이전글에 간략하게 EFK가 무엇인지 왜 사용해야 하는지에 대해 간략하게 설명했다.
필자는 모든 툴을 모두 이해한 상태에서 시작해야 한다고 생각하지 않기 때문에 일단 그냥 해보자
우선 쿠버네티스에서 모든 리소스는 namespace로 구분하기 편하기 때문에 Elastic Search , Fluentd , Kibana가 배포될 namespace를 생성하자. 본인은 kube-efk로 하겠다
- Namespace
### 명령어로 올리지 말고 yaml 형태로 리소스 생성하자
apiVersion: v1
kind: Namespace
metadata:
name: kube-efk*ElasticSearch
ElasticSearch는 Fluentd에서 수집된 로그를 여러 파드들이 공유받고 그 상태값을 유지해야 하기 때문에 상태값이 변하는 Deployment보다는 Statefulset이 좋겠다
apiVersion: apps/v1
kind: Statefulset
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
replicas: 1 #노드 하나로만 구성하는 ElasticSearch를 실행할 것이므로 replicas=1로 하겠다
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elastic/elasticsearch:6.4.0 #공식 사이트에서 이미지 정보를 받아오자
env:
- name: discovery.type
value: "single-node" #Discovery.type의 value를 single-node로 설정해서 노드가 한개인걸로 설정
ports:
- containerPort: 9200 # ElasticSearch가 사용하는 포트인 9200,9300번을 설정
- containerPort: 9300
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elasticsearch
name: elasticsearch-svc
namespace: default
spec:
ports: # 위에서 지정한 port들을 각각 nodeport 30920,30930으로 접근 가능하도록 nodeport 필드를 설정했습니다.
- name: elasticsearch-rest
nodePort: 30920
port: 9200
protocol: TCP
targetPort: 9200
- name: elasticsearch-nodecom
nodePort: 30930
port: 9300
protocol: TCP
targetPort: 9300
selector:
app: elasticsearch
type: NodePort자 이제 yaml을 저장하고 kubectl apply -f elasticsearch.yaml로 파드를 실행합니다.
localhost:30920을 통해 다음 설정이 확인되면 elasticsearch가 정상적으로 실행 된겁니다.
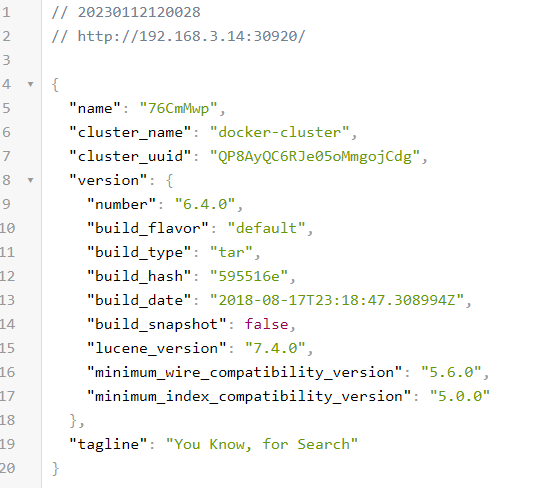
다음에는 로그 데이터를 시각화해서 편하게 보기위한 kibana를 배포해보도록 하겠다
필자가 쓰고도 부끄러우니 이 글은 잘 다듬어서 주말에 수정하도록 하겠다

2dn