딥러닝을 활용한 Image Compression 논문을 읽으면 RD 커브 (Rate-Distortion Curve) 그래프에 비교 방법론 중 고전적인 방법인 JPEG, JPEG2000 등의 방법이 보인다.
최근 논문에는 잘 안넣고 딥러닝만 비교하는 추세같아 보이지만, 그래도 고전적인 방법에 딥러닝을 접목시켰을 것이기 때문에 공부한 것을 정리해보려합니다.
1. JPEG
논문 : The JPEG still picture compression standard
https://ieeexplore.ieee.org/document/125072
JPEG (Joint Photographic Experts Group)은 이미지 압축 중 손실 압축(Lossy Compression)에 속하는 압축 방법이다. 제이펙이라 불리고, 확장자는 .jpg, .jpeg 확장자를 사용한다.
여기서 손실 압축 (Lossy Compression)이란 원래 데이터를 일부 손실하여 압축하는 방법이다. 즉, 데이터 일부를 손실하며 데이터 크기를 줄인다.
압축 과정
1. 색 공간 변환 (RGB -> YCbCr)
YCbCr 색 공간에서 Y는 밝기 값이며, Cb,Cr은 색차 성분이다.
Cb : 파란색이 얼마나 있는가
Cr : 빨간색이 얼마나 있는가
공간을 변경하는 이유는 사람이 예민하게 반응하는 밝기와 색감을 채널로 정의하여 압축과정을 효율적으로 하기 위함이다. 사람은 색 구분 성능은 좋지 않다.
2. 다운샘플링(downsampling) = 크로마 서브샘플링 (Chroma subsampling)
YCbCr로 변환한 후 Y 성분은 그대로 두고 Cb, Cr을 줄이기 위해 다운샘플링을 진행한다. Y 성분을 그대로 두는 이유는 앞서 말한 것 처럼 사람은 밝기에 민감하기 때문이다.
다운샘플링 방법은 주로 J:a:b로 표현한다.
J : 픽셀 블럭의 너비 (주로 4 사용)
a : 첫번째 행에서 추출할 샘플 수
b : 두번째 행에서 추출할 샘플 수
default 비율은 4:2:0 샘플링을 주로 사용.
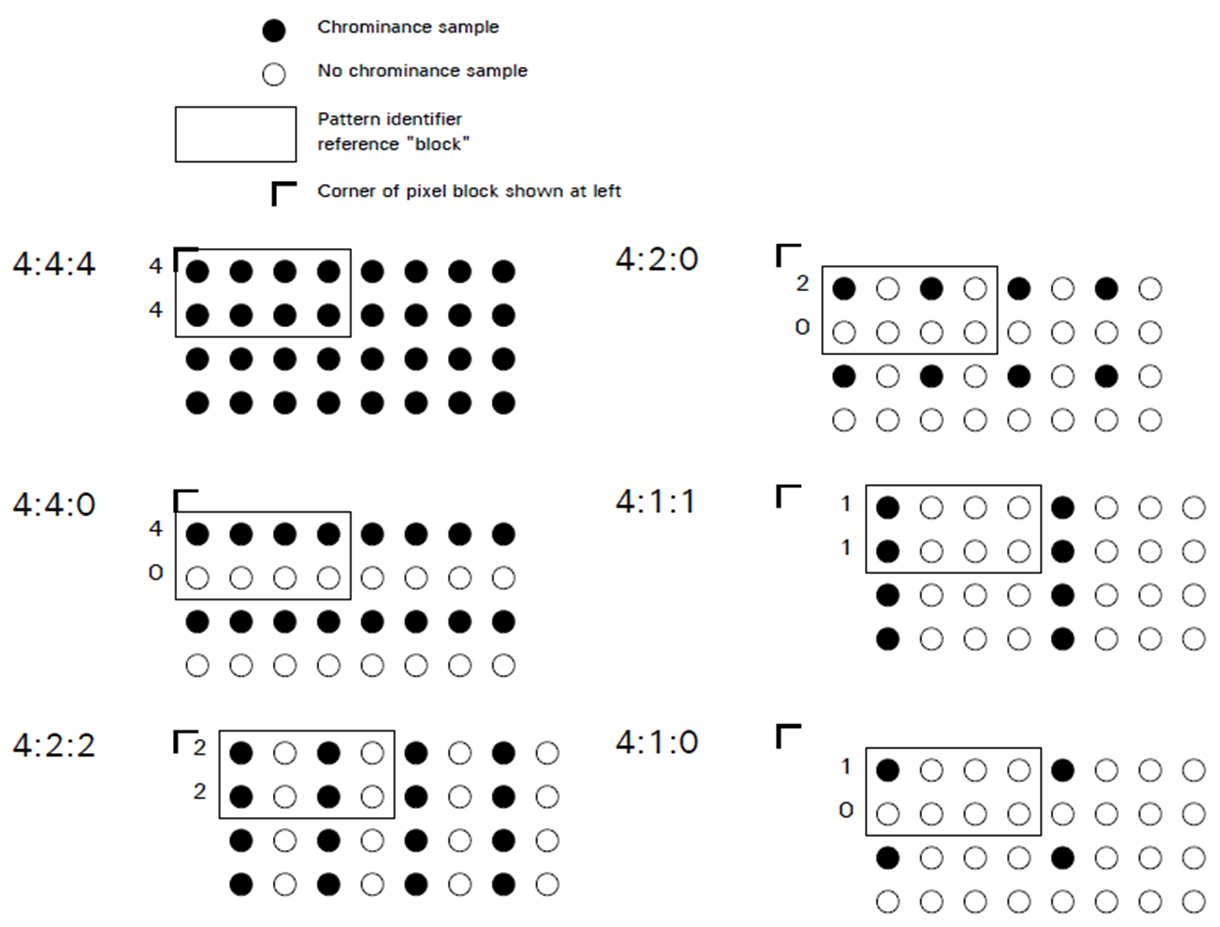
J,a,b 값을 조절하여 샘플링 및 버릴 픽셀 정보를 사용자가 조절할 수 있다.
