
6강 LOD 표현식 ① VLOD
View Level of Detail
얼마나 detail하게 데이터를 분류할 것인가?

- 모든 ‘측정값’은 VLOD에서 집계되고 표현된다.
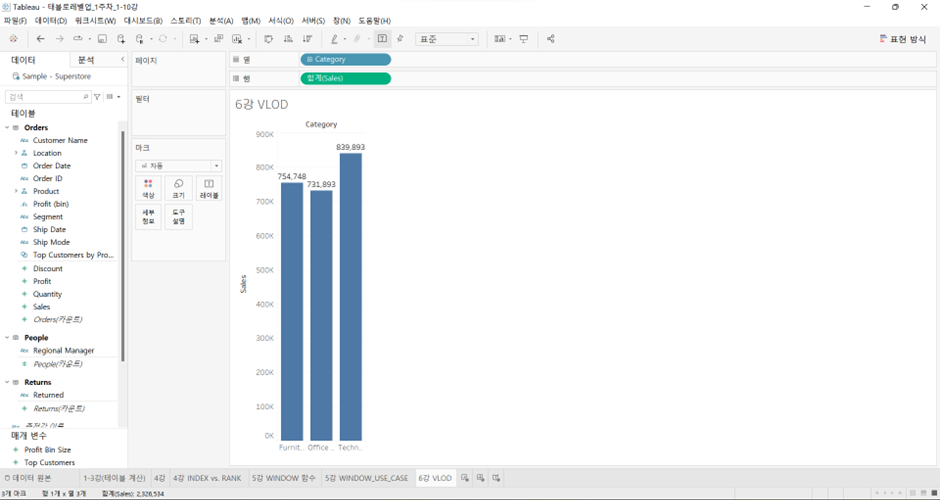
- 위와 같이 태블로의 집계 방식은 합계가 디폴트 값
합계(Sales)에서 우클릭하면 다른 방식으로도 집계 가능
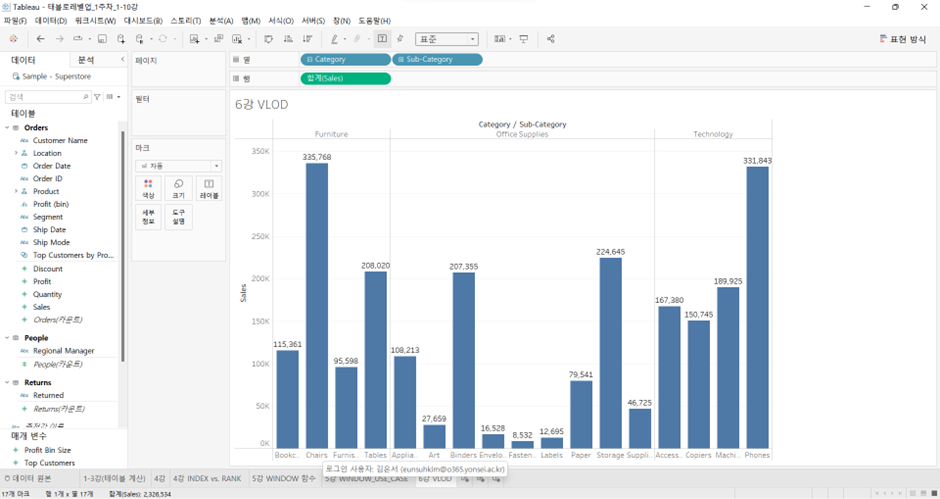
- Sub-Category까지 세분화되었을 때: VLOD를 sub-category 레벨까지 내리면, 기존의 카테고리 레벨에서 집계하는 대신에 서브 카테고리 레벨에서 새롭게 집계 → 이것이 모든 측정값은 VLOD에서 집계된다는 의미
- VLOD에서 표현된다는 것은 위와 같이 VLOD 수준에서 집계된 결과가 눈에 그대로 보인다는 의미
VLOD를 결정하는 것은 오직 차원이다. (O)
VLOD를 변화시킬 수 있는 위치: 행, 열, 페이지(?),필터, 색상, 크기, 레이블, 세부정보,도구설명
(차원을 위의 위치들에 올리면 화면의 LOD는 점점 더 구체적으로 감.)
- Sales를 행에 넣은 상태에서 Category를 열에 넣으면 화면 왼쪽 아래의 마크 숫자가 변하여, LOD가 변했음을 알 수 있음 (마크 숫자 변함 = VLOD 변화)
- 마크 카드 안에서 차원을 색상, 크기, 레이블, 세부정보에 올리면 화면의 LOD를 바꿀 수 있음
- 도구설명, 필터는 화면의 VLOD 바꾸지 않음
- 페이지는 애매, 화면의 LOD 바꿀 수 있는 것으로 볼 수 있음
모든 측정값은 VLOD에서 집계되고 표현된다.
- Tableau v9부터 LOD Expression이 태블로 안으로 들어왔기 때문에 데이터가 집계되는 레벨이 반드시 VLOD일 필요는 없다.
- 버전이 업데이트 되어서 좀 더 쉽게 아래와 같은 질문들에 대한 답을 찾을 수 있게 됨
- 회사 연봉이 업계 평균 대비 어느 정도인가요?
- 용인에서는 경기도 평균 대비 얼마나 더 팔렸나요?
- 17개의 광역지자체의 GDP에 대한 소속 기초지자체의 기여도는 얼마인가요?
Level of Detail Expressions: Include, Exclude, and Fixed
Syntax for LOD Expressions:
{Include [차원1], [차원2] : SUM([측정값])}어떤 종류의 LOD 표현식을 쓸 것인가?
- VLOD에 포함되지 않은 특정 차원을 포함하고 싶을 때 : Include
- VLOD에 포함된 특정 차원을 제외하고 싶을 때 : Exclude
- VLOD에 상관없이 특정 차원을 고정하고 싶을 때 : Fixed
- 여러 개의 차원을 사용할 경우 쉼표(,)로 구분
- 반드시 집계값이 사용되어야 하며, ATTR 또는 테이블 계산식은 사용 불가
7강 LOD 표현식 ② INCLUDE LOD 표현식
현재 VLOD가 Category 수준에서 평균 매출값이 보여지고 있음.
{ INCLUDE [Sub-Category] : AVG([Sales]) } 식으로 구성된 Sales by Sub-Category – Include를 화면에 넣으면
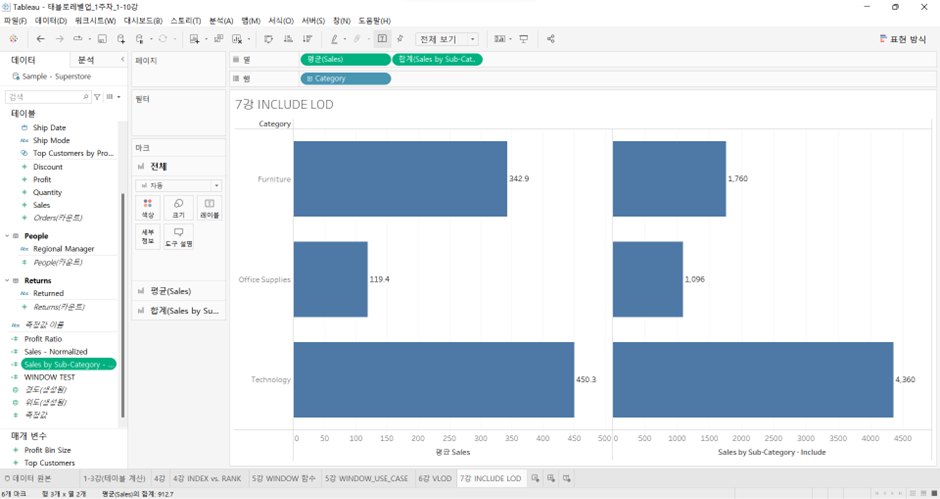
-
어떻게 계산된 것인가? 눈에 보이지 않지만 태블로 뒷단에서
“Avg. Sales by Category and Sub-Category”계산이 먼저 이루어짐. 즉 Sub-Category를 포함하는 레벨에서 평균 Sales 계산이 먼저 이루어짐.
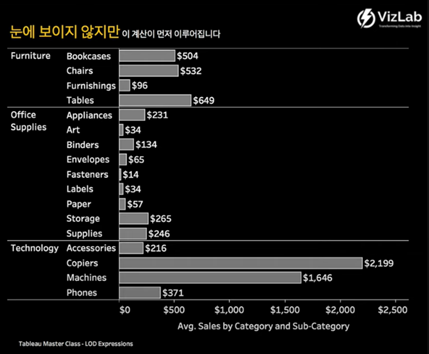
-
다음으로 그 결과를 갖고 카테고리를 기준으로 다시 계산이 이루어짐.

-
현재 카테고리 레벨의
Furniture,Office Supplies,Technology를 기준으로 기존의 결과들이 아래와 같이 재집계.
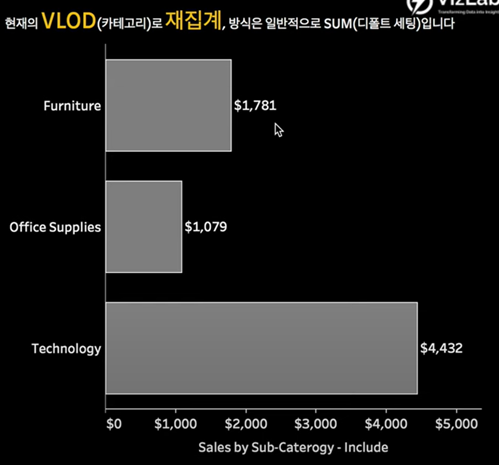
-
그래서 1781 = 504 + 532 + 96 + 649
-
이게 지금 합산으로 이루어지는 이유는 Include LOD 표현식을 화면 안에 올릴 때 합계로 올리기 때문에, 재계산이 이루어지는 방식 또한 합계
왜 재계산?
-
Include LOD는 태생적으로 새로운 차원을 포함하고 있기 때문에, Include LOD에서 만든 결과는 VLOD보다 depth가 깊을 수밖에 없다. 그 깊은 (more granular) 레벨에서 계산된 결과를 그것보다 얕은 (more aggregated) 레벨인 VLOD에서 표현해야 하기 때문에 두 번째 계산이 이루어지는 것이다.
-
이제 Include LOD의 집계를 평균으로 바꾼 후 좌측과 우측을 비교.
