
1강 테이블 계산에 대한 이해
테이블 계산이란?
"Configurable Secondary Calculation"
1. Calculation
- 일반적인 관점에서 + / - / * / ÷의 사칙연산이 태블로에 반영
- 태블로의 관점에서 row level / 집계 / LOD / 테이블 계산과 같은 계산 방법 제공
2. Secondary Calculation
- 첫번째 계산에 '종속되어 나타나는' 계산
→ First-Level Calc는 태블로가 우리에게 보여주는 매직 (막대 그래프, 라인 차트 등의 집계 계산): 데이터를 불러오고 나서 Sales, Profit 같은 측정값을 더블클릭하거나 drag & drop 했을 때 화면 안에 바 차트가 그려짐. 사용자의 동작들을 태블로가 data source가 알 수 있는 query language로 바꾼 후 호출을 받아서 화면에 차트를 그려줌.
Secondary Calc (두번째 계산)에 대한 함의
- 데이터 원본 소스와 무관하다.
- 태블로가 data source가 알 수 있는 query language로 바꿔준다는 것 = data source를 향해 질문을 하고 결과물을 갖고 오는 것. 즉 첫번째 계산은 데이터 원본 소스와 관련O
- 두번째 계산은 첫번째 계산의 결과물에서, 화면 내에서 재계산이 일어나는 것이기 때문에 데이터 원본 소스와 무관
-> 여기에서 나타나는 문제는 테이블 계산이 이해하기 어려움. 테이블 계산은 데이터 원본 소스와 무관하게 화면 내에서 이루어지기 때문에 화면에 들어가 있는 차원의 종류에 따라서 바뀜.
- 작동 우선순위가 비교적 후순위이다.
- 태블로에서는 명령을 줄 때 순서대로 작동 (order of operations)
- Filter 같은 앞선 순위에서 이루어질 수 있는 calculation에 영향을 많이 받음
- 반대로 가장 큰 장점은 편하다는 것. 비즈니스에서 의식의 흐름에 맞음.
i.e. 전체 매출의 몇 %? Table Calculation이 없으면 여러 과정을 거쳐서 만들어내야 하지만 태블로에는 Table Calculation 만을 사용해 답을 도출 가능
3. Configurable Secondary Calculation
- Configurable = 무엇인가(=계산의 범위)를 설정할 수 있다.
- 테이블 계산의 ‘테이블’은 결국은 계산의 범위를 의미하는데, 테이블, 패널, 셀을 포괄하는 의미
테이블= 전체 범위패널= 일부 범위셀= 하나의 특정한 결과물만 찝어서
4. Quick Table Calculation
- Table Calculation의 종류는 매우 많은데, 계산된 필드를 열어서 스크립트를 직접 써줘야 함
- Quick Table Calc는 그 중 비즈니스/일상에서 사용도/빈도가 높은 것들을 모아놓은 패키지
측정값우클릭 >퀵 테이블 계산클릭 >원하는 것클릭
2강 테이블 계산 범위 설정 A
퀵 테이블 계산
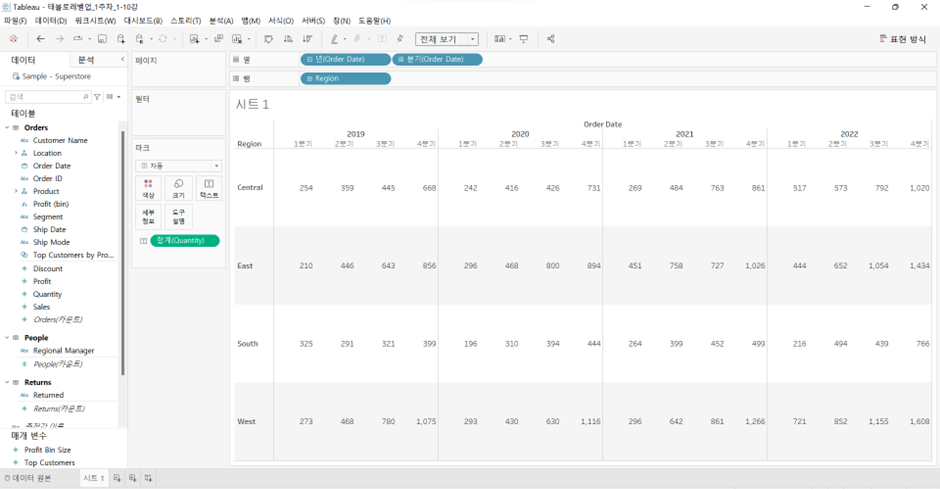
측정값 우클릭 > 퀵 테이블 계산 > 누계
-> Quantity를 다시 화면 안으로 집어넣고 방금 만든 테이블 계산과 비교하면
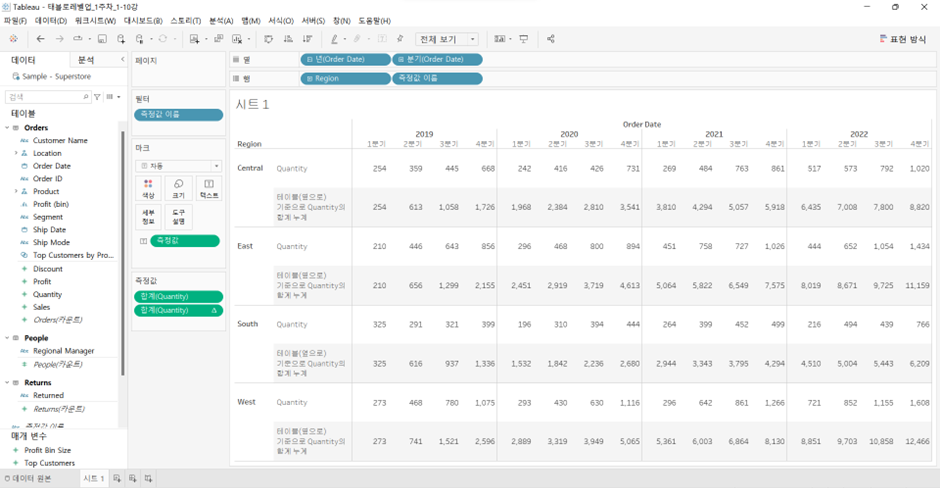
-
Quantity에는 숫자가 그대로 표시, 밑에는테이블(옆으로)기준으로Quantity의 합계 누계 (running sum) -
분석>총계>행 총합계 표시 -
분석>총계>열 총합계 표시 -
분석>총계>모든 소계 추가
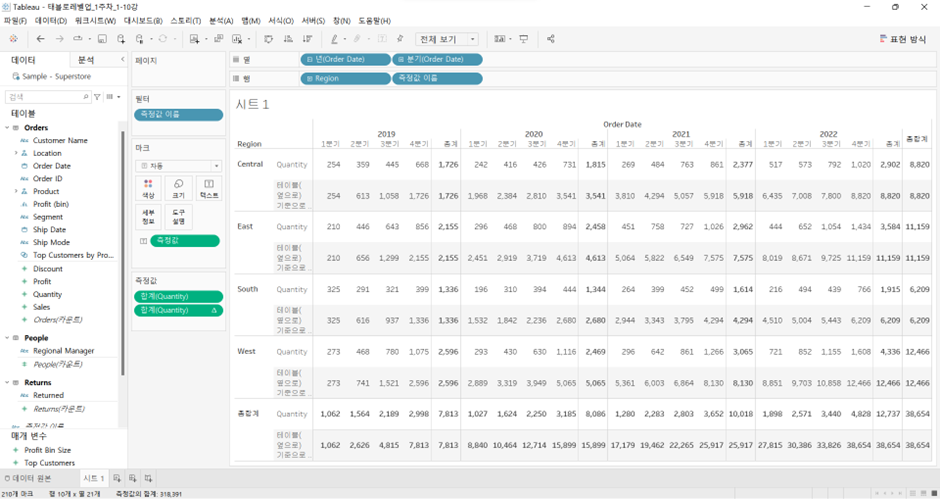
-
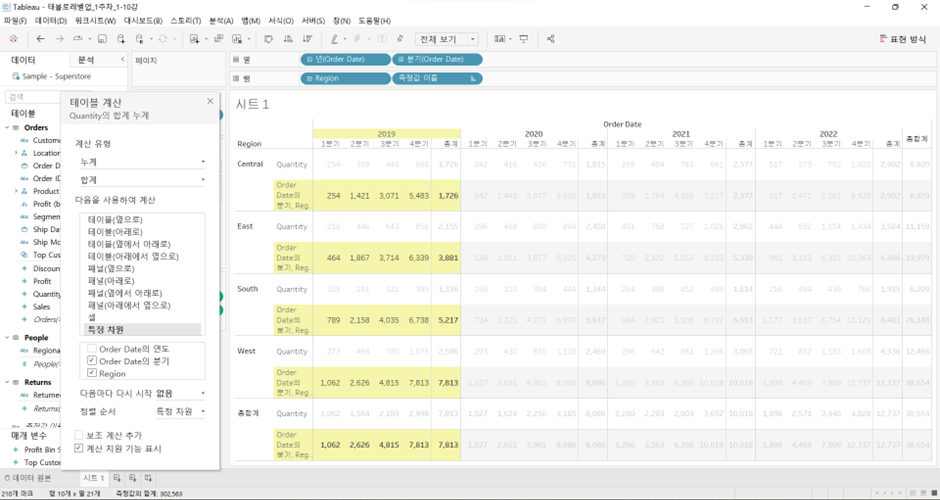
Central의테이블(옆으로)기준으로Quantity의 합계 누계를 보면 ’15 총계에 ’16 Q1 값이 더해져서 우측으로 쭉 가고, ’16 총계에 ’17 Q1 값이 더해져서 우측으로 쭉 가고, 반복하여 ’18 Q4에 도달.
