해당 내용은 coursera의 'Machine Learning : Classification' 강좌 내용을 기반으로 정리되었습니다.
Introduction
1.이전 챕터에서 배운 단순 선형 분류기는 결정 경계를 통해 Class를 구분하였다
2.Logistic Regression은 주어진 데이터가 특정 Class에 속할 "확률"을 구하고 난 후, Threshold( Default 0.5) 값 이상이면 Positive, 이하이면 Negatvie Class로 구분하는 모델이다.
3.Likiehood Function은 각 Data Point가 특정 Parameter 값을 가질 때, 특정 Class에 속할 확률을 구하는 함수이다.
4.모델 성능은 크게 Accuracy, Precision, Recall, AUC/ROC curve와 같은 5가지 척도로 측정된다.
Model Overview
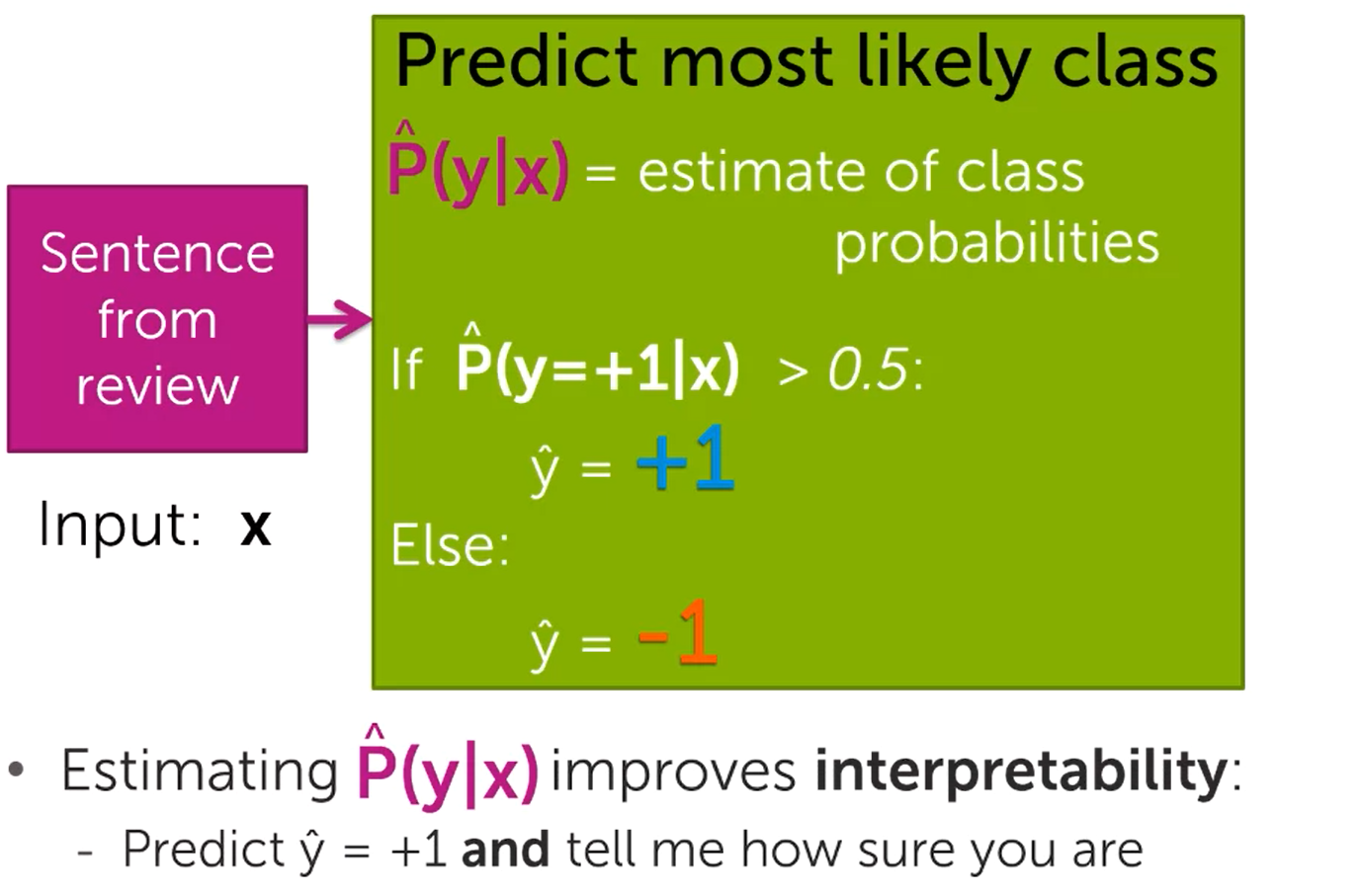
앞의 감성 분석의 예제를 그대로 사용하여 로지스틱 함수의 전반적인 내용을 설명하겠습니다. 우선 각 Input vector 값(Counting)과 해당 Vector의 Coefficient와의 가중합을 통해서 확률 값을 구합니다. 그 값이 0.5이상인 경우 Positive(+) Class, 이하인 경우 Negative(-) class로 분류합니다.