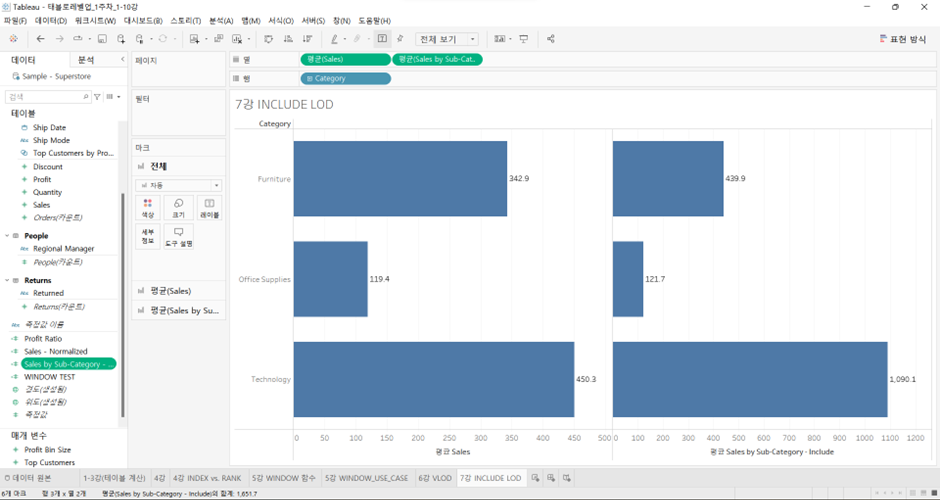
왜 차이가 나나?
왼쪽 계산 방식 = 단순 평균값
- 카테고리별로 매출을 더한다. -> 각 매출을 각 카테고리 행의 개수로 나눈다. (단순 평균값)
SUM([Sales]) / Sum([Number of Records])오른쪽 계산 방식 = 평균의 평균
- 서브카테고리별로 매출을 더한다
- 각 매출을 각 서브카테고리 행의 개수로 나눈다 (여기까지 서브카테고리별 평균 매출)
- 카테고리별로 각 서브카테고리별 평균 매출을 다시 더한다
- 각 매출을 각 카테고리의 서브카테고리 개수로 나눈다
다시 말해, 먼저 서브카테고리 레벨에서
SUM([Sales]) / SUM([Number of Records])
(= Avg. Sales by Sub-Category)다시 카테고리 레벨에서
SUM([Avg. Sales by Sub-Category])/COUNTD([Sub-Category])다시 정리
- Include LOD에 명시된 차원을 포함하여 집계가 이루어짐 (첫번째 단계)
- VLOD에 맞추어 표현하기 위해 첫번째 계산 결과를 재집계함 (두번째 단계)
- Include LOD의 결과는 VLOD보다 깊을 수밖에 없음. 그래서 더 깊은 레벨에서 1차 집계가 우선 이루어지고 그것보다 더 얕은 수준에서 VLOD를 표현해야 함. 그러기 위해서는 첫번째 결과를 다시 집계할 수밖에 없음. 여기서 두번째 계산.
Include 연습
각 도시(City)별 평균 매출(Sales)을 기준으로 최대-최소 편차가 다섯 번째로 큰 주(State)는 어디인가요?
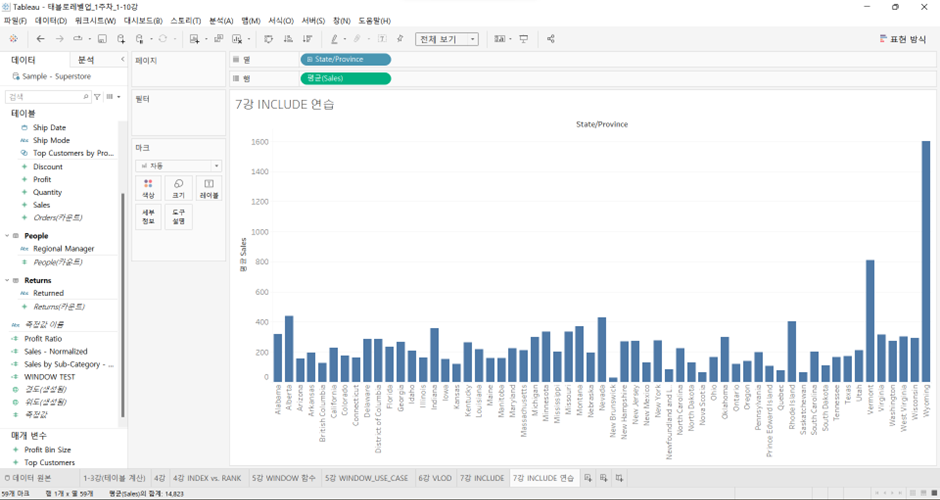
위는 단순히 각 주별 평균 매출을 나타낸 것.
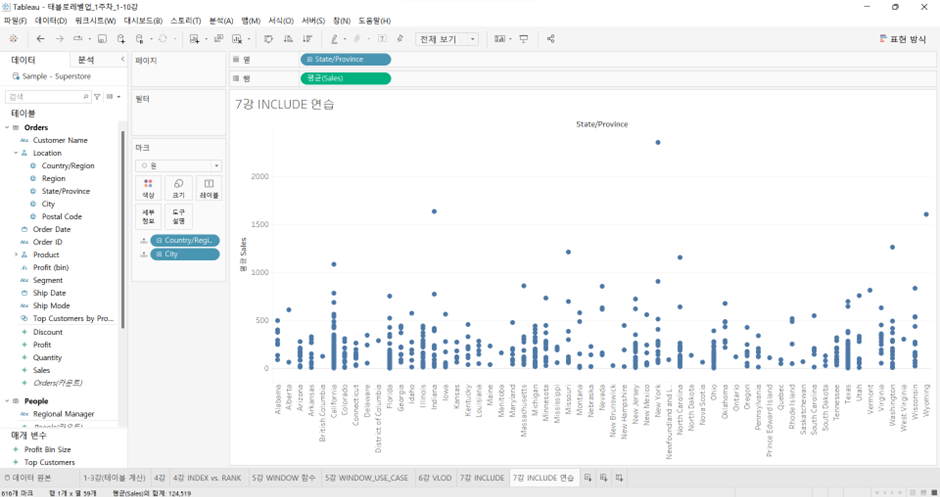
City 추가하고 원으로 바꾸면,
위의 원 하나하나는 각 주별로 소속되어 있는 도시들의 평균 매출
계산된 필드 생성
Sales - Avg by City - Include
{ INCLUDE [City] : AVG([Sales]) }이것을 View에 올려준다면
뒷단에서는 도시 레벨을 포함해서 평균 매출을 1차 집계로 구할 것 (아래와 같이)
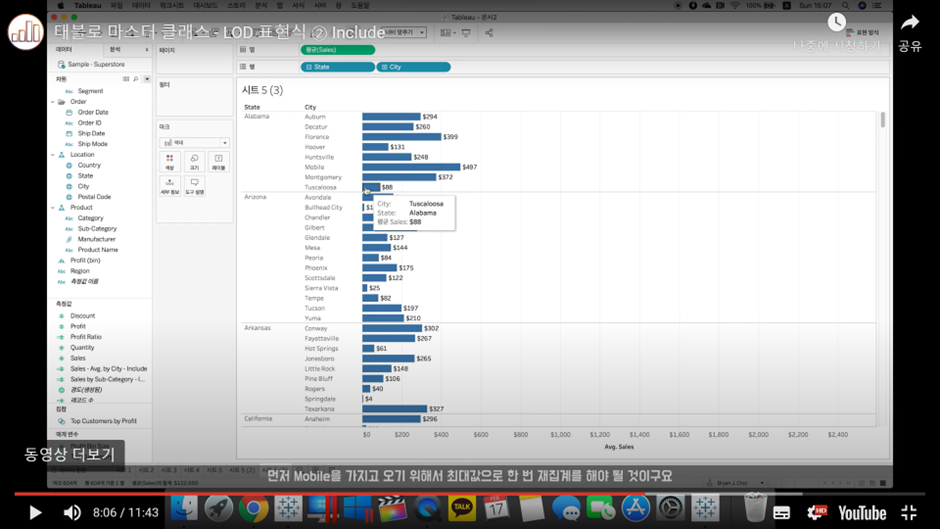
이 1차 집계한 결과를 어떻게 다시 한번 집계해야 할까?
-
Alabama 주 기준으로 먼저 Mobile을 갖고 오기 위해 MAX값으로 한 번 재집계, 다음으로 Tuscaloosa를 갖고 오기 위해 MIN값으로 한 번 재집계
-
Alabama 주 살펴보면 MAX는 Mobile의 평균 매출 금액이었고, MIN은 Tuscaloosa의 평균 매출 금액. MAX-MIN = 편차
-
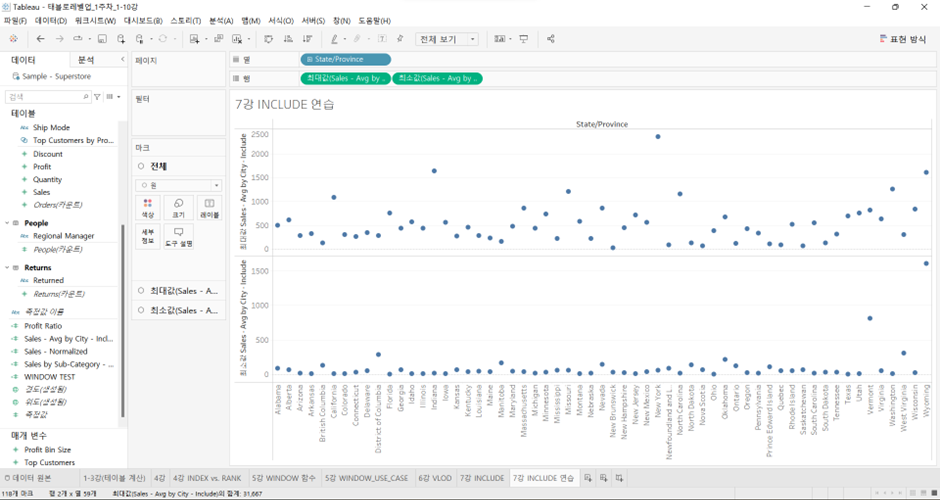
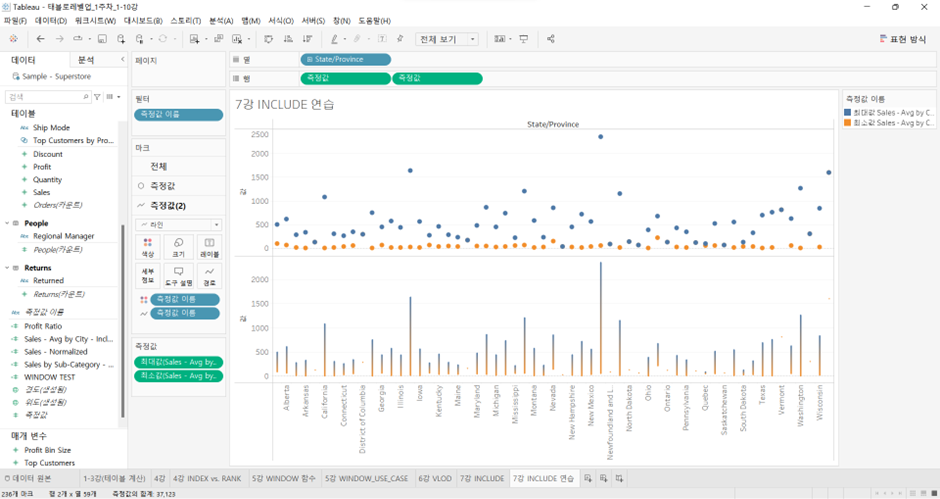
축을 2개 사용하기보다는 최소값을 축 (축의 머리글이 표시된 부분) 위에 얹은 후, 이중 축(Ctrl 누르고 측정값 옆으로 옮기기)을 써서 위의 것은 점으로 두고 밑의 것은 라인으로 바꿈. 그리고 마크 판에 있는 ‘측정값 이름’에 Ctrl 누르고 측정값 이름을 경로에 넣으면 이렇게 된다.
