강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Review
Bellman Equation
V(s)=a∈A(s)∑π(a∣s)Qπ(s,a)
Q(s,a)=Rsa+γs‘∈S∑Pss‘aVπ(s‘)
V(s)=a∈A(s)∑π(a∣s)(Rsa+γs‘∈S∑Pss‘aVπ(s‘))
Q(s,a)=Rsa+γs‘∈S∑Pss‘aa‘∈A(s‘)∑π(a‘∣s‘)Qπ(s‘,a‘)
Bellman Optimal Equation
V∗(s)=a∈A(s)maxQ∗(s,a)=a∈A(s)max(Rsa+γs‘∈S∑Pss‘aV∗(s‘))
Q∗(s,a)=Rsa+γs‘∈S∑Pss‘aV∗(s‘)=Rsa+γs‘∈S∑Pss‘aa‘∈A(s‘)maxQ∗(s‘,a‘)
Value Iteration
Value Iteration은 정책 평가와 정책 개선을 한번에 묶은 것으로 정책에 대한 개선 없이 가치 함수만을 개선하는 방식으로 Loop를 하나로 줄였다. (이것 역시 γ-축약사상을 만족하기 때문에 최적 가치함수에 반드시 수렴한다.)
Definition
V(s)←amax(Rsa+γs‘∈S∑pss‘aV(s‘))
Psuedocode

Conclusion
자세히 보면 벨만 최적 방정식을 Sample로 모으고 있다는 것을 확인할 수 있다.
가치 반복 알고리즘은 Bellman 최적 방정식의 샘플 기반을 추산하는 것으로 최적 가치 함수를 추정한다.
Off-Policy Monte-Carlo
우리는 지난 시간에 Off-Policy 방법을 이용하기 위해 Importance Sampling 방식에 대해서 공부하였다. Random Variable에 두 정책의 ratio를 곱하면 된다.
Gtμπ=k=t∏T−1μ(at∣st)π(at∣st)Gt
Policy Iteratoin
Policy Iteration은 정책 평가 정책 개선 과정을 통해 최적 가치 함수를 추정한다.
- Incremental Policy Evalutatoin TD
V(s)←V(s)+α(rt+γV(st+1)−V(st))
Q(s,a)←Q(s,a)+α(rt+γQ(st+1,at+1)−Q(st,at))
- Greedy Policy Improvement : PI
π‘(s)=arga∈A(s)maxQπ(s,a)
- ϵ−greedy
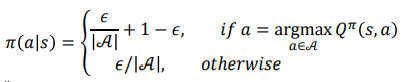
Importance sampling for Off-Policy TD
Random Variable에 policy weight를 곱해주면 된다.
V(s)←V(s)+α(μ(at∣stπ(at∣st(rt+γV(st+1))−V(st))
Q-Learning no Importance Sampling
하지만 importance sampling을 위해 weight를 곱해주는 것은 데이터의 분산을 높여 많은 시뮬레이션을 요구한다고 밝혀졌다. 그러면 weight 를 곱하지 않고도 Off-Policy를 사용하는 방법은 없을까? 답은 Q-Learning 이다.
Psuedocode

Q-Learning Objective
가만보면 Q-Learning에서 TD가 최적 벨만 방정식의 모습임을 바로 눈치챌 수 있다.
그러므로 Bellman 최적방식의 샘플기반 추산을 통해 가치함수를 추정하는 것이 Q Learning의 본질이다.

Q-Learning이 왜 정책에 영향을 받지 않고 Off-Policy가 가능한지에 대한 수학적인 유도는 DDPG에서 하도록 하겠다.
Replay Buffer
Q-Learning은 Off-Policy 알고리즘이기 때문에 Replay Buffer에 데이터를 보관하여 사용할 수 있다.
Conclusion
오늘 이 시간에는 Off-Policy Q-Learning 에 대해서 알아보았다.
