1. 잘 모르면 일단 설치부터...
git clone https://github.com/ultralytics/yolov5.git2. 일단 전체 폴더 구조는 이러하다.
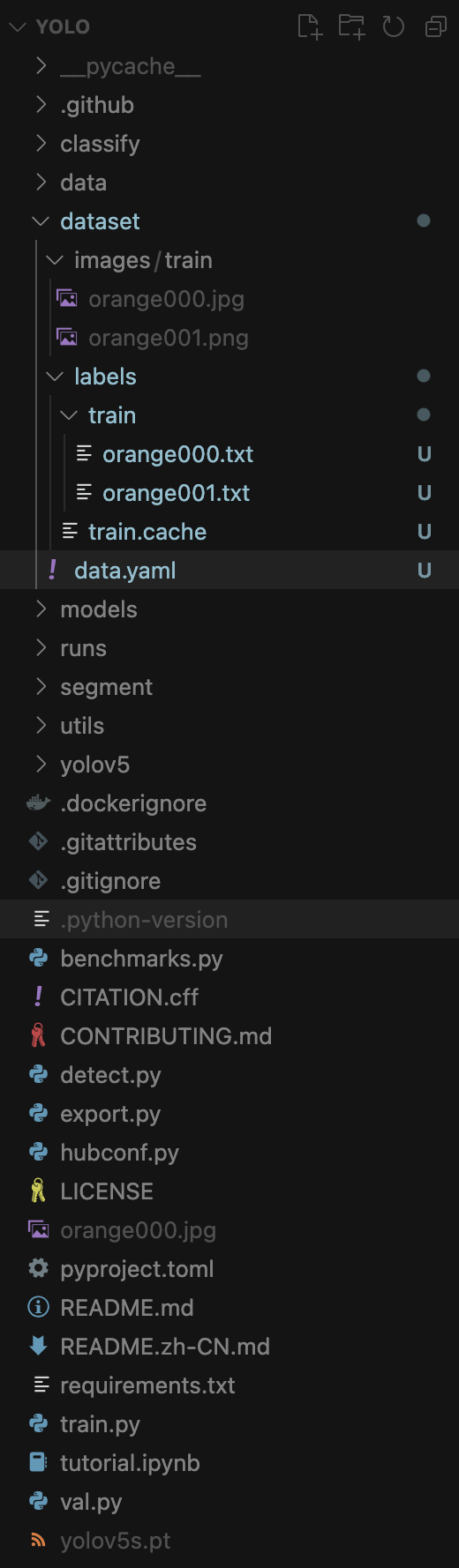
3. 눈에 띄는 dataset 폴더...
3-1. data.yaml
경로의 기준은 yolov5 최상위 경로이다.
train: ./dataset/images/train
val: ./dataset/images/train
nc: 1 # 클래스 수
names: ['orange'] # 네가 지정한 클래스 이름3-2. images/train 폴더
훈련시킬 이미지를 넣는 폴더
3-3. labels/train 폴더
훈련시킬 이미지로 탐지 대상을 선택하여 그 정보를 넣는 폴더
4. 그래서, 이미지는 알겠는데 라벨은 어떻게?
4-1. labelImg
가장 괜찮은 방법인거 같은데 실행이 원만하지 않아 패스.
4-2. Make Sense
- 이미지를 불러온 뒤 특정 영역을 선택하여 탐지할 이름을 지어주면 된다.
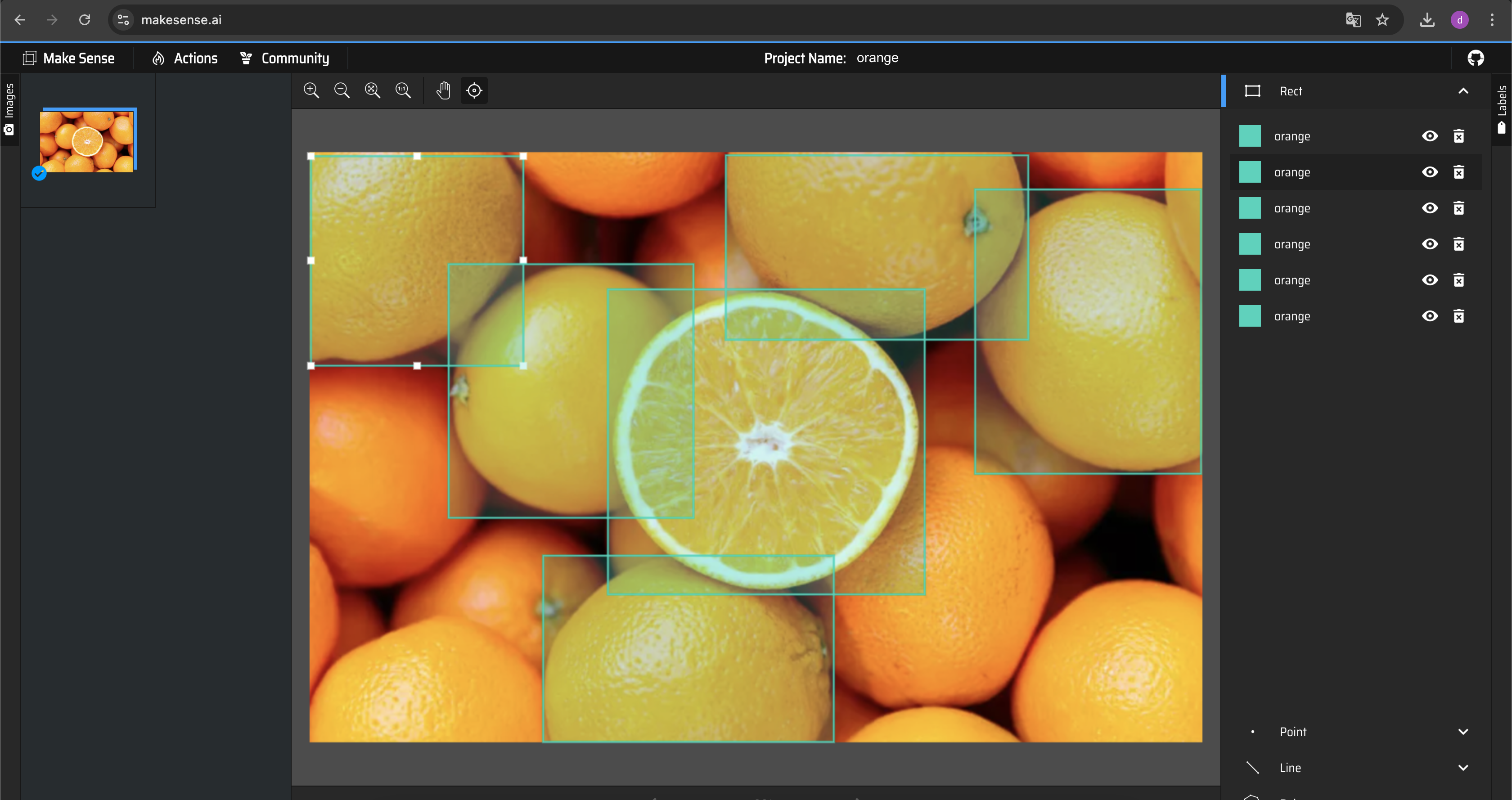
- Actions > Export rect annotations
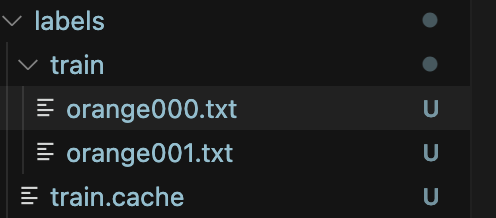
4-3. Export 후 압축 해제
이미지파일명.txt 파일이 남는다.
4-4. dataset/labels/train 폴더로 복사
이런 느낌이다.

