Ensemble Bootstrapped Deep Deterministic Policy Gradient for vision-based Robotic Grasping -논문 리뷰
강화학습 논문 리뷰
Reference
- W. Liu et al., "Ensemble Bootstrapped Deep Deterministic Policy Gradient for Vision-Based Robotic Grasping," in IEEE Access, vol. 9, pp. 19916-19925, 2021, doi: 10.1109/ACCESS.2021.3049860.
이 논문은 이전에 소개한 https://velog.io/@everyman123/Automtic-Inside-Point-Localization-with-Deep-Reinforcement-Learning-for-Interactive-Object-Segmentation-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
과 비슷한 문제를 해결하기 위해 고민한다.
DDPG는 Exploration 전략이 Noisy에 의지하기 때문에 Optimal Policy로 가는데 오랜 시간이 걸린다. (Local Optimal에 빠지기 쉽다) 그러므로 이 연구와 이전 연구는 여러 Network로 Ensemble Network를 구성한다.
DDPG의 Target Network와 헷갈리지 말자. 이전 연구에서는 N개의 DDPG Agent를 구성하며 2N개의 Target Network를 만들었다. (각 DDPG의 Actor와 Critic 신경망의 Target)
하지만 이 연구는 크게 두 가지가 이전에 소개한 연구와 차이점이 있다.
- Actor Critic은 1개지만 Critic은 여러개
이전에 소개한 연구는 Actor Critic 모두 N개씩 구성했다.- 모든 Critic을 선택하는 것이 아니라 k개 randomly choice해서 ensemble에 활용한다. 이것은 Exploration을 활성화하기 위함이다.
Model
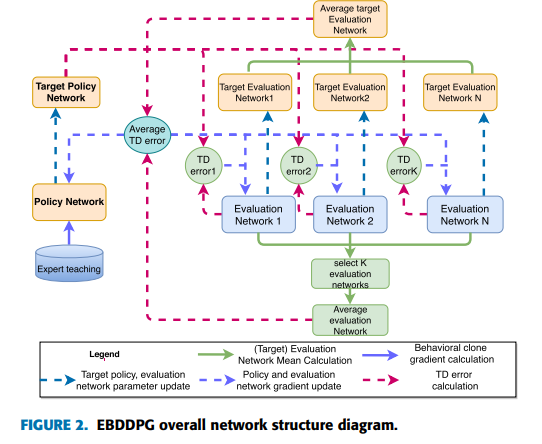
Overview
이 연구는 1개의 Actor 신경망과 다수의 Q 신경망(각 Q 신경망에 대응하는 Target Network) 으로 구성 되었다. 이것은 같은 행동에 대해 다양한 각도로 평가해 최적의 판단을 이끌어내기 위함이다. (최적의 판단은 최적 가치 함수를 의미한다.)
이것은 직관적으로 합리적인 생각이다. 우리가 어떤 역사적 사건을 평가할 때는 여러 시각에서 종합적으로 판단하기 때문이다. 마찬가지로 Q신경망을 근사하는 Critic 신경망은 Actor 신경망의 행동을 평가하는 역할을 하기 때문에 여러 Critic 신경망을 구성해 Actor의 행동을 종합적으로 판단하는 것이 Optimal Policy에 수렴할 가능성을 높인다.
목적함수
Critic 신경망
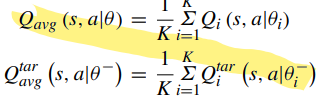
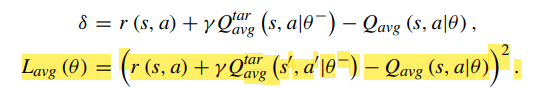
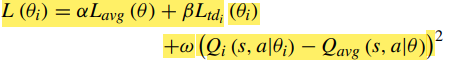
-
k개의 Critic을 선택했을 때 를 계산한다. $L_{avg}은 $ k개의 Q Network를 학습할 때 모두 이용한다.
-
각각의 신경망에 대하여 TD-error을 구한다.
-
각 신경망이 ensemble critic과 얼마나 다른지를 loss에 추가한다. 이것은 regularization효과를 준다. 신경망 끼리 너무 차이가 크다면 학습에 불안정성을 유발할 수 있기 때문이다.
-
and
Actor 신경망

Actor 신경망은 선택된 critic의 Ensemble(Average) critic을 이용해 DDPG 알고리즘대로 Actor 신경망을 Updating한다.
Algorithm

모든 Q신경망을 사용해 평균을 내는 것이 아니라 Random하게 k개를 뽑아 k개의 Q 신경망에 대해서만 학습하고 다시 randomly k개를 뽑는 과정을 epoch가 끝날 때까지 반복한다.
모든 Q에 평균을 내지 않고 선택하는 이유는 모든 Q에 대한 평균은 단일 Q의 변화에 비해 매우 느리게 변하기 때문에 자칫 강화학습에서 가장 중요한 Exploration이 제대로 이루어지지 않아 Local Optimal에 빠질 수 있기 때문이다.(이 가설은 나중에 실험적으로 입증되니 Experiment 파트에서 다시 보자.)
Ensemble 방식을 사용하는 이유도 하나의 Critic에 의지한 나머지 Local Optimal에 빠지는 문제를 해결하기 위해서인데 Ensemble 방식으로 Local Optimal에 빠지면 모양이 빠진다.
이 연구에서는 Q중에 k개를 random하게 선택하고 k개의 Q를 Ensemble 함으로써 agent가 Exploration을 제대로 할 수 있도록 하였다.
Experiment
The Influence of the Number of Ensemble critics on the DDPG Algorithm

