturbs
formant,pitch,frequency response - 언어 정보는 유지하면서, 이와는 관련 없는 다른 정보들을 변경하여 최대한 관련없는 정보를 제거하는 방법입니다.
- perturbs
-
Perturbation function (
g) for Pitch Estimation (Yingram)- perturbs
formant,frequency response, but preserving pitch - 위와 동일하지만 Pitch perturbation은 사용하지 않았습니다.
- perturbs
Analysis Features
Linguistic
-
56k 시간과 53개 국어로 구성된 음성 데이터로 사전에 학습된 XLSR-53 (Wav2vec 2.0)를 이용하였습니다.
-
XLSR-53은 SSL 기반으로 학습된 모델로 논문에서는
provide language-agnostic linguistic information로 언어에 구애받지 않는 언어 정보를 제공하여 Multi-Language 상황에도 제약받지 않는 좋은 특징이라고 생각하고 채용한거 같습니다. (Masked 기반 SSL은 별룬가?HuBERT, WavLM, wav2vec-BERT) -
Encoder에 어떤 layer 출력을 사용할지는 이전에 middle layer 가 가장 characteristic to pronunciation 라는 점에서 24개의 Encoder 중 12번째 출력을 사용했다고 합니다.
Speaker (Timbre)
-
이전 많은 연구들은 unseen speaker에 대한 음색 특징을 추출하기 위해서, 사전에 화자 인식으로 지도 학습된 모델의 speaker embedding을 사용했습니다.
-
여기서는 fully self-supervised manner로 별도의 speaker labels를 사용하지 않고 학습을 진행합니다.
-
모델은 사전에 학습된 XLSR-53 모델의 1st layer 출력을 계산한 뒤, 화자 인식에서 많이 사용되는 ECAPA-TDNN 모델을 사용했습니다.
-
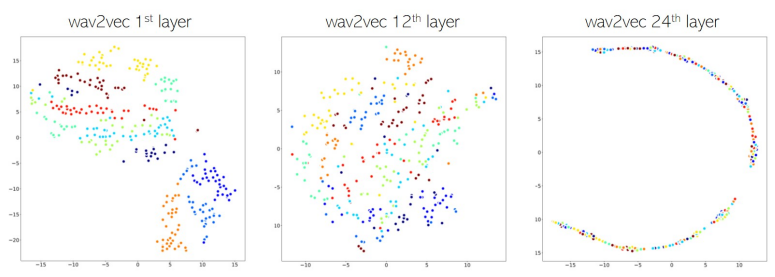
Linguistic 과 다르게 낮은 레이어 출력을 사용한 이유는 VCTK 데이터의 TSNE 결과를 보았을때 speaker를 cluster 하기에 이미 충분했다고 합니다. 그리고, layer가 더 깊어질수록 이러한 화자 정보를 점점 잃어가는 양상을 보였다고 합니다.
Pitch
- 일반적으로 Pitch를
fundamental frequency(f_0)로 보는 경우가 많습니다. 하지만 종종 glottal pulse의 불규칙한 주기성에 의해서, 말에서 삐걱거리는 목소리 (creaky voice), 이것은 보통 gitter 또는 Sub-harmonics로 나타냅니다. 즉,f_0로 Pitch를 정의하기에 어려운 부분이 존재한다고 하며, 본 논문에서는 Yin Algorithm 을 이용한 YinGram feature를 제안합니다.
Yin Algorithm [Paper, YouTube]
Parameters
> t: frame index
> tau: time lag
> W: window_size
> r_t: auto-correlation function
: difference function
Yin Algorithm - : cumulative mean normalized difference function
- Yin Algorithm 에서는 의 최소 값을 가지는 frame를 찾아 를 정하는 형태였습니다. 본 논문에서는 pitch 찾기 위한 별도의 작업을 하지 않고 이 자체를 특징으로 사용합니다.
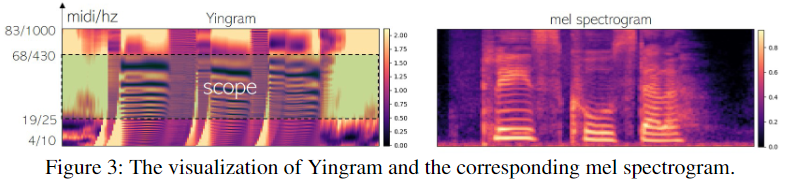
Yingram (Y)
- Yin Algorithm에서 구한 자체로는 controllability 가 떨어집니다. 이러한 문제를 해결하기 위해서
time-lag axis to midi-scale로 Yingram 특징으로 변환합니다.