5. 꼴랑 이미지 2개지만 훈련해보자.
- 이미지의 크기는 320으로 세팅한다
- 배치수는 1
- 반복 횟수는 10번
- 데이터 yaml 파일 경로는 ./dataset/data.yaml
- 결과 파일 저장 생략
- 기존 모델인 yolov5s.pt 을 불러와서 거기서부터 훈련
- 이름은 ver0.1 로 한다.
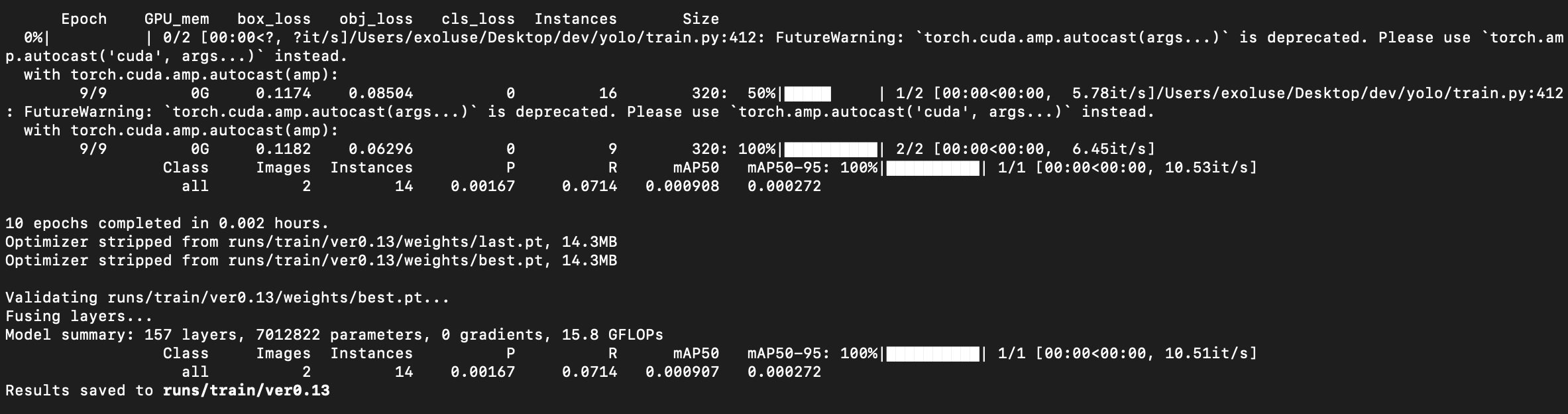
python train.py --img 320 --batch 1 --epochs 10 --data ./dataset/data.yaml --weights yolov5s.pt --name ver0.1 --nosave- 10번 반복 후 마무리~