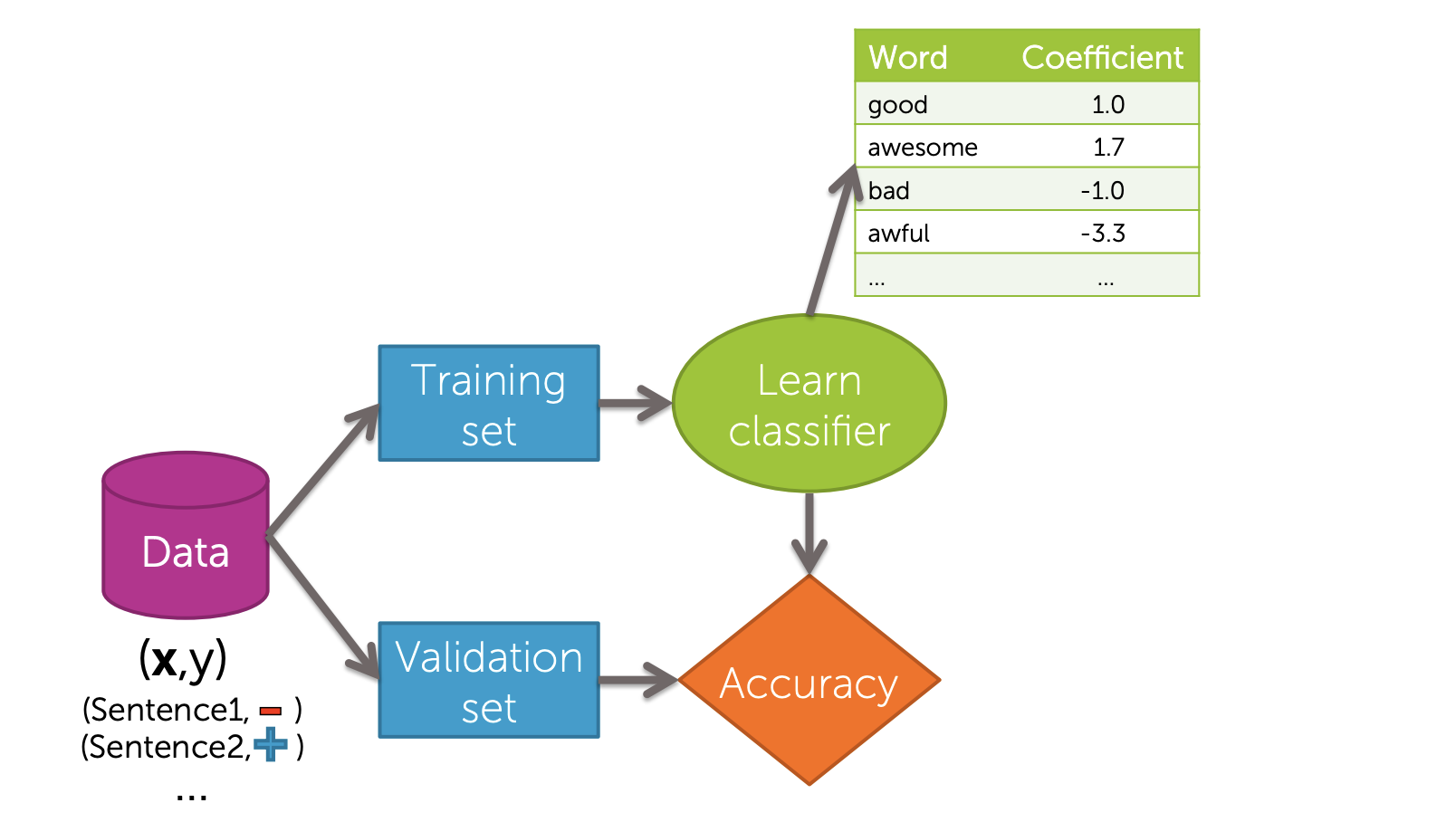
Training Set으로 (각 Data point들의 Feature)의 값들을 구한 뒤에, Validation set으로 검증합니다. 이때 주로 사용되는 Metric은 Accuracy입니다.