=East는Central의 값을 갖고 가지 X. 각 지역별로Quantity가 누계(running sum)로 계속 더해지고 있는 것을 볼 수 있음. -
테이블 계산 필드 우클릭>테이블 계산 편집하면 Configuration Window가 나타남
계산 유형

부분
1. 계산 유형
2. 다음을 사용하여 계산 -> 계산의 범위(테이블/패널/셀)을 정하는 부분
테이블(옆으로)
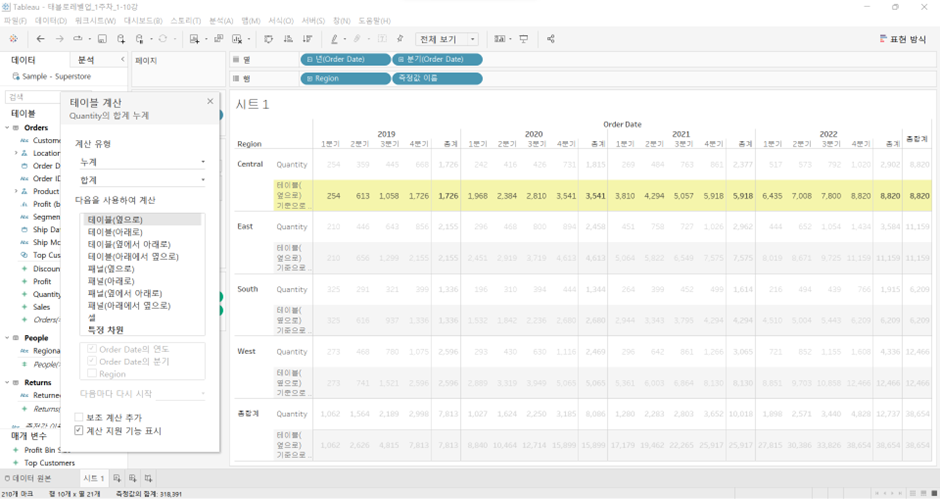
테이블= 전체(처음부터 끝까지),테이블(옆으로)= 옆으로 처음부터 끝까지- 한 Region의 ’15.Q1~’18.Q4 총 4년, 16개 Q의 값이 누적으로 더해져서 총계 반환
- 이 값이 다른 Region에는 영향을 미치지 X. 다른 Region도 똑같이 계산.
테이블(아래로)
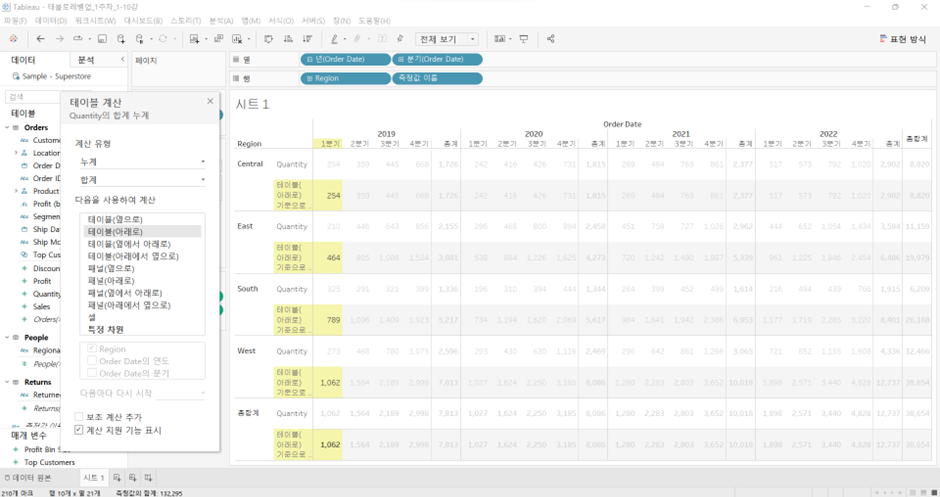
테이블(아래로)= 위에서 아래로 처음부터 끝까지.- 즉 Region끼리 쭉 더하라는 뜻
- 한 Q의 Central + East + South + West
- 이 값이 다른 분기에는 영향을 미치지 X. 다른 분기도 똑같이 계산.
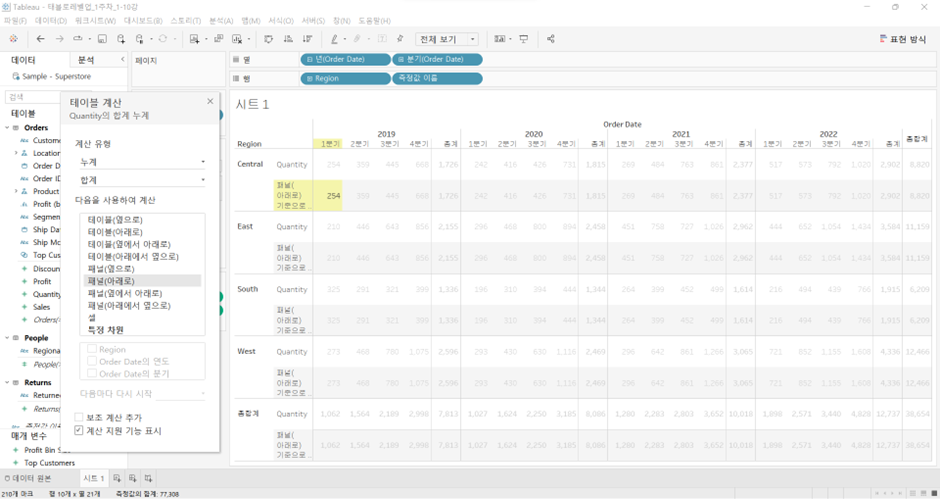
테이블(옆에서 아래로)
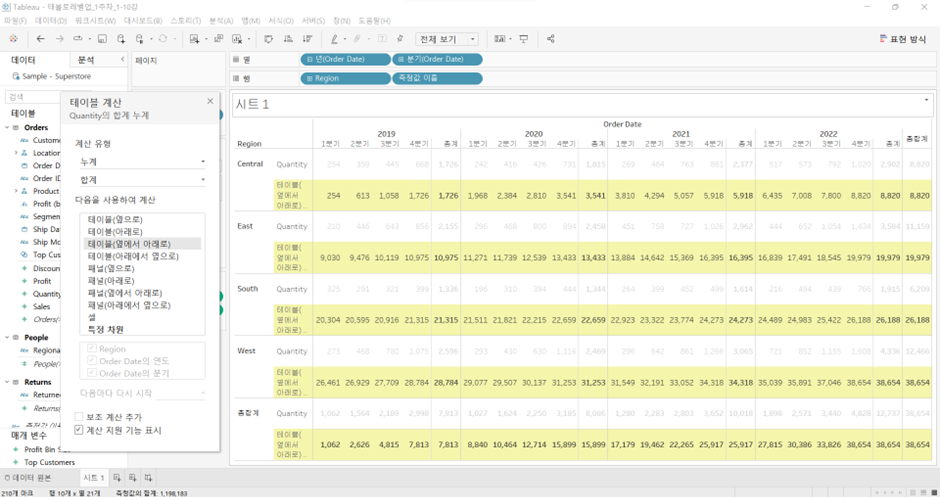
- 먼저 한 Region에서 옆으로 ’15.Q1~’18.Q4 처음부터 끝까지 가서
Central의 총합계를 그대로 받아서 아래로 내려와서 East의 ’15.Q1~’18.Q4 순으로 값들 더함 - 같은 방법으로 South, West
- 이 경우 West의 총합계 값은 모든 dataset의 총합
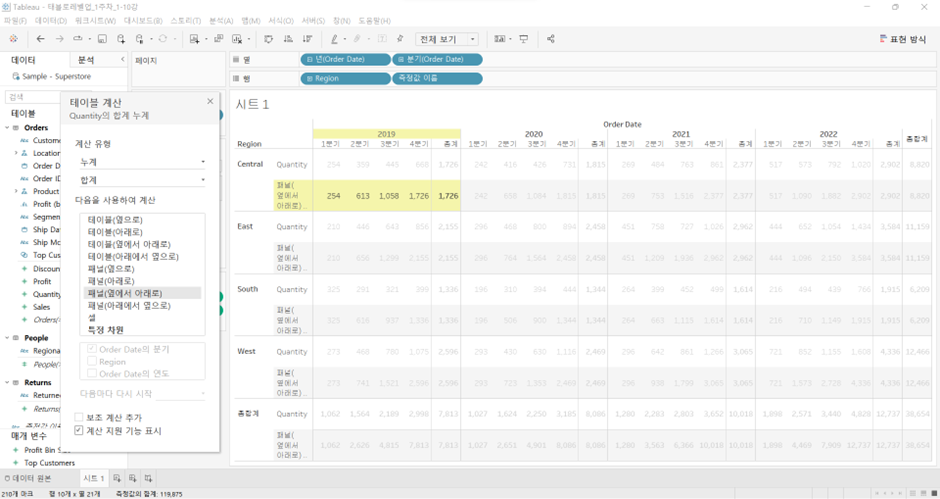
테이블(아래에서 옆으로)
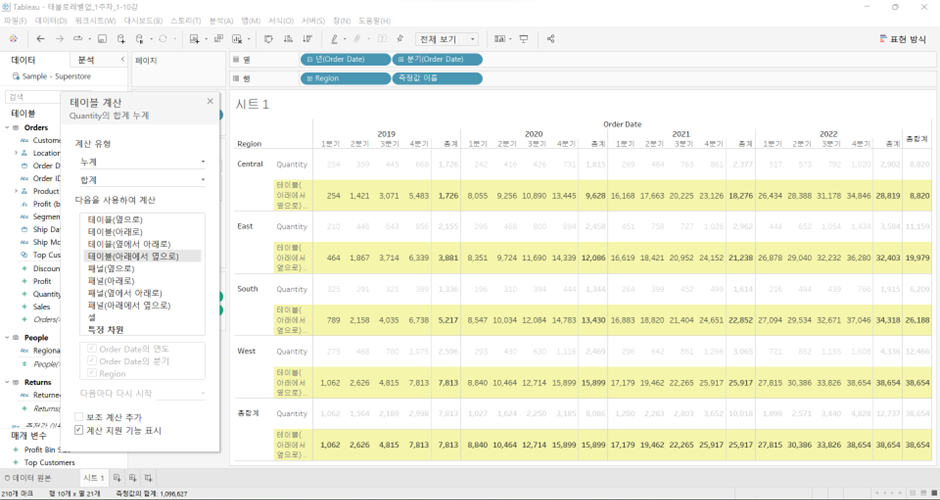
