[Compression] Learning End-to-End Lossy Image Compression: A Benchmark (2021) 리뷰, Proposal 제외
Image Compression
논문 제목
Learning End-to-End Lossy Image Compression: A Benchmark (2021)
https://arxiv.org/abs/2002.03711
인용수 : 141회
1. INTRODUCTION
이미지 압축, 특히 lossy image compression의 목표는 이미지 신호의 중요한 시각 정보를 보존하는 동시에 효율적인 전송 및 저장을 위해 이미지 인코딩에 사용되는 비트 전송률을 낮춰야한다. 다양한 애플리케이션 시나리오에 따라 이미지 품질과 코드의 bit-rate 간의 균형을 맞추기 위한 절충점을 찾는다.
최근 수십 년 동안 비트 전송률 제약으로 재구성 품질을 최적화하기 위해 다양한 코덱이 개발되었다.
기존 이미지 압축 프레임워크의 설계에는 두 가지 기본 원칙이 있다.
- 이미지 신호는 decorrelated 해야하며, 이는 엔트로피 코딩의 효율성을 향상시키는 데 도움이 됨.
- lossy compression의 경우 무시된 정보가 재구성 품질에 미치는 영향이 가장 적어야함. 시각적으로 중요하지 않은 정보는 코딩 과정에서 버려야됨.
기존의 이미지 압축 파이프라인은 Transfrom, Quantization, Entropy Coding과 같은 모듈로 구성되어있다.
- 이미지 압축을 위해 잘 설계된 Transform은 이미지 신호를 compact하고 decorrelated한 계수로 변환함. 이산 코사인 변환 (DCT)은 JPEG 이미지 코딩 표준에서 8x8로 분할된 이미지에 적용됨.
JPEG 2000의 이산 웨이블릿 변환 (DWT)은 multiresolution image representation을 도입하여 스케일에 걸쳐 이미지를 decorrelate하여 코딩 성능을 향상 시킴. - 양자화는 계수 벡터에서 정보가 적은 차원을 잘라내어 가장 중요도가 낮은 정보를 삭제함. 양자화 성능을 improve하기 위해 vector quantization과 trellis-coded quantization 등의 방법이 도입되기도 함.
- 그 후, 상관 계수는 엔트로피 코딩으로 압축됨. 허프만 코딩은 JPEG 이미지에 먼저 사용되었음. 그 다음 arithmetic coding 및 context-adaptive binary arithmetic coding이 이미지 및 비디오 codec에 활용됨.
기본 구성 요소 외에도 최신 비디오 코덱 (HEVC & VVC)은 프레임 내 코딩을 위해 intra prediction 과 in-loop filter를 사용.
두 가지 방법은 이미지 코덱인 BPG에도 적용되어 공간 중복성(spatial redundancy)을 더욱 줄이고 재구성 프레임의 품질, 특히 interblock redundancy을 개선함.
그러나 널리 사용되는 기존의 하이브리드 이미지 코덱에는 한계가 있음.
- 이러한 방식들은 모두 분할된 이미지 블록(ex 8x8)을 기반으로 하므로 blocking effects가 발생.
- 코덱의 각 모듈은 다른 모듈에 대해 복잡한 종속성을 가지고 있음. 따라서 전체 코덱을 jointly optimize하는 것은 어려움.
- 모델을 전체적으로 최적화할 수 없기 때문에 한 모듈을 부분적으로 개선해도 전체 성능이 향상되지 않아 정교한 프레임 워크의 추가 개선이 어려울 수 있음.
딥러닝의 발전으로 end-to-end 이미지 압축 프레임워크를 구축하기 위한 많은 연구가 진행됨. 학습 기반 방법은 기존 방법과 상당한 차이가 있음.
end-to-end 학습 방식의 경우 전체 프레임워크를 최적화할 수 있기 때문에 모듈 성능을 개선하면 자연스럽게 최종 성능 개선으로 이어짐. 또한, joint optimization을 통해 모든 모듈이 더 adaptive하게 작동.
end-to-end learned image compression 방법을 설계할 때는 두 가지 측면을 고려해야함.