그렇다면 확률 값을 구하기 위해서는 어떤 개념들이 필요하고, 분류하는 결정경계는 어떻게 도출되는지 차근차근 알아보도록 합시다.
Conditional probability
Probability as degrees of Belief
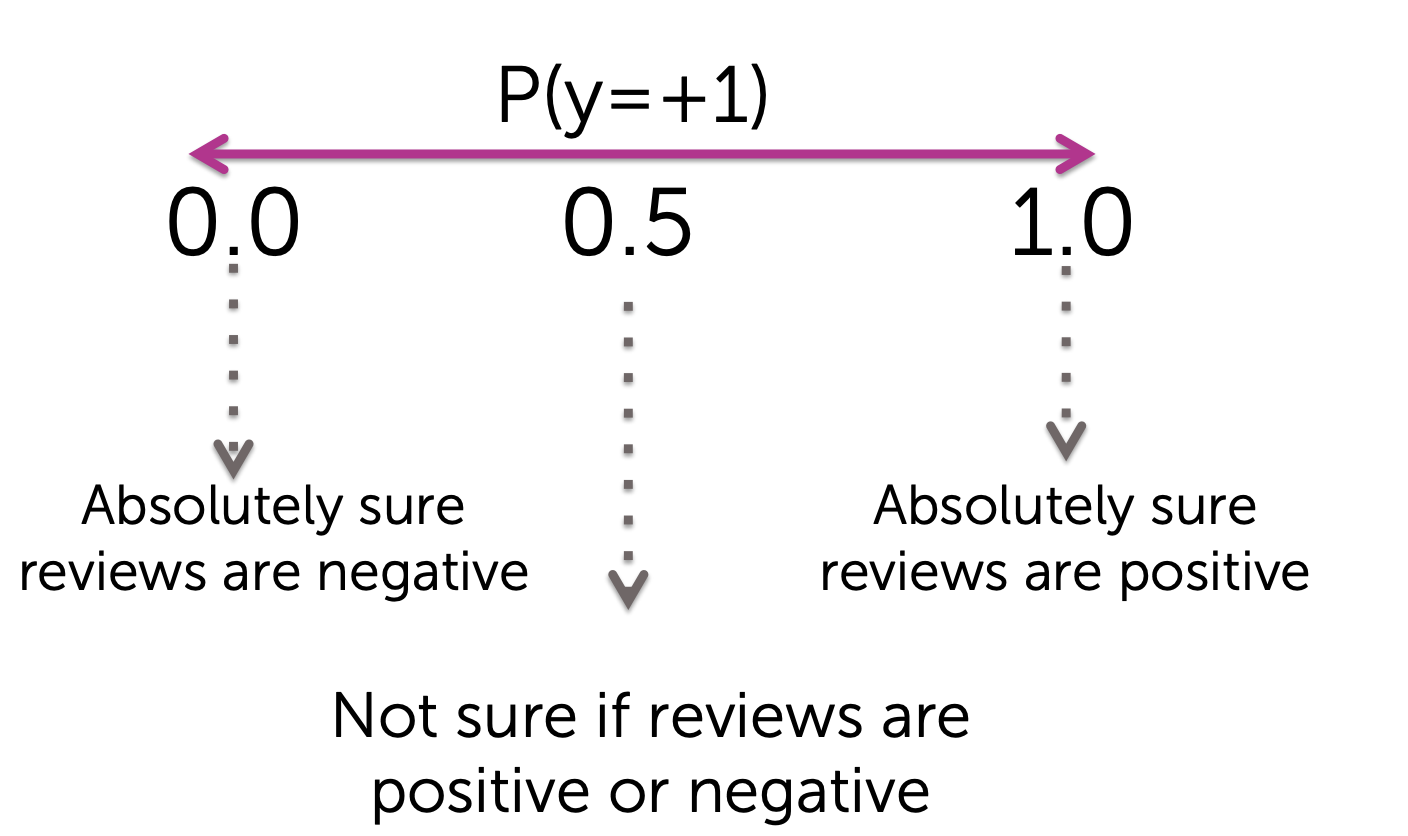
앞서 말했듯이, 각 관측치들이 특정 Class에 속할 "확률"은 Class의 분류 척도입니다. 그렇다면 이 모델에서 "확률"은 어떻게 해석해야 할까요? P(y=+1)은 관측값이 Positive class에 속할 확률입니다. 이 값이 1에 가까울수록 Positive Class에 속하는 것이 "확실"해집니다. 