- 테이블(옆에서 아래로)와 결과는 똑같은데 계산되는 방식이 바뀜
- ’15.Q1에서 아래로 쭉 내려온 이후에 (West까지) 총합계를 그대로 받아서 옆 칸(’15.Q2) 위로 올라가서 값들 더하면서 아래로 쭉 내려옴
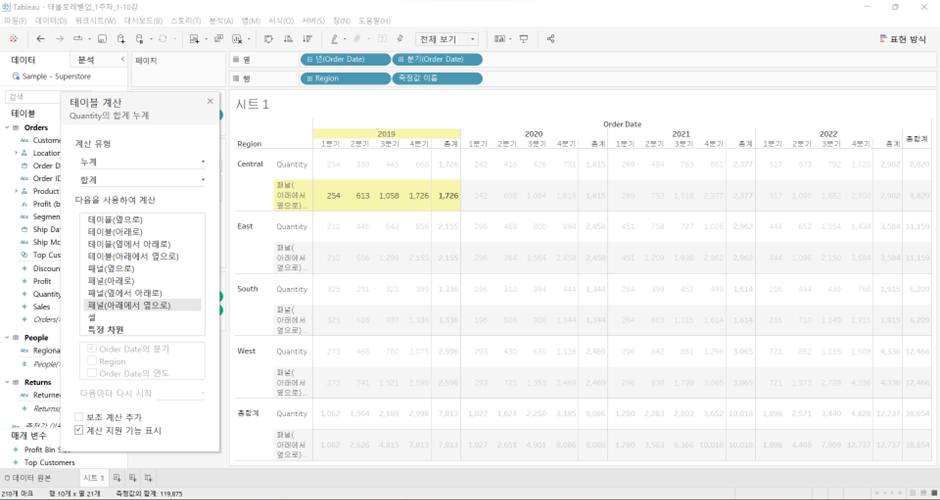
패널
셀단위 바로 위의 것- 현재 뷰에서는
셀=분기로 잡혀 있기 때문에패널=연도
패널(옆으로)
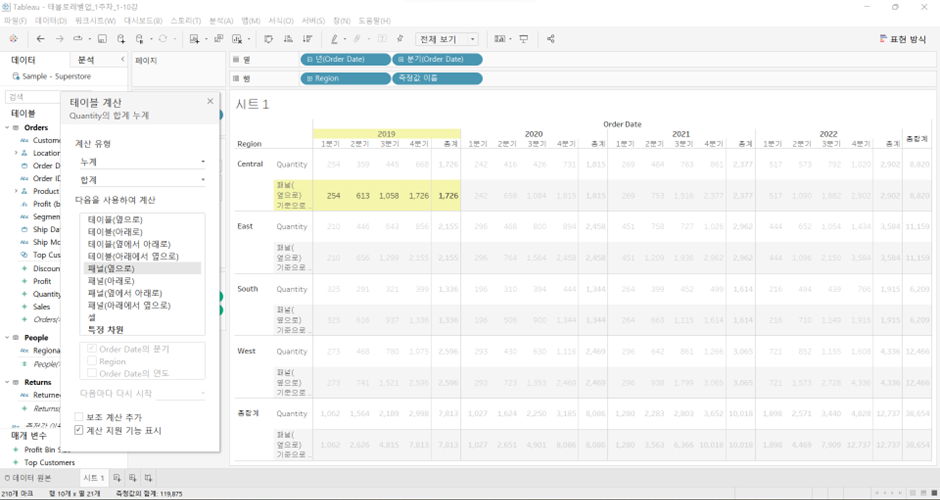
- ‘15년도의 Q1~Q4 값을 누적해서 더하고, 옆 패널(‘16년도)로 넘어갈 경우 ’16.Q1이 다시 시작
패널(아래로)
패널(옆에서 아래로)
패널(아래에서 옆으로)
셀
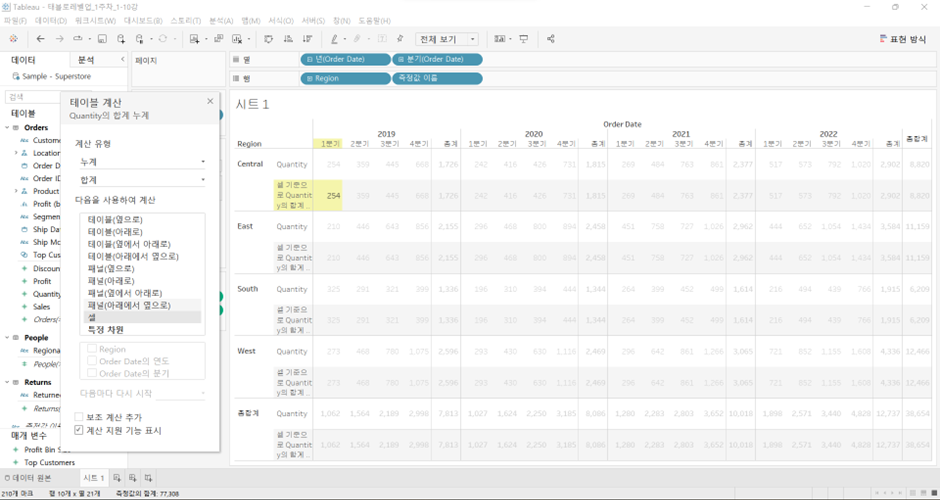
- 하나의 값(Central ’15.Q1)에 대해 누계 합계 구하는 것
- 사실상
셀차원의 테이블 계산은 큰 의미가 없음. 자기 자신에 대해서만 누계를 구하면 결과 값은 자기 자신 → Quantity = 누계 테이블 계산
특정 차원 (쓰는 것 권장)
테이블(옆으로),패널(옆으로)는 화면에서 열과 행 선반에 잡혀 있는 위치를 기반으로 테이블 계산 수행.- 예를 들어
분기를 행 선반으로 옮기는 순간 계산 결과가 완전히 얽힘. ‘옆으로’, ‘아래로’는 상대적인 개념이기 때문. 패널(옆으로)를 클릭한 상태에서 변화를 주면서도패널(옆으로)를 계속 유지하고 싶다면특정 차원을 클릭해 고정
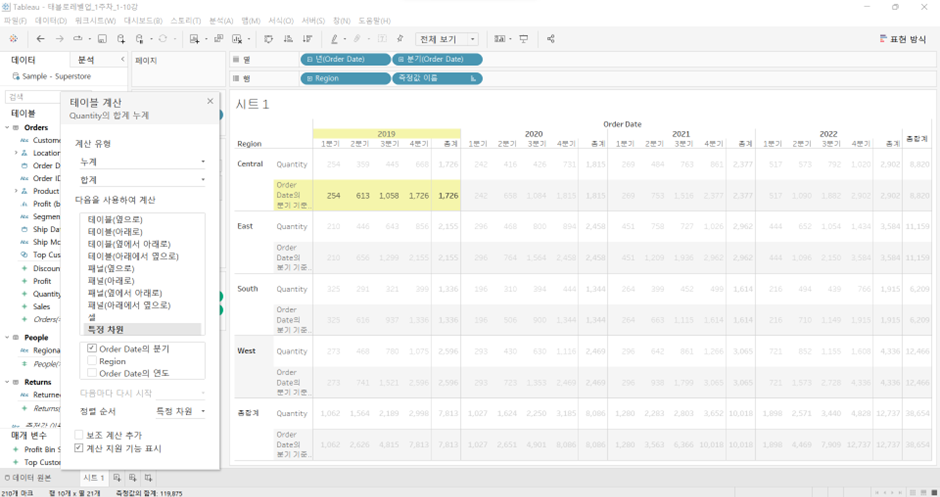
- 예를 들어
- 체크박스
- 계산 지원 기능 표시: 노란색 하이라이트
3강 테이블 계산 범위 설정 B
“특정 차원” 공식
각 A와 B별로: A와 B의 체크박스 비움,
C와 D에 대해서: C와 D의 체크박스 선택
-
~별로 = 누계가 해당 범위를 넘어서 이월되면 안됨