-
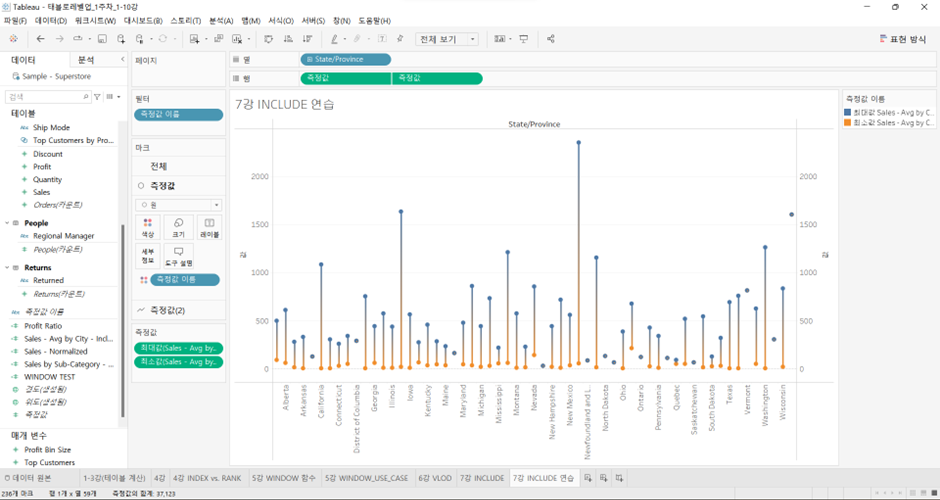
이중축 쓰고 (측정값 중 우측에 우클릭하고 ‘이중축’ 선택) 우측 축에 대해 축 동기화 시키면, 편차가 보는 화면에서 만들어지고 있음.
-
위의 화면에서 편차를 내림차순으로 정리하려면 ‘편차’를 만들어주어야 함
이름: Diff
MAX([Sales - Avg by City - Include]) -
MIN([Sales - Avg by City - Include])- 열에 State 우클릭 >
정렬>필드> 필드명Diff>내림차순에 체크
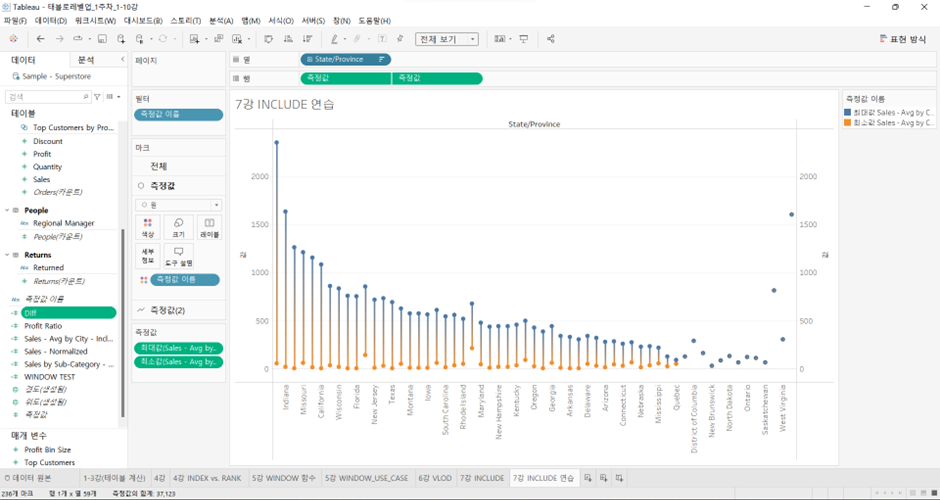
- 이렇게 LOD를 써서 더 낮은 (more granular) 레벨에서 계산된 것을 가지고 더 높은 레벨에서 정렬하거나 값을 구할 수 있음.
Include LOD는 언제 쓰나?
(상황은 그렇게 많지 않음)
- 일단, 데이터셋의 뎁스가 상대적으로 깊어야 함.
- 집계를 2번 해야 할 때 (평균의 최대값, 최소값의 평균 등)
8강 LOD 표현식 ③ EXCLUDE LOD 표현식
VLOD에 포함된 특정 차원을 제외하고 싶을 때
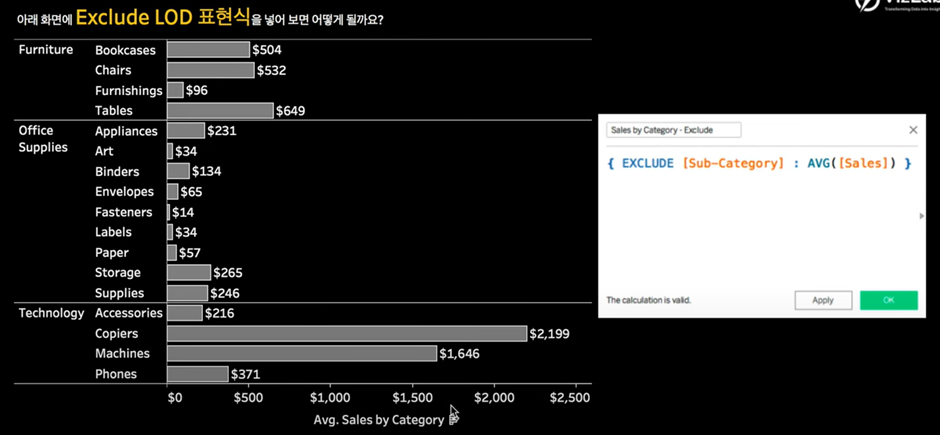
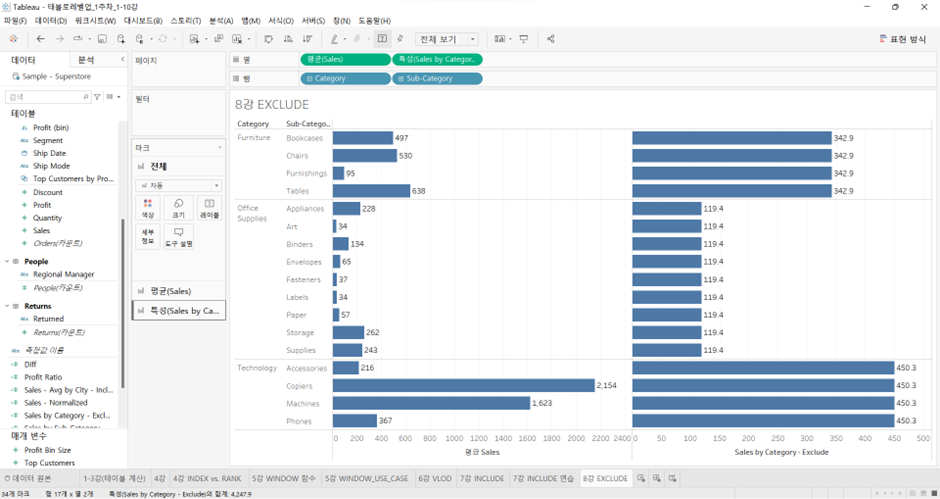
- 평균 매출 금액이 Category, Sub-Category 레벨까지 내려와서 표현
이름: Sales by Category - Exclude
{ EXCLUDE [Sub-Category] : AVG([Sales]) }식을 집어 넣으면 이렇게 됨.
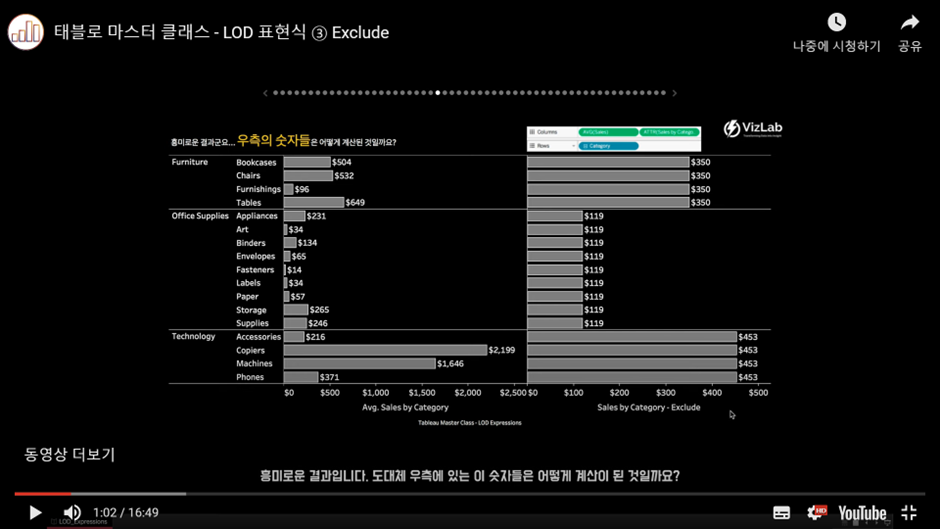
설명
-
서브 카테고리를 제외한 Exclude LOD 표현식을 화면 안으로 집어넣으면,
(기존 화면에서 VLOD는 Sub-Category까지 내려와 있는데) -
Sub-Category 레벨을 제외한 수준에서 평균 Sales가 1차로 계산된다.
