강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Introduction
Monte Carlo와 TD 방식으로 가치함수를 추정하는 방식은 에 대한 정보가 필요 없기 때문에 Model-Free 방식이라고 부른다. 상태 천이 함수를 추정할 필요없이 환경과 지속적인 상호작용으로 오는 데이터를 이용하여 가치함수를 추정한다. 하지만 Model-Free 방식은 Sample-efficient가 매우 낮다고 알려져 있다.
왜냐하면 어떤 정책으로 만들어진 데이터로 정책 개선을 하면 이전 데이터를 모두 버려야 하기 때문이다.이런 방법을 On-Policy 방법이라고 하며 A2C,PPO,A3C,Policy-Gradient같은 알고리즘들이 On-Policy 이다.
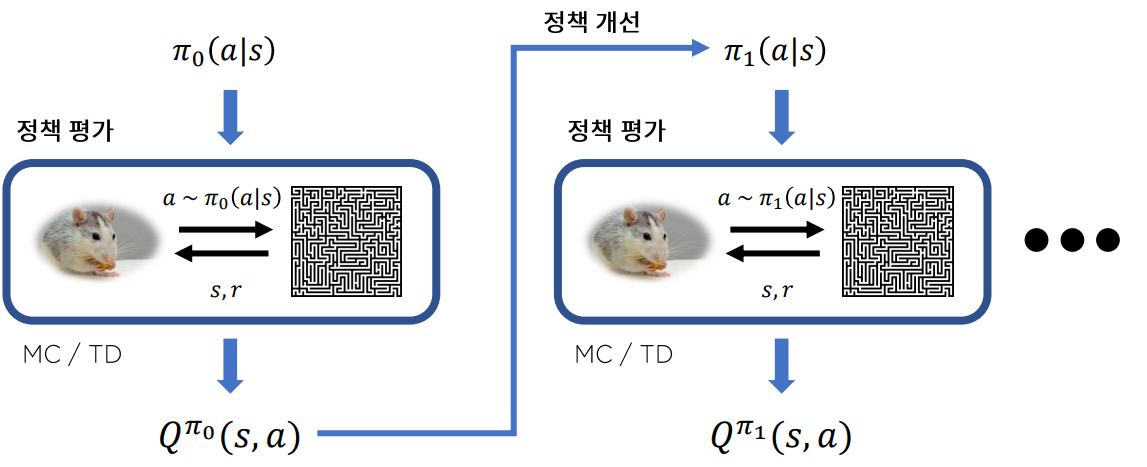
이미 사용한 데이터를 재활용할 수는 없을까? 물론 가능하다.이런 방식을 Off-Policy 방법이라고 한다.
이번 시간에는 Off-Policy에서 Monte Carlo와 TD 방식을 소개할 것이다. 여기서 Off-Policy와 TD방식을 조합하여 만들어진 알고리즘이 그 유명한 Q-Learning 알고리즘이다.
직관적으로 우리는 Off-Policy 방식으로 학습한다. 최근의 기억뿐만 아니라 먼 과거의 경험까지 끌어다 사용하기 때문이다. 그럼 점에서 Off-Policy는 우리의 직관에 더 잘 들어맞는다.
Importance Sampling
가치 함수는 Expectation으로 정의된다. 즉,
random variable에 두 확률 밀도 함수의 ratio(weight라고 부른다)를 곱하면 q라는 확률밀도 함수를 이용해서 p 확률밀도 함수에 대한 expectation을 구할 수 있다. Off-Policy Monte Carlo도 이 방법을 이용하여 Off-Policy 방식을 사용할 수 있다.
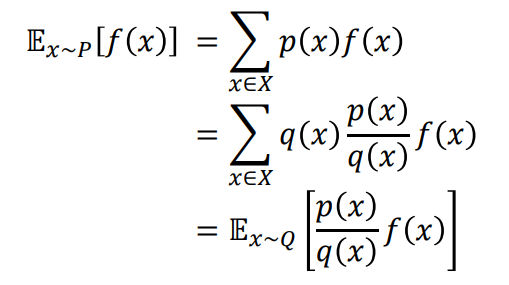
Ratio of Policy

MDP에서 확률 밀도 함수를 정의해 보자.
가 된다.
정책 에 의해 만들어지는 확률 밀도 함수를 라고 하고
정책 에 의해 만들어지는 확률 밀도 함수를
라고 하자
그럼 두 확률 밀도 함수의 ratio는
가 된다.
Off-Policy MC
우리는 radom-variable에 확률 밀도 함수의 ratio를 곱해주면 Importance Sampling에 의해 Off-Policy 방식을 사용할 수 있음을 알고 있다. 그럼 이것을 이용해 Incremental Policy Evalutation식을 수정하면
하지만 Importance Sampling의 경우 분산이 더 커진다고 알려져 있다. 그러면 Importance Sampling 없어도 Off-Policy가 가능할까? 다음 시간에 알아보자.