-
“특정 차원” 선택했을 때 나타나는 체크박스:
-
1,726 = 각 지역별, 연도별로 Quarter에 대한 누적합계
- 체크박스 中 ‘지역별’ (
Region), ‘연도별’ (Order Date의 연도) -> 체크 해제 - ‘Quarter’ (
Order Date의 분기) -> 체크 O
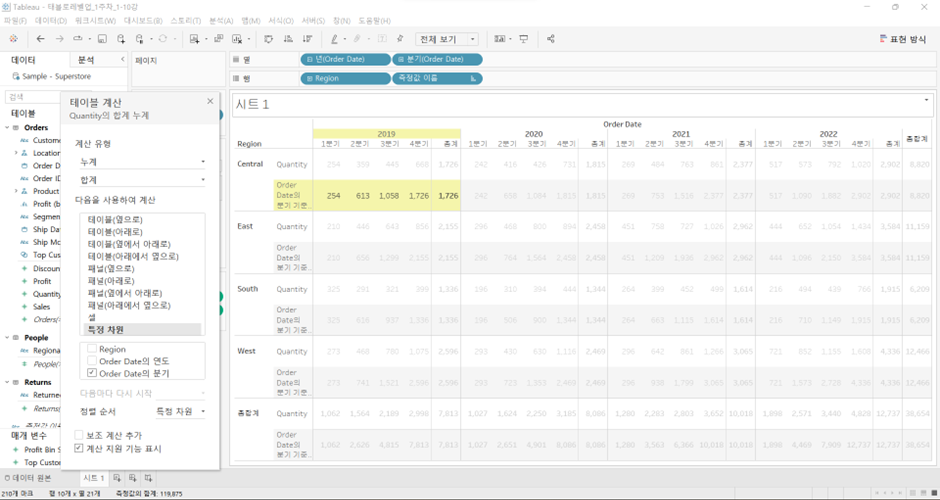
- 체크박스 中 ‘지역별’ (
-
테이블(아래로) ->
Region만 체크박스 선택
= 각 연도별, 분기별로 지역에 대한 누적합계
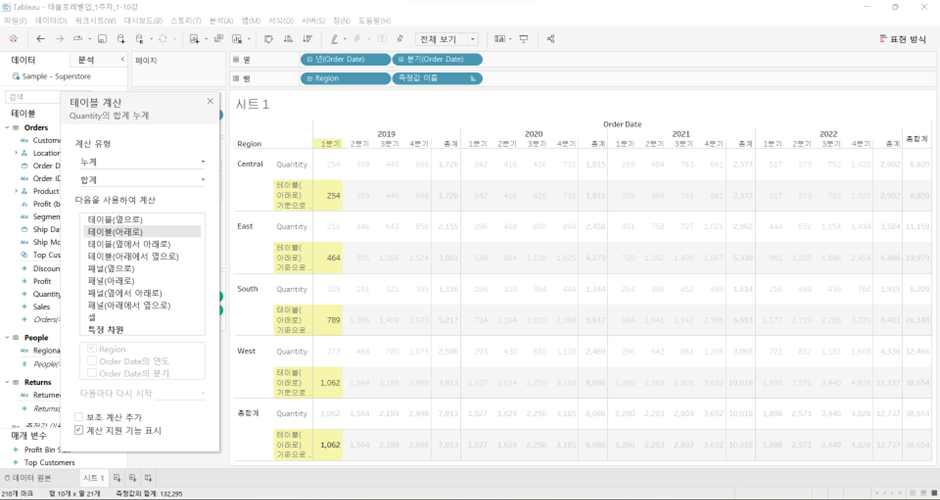
-
각 연도별로 분기(옆쪽)와 지역(아래쪽)에 대해서 누적합계
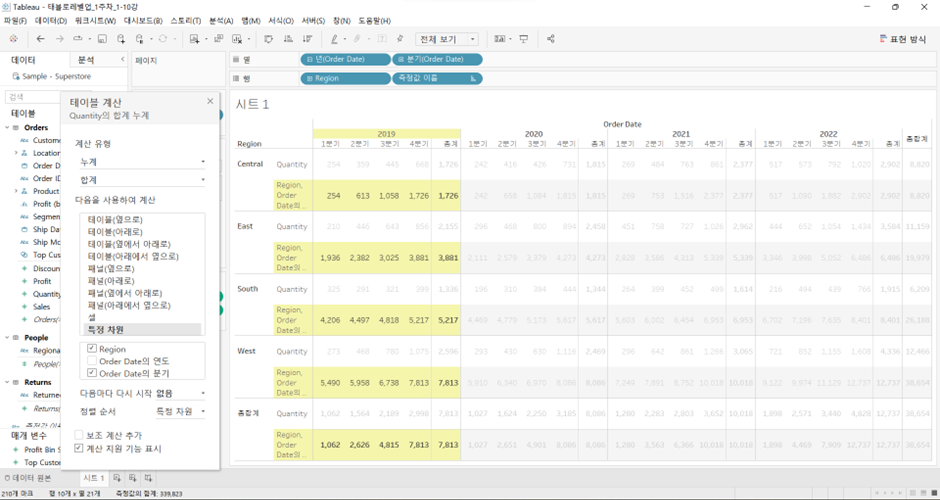
- 옆으로 분기를 더하는 방식으로 계산이 먼저 이루어졌고 그 값을 아래의 다른 지역이 받아서 다시 한번 분기를 더해가는 방식으로 계산이 이루어 짐.
- 이렇게 계산이 이루어지는 이유는 선택 박스 內 Region과 분기 중, Region이 분기보다 위에 있기 때문. 특정 차원을 선택할 때는 차원들의 순서가 중요해짐 (순서는 선택 박스 내에서 움직일 수 있음). 위쪽에 위치한 차원값 하나 하나에 대해서 아래쪽에 위치한 차원값이 순서대로 계산됨.
-
위의 예시에서 Region을 맨 밑으로 이동시킬 경우:
- 밑으로 먼저 내려가고 (= 분기 안에서 먼저 계산) 그 다음에 그 값을 받아서 옆으로 감 (= 지역들을 계산)
4강 테이블 계산 주요 함수 – INDEX, SIZE, RANK, and TOTAL
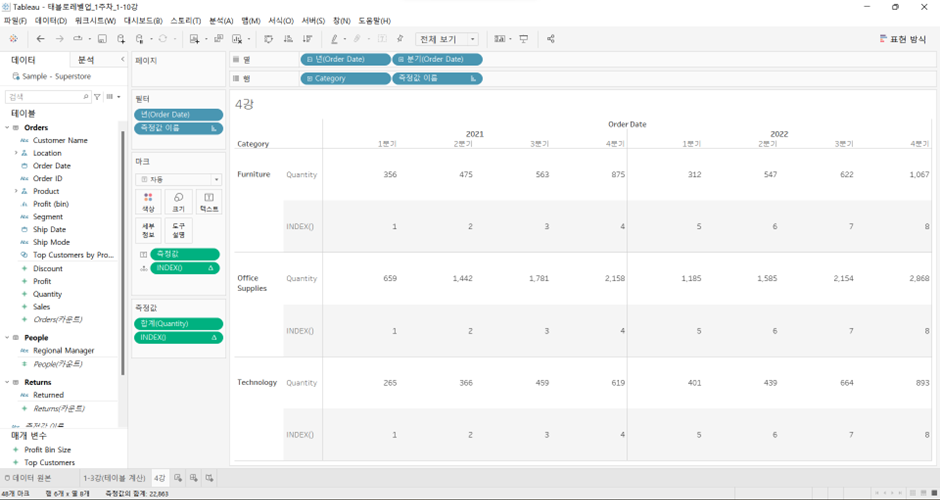
(1) INDEX(): 위치에 따라 줄을 세운다
- 계산된 필드 아니라 마크에서 알약 직접 만들기
- 위치의 범위를 어디까지 정할 것인가?
