일하다 보니 부서 내 어디선가 EFK를 쓴다는 말을 들었다.
용어가 AWS의 컴포넌트들이랑 비슷해서 AWS에 있는 하나의 컴포넌트 겠거니 했는데
로그수집 및 모니터링에 유용한 툴 이라고 한다.
쿠버네티스 환경에 MSA로 띄워져 있는 각각의 역할을 하는 서비스들,,, 지금은 10개 내외로 띄워져 있지만 서비스가 확장되고 여러 기능들이 생길때마다 늘어나는 파드들이 생길 것이다. 지금은 기능이 많이 없어서 어떤 서비스에서 장애가 나면 대충 어떤 파드에서 에러가 낫겟거니 유추가 가능하지만 1년뒤에도 내가 이 파드가 어떤 서비스를 제공하고 있는지 다 알지는 못할 것 같다.
임시로 모든파드에 있는 로그들을 마스터서버 디렉토리에 마운트 시켜놓긴 했지만 로그들을 일일이 보려면 여전히 불편하긴 하다.
그래서 EFK란가 뭔가를 구축해보려 한다.
필자는 아직도 저게 다 뭔지 무슨 기능을 하는지는 아직도 모른다. 지금 쓰면서 알아가보자
우선 EFK는 ElasticSearch + Fluentd + Kibana 이 3스택의 앞글자를 따와서 EFK라고 한다.

이 각 스택이 무슨 역할을 하는지 3개를 같이 쓰면 가 좋은지 까지 정리하고 이 포스팅을 마무리 해 보자
ElasticSearch
이 친구는 검색엔진이라고 한다. 많은 양의 데이터를 보관하고 실시간으로 저장,검색,분석 할 수 있게 해준다고 한다.
ElasticSearch의 특징들을 알아보고 가자
- 멀티테넌시
- 데이터를 여러개로 분리된 인덱스들의 그룹으로 저장한다
- 서로 다른 인덱스의 데이터를 하나의 질의로 검색하여 하나의 출력으로 도출이 가능하다
- 실시간 데이터 및 실시간 분석
- 저장된 데이터는 검색에 사용되기 위해 별도의 재시작/갱신이 불필요하다
- 색인 작업이 완료됨과 동시에 바로 검색이 가능하다
- 실시간 분석/ 검색은 데이터 증가량에 구애받지 않는다.
- 고가용성
ElasticSearch는 하나 이상의 노드로 구성되고 각 노드에는 1개 이상의 데이터 원본과 복사본을 서로 다른위치에 나누어 저장을하여 고가용성을 제광한다
- 항상 일정한 데이터의 복사본의 개수를 유지하여 높은 가용성과 안정성을 보장한다.
- 노드가 종료되거나 실행에 실패할 경우 다른 노드로 데이터를 이동한다.
4.테이블과 스키마 대신에 JSON 구조로 인헤 모든 레벨의 필드에 접근이 쉽고, 빠른 속도로 검색이 가능해진다.
- JSON 문서를 URI로 명시 , 이 문서를 처리하기 위해 HTTP 메소드를 이용한다.
필자도 다른 포스트를 참고하고 있다보니 어려운 용어로 쓰고 있는 것 같다. 앞으로 모든 포스트가 써진 후 수정 될거 같다 미안하다.
ElasticSearch의 시스템 구조정도는 알아보고 가야할 것 같다.
ElasticSearch의 하나의 클러스터는 마스터노드와 데이터노드로 구성된다.
마스터 노드는 전체 클러스터의 상태에 대한 메타정보를 관리하느 노드다.
기존의 마스터 노드가 종료되면 새로운 마스터 노드가 선출되고 마스터 노드는 요청을 처리하지 않고 데이터를 보유하지 않으므로 CPU,RAM 및 디스크와 같은 적은 리소스만 사용한다.
node.master 속성을 false하면 마스터 노드에서 제외된다.
데이터 노드는 색인도니 데이터를 실제로 저정하느 노드이다.
데이터 노드는 인덱스 처리 빈도에 따라 Hot Data Node와 Warm Data Node로 나뉘어 진다.
node.data속성을 false로 하면 내당 노드는 데이터를 저장하지 않는다.
FluentD
이 친구는 로그 데이터를 수집하고 변환 후 ElasticSearch의 백엔드로 전송해주는 역할을 하는 친구라고 한다. 이 친구가 먼저 로그 수집을하고 ElasticSearch로 보내주나 보다.
ElasticSearch를 너무 힘줘서 썻은니 이 친구의 특징은 간단히 설명하고 넘어가겠다
- 데이터의 유실을 막기위해 메모리와 파일기반의 Buffer 시스템을 갖고있다.
- Failover를 막기위한 HA 구성도 가능하다고 한다.
Kibana
이 친구는 수집된 로그를 그래프, 파트로 제공해주는 ElasticSearch용 데이터 시각화 관리도구라고 한다. Kibana를 사용하여 웹 사이트 방문자를 표시할 수도 있고 트래픽을 실시간으로 볼 수도 있다.
EFK 스택 아키텍처
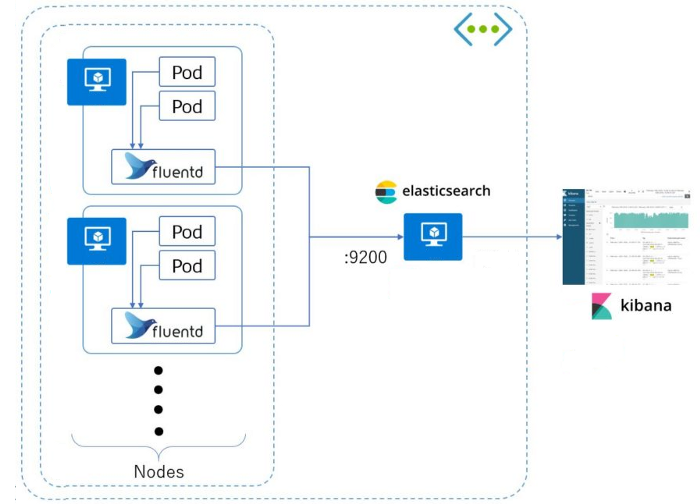
본인도 조금 더 EFK를 알게되면 아키텍처까지 직접 그려서 구축해보겠다.
아키텍처를 조금 설명하자면 각 파드의 Fluentd에서 로그를 수집하고 수집된 로그를 ElasticSearch 백엔드로 변환하여 전송한다. ElasticSearch에서 데이터가 분석되고 분석된 데이터는 Kibana로 시각화하여 볼 수 있다.
참고: Kibana 대시보드를 사용하고 나머지 Fluentd ElasticSearch는 백엔드에서 작동한다.
이제 EFK 스택을 구성하는 각각의 서비스에 대해 간략하게 알아봤으니 상세 구축과정을 살펴보자