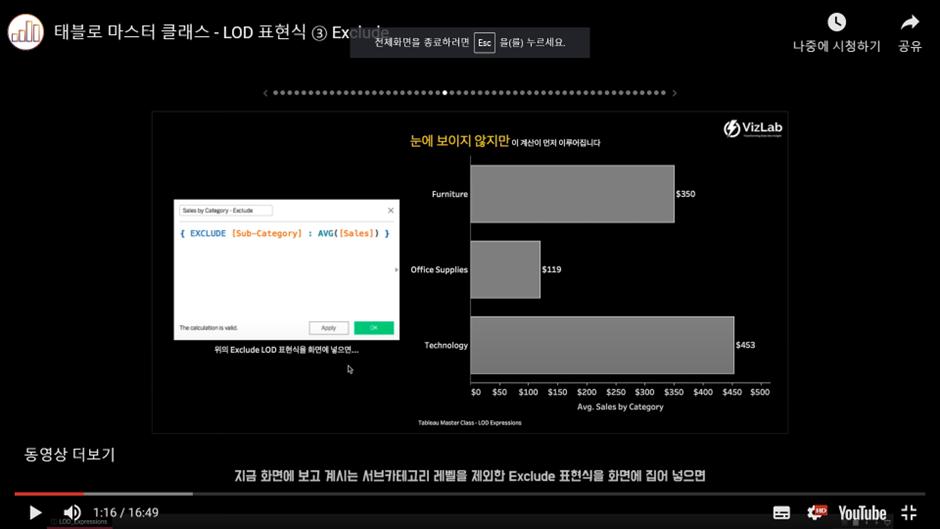
-
그리고 그 결과값은 현재의(기존의) VLOD(=Sub-Category 레벨)에서 표현하기 위해 각 카테고리별로 동일한 숫자들로 복제된다.
핵심 정리
- Exclude LOD에 명시된 차원을 제외한 후 집계가 이루어짐 (첫번째 단계) (Exclude LOD 안에서 선언된 그 차원이 반드시 VLOD 안에 포함되어 있어야 함 – 그래야 VLOD 안에 있는 차원을 제외하고 계산이 이루어질 것)
- VLOD에 맞추어 표현하기 위해 첫번째 단계 결과를 복제함 (두번째 단계)
- 즉, Exclude LOD에서 만들어진 그 계산 결과는 VLOD의 수준보다 항상 얕을 수밖에 없다. 더 얕은 수준에서 만들어진 결과를 더 깊은 수준인 VLOD에 맞추어 표현하기 위해서는 1단계의 계산 결과를 2단계에 복제할 수밖에 없다.
연습문제
예시 1 -> 활용상황 1
도시(City)의 소속 주(State)에 대한 수익(Profit) 기여도를 지도에 표현하라.
- 원 = 각
City - 원의 색상 = 각
City가 속한State의 총 수익에 대한 기여도. 파란색으로 갈수록 수익, 빨간색으로 갈수록 손실 - 원의 크기 = 수익 또는 손실의 규모
이것을 나타내는 지도를 만들기
풀이
City를 더블클릭해서 지도 만듦
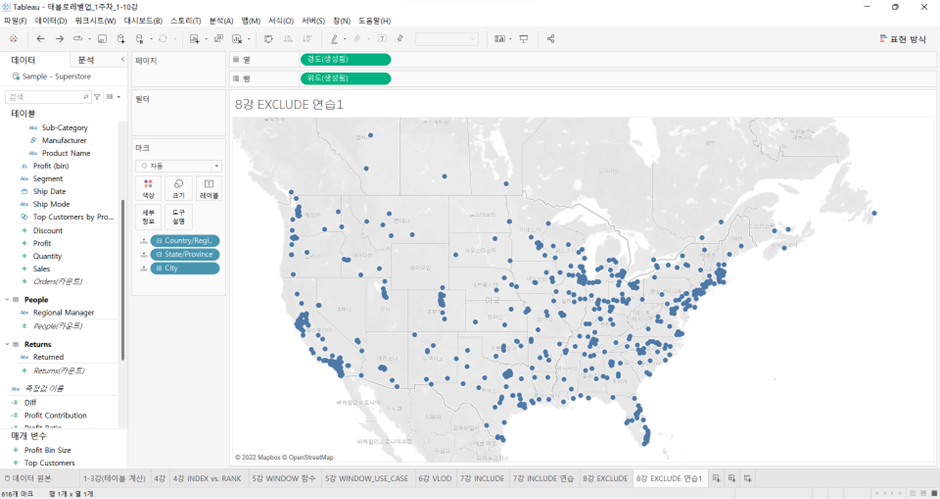
- 색상(각 도시가 속한 주의 총 수익에 대한 기여도)을 위한 계산된 필드를 만들 것
- 기여도를 계산하는 필드는
“각 도시의 수익의 합계 / 해당 도시가 포함된 각 주의 수익의 합계”을 계산해야 함 - 현재의 VLOD는
City레벨에서 형성되고 있기 때문에SUM([Profit])= 각 도시별 수익의 합계 - 현재 VLOD인
City레벨에서 도시를 제외(Exclude LOD) 해버리면State레벨에서 수익이 집계될 것 - 그래서 계산된 필드는
이름: Profit Contribution
식: SUM([Profit]) / ATTR({ EXCLUDE [City] : SUM([Profit]) })- 여기에서
SUM([Profit])은 도시별 수익 ‘집계된 값’ - LOD 표현식은 항상 그 결과가 집계된 값이 아니라, Raw Level의 값이기 때문에 한 번 더 집계해주어야 한다. 그래서
SUM으로 해도 되고,AVG로 해도 되고,ATTR로 해도 됨.
이 계산된 필드를 색상에 올려주면
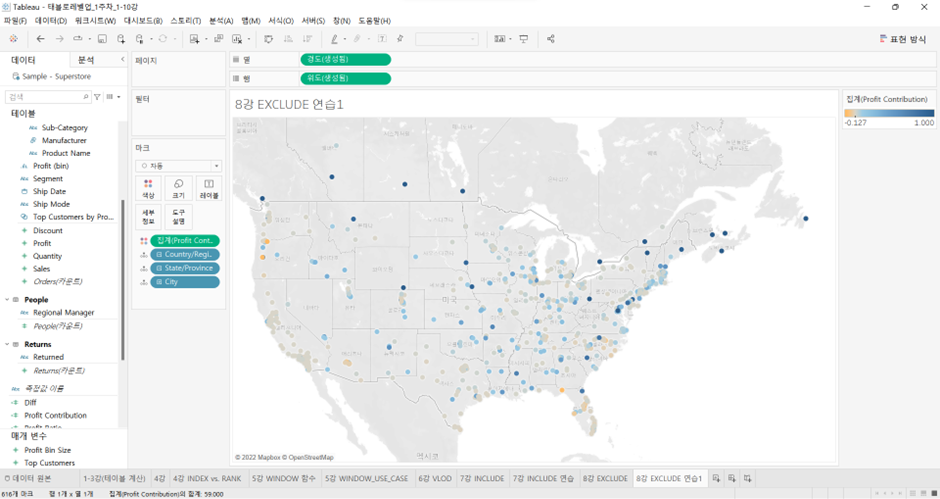
- 마이너스로 주의 수익을 갉아먹는 도시도 있다는 것을 알 수 있음.
- 사이즈
Profit을 크기에 집어넣으면, 가장 작은 값이 마이너스도 나오고 있음.- 그런데 이 화면에서 원하는 것은 수익/손실 상관없이 규모의 '크기'를 표현하는 것이기 때문에
- 크기의
SUM([Profit])을 더블클릭 >ABS(절댓값) 적고 괄호 치면
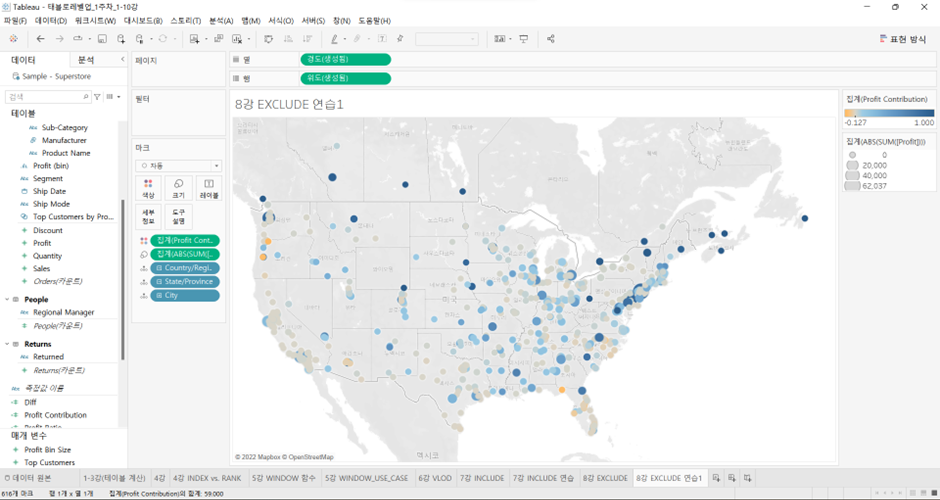
- ABS가 크기를 조정함. 원의 크기를 통해 각 도시의 수익/손실 규모를 알 수 있음
예시 2 -> 활용상황 2
Sub-Category별로 Sales의 총합계가 나와 있는 상황에서, (아래와 같은 상황)
Paper의 값을 기준으로 상대적으로 다른 Sub-Category 항목이 얼만큼 더 팔았는지 혹은 덜 팔았는지를 표현하라.
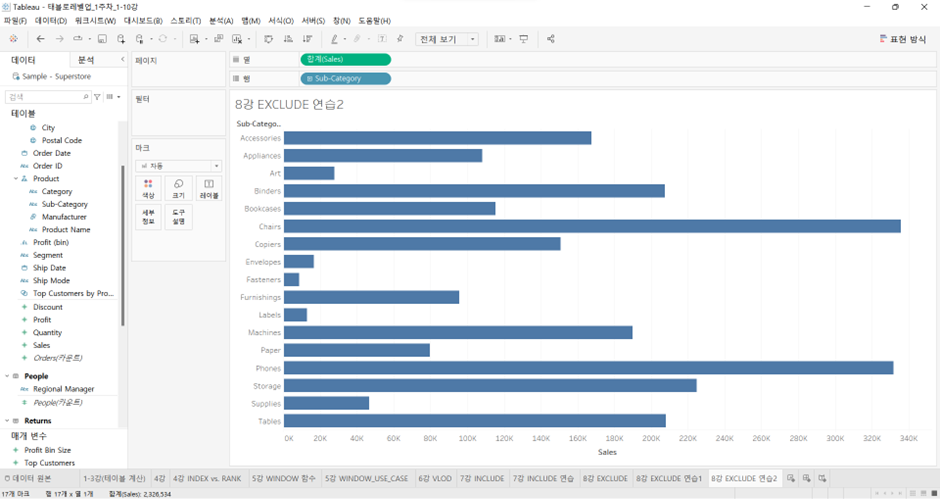
- 계산된 필드 만들기 (첫번째)
이름: Sales - Paper
식: IIF([Sub-Category] = 'Paper', [Sales], NULL)IIF는IFfunction과 동일. 형식은IIF(테스트, 해당하는 경우, 해당하지 않는 경우, [알 수 없음])- Sub-Category가
Paper이면Sales를 반환하고, 그렇지 않으면NULL값을 반환한다.