테이블(옆으로)= 각 카테고리별로 연도와 분기에 대해서 인덱스를 매겨라테이블(아래로)= 각 연도와 분기 별로 카테고리에 대해서 인덱스를 매겨라
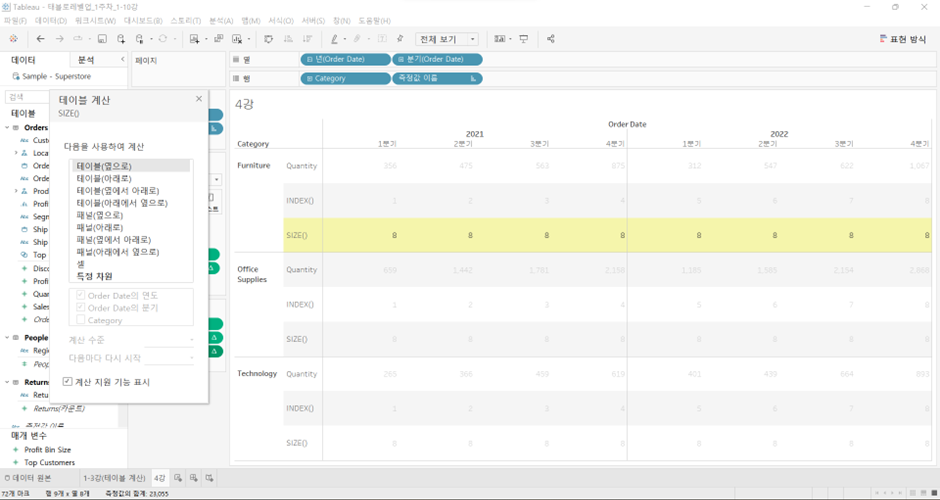
(2) SIZE(): 그 줄의 제일 끝 번호
- INDEX와 SIZE가 동일한 방식으로 테이블 계산이 configure되어 있을 경우 index의 제일 끝 값이 모든 셀에 대해 채워진다
- 각 카테고리별로 연도와 분기에 대해서 사이즈
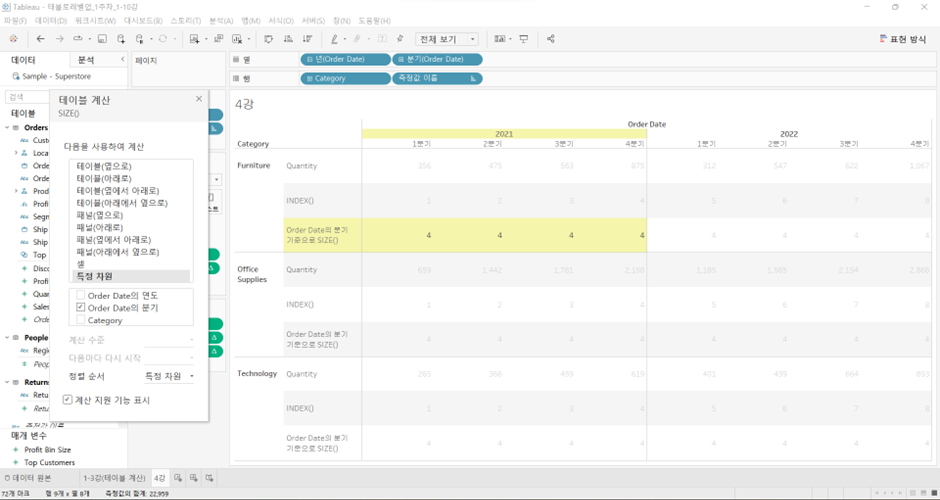
- 각 카테고리와 연도별로 분기에 대해서 사이즈
(3) RANK([Aggregated Calc(집계된 계산)]): Aggregated Calc에 따라 줄을 세운다
RANK(SUM(Quantity))
- Default 값: 각 카테고리별
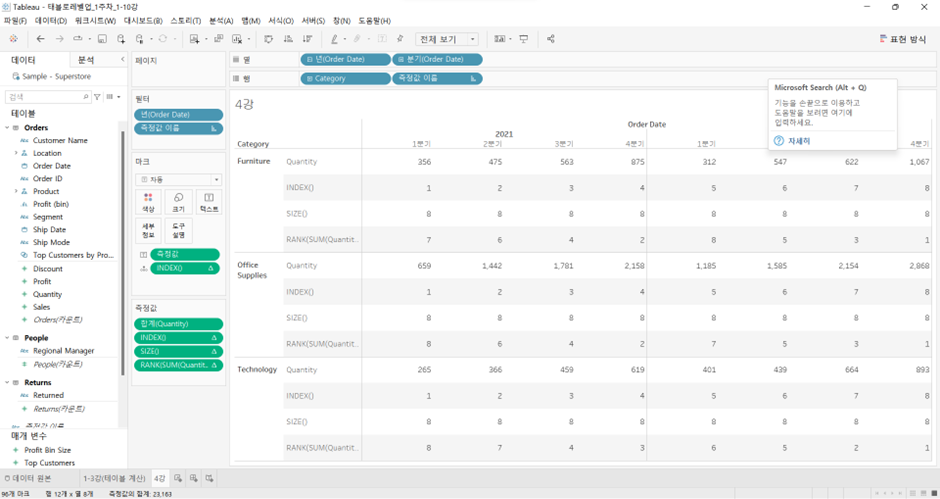
- 이것 역시 테이블 계산으로 범위 조정 가능
예를 들어 테이블(옆에서 아래로) 선택할 경우 전체를 기준으로 Rank 매겨짐 (1-24위)
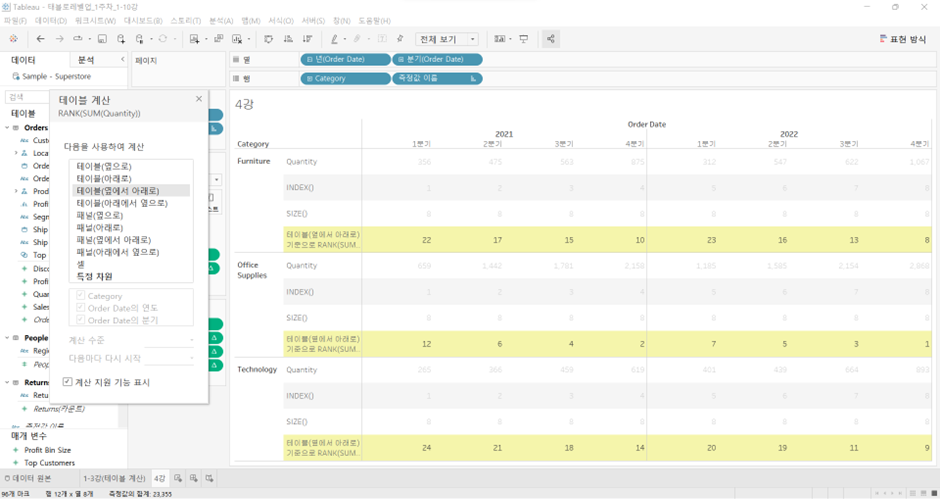
- 카테고리 및 연도 별로 잡았을 때: 1-4위
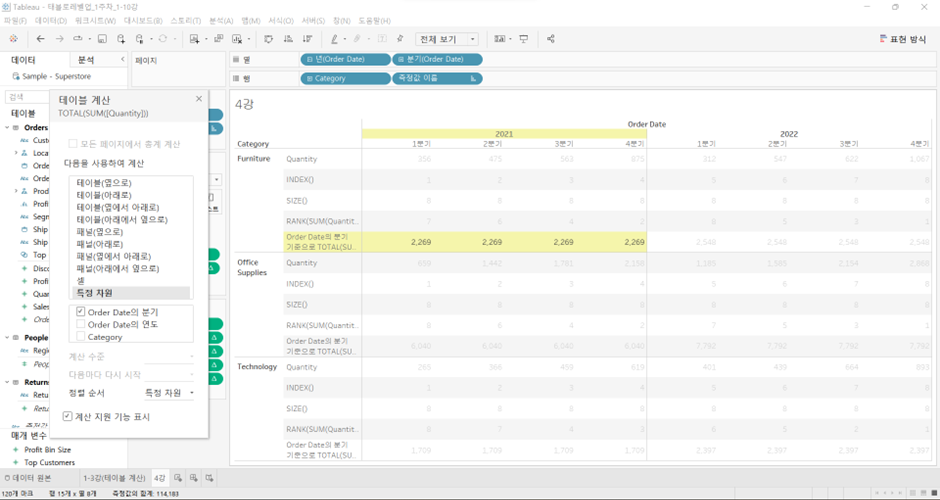
(4) TOTAL([Aggregated Calc]): 지정된 범위 전체에서의 Aggregated Calc(총합)
TOTAL(SUM(Quantity))
- Default 값: 각 카테고리별
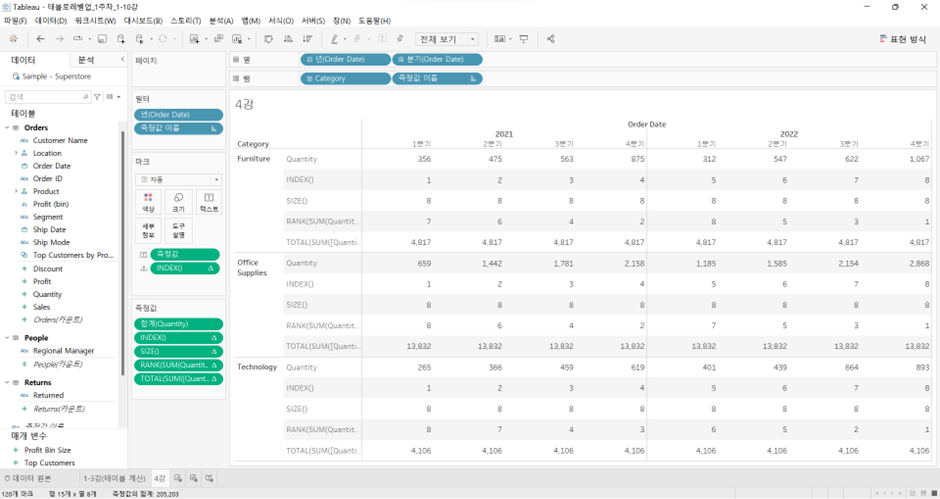
- 각 연도별, 카테고리별
INDEX vs. RANK
-
세팅:
Customer Name행에 올리고 >Order ID우클릭 드래그해서 카운트(고유)값으로 올리고 > 내림차순 정렬
