파이썬 판다스 심화
판다스(Pandas)는 매우 다양한 함수와 메소드를 제공하기 때문에 처음 사용하면 헷갈릴 수 있는 함수들이 많습니다.
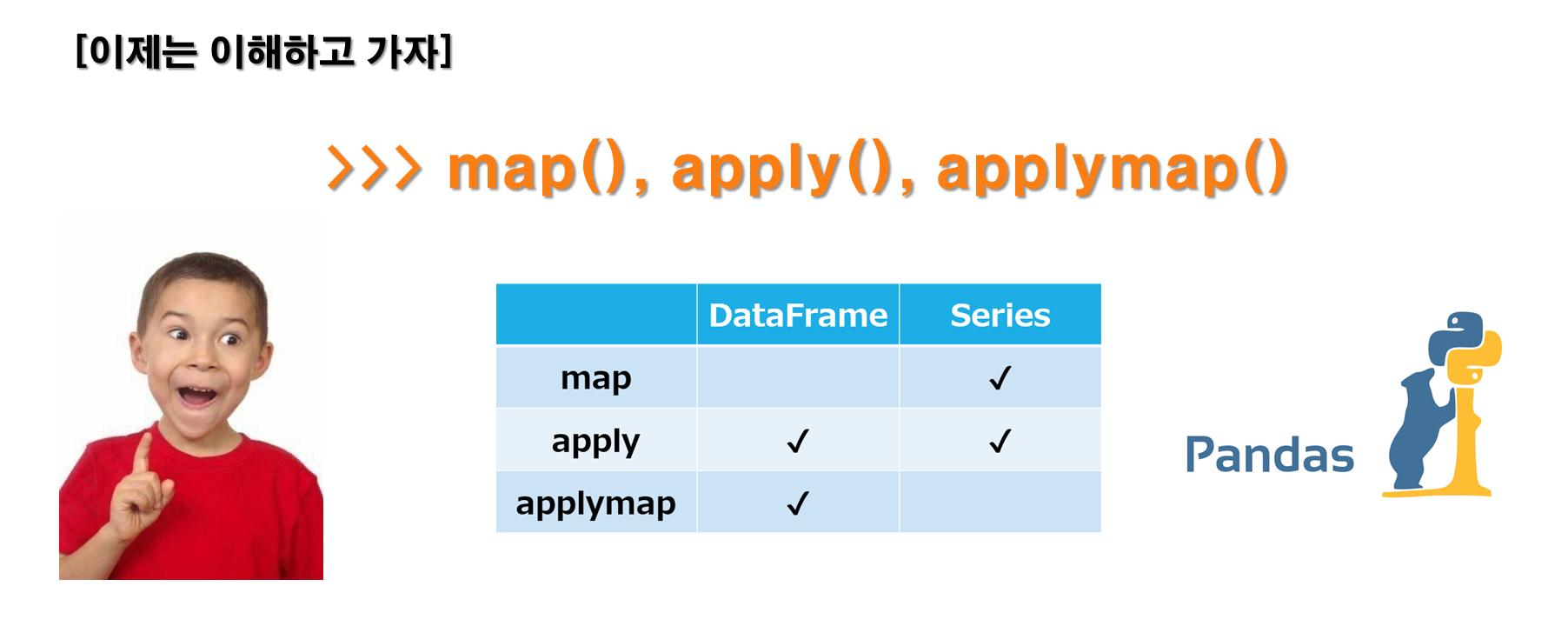
이번 포스트에서는 apply(), applymap(), map(), reduce()와 같은 헷갈릴 수 있는 함수들을 중심으로 간단한 개념과 예제를 소개해보도록 하겠습니다.
1. apply()
apply() 메소드는 시리즈(Series)나 데이터프레임(DataFrame)의 각 원소에 함수를 적용하여 결과를 반환합니다. 데이터프레임에서는 행(axis=0) 또는 열(axis=1)을 기준으로 함수를 적용할 수 있습니다. 예를 들어, 다음과 같은 데이터프레임이 있다고 가정해봅시다.
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})이 데이터프레임에서 각 열의 합을 구하고자 한다면 다음과 같이 apply() 메소드를 사용할 수 있습니다.
col_sum = df.apply(np.sum, axis=0)
print(col_sum)위 코드는 apply() 메소드를 사용하여 각 열의 합을 계산하고 col_sum 변수에 저장합니다. np.sum 함수를 첫 번째 인자로 전달하고, axis=0을 두 번째 인자로 전달하여 열을 기준으로 함수를 적용합니다. 출력 결과는 다음과 같습니다.