- Sub-Category가
Sales – Paper을 화면에 넣어 보면
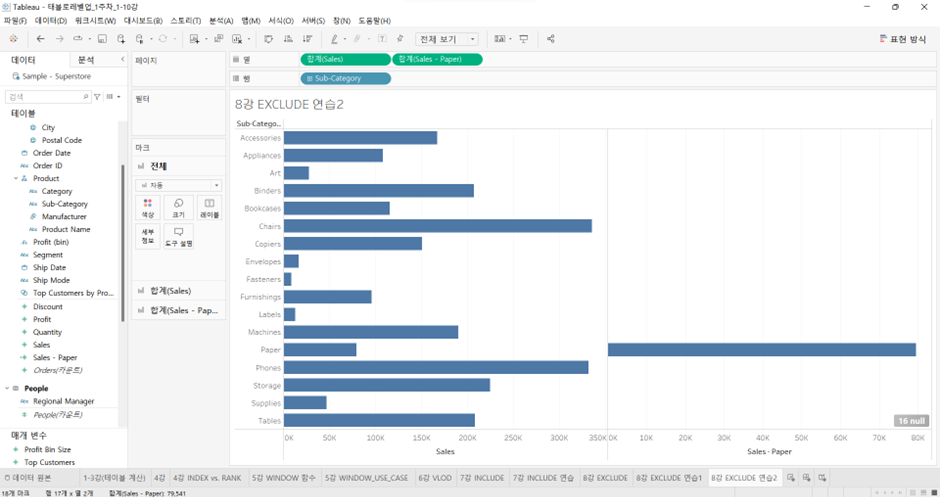
- 계산된 필드 만들기 (두번째, Exclude LOD 포함)
이름: Sales - Paper - Exclude
식: { EXCLUDE [Sub-Category] : SUM([Sales - Paper]) }- 현재 VLOD가 Sub-Category인데, 이를 제외하면 ‘전체 레벨’이 됨. 전체 레벨에
Sales – Paper을 더해 주라는 것. (다 더해 봤자 Sales - Paper의 금액). 그 상태에서 VLOD에 맞춰서 표현해주기 위해 복제된다.
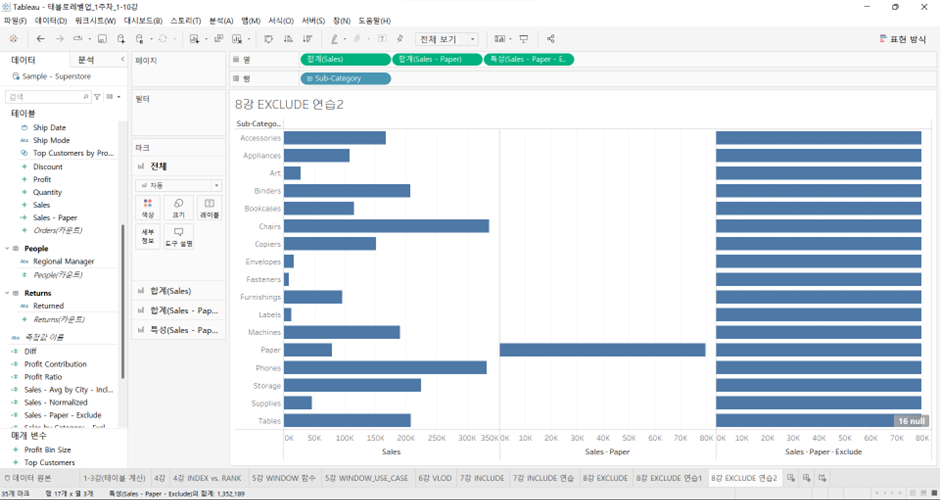
- 계산된 필드 만들기 (세번째) 우리가 원하는 값을 얻기 위해서는 각 Sub-Category의 Sales의 합에서 Sales - Paper - Exclude를 빼주면 된다.
이름: Sales - Relative to Paper
식: SUM([Sales]) - ATTR([Sales - Paper - Exclude])- ([Sales - Paper - Exclude])는 LOD Expression이고 Raw Level에 있는 값이기 때문에, 오른쪽을
ATTR로 집계해주기 - 집계 후 화면에 집어넣으면
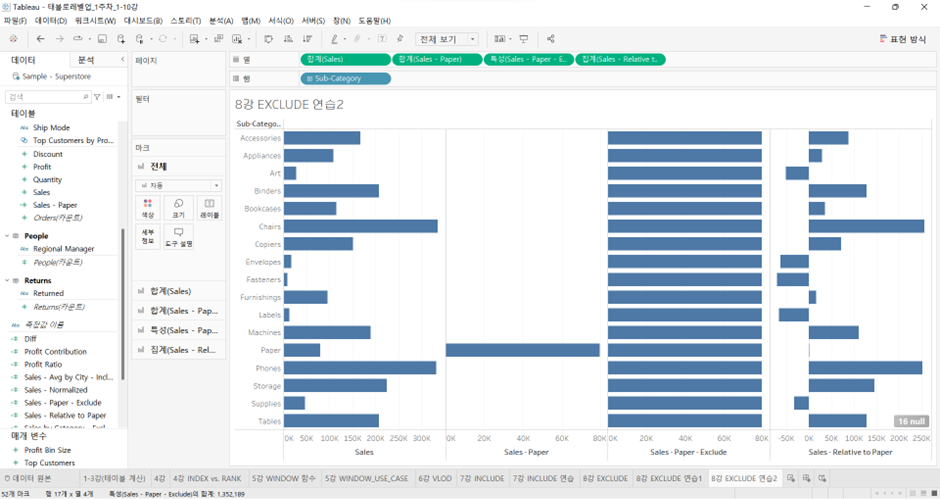
- 앞의 계산된 필드 2개를 다 제외
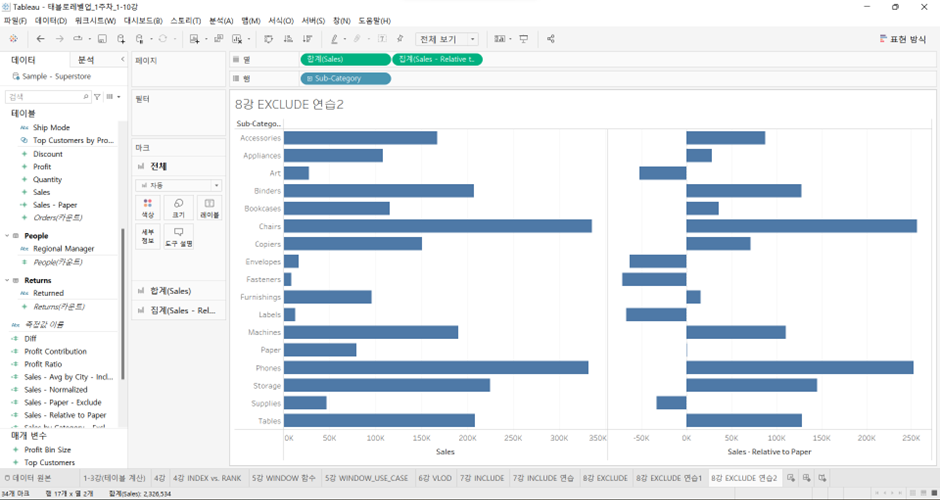
- 왼쪽으로 튀어나왔으면 Paper보다 매출 금액이 낮은 항목, 오른쪽에는 Paper보다 매출 금액이 높은 항목
활용하는 상황
- 차원 A에 대한 하부 차원 B의 기여도를 정규화할 때
- e.g., 차원 State에 대한 하부 차원 City의 기여도를 정규화
- 특정 차원에 대한 하나의 값을 동일한 차원의 다른 값과 상대 비교할 때
- e.g., Paper와 다른 서브 카테고리 항목들의 매출 비교
Include와 Exclude LOD는 활용도가 높지 않음. 왜?
- 대부분의 Include와 Exclude는 Fixed로 대체 가능한데, Fixed가 훨씬 사용하기 편리하다.
- “유연성(Flexibility)”
- 화면의 구성 (In & Ex는 VLOD에 연계된 개념이기 때문에 덜 유연 – Fixed는 내가 원하는 특정 차원으로 화면을 고정시키는 것으로, View 고려할 필요 없기 때문에 더 유연)
- 계산 결과의 종류 (In & Ex는 항상 결과값이 측정값 – Fixed는 측정값도 나오고 차원도 됨. 대표적으로 날짜 데이터 ‘최근 1개월’/’최근 1주’)
- 작동의 순서 (In & Ex는 Dimension 필터 적용 이후 계산이 일어남 = 항상 Dimension 필터의 영향을 받음 – Fixed는 Dimension 필터의 영향을 받지 않고, Dimension 필터 Context 필터로 만들어줄 경우 제어 가능)
9강 LOD 표현식 ④ FIXED LOD 표현식
Fixed
Case 1: Fixed LOD에서 선언한 차원이 VLOD에 포함되어 있을 때
Case 2: Fixed LOD에서 선언한 차원이 VLOD에 포함되어 있지 않을 때
Case 1 Fixed LOD에서 선언한 차원이 VLOD에 포함되어 있을 때
예시1
VLOD = FIXED LOD at Sub-Category 레벨
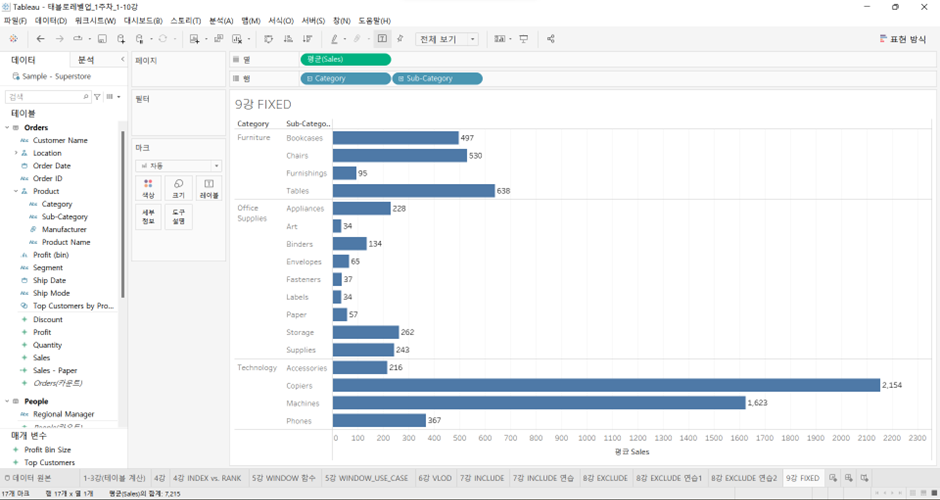
- 이 화면에 FIXED LOD를 집어넣는다.