Parameters
> m: midi note
> c(m): midi-to-lag conversion function
> sr: sampling rate
Setting
> Yingram의 20 bins이 1 semitone 을 나타냄. 한 옥타브는 12 semitone
> W(Window Size): 2048 -> tau: 22 to 2047
> Frequency Range: 10.77Hz to 1000.47Hz-
Synthesis Network 학습시, 위에서 생성한 Yingram 특징 중 25.11Hz to 430.19Hz (즉, Yingram의 19~68번째 midi, 984개 bins) 영역을 입력으로 넣어줍니다.
-
이러한 영역 학습 방법으로, Inference시에 Pitch Shift를 생성된 Yingram 중 입력으로 넣어줄 영역을 간단히 바꿔주는 것으로 가능하다고 합니다.
-
예시로 Synthesis에 넣어주는 Yingram 입력 scope를 20bins down하면(18~67번째로 변경)하면 반음이 올라가는 효과를 볼 수 있다고 합니다.
Energy
- 간단하게 log-mel spectrogram의 frequency bin의 평균 값을 사용했다고 합니다.
Synthesis Network
-
source-filter 이론의 영감을 받아, generator를 2가지 soruce generator 와 filter generator 로 구성했다고 합니다.
-
source generator 는 Yingram (Pitch), S(Speaker Embedding), E(Energy)를 입력으로 받아 Pitch harmonics 를 생성합니다.
-
Filter generator 는 Wav2vec, S, E를 입력으로 받아 Spectral envelope를 생성합니다.
-
수식으로 나타내면 다음과 같습니다.
Parameters
> S: Speaker Embedding
> E: Energy
> M: Log-Mel Spectrogram- 두 Generator의 모델 구조은 1D-CNN layers with gated linear units(GLU) 를 쌓아서 만든 구조로 아래 그림과 같습니다. 두 generator는 입력 dimension 크기만 다릅니다.
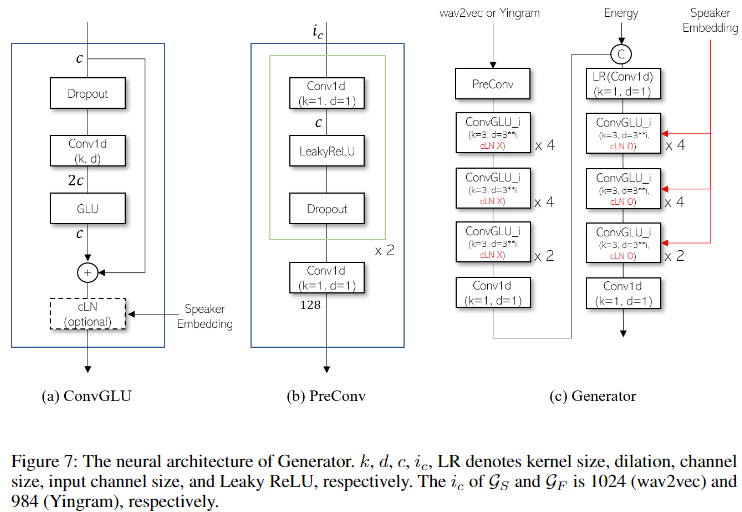
- generator 학습시에는 mel spectrogram 만으로 학습 loss를 주었음에도, 아래 그림과 같이 source와 filter를 각각 생성했을 뿐 아니라 formant를 보존하면서 pitch shifting을 가능하게 했다고 합니다.

- 마지막으로 생성된 Mel-spectrogram을 사전의 학습된 HiFi-GAN vocoder를 이용하여 Waveform 을 생성해냅니다.
Training
Information Perturbation
-
개념적인 설명보다 구체적인 Perturbation 함수에 대해 설명합니다.
-
우선 3가지 함수에 대해서 설명합니다.
- (formant shifting), (pitch randomization)
- 와 의 경우, formant shifting = , pitch shift ratio = , pitch range ratio = 로 샘플링 된다고 합니다. 코드 구현은 보통
parselmouth.praat라이브러리를 이용하여 처리가 이뤄지는 것으로 보여집니다.
- 와 의 경우, formant shifting = , pitch shift ratio = , pitch range ratio = 로 샘플링 된다고 합니다. 코드 구현은 보통
- (parametric equalizer)
- 의 경우 3종류의 low-shelving, peaking, and high-shelving 필터들로 모델링 됩니다.
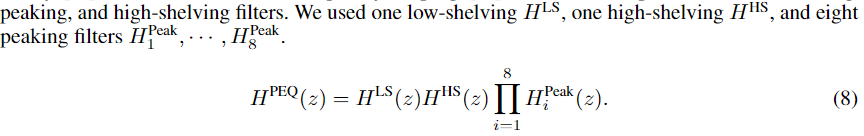
- Each component is a
second-order IIR filterand has acutoff/center frequency, quality factor, and gainparameter 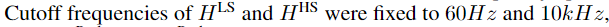
- 다른 구체적인 옵션이 궁금하시면 논문 Appendix A를 참고 하시길 바랍니다.