- transform network 이후의 latent representation coefficients가 낮으면 엔트로피 코딩에서 더 많은 bit-rate를 save할 수 있다.
- 엔트로피 모델에 의해 계수의 확률 분포를 정확하게 추정할 수 있다면 비트스트림을 더 효율적으로 활용할 수 있고, latent representations을 인코딩하는 bit-rate를 더 잘 제어할 수 있어 bit-rate와 distortion 사이의 균형을 더 잘 맞출 수 있다.
generalized divisive normalization (GDN)은 density model로 image content를 모델링하여 이미지 압축에서 뛰어난 성능을 보여준다. GDN 이후 수많은 end-to-end learned image compression 방법이 개발되었음.
2. PROBLEM FORMULATION
Natural image signal에는 많은 공간적 중복(spatial redundancies)이 포함되며 perceptual quality에 큰 저하없이 압축할 수 있는 잠재성이 있다.
bandwidth와 storage에 대한 실질적 제약을 고려할 때, lossy image compression은 특정 이미지를 표현하는 bit-rate를 최소화하여 일정 수준의 왜곡을 허용하여 널리 채택되고 있음.
압축 프레임워크는 일반적으로 encoder-decoder 쌍으로 구성된다.
입력 이미지 와 의 분포인 , encoding transform ε 와 양자화 함수 가 있는 인코더가 주어지면 discrete code 는 다음과 같이 생성된다.
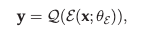
여기서 은 학습 중 조절할 인코더 파라미터를 나타낸다.
이미지 픽셀의 representation을 얻기 위해 디코더 는 code 에서 이미지 을 reconstruct함.
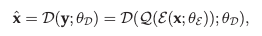
여기서 는 의 파라미터를 나타낸다.
두 가지 종류의 metric, 즉 distortion D와 bit-rate R은 lossy image compression의 핵심 문제인 bitrate-distortion 최적화 를 해야함.
D는 재구성된 이미지가 원본 이미지가 얼마나 다른지를 측정하며, 일반적으로 fidelity 기반 metrics 또는 perceptual metrics을 통해 측정함. (주로 mse 사용)
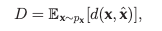
여기서 는 왜곡 함수를 나타냄. R은 entropy constraints에 따라 를 인코딩하는 비트 수를 나타낸다.
그러나 로 표시되는 latent code 의 실제 확률 분포는 알 수 없으므로 정확한 엔트로피 계산이 어려움.
따라서 일반적으로 엔트로피 코딩을 위해 엔트로피 모델 를 사용하여 를 추정함.
따라서 rate는 다음과같이 와 의 cross entropy로 공식화할 수 있다.
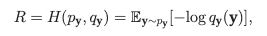
여기서 는 실제 확률분포를 나타내고 는 엔트로피 모델에 의해 추정된 분포를 나타낸다.
전체 compression model은 R과 D의 가중합을 최적화한 것을 볼 수 있으며, trade-off 계수 를 사용하여 다음과 같은 최적화를 최소화함으로써 문제를 해결할 수 있다.
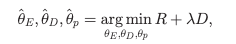
여기서 는 엔트로피 모델의 파라미터를 나타낸다. 최적의 parameters 은 를 따르는 이미지 에서 전반적으로 우수한 rate-distortion performance를 달성하는 모델을 만들 수 있음. 값은 다른 applications의 요구사항에 따라 rate-distortion trade-offs을 나타냄.
rate-distortion optimization 개념은 기존 압축 방식에도 적용되지만, learning-based methods은 최종적으로 모든 구성 요소의 joint optimization를 할 수 있다.