이름: Sales - Avg. by Sub-Category - Fixed
식: { Fixed [Sub-Category] : AVG([Sales]) }-
Fixed LOD 안에 서브 카테고리 레벨에서 집계가 선언되고 있고, VLOD 안에 서브 카테고리가 포함되어 있다. 위의 Fixed LOD를 화면 안으로 집어넣게 된다면?
-
뒷단에서는 먼저 Sub-Category 레벨에서의
AVG([Sales])계산이 일어날 것이고, 여기에서 태블로가 작동하는 방식은 Include 또는 Exclude 둘 중 하나임. (아래와 같이)
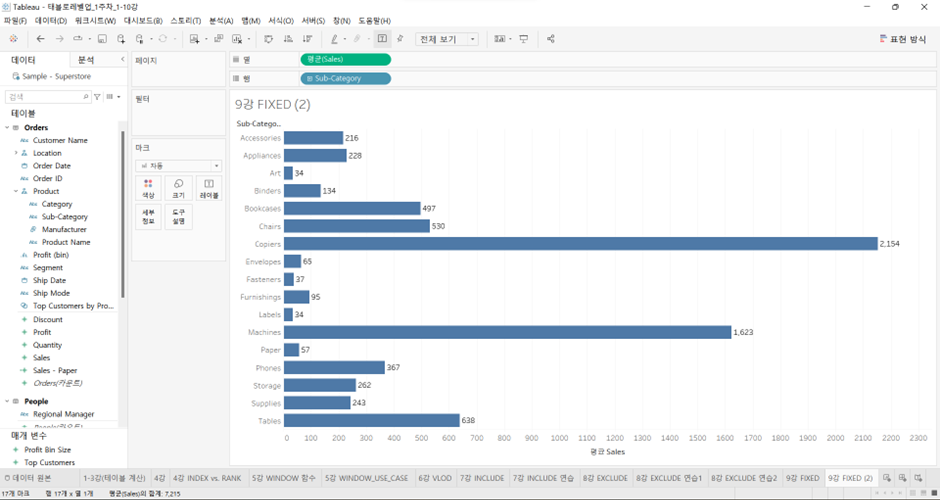
-
그리고 VLOD가 현재 Sub-Category 레벨이고 Fixed LOD에서 만들어진 레벨이 Sub-Category 레벨과 같음. 따라서 2차 집계 어떻게 하든지 상관 없이 Sub-Category 레벨로 나온다. Include 방식으로 재집계할 필요도, Exclude 방식으로 복제할 필요도 없다. 그래서 보고 있는 위의 화면이 그대로 나오고, 1차 계산 뒤 2차 계산이 일어나지 않는다.
(아래와 같음)
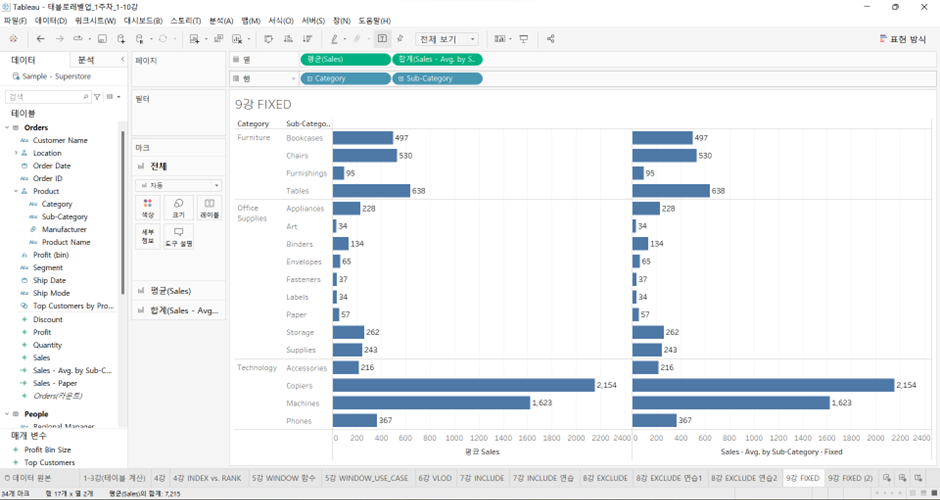
-
두번째 집계를 합계로 하든, 평균으로 하든, 최댓값으로 하든, 최솟값으로 하든 상관없이 1차로 Fixed LOD 안에서 집계된 레벨이 지금 화면의 VLOD와 같기 때문에, 2차 집계는 어떤 방식으로 하든 관계없이 VLOD, 그리고 Fixed LOD 안에서 선언되었던 레벨로 나오게 된다.
따라서Sales - Avg.by Sub-Category - Fixed의 두번째 집계를합계로 설정했음에도 불구하고Sales의 평균과 같은 그래프가 도출된다.
예시2
VLOD, deeper than Fixed LOD
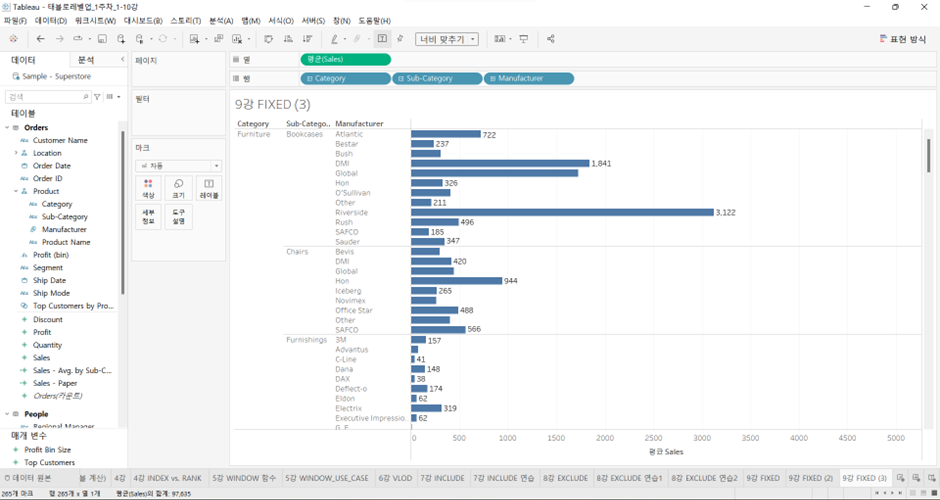
-
아까의 Sub-Category 레벨에서 한단계 더 내려간 제조사 레벨 (밑의 검은색 화면의 왼쪽 그래프)
VLOD는 Manufacturer 레벨까지 내려감.
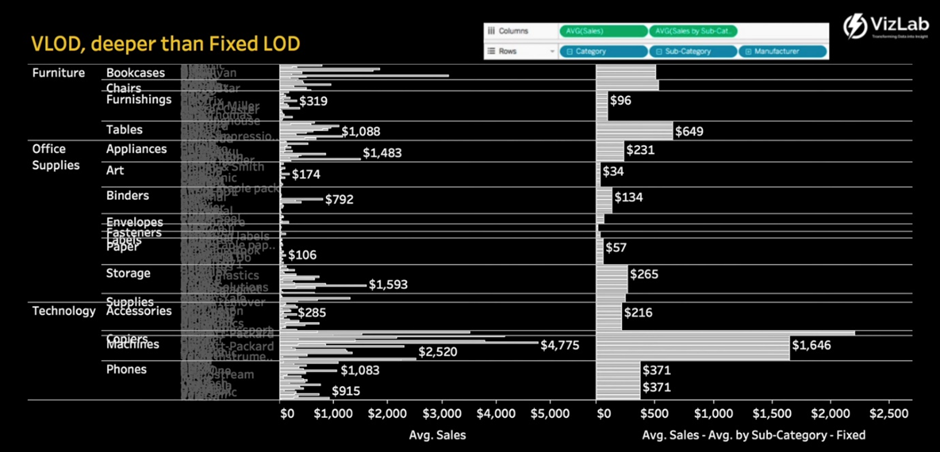
-
태블로 뒷단에서 일어난 (1차 집계) 결과는 아까 본 9강 FIXED (2) 그래프와 똑같이 Sub-Category 레벨에서 평균 Sales를 집계. 그러나 아까와 달리 VLOD가 현재 Fixed LOD 안에서 선언된 레벨보다 더 깊은 수준이다.
-
(아까 만든 Fixed LOD 표현식을 올리면,)
따라서 제조사 레벨과 상관없이, Sub-Category 레벨에서 계산된 평균 매출 금액이 오른쪽에 복제되어 나오는 것
-
복제되는 이유는 Exclude와 같음. VLOD와 맞추기 위해서.
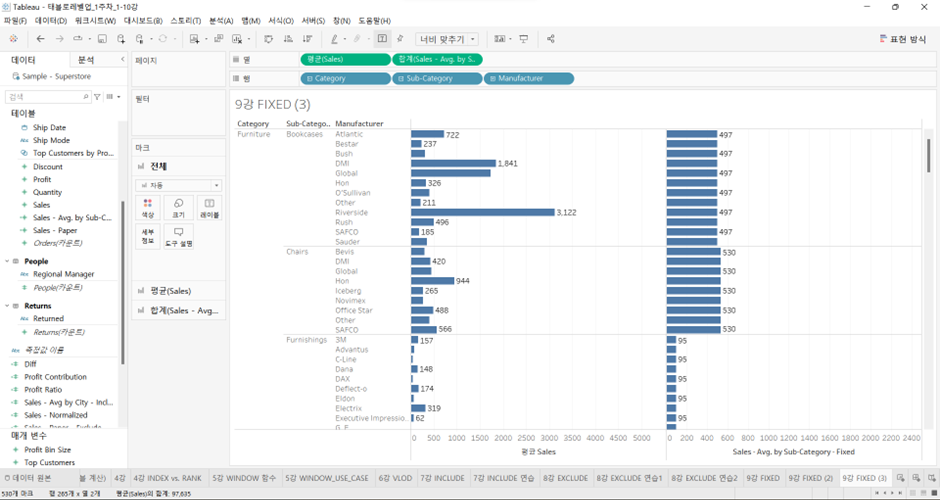
핵심 정리 - Case 1. Fixed LOD에서 선언한 차원이 VLOD에 포함되어 있을 때
- VLOD와 Fixed LOD의 DEPTH가 같을 때: 1차 집계 결과가 그대로 표현 (-> 굳이 LOD 표현식을 사용할 필요가 없음)
- VLOD가 Fixed LOD보다 더 깊을 때: 1차 집계 결과를 VLOD에 맞추기 위해 복제 (-> Exclude처럼)
Case 2 Fixed LOD에서 선언한 차원이 VLOD에 포함되어 있지 않을 때
예시 3
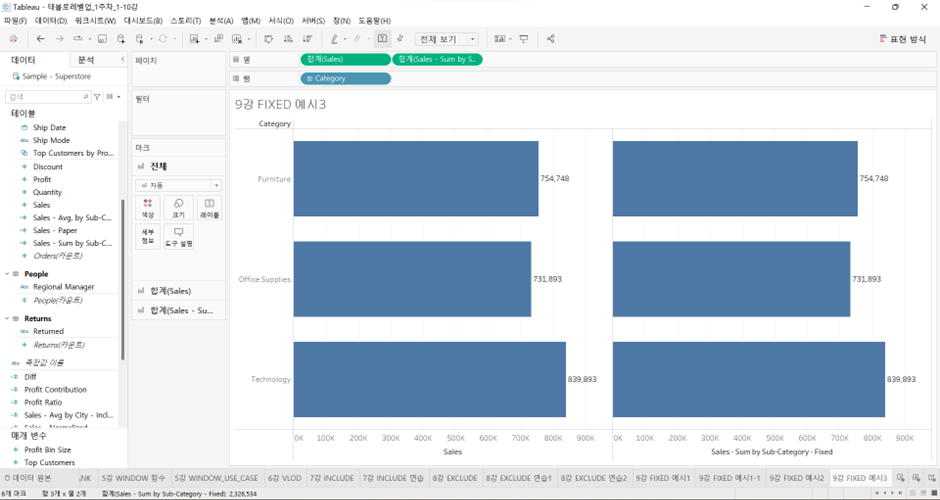
왼쪽은 단순히 매출 합계를 카테고리별로 올린 것이고, 오른쪽은 서브 카테고리 레벨에서 집계된 매출 합계를 Fixed LOD로 만들어서 화면 안에 집어넣은 것. 둘의 결과는 똑같이 나온다.