- 의 경우 3종류의 low-shelving, peaking, and high-shelving 필터들로 모델링 됩니다.
- (formant shifting), (pitch randomization)
-
결과적으로 for Linguistic (wav2vec), for Pitch (Yingram) 으로 표현됩니다.
Training Loss
- 본 논문은 Mel Spectrogram 간의 L1 Loss를 사용합니다. 그러나, 음성 합성에서 L1 or L2 Loss는 생성되는 acoustic feature의
over-smootheness problem을 겪게 합니다. - 이를 완화하기 위해서 이전의 저자가 제안한
speaker conditional generative adversarial training method를 사용했습니다.
Parameters

-
Discriminator
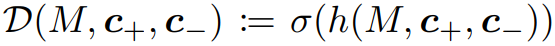
-
projection conditioning를 positive pairs 뿐 negative pairs 에도 동일하게 적용합니다.
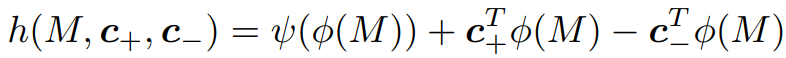
-
Discriminator와 Generator의 Loss function은 각각 , 이며 아래와 같습니다.
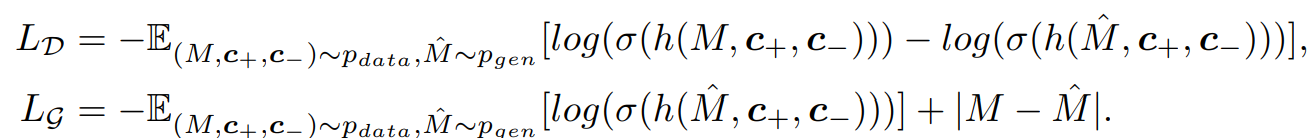
-
사용된 Discriminator 모델 구조는 아래와 같습니다.
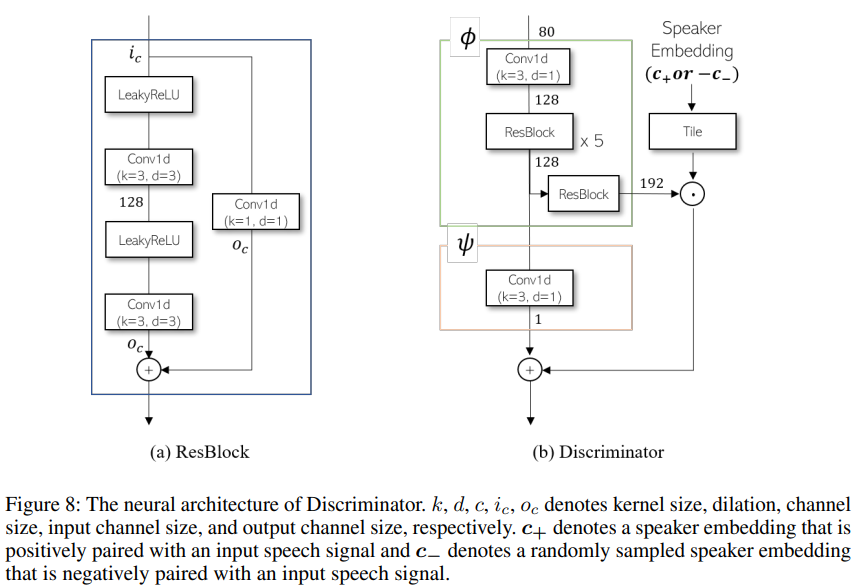
Test-time Self-Adaptation (TSA)
- 말그대로 Test-time의 적용되는 기법입니다. unseen language에 대해서 별도의 모델 finetuning 없이 low-resoruce 상황에서도 효과적으로 성능을 향상 시킬 수 있는 방법을 제안합니다.
- 입력으로 부터 계산된 Ground Truth Mel 과 생성된 Mel 간의 L1 Loss를 계산합니다. 이후 이 Loss를 Filter Generator를 거쳐
Linguistic wav2vec feature만 Backpropagation 신호를 통해서 수정하는 방법입니다. 이 과정은 아래 그림과 같습니다.
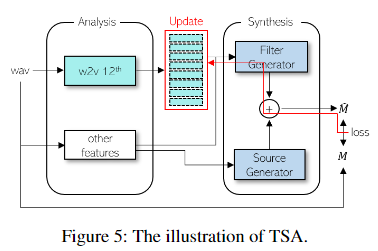
자세한 결과 분석은 논문을 참고해주시기 바랍니다.
결론은 추후에 업데이트 하겠습니다.
결론
Coming Soom