A 6
B 15
C 24
dtype: int642. applymap()
applymap() 메소드는 데이터프레임(DataFrame)의 모든 원소에 함수를 적용하여 결과를 반환합니다. 예를 들어, 다음과 같은 데이터프레임이 있다고 가정해봅시다.
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})이 데이터프레임의 모든 원소에 2를 곱하고자 한다면 다음과 같이 applymap() 메소드를 사용할 수 있습니다.
df2 = df.applymap(lambda x: x * 2)
print(df2)위 코드는 applymap() 메소드를 사용하여 데이터프레임의 모든 원소에 람다(lambda) 함수를 적용하고, 결과를 df2 변수에 저장합니다. 람다 함수는 입력값에 2를 곱하여 반환합니다. 출력 결과는 다음과 같습니다.
A B C
0 2 8 14
1 4 10 12
2 6 12 18이번에는 다른 예시를 살펴보겠습니다. 다음과 같은 데이터프레임이 있다고 가정해봅시다.
import pandas as pd
df = pd.DataFrame({
'A': ['apple', 'banana', 'cherry'],
'B': ['dog', 'cat', 'bird'],
'C': [1, 2, 3]
})이 데이터프레임의 문자열 데이터를 모두 대문자로 변경하고자 한다면 다음과 같이 applymap() 메소드를 사용할 수 있습니다.
df2 = df.applymap(lambda x: str(x).upper() if isinstance(x, str) else x)
print(df2)위 코드는 applymap() 메소드를 사용하여 데이터프레임의 모든 원소에 람다(lambda) 함수를 적용하고, 결과를 df2 변수에 저장합니다. 람다 함수는 문자열 데이터에 대해서는 대문자로 변경하고, 그렇지 않은 경우에는 그대로 반환합니다. isinstance(x, str)는 변수 x가 문자열(str)인지 확인하는 코드입니다. 출력 결과는 다음과 같습니다.
A B C
0 APPLE DOG 1
1 BANANA CAT 2
2 CHERRY BIRD 33. map()
이어서 혼동하기 쉬운 함수로 map()과 replace()를 살펴보겠습니다.
map() 메소드는 시리즈(Series)에서 사용할 수 있는 메소드입니다. 시리즈의 각 원소에 함수를 적용하여 결과를 반환합니다. 예를 들어, 다음과 같은 시리즈가 있다고 가정해봅시다.
import pandas as pd
s = pd.Series(['cat', 'dog', 'bird'])이 시리즈의 각 문자열 데이터의 길이를 구하고자 한다면 다음과 같이 map() 메소드를 사용할 수 있습니다.
s2 = s.map(lambda x: len(x))
print(s2)위 코드는 map() 메소드를 사용하여 시리즈의 각 원소에 람다(lambda) 함수를 적용하고, 결과를 s2 변수에 저장합니다. 람다 함수는 입력값의 길이를 반환합니다. 출력 결과는 다음과 같습니다.
0 3
1 3
2 4
dtype: int644. replace()
replace() 메소드는 데이터프레임(DataFrame)이나 시리즈(Series)에서 사용할 수 있는 메소드입니다. 데이터프레임이나 시리즈의 값을 다른 값으로 교체합니다. 예를 들어, 다음과 같은 시리즈가 있다고 가정해봅시다.
import pandas as pd
s = pd.Series([1, 2, 3])이 시리즈의 값을 다른 값으로 교체하고자 한다면 다음과 같이 replace() 메소드를 사용할 수 있습니다.
s2 = s.replace({1: 'apple', 2: 'banana', 3: 'cherry'})
print(s2)위 코드는 replace() 메소드를 사용하여 시리즈의 값 1을 'apple', 값 2를 'banana', 값 3을 'cherry'로 교체하고, 결과를 s2 변수에 저장합니다. 교체할 값을 딕셔너리(dictionary) 형태로 전달합니다. 출력 결과는 다음과 같습니다.
0 apple
1 banana
2 cherry
dtype: object딕셔너리의 키(key)는 교체할 값을, 값(value)은 새로운 값으로 지정합니다. 이렇게 replace() 메소드를 사용하면 데이터프레임이나 시리즈의 값을 쉽게 교체할 수 있습니다.