Fixed LOD
이름: # Sales - Sum by Sub-Category - Fixed
식: { FIXED [Sub-Category] : SUM([Sales]) }왜 Sub-Category 레벨에서 합산했는데 Category 레벨에서 결과가 나오는 것일까?
-
Include의 경우의 원리를 생각해 보면 동일하게 적용 가능
-
위 Fixed LOD 표현식에서 태블로 뒷단에서는 다음과 같은 계산을 수행한다.
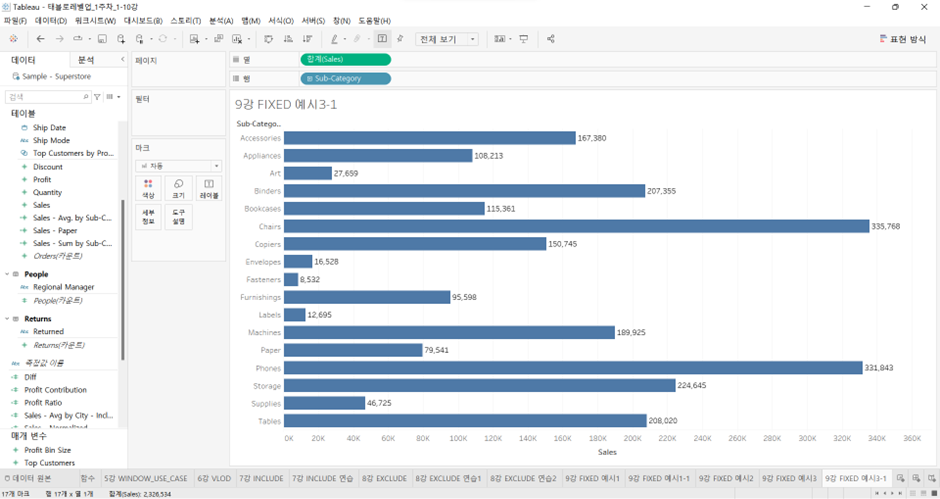
Fixed LOD 안에서 정의된 레벨은 Sub-Category 레벨이고, 현재 VLOD에서 정의된 레벨은 보다 한 단계 높은 Category 레벨이기 때문에 VLOD에서 표현하기 위해 재집계가 이루어지고, 이것이 ‘합계’였기 때문에 동일한 그래프가 도출된 것이다.
예시 4 – 평균으로 도출
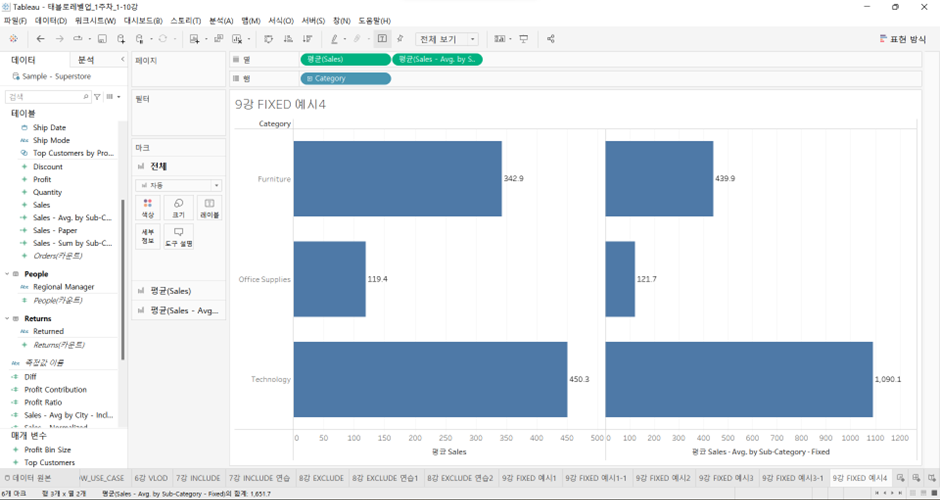
- 왼쪽은 Sales를 카테고리 레벨에서 평균으로 단순히 집계한 금액이고, 오른쪽은 서브 카테고리 레벨에서 평균 매출을 집계한 이후에 화면으로 Fixed LOD를 집어넣은 것이다.
- 1차적으로 Fixed 안에서 선언한 Sub-Category 레벨에서 평균으로 집계가 이루어지고, 거기서 만들어진 레벨이 지금 화면에서 보이는 VLOD인 Category보다 더 깊기 때문에, depth가 더 얕은 VLOD로 표현되기 위해서 재집계가 이루어진다. (-> Include의 작동 방식과 완전히 동일)
예시 5
City 레벨에서 Sales 평균 본 후에
이름: Sales - Avg. by Sub-Category - Fixed
식: { Fixed [Sub-Category] : AVG([Sales]) }위의 Sub-Category 레벨에서 평균 Sales가 집계된 Fixed LOD를 화면 안으로 집어 넣으면
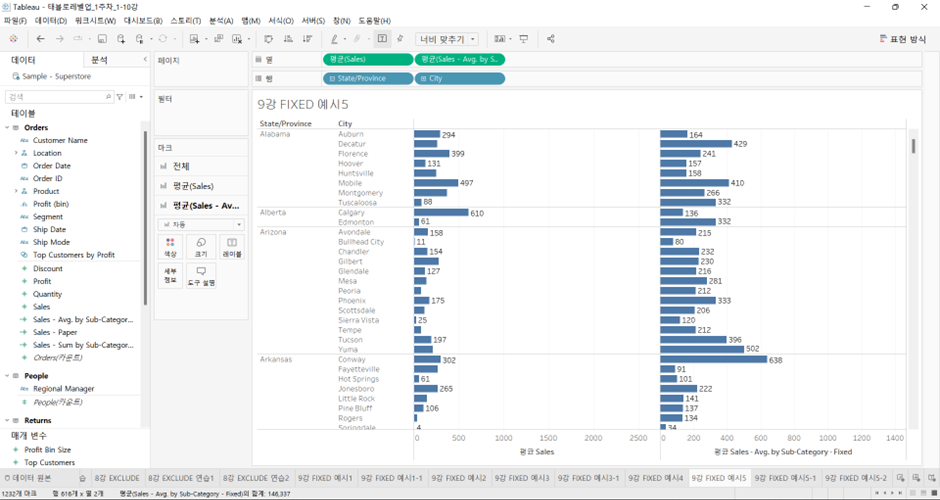
이렇게 나옴.
- 일차적으로 Fixed LOD 안에서 선언된 레벨에서의 계산 Sub-Category에서 평균 Sales가 집계된 계산이 1차적으로 일어나게 됨.
- 그 다음으로 Fixed LOD 안에서 선언된 차원(Sub-Category)가 포함된 화면에서, 태블로는 측정값의 존재 유무를 확인한다.
- e.g., Alabama 주의 Auburn이라는 도시에서는 17개의 Sub-Category 항목 중에서 Art, Chairs, Envelopes, Labels, Paper, Storage 6개의 항목에 대해서만 Sub-Category 값을 가짐.
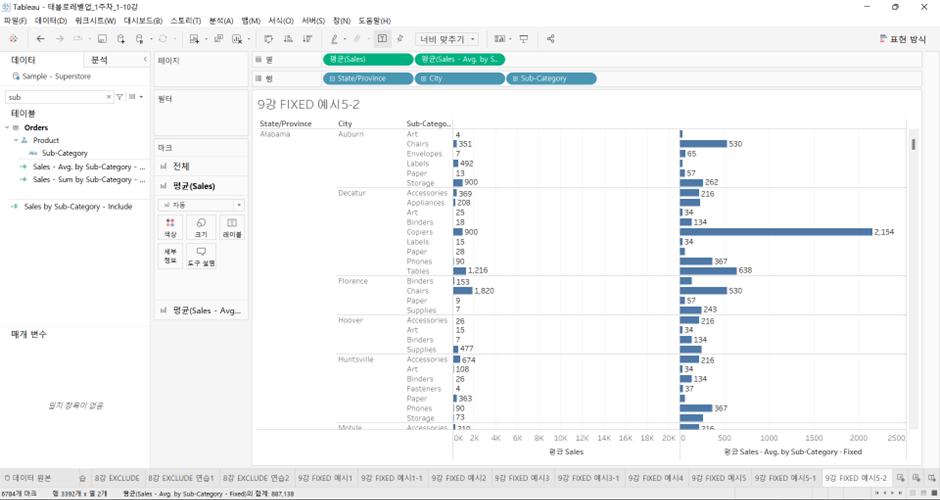
따라서 Auburn이라는 도시는 이 6개 항목의 1차 계산 결과에 대해서만 2차 계산(평균)을 수행하게 된다.
따라서 총 6가지의 항목들의 평균의 합계가 987이고, 이를 6으로 나누면 위에서 본 164라는 결괏값이 도출된다.
핵심
• Fixed LOD에서 선언한 차원과 집계 방식에 따라 1차 집계가 이루어짐
• Fixed LOD에서 선언된 차원(Sub-Category)을 포함하는 레벨에서 측정값(Sales)가 존재하는지 스캔
• 해당 측정값이 존재하는 항목에 대해서만 1차 집계값을 가지고 옴. (이 모든 과정은 눈에 보이지 않음)
• VLOD에서는 존재하는 1차 집계값에 대해서만 재집계하여 화면에 표현
예시 6 (연습문제)
각 지역(Region)별로 수익을 낸 주문과 손실을 낸 주문의 매출 비중을 구해보세요.