| 옵션 | 내용 |
|---|---|
| --weights | 훈련된 모델 파일 경로(이 옵션을 빼면 처음부터 훈련하게 된다.) |
| --img | 입력 이미지의 크기 (예: 640) |
| --source | 이미지를 넣을 경로 (단일 이미지나 디렉토리 가능) |
| --conf | 최소 신뢰도 (예: 0.25, 너무 낮으면 안되니 적당히) |
| --save-txt | YOLO 형식의 .txt 라벨 파일로 결과 저장 |
| --save-img | 인식 결과가 표시된 이미지를 저장 |
6. 훈련을 했으면 탐지 돌려봐...
- best.pt 을 불러와서 탐지
- 이미지 크기는 320
- 탐지할 이미지 원본은 orange000.jpg 로 합시다.
- 신뢰도는 0.3 이하로
python detect.py --weights runs/train/ver0.13/weights/best.pt --img 320 --source ./orange000.jpg --conf 0.3 7. 결과
- run/detect/exp4 폴더에 결과가 저장되었다고 함!

- run/detect/exp4/orange001.png 파일

8. 다른 라벨로 훈련, 탐지
-
원래 이랬던 이미지를

-
말의 머리를 horse, 사람 머리를 human 으로 라벨링 하여 훈련

-
train_batch0.jpg

-
train_batch1.jpg

-
train_batch2.jpg

-
탐지 결과 (신뢰도 0.2)

Finally
당연한 말이겠지만 데이터가 가장 중요하다. yolo 데이터를 최대한 정교하게 많이 만들어서 반복 학습을 해야 좀더 정확한 결과를 볼 수 있겠다. 뭔가 사람같다. 많이 만들고 반복하고...

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.