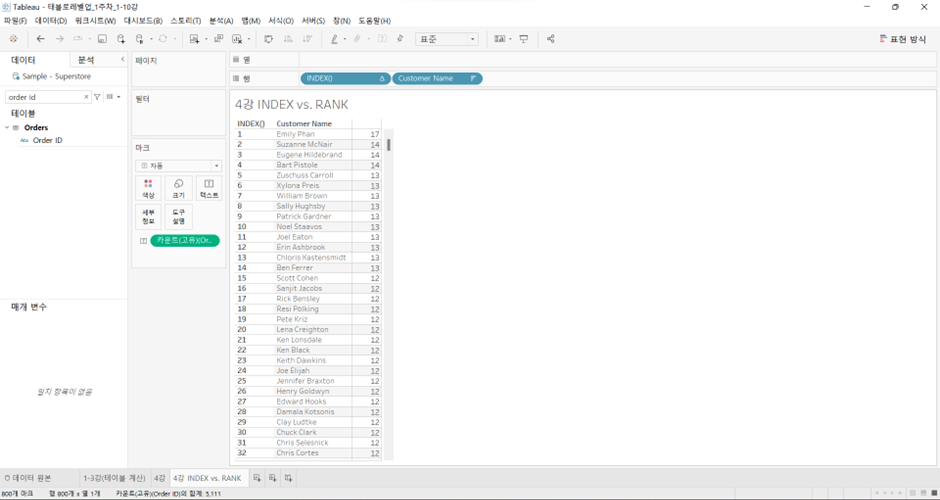
RANK(COUNTD([Order ID]))
*COUNTD: 중복 제외하고 카운트
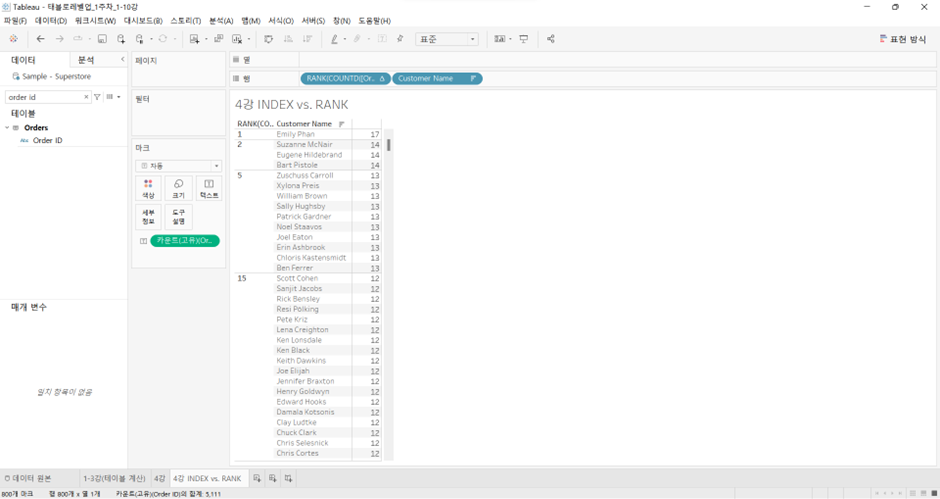
-
INDEX: 차원 sorting 자유롭다 (거꾸로 정렬 가능) vs. RANK: 그렇지 못하다
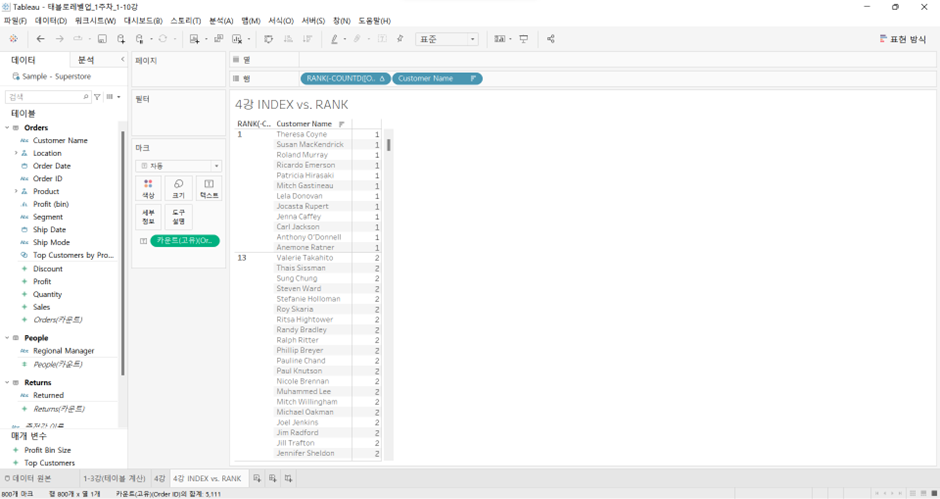
RANK(SUM([Sales]))로 바꾼 후,
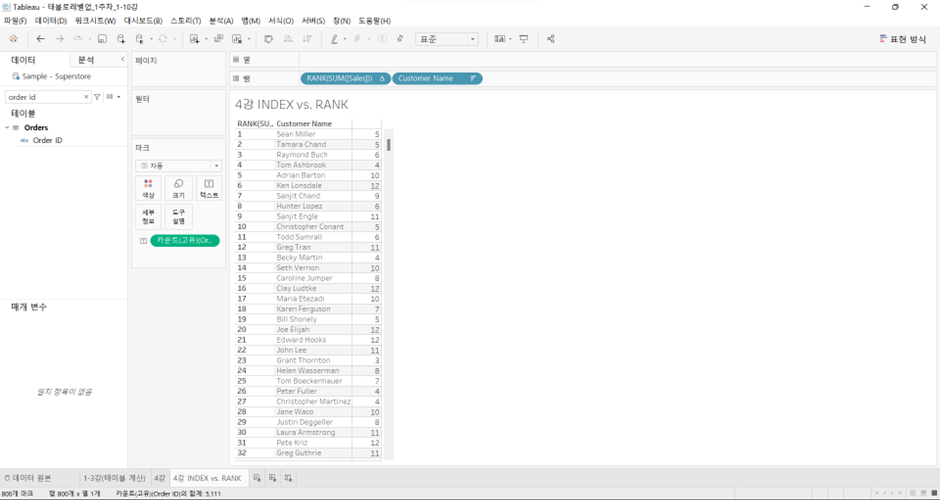
-
RANK: View에 없는 측정값 (이 경우 Sales)에 대해서도 순위 매김 vs. INDEX: 그렇지 못함
-
RANK: 다양한 동점자 처리 방식 지원
- e.g., (6, 9, 9, 14)의 순위에 대해
RANK(1, 2, 2, 4)RANK_DENSE(1, 2, 2, 3)RANK_MODIFIED(1, 3, 3, 4)RANK_UNIQUE(1, 2, 3, 4)
- e.g., (6, 9, 9, 14)의 순위에 대해
-
vs. INDEX: 그렇지 못함 (아래에, 동일한 측정값 갖고 있는 customer에 대해서도 index 다르게 매김)
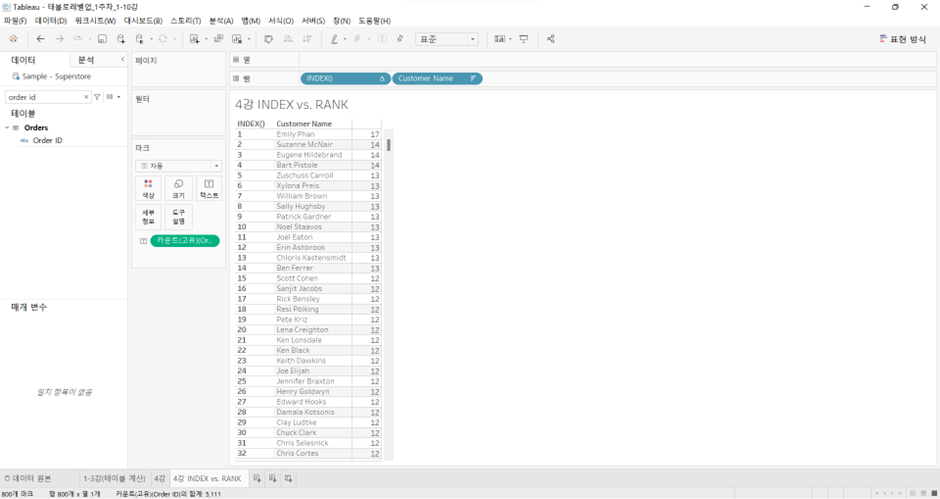
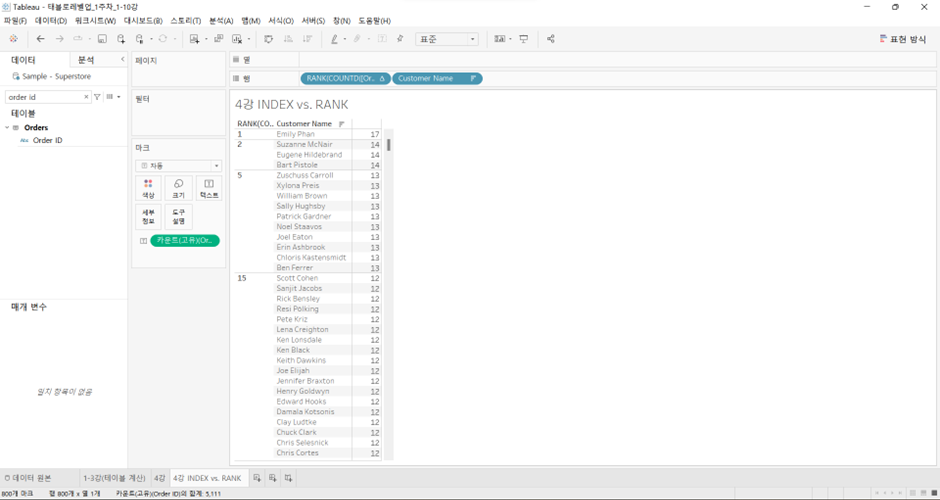
-
RANK를 오름차순으로 만들고 싶을 때: RANK(-COUNTD(Order ID))로 바꿔주기
5강 WINDOW 함수
-
세팅 열:
Order Date분기 연속형 (우클릭하여 ‘2015년 2분기’ 형식으로 설정 필요), 행:합계(Sales)연속형
-
계산된 필드 만들기 > 테이블 계산 선택 시 나타나는 윈도우 함수
(1)WINDOW_AVG
(2)WINDOW_COUNT
(3)WINDOW_MAX
(4)WINDOW_MIN
(5)WINDOW_SUM
Window란?