반대로, 0에 가까울수록 Negative Class에 속하는 것이 "확실"해집니다. 즉, 이 모델에서 확률은 확신의 척도입니다.

그렇다면 이 모델에서 조건부 확률은 어떤 의미일까요? 기존의 조건부 확률은 특정 조건 일때, 특정 값이 될 확률을 의미합니다.
위 그림을 보면, 각각의 관측치(sentence)에는 다양한 X값들(words)이 존재합니다.
그러므로 이 모델에서 조건부 확률은 특정 단어들로 만들어진 문장일 때, Positive Class로 속하는 확신의 정도를 의미합니다.
Likelihood Function
Scoring Function
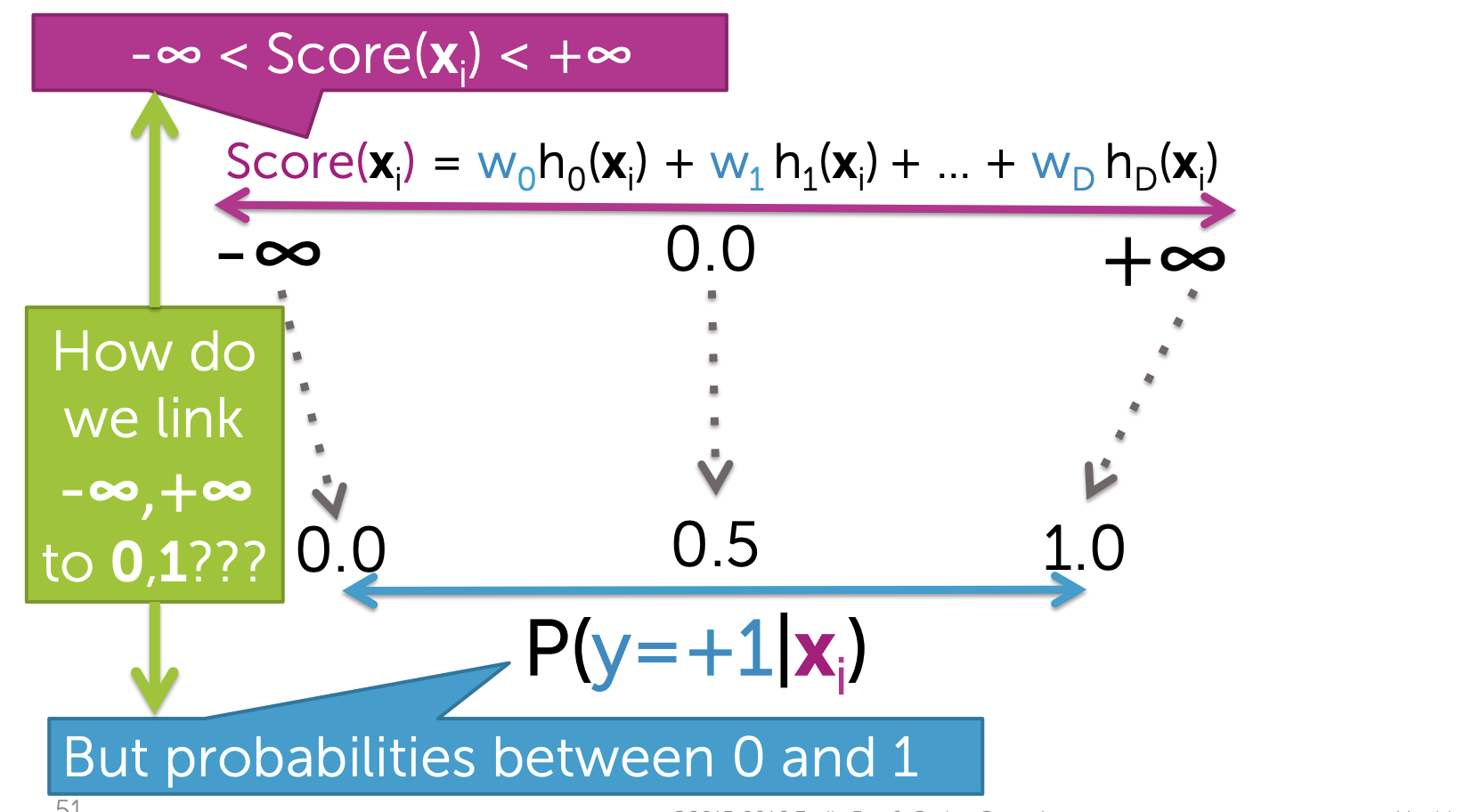