- 열은 합계(Sales), 행은 Region
- 합계(Sales) → 퀵 테이블 계산 → 구성 비율
- 합계(Sales) → 다음을 사용하여 계산 → 테이블(옆으로)
(각 지역마다 100%로 만들어줌) - 주문별로 수익을 냈는지, 못 냈는지 확인하는데 Fixed LOD를 쓰면 됨. 5번의 Fixed LOD를 계산된 필드에 만들어서 색상에 넣어주면, 수익을 발생시킨 주문과 손실을 난 주문이 주황색과 푸른색으로 나누어져 표현된다.
- Fixed LOD
이름: Profitable Order
식: { FIXED [Order ID] : SUM([Profit]) > 0 }- Fixed는 지금 VLOD가 Region에서 이루어지고 있는데 이것과는 전혀 상관없는 새로운 차원인 Order ID별로 무엇인가를 계산해서 현재의 VLOD와는 전혀 상관없는 차원으로 화면을 만들 수 있음.
활용
(1) 전체 데이터셋 범위에서 집계값을 잡을 때
이름: Sales – Total
식: { SUM([Sales]) }- 어떤 레벨로 분류를 해도 값이 전체 금액(Sales)에서 바뀌지 않고, = 데이터셋 전체의 범위에서 Sales의 합계가 잡혀있고, 어떠한 차원에 의해서도 쪼개질 수 없다.
(2) 날짜 필드를 활용할 때 ex. 최근 3개월, 올해, 지난 주 등
이름: Recent Year
식: { MAX(YEAR([Order Date])) }- MAX로 집계하면 가장 최근 값이 나오게 됨. MAX로 안 감싸주면 집계값 안 나옴.
- 지난해는 어떻게 만들 수 있나?
이름: Last Year
식: [Recent Year] – 1- 작년, 올해는 상대적 개념이어서 계속 바뀜. Fixed LOD로 계산을 만들어 놓으면 계산 가능
(3) 필터의 영향을 받지 않는 값을 만들어야 할 때
- Dimension 필터의 영향 받지 X (위의 내용 참고)
이 외에도 수도 없이 많다!
10강 LOD Expressions ⑤ LOD 표현식 vs 테이블 계산식
평균 라인
- 분석 탭의 평균 라인 집어넣기를 통해서 Include LOD 또는 Exclude LOD와 같은 결과물들을 만들어낼 수 있다.
- 평균 라인이 테이블 계산식이 작동되는 방법과 완전히 동일
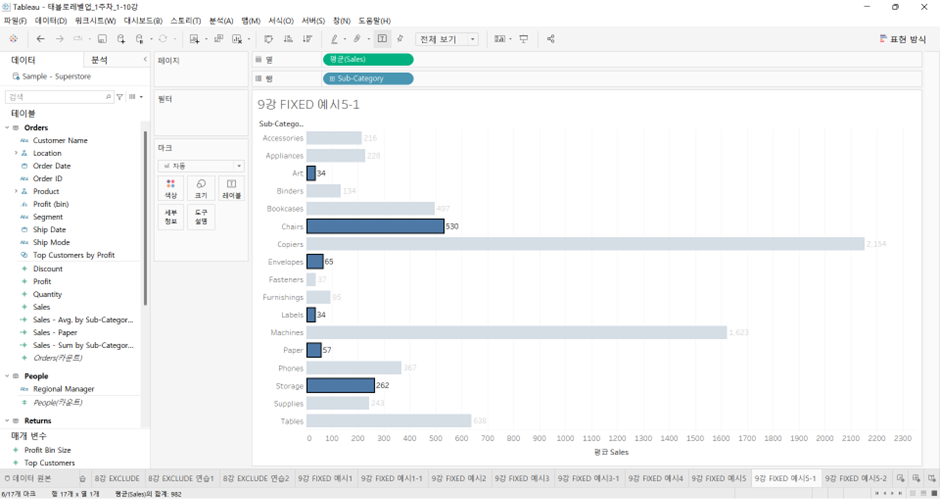
- 분석 탭 > 평균 라인 > 패널 > 평균 440이라는 값이 나옴. 이 숫자는 어떻게 나왔는가?
Furniture의 4개 Sub-Category의 평균끼리 평균 낸 값이 440- Include LOD가 작동하는 방식과 동일하다. 1차적으로 서브 카테고리 레벨에서 평균 Sales가 계산되고, 화면에서 표현되기 위해 패널별로 평균이 다시 한번 계산된다. 즉, 서브 카테고리 레벨이 고려된 가중 평균이다.
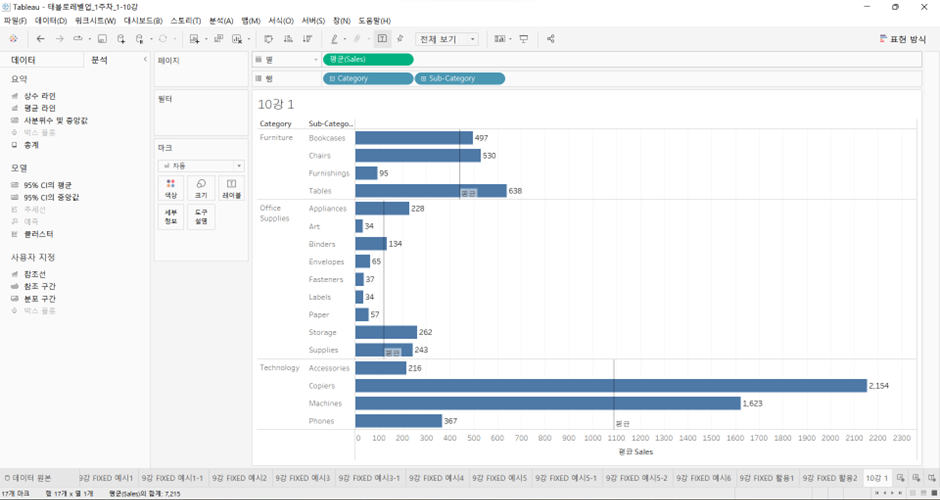
- 평균 라인 > 값 두번째를 총계로 바꾸면,
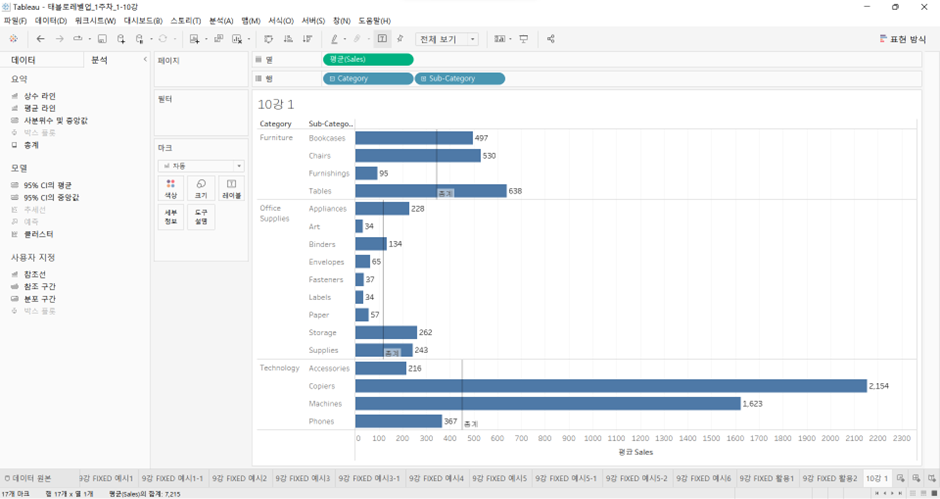
- Exclude LOD가 작동하는 방식과 동일하다.
- 서브 카테고리 레벨과 관계없이 Category레벨에서 모든 매출의 합계를 더하고, 그 카테고리 레벨에 있는 데이터 행의 개수로 나눠준다.
예시
각 서브 카테고리의 평균 매출이 자기 자신이 속한 카테고리의 평균 매출과 얼마만큼 차이가 나고 있는지 표현해보세요.
- 각 Sub-Category별 평균 매출을 만들어 준다.
- 위의 항목을 만들기 위해서, 카테고리는 3가지 항목이 있음. VLOD에 없는 Category의 평균 매출 금액을 구해야 되기 때문에, Fixed LOD 표현식을 이용해야 한다. (이 화면에서는 패널X, 테이블과 셀만이 존재)
- 카테고리의 평균 매출 Fixed LOD
이름: Sales - by Category – Fixed
식: { FIXED [Category] : AVG([Sales]) }이름: Difference
식: AVG([Sales]) - AVG([Sales - by Category - Fixed])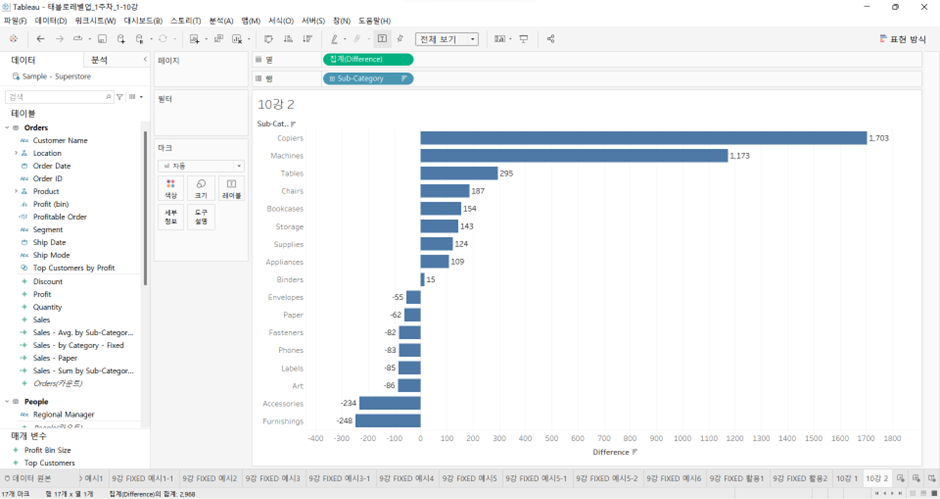
- 위 그래프와 같이 각 서브 카테고리의 평균 매출과 자신이 속한 카테고리의 평균 매출의 차이를 표현할 수 있다.
- 테이블 계산식은 화면의 특정한 조건에 따라서 계산이 되는 것이기 때문에, 화면 안에 없는 필드에 대해서는 계산이 불가능하다.
핵심
- 테이블 계산식 대비 LOD 표현식의 강점은 유연성이다. 참조선(테이블 계산식)은 VLOD에 없는 차원에 대한 계산 결과를 절대로 만들어 낼 수 없다.
참고