Critic의 숫자가 많을수록 성능이 좋아지는 것을 확인할 수 있다. 이것은 한 사건에 대해 다각도로 평가하기 때문에 우리의 직관과 실험결과가 잘 일치한다.
chosen critics and Exploration
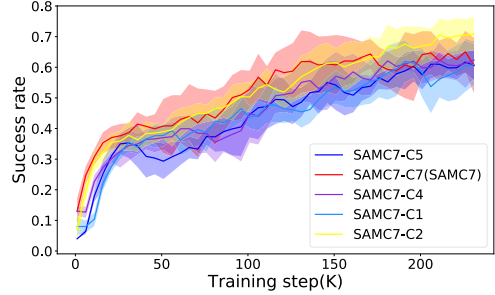
1개의 Actor와 7개의 Critic으로 구성된 동일한 구조에서 Ensemble에 활용할 신경망을 고르는 숫자만 다르게 했을 때의 결과다 보다시피 Choice가 많을 수록 성능이 떨어지고 있음을 확인할 수 있다.
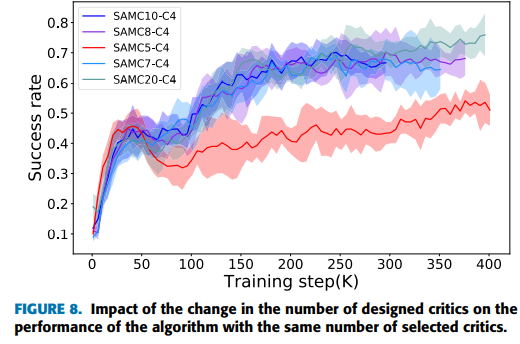
그러면 동일한 숫자를 선택할 때 Critic의 숫자만 많으면 계속 성능이 좋아질까? 예상대로 Exploration performance가 Critic의 숫자가 많아질수록 계속 증가한다. 하지만 critic이 10개일때는 critic이 8개일때 보다 성능이 좋지않다. Critic 갯수를 무조건 늘린다고 성능이 좋아지지는 않는 것 같다. 여기서는 Critic 갯수가 20개일 때 성능이 제일 좋음을 확인할 수 있다.
State of the Art
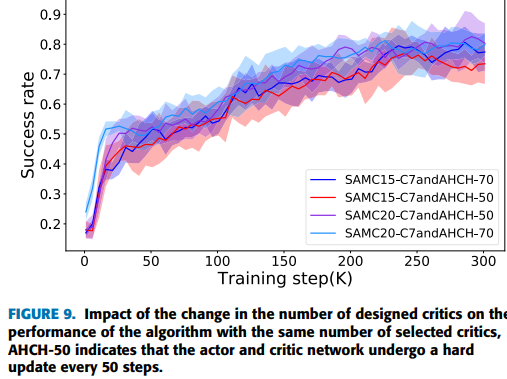
보통 DDPG는 Soft updating 방식으로 Target Network를 updating한다. 반며에 epoch 마다 orginal network의 parameter를 그대로 target에 복사하는 방식이 있는데 이런 방식을 Hard-updating방식이라고 한다. 이 연구에서는 SAMC20-C7 and AMCH-50(20 개의 critics에서 7개를 선택해 ensemble하고 모든 target network는 50epoch마다 hard updating한다) 가 가장 높은 평균성능을 보이며 최고 성능은 90프로를 넘는 것을 확인할 수 있다.
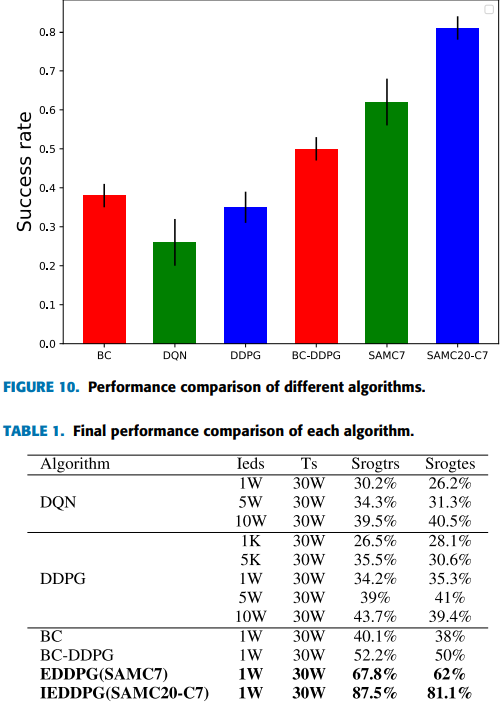
SANC20-C7가 SOTA를 달성하였다.
Conclusion
이 연구는 이전에 소개한 단순히 평균을 내는 Ensemble 방식보다 더 고도화된 Ensemble 방식을 소개한다. Actor 신경망이 1개만 있기 때문에 이전 연구보다 Network 숫자가 확연히 적다. 또한 단순히 평균을 내는 것이 아니기 때문에 Local Optimal에 빠질 가능성을 매우 낮췄다. (성능을 높아지는 건 Local Optimal에 빠지지 않았다는 뜻이다.)