3. 블록 (8x8) 나누기
서브샘플링까지 진행했다면 각 성분에서 128을 빼주고 8x8 행렬로 분할한다. 그러면 픽셀의 범위는 0~255에서 -128~127로 변경된다. 128을 뺀 이유는 이산 코사인 변환의 범위에 맞춰주기 위함이다.
4. 이산 코사인 변환(Discrete Cosine Transform, DCT)
이산 코사인 변환은 이미지 공간 도메인에서 주파수 도메인으로 변환하는 방법이다. 시각적으로 중요도가 낮은 고주파 성분을 분리해낸다.

8x8 패치를 DCT 변환을 하면 8x8 패치의 값이 -255~255사이의 값으로 변하게 될 것이다.
좌상단에 있는 숫자를 DC (낮은 주파수), 그 외 숫자는 AC(높은 주파수)라고 한다.
5. 양자화 (Quantization)
양자화 과정은 DCT로 변환된 계수를 더 작은 비트 수로 근사화하여 저장하는 과정이다. 이 과정에서 정보의 손실이 발생하므로, JPEG 압축은 손실 압축 방식에 속한다.
양자화는 각 DCT로 도출된 값을 양자화 행렬로 나누고 결과를 반올림하여 얻는다.
양자화 행렬은 고주파 성분을 더 큰 값으로 나누어 더 많이 축소시키므로, 이미지의 중요하지 않은 정보를 제거한다.
양자화를 진행하면 고주파 성분의 값은 0으로 변할 것이다.
6. 지그재그 스캐닝 (Zigzag Scanning)
지그재그 스캐닝은 8x8의 양자화된 DCT 계수 블록을 1차원 벡터로 변환하는 과정이다. 블록의 좌상단 모서리에서 시작하여, 대각선 방향으로 아래로 내려가다가, 가능한 경우 오른쪽으로 이동하며, 다시 위로 올라가는 패턴을 반복합니다. 이 과정은 블록의 모든 계수를 순회할 때까지 계속진행하는 방식으로 압축한다.
8x8 행렬에서 다음 순서로 스캔이 진행된다.
아래와 같은 순서로 진행하는 이유는 DCT와 양자화 과정을 거친 후, 대부분의 이미지 정보(에너지)는 8x8 블록의 좌상단 모서리(저주파 영역)에 집중되어 있고, 우측 하단 모서리(고주파 영역) 쪽으로 갈수록 계수들은 0에 가까운 값을 많이 가지기 때문이다. 지그재그 스캐닝은 이러한 계수들을 효과적으로 배열하여, 연속된 0들을 더 잘 그룹화함으로써 후속 엔트로피 인코딩 과정을 최적화 할 수 있다.
0 1 5 6 14 15 27 28
2 4 7 13 16 26 29 42
3 8 12 17 25 30 41 43
9 11 18 24 31 40 44 53
10 19 23 32 39 45 52 54
20 22 33 38 46 51 55 60
21 34 37 47 50 56 59 61
35 36 48 49 57 58 62 63
7. 엔트로피 코딩 (Entropy Coding)
양자화 과정을 거친 후, 결과물은 엔트로피 코딩을 통해 압축된다. 엔트로피 인코딩에는 주로 허프만 코딩(Huffman Coding)이나 산술 코딩(Arithmetic Coding)과 같은 방법이 사용된다. 이 과정은 데이터의 통계적 속성을 이용하여 더 효율적으로 데이터를 표현한다.
2. JPEG 2000
논문 : THE JPEG2000 STILL IMAGE CODING SYSTEM
https://www.cs.cmu.edu/~guyb/realworld/paper_ieee_ce_jpeg2000_Nov2000.pdf
JPEG 2000 (JP2)는 JPEG 방법을 대체할 목적으로 개발되었다. JPEG 과정 중 이산 코사인 변환 대신, 이산 웨이블릿 변환을 사용하였다. 확장자는 .jp2를 사용한다.
JPEG 2000은 JPEG과 달리 일반적으로 사용되지 않는다고 한다.
압축 과정
1. 색 공간 변환 (RGB -> YCbCr)
JPEG와 동일하게 색 공간을 변환한다.
2. 타일링 (Tiling)
큰 이미지를 처리할 때, 이미지는 여러 개의 작은 타일로 분할한다. 이는 메모리 사용량을 줄이고 처리를 병렬화할 수 있게 해준다. 그리고 각 타일은 독립적으로 압축되어 처리된다.
3. 이산 웨이블릿 변환 (Discrete Wavelet Transfrom, DWT)
DWT는 이미지의 다양한 해상도를 제공하며, 고주파와 저주파 성분을 분리한다. 고주파 성분은 세부 정보를, 저주파 성분은 광범위한 특징을 나타낸다.
2D DWT는 이미지를 LL(저주파), LH(수평 고주파), HL(수직 고주파), HH(대각선 고주파)로 총 4개의 섹션으로 분리한다.
4. 양자화 (Quantization)
JPEG와 동일하게 양자화를 진행한다.
5. 엔트로피 코딩 (Entrophy Coding)
JPEG 2000은 EBCOT(Embedded Block Coding with Optimized Truncation, 내장형 블럭 부호화)를 사용하여 웨이블릿 계수를 효율적으로 압축한다.
4. Reference
https://suyeon96.tistory.com/15
https://ko.wikipedia.org/wiki/JPEG
https://youtu.be/tHvZngU14jE?si=5kUoif9wx_8sTXdI