우도함수에 들어가기 앞서, 앞 Chapter에서 배운 Decision Boundary의 기본적인 개념을 알아야 합니다. 기존의 Score함수는 coefficient와 input vector의 가중합입니다. 그 값이 0인 경우에는 Decision Boundary로 결정되고, 양수이면 Positive, 음수값이면 Negative Class로 분류되는 구조였지요.
하지만 이 모델에서는 Score값이 특정 Class로 분류되는 "확신의 정도"로 설명하길 원합니다.
Link Function
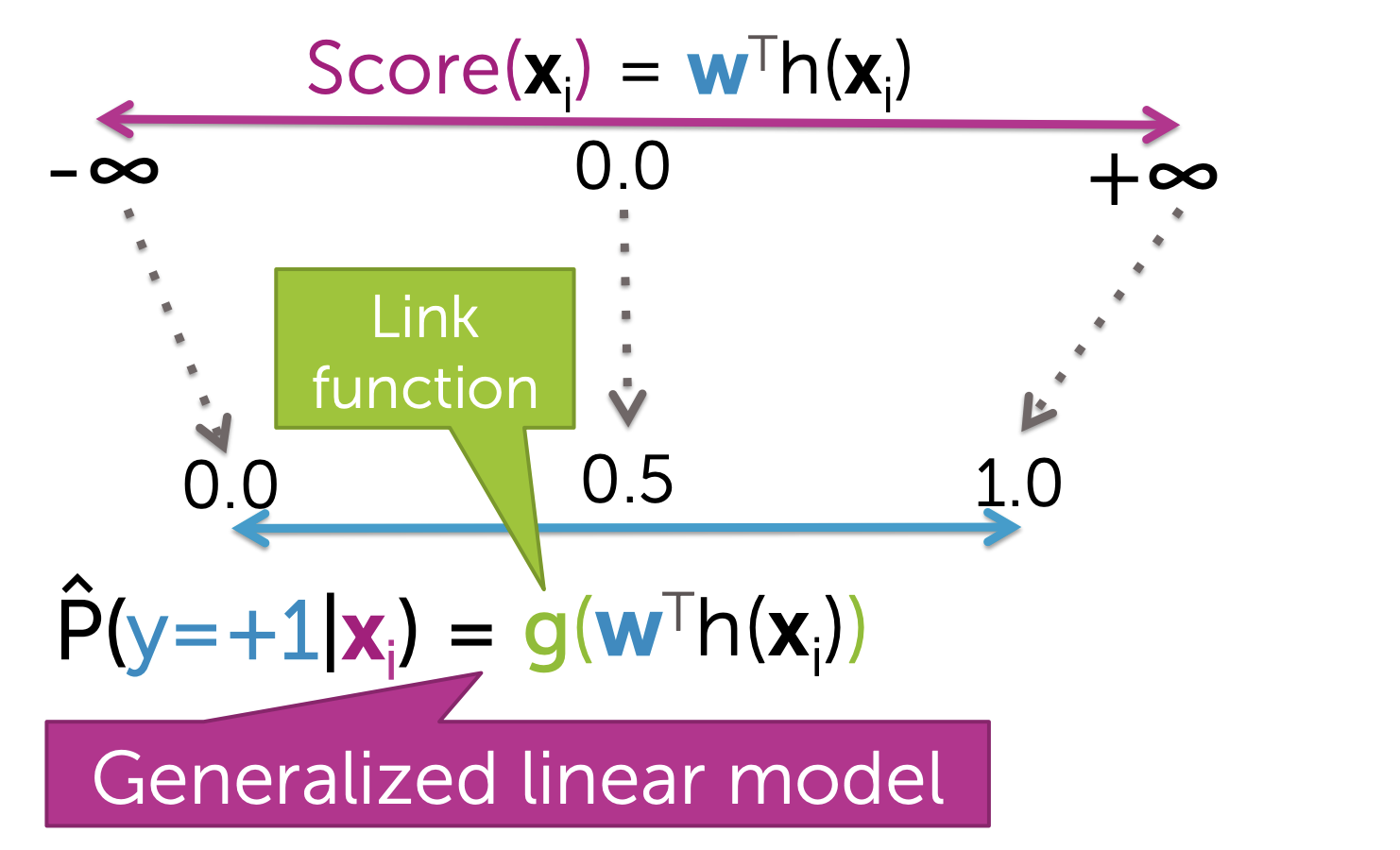
이때, 특정 문장이 특정 클래스에 속할 수 있도록 만들어주는 Link Function이 필요합니다. Link Function을 통해 Score 값을 0~1 사이의 값으로 압축시킵니다.