-
사용자 중심의 커스터마이징이 가능한 계산 (customizable calculation range)
-
테이블 계산 안에서는 반드시 집계된 계산이 들어가야 함 (테이블 계산은 secondary calc이기 때문)
-
WINDOW TEST (새 계산된 필드 만들기) >
WINDOW_AVG(SUM([Sales]))적용해서 올렸을 때,
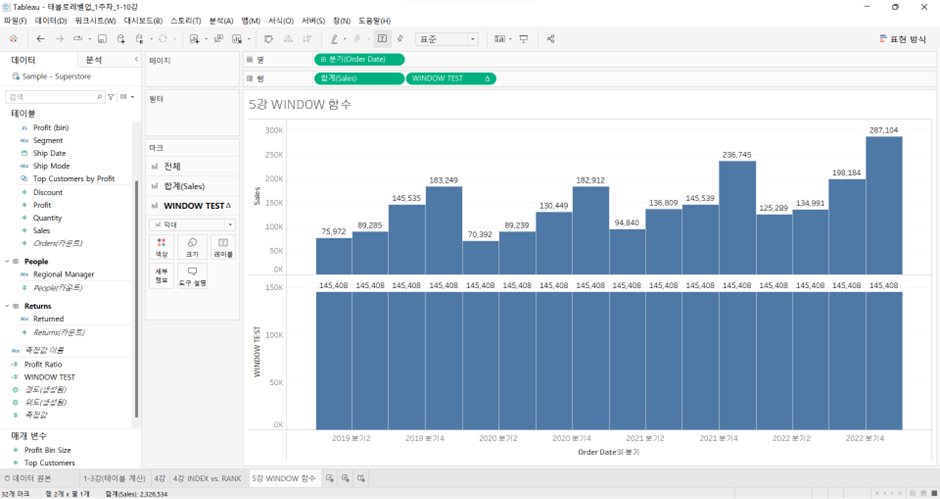
WINDOW_AVG
- 분기별 모든 Sales 다 합계한 이후, 화면의 분기 개수로 나눠서 평균 낸 값
- 형식:
WINDOW_AVG(식, [시작, 끝])WINDOW_AVG(SUM([Sales]), FIRST(), LAST())-> 처음부터 끝까지 평균을 내라- FIRST, LAST는 redundant하기 때문에 지워도 상관X
WINDOW_AVG(SUM([Sales]), 0, 3)(각 식에 대한 결과물은 아래 캡처 참고)
- [시작, 끝] -> 자기 자신을 기준으로 한 위치
- 0 -> 자기 자신의 위치
- 3의 위치에 오는 다른 숫자 -> 자신을 기준으로 상대적인 위치
- 마이너스가 붙으면 자기 앞의 것
- 위의 함수 적용 시 ’19.Q1에 나타나는 값 = 자기 자신 + 자신 뒤의 3개 (= 총 4개)의 평균
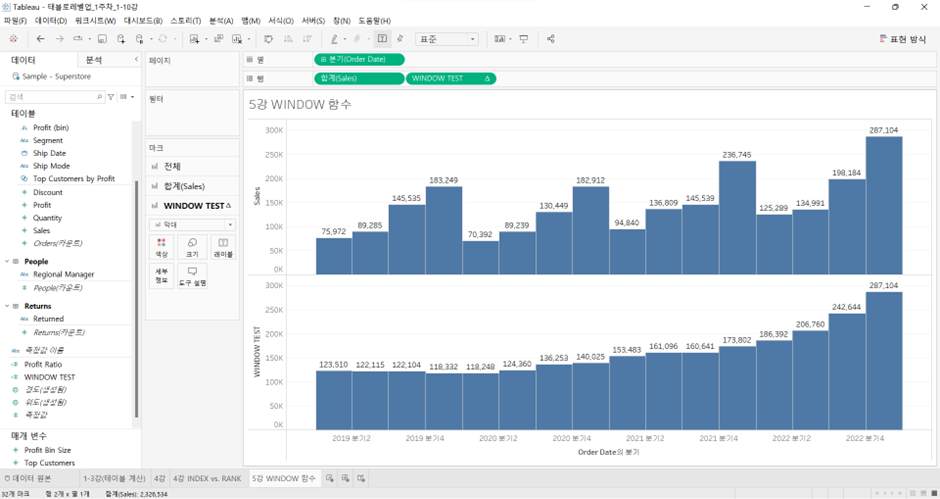
WINDOW_AVG(SUM([Sales]), -1, 1) - -1 -> 내 앞의 1개
- 1 -> 내 뒤의 1개
- 자기 자신을 포함해 총 3개의 평균
- 만약 ’19.Q1처럼 자신의 앞의 분기가 없다면 자신 + 뒤의 1개를 더한 후 2로 나눠줌 (값이 존재하지 않는 경우에는 고려X)
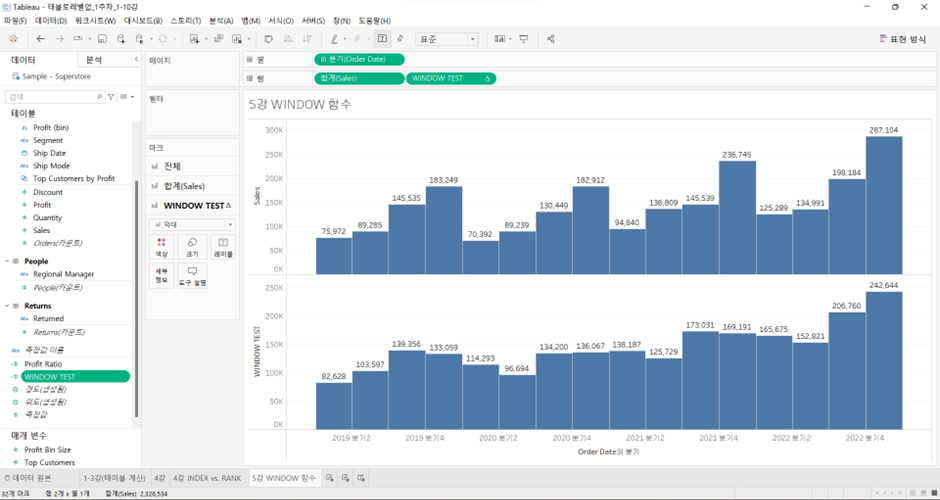
만약 나를 포함해 앞의 값과 뒤의 값이 모두 있는 경우에만 WINDOW 계산 결과를 달라고 하는 조건을 추가하려면?
IF WINDOW_COUNT(SUM([Sales]), -1, 1) = 3 THEN
WINDOW_AVG(SUM([Sales]), -1, 1)
END결과는 아래와 같음
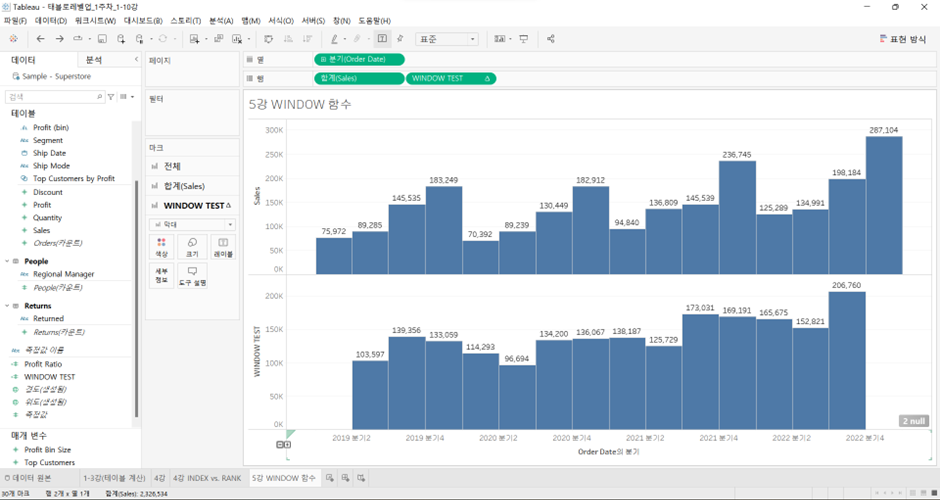
그러면 WINDOW는 셀이나 패널은 무시?
-
Order Date 불연속형으로 만들어주고
WINDOW_AVG(SUM([Sales]), -1, 1)&테이블 옆으로- 이 경우 연도로 설정되어 있는 패널을 무시하고 계산 이루어짐 (패널의 경계 뛰어넘어 개수 계산)
- 이 경우 연도로 설정되어 있는 패널을 무시하고 계산 이루어짐 (패널의 경계 뛰어넘어 개수 계산)
-
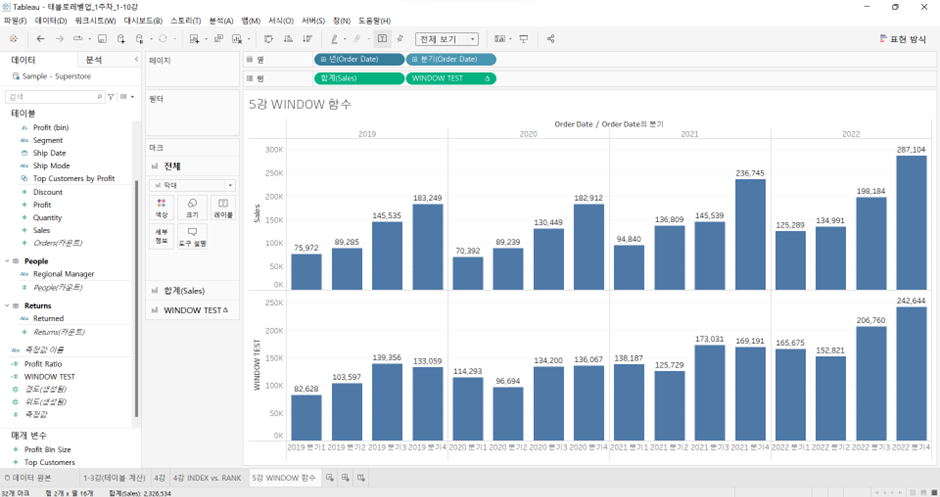
WINDOW TEST의 테이블 계산 편집 열고
WINDOW_AVG(SUM([Sales]), -1, 1)&패널 옆으로- 이 경우 테이블 계산에서 ’19.Q4의 값은 ’20.Q1의 Sales 값을 고려 X. 자기 앞에 있는 값 + 자기 자신의 값 평균 냈을 때의 값
-
여기에서 WINDOW TEST의 계산을 이렇게 편집하면?
IF WINDOW_COUNT(SUM([Sales]), -1, 1) = 3 THEN
WINDOW_AVG(SUM([Sales]), -1, 1)
END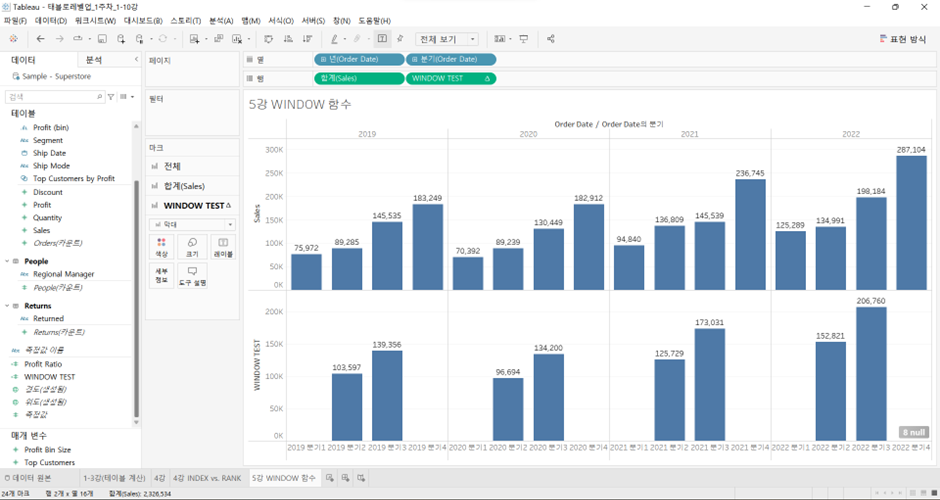
- 연도별로 2분기, 3분기의 값만 나타남
- 즉 WINDOW는 테이블, 패널 하부의 개념
WINDOW 함수의 Use Case
- 데이터의 분포가 상이하게 나타나는 차원 값 normalize시킬 때
Feature Scaling: 모든 value를 0에서 1 사이로 normalize 시킴- Sales-Normalized
(SUM([Sales])-WINDOW_MIN(SUM([Sales]))) /
(WINDOW_MAX(SUM([Sales])) - WINDOW_MIN(SUM([Sales])))-
세팅:
열, 행 외에INDEX()에서 테이블 계산 편집을 고객에 대해서 함 ->INDEX()를 사용하여 Sales 수는 너무 많이 겹치기 때문에 고객 다 보이게 퍼뜨린 것
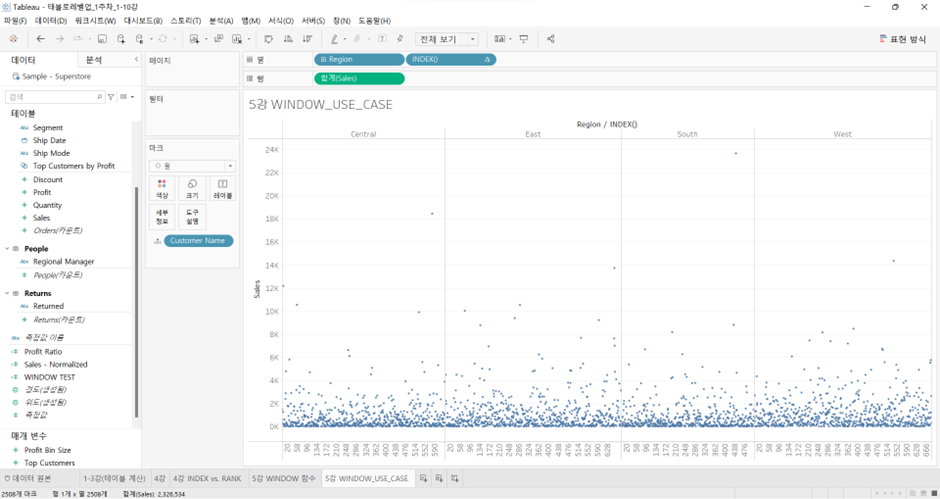
-
그러면 여기에서 지역별로 최대 매출 고객 4명 확인 가능
-
이 상태에서
Sales-Normalized를 행에 집어넣고Sales를 빼고Sales-Normalized테이블 계산을 고객에 대해서 만들어 주면, 아까 말했던 지역별 최대 매출 고객 4명이 동일 선상에서 확인 가능
(매출 규모 상대화시켜서 나타남)
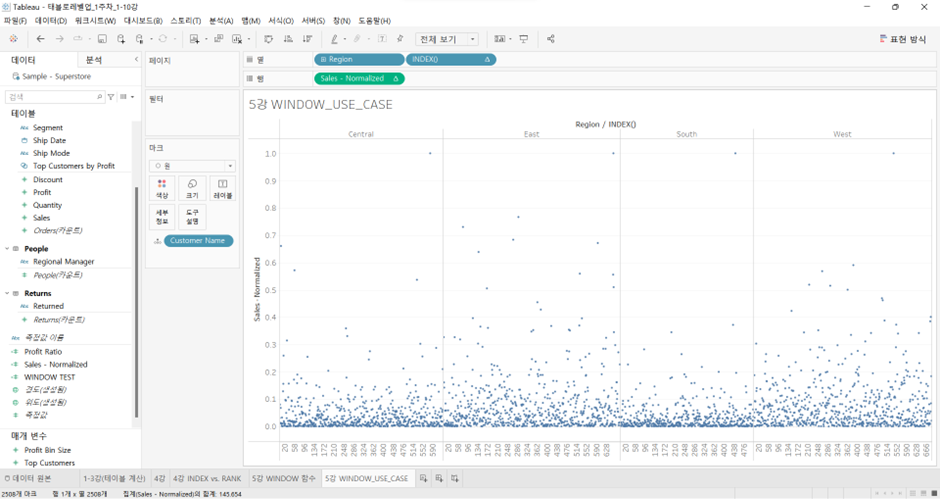
참고