Logistic Regression : Model
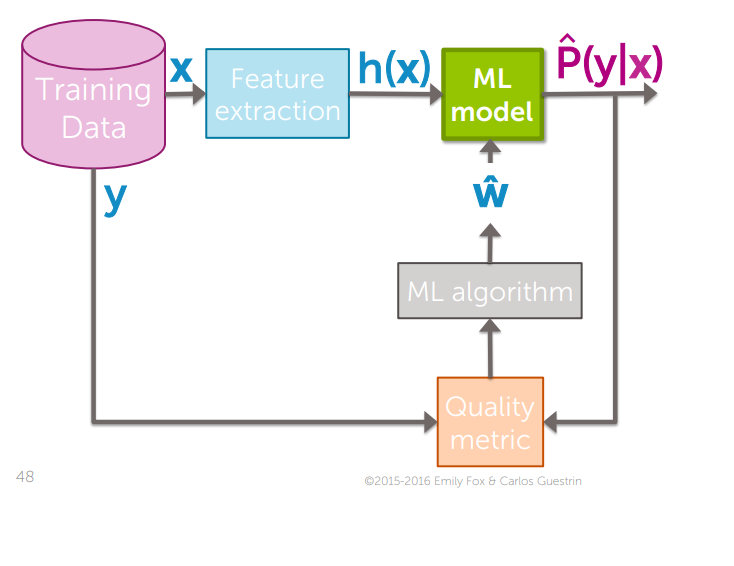
앞서 설명한 내용들을 토대로 보면,
Feature Extraction : Input vector들은 분석에 맞게 Scaling, inputing 작업을 통해 보정을 해줍니다.
y : 실제 데이터에 Labeling 된 값입니다.
: y값과 과의 비교를 통해 Quality Metric이 나옵니다. 기존의 모델 성능보다 높은 경우에, 패러미터를 업데이트 합니다.
: 관측치가 Positive Class로 분류되는 확신의 정도를 의미합니다. 을 통해 확률 값을 구합니다.