Global Optimization
learned image compression과 기존 traditional hybrid codec의 가장 큰 차이점은 최적화에 있다.
learned image compression모델은 수작업으로 조정하는 대신 신경망에 의해 계산되는 SSIM, MS-SSIM, perceptual difference 등으로 조정할 수 있다.
또한 기존의 하이브리드 코딩 프레임워크는 일반적으로 개별 구성요소의 규모에서 개선되는 반면, 학습 기반 방식에서는 모든 모듈을 학습할 수 있으며 모든 파라미터와 구성요소를 공동으로 최적화할 수 있다. 하지만 최적화의 어려움으로 인해 end-to-end learned compression에서 좋은 성능을 얻기 어려움.
Full-Resolution Processing
하이브리드 프레임워크는 일반적으로 분할된 블록을 처리하지만, 합성곱 신경망은 이미지의 전체 해상도를 처리한다.
Full Processing은 더 많은 context를 통해 엔트로피 모델링에 더 많은 이점을 가져다주고 partitioning으로 인한 blocking effect를 피할 수 있다. 또한 Full-Resolution Processing는 복잡성이 증가함.
컨볼루션 커널의 인식 영역은 제한되어 있기 때문에 더 넓은 영역을 인식하고 modeling capacity을 개선하려면 네트워크는 더 깊어져야함.
Rate Control
joint optimization를 사용하면 전체 모델이 rate-distortion constraint을 target으로 삼을 수 있지만, 하이브리드 방식에서는 additional rate-control component가 사용되며 최적의 근사치를 생성하지 못할 수 있다.
그러나 learning-based methods의 대부분은 다양한 rate-distortion trade-offs에 대해 여러 모델을 학습 시켜야한다.
다른 single-model variable-bit-rate architectures는 일반적으로 훨씬 더 많은 시간이 소요된다. 따라서 이러한 방법의 실용성은 제한적이다.
3. OVERVIEW OF PROGRESS IN RECENT YEAR
deep networks의 strong modeling capacity에 힘입어 learned image compression의 성능은 JPEG, BPG (HEVC Intra)의 성능을 넘어섰고, 성능 격차는 더욱 벌어지고 있다.
초기 연구는 신경망으로 ransform coding을 적용할 수 있는 아키텍쳐를 찾고 end-to-end trainable solution을 제안하는 것을 목표로 했다.
네트워크를 end-to-end trainable로 만들려면 미분 불가능한 quantization component를 신중하게 설계하고 미분가능하도록 프로세스를 설계해야한다.
일부 연구에서는 양자화를 uniform noise로 대체하고, 다른 연구에서는 forwarding에서 direct rounding을 사용하고, 의 gradient를 역전파한다. 또한, 양자화를 더 부드럽게 하기 위해 direct scalar quantization를 soft-to-hard vector quantization으로 대체하는 방법을 제안.
다른 연구에서는 양자화 파라미터를 추가적으로 학습하는 모델을 설계함. 양자화를 통합한 variational autoencoder (VAE) 기반 모델을 훈련하는 것은 간단하지 않기 때문에 최근에도 이미지 압축을 위한 advanced optimization techniques이 광범위하게 연구됨.
압축 네트워크를 훈련할 수 있게 되면, 다음 문제는 이미지 신호 간 spatial redundancy을 효율적으로 줄이는 것이며, 일반적으로 transform이 중요한 부분이다.
GDN 또느 비선형성이 강화된 residual block과 같은 컨볼루션 신경망(CNN)의 형태를 가진다.
attention module, non-local networks, invertible structures와 같은 advanced된 컨볼루션 구조도 transform의 모델링 능력 향상을 위해 사용되었다.
각각의 반복에서 네트워크는 latent representations에서 불필요한 비트를 제거한다. 따라서 final representations는 compact해짐.
transform 이후, 압축된 latent representations은 엔트로피 코딩을 통해 추가로 압축되며, 자주 발생하는 패턴은 적은 비트로, 드물게 발생하는 패턴은 많은 비트로 표현된다.
초기 연구에서는 요소별 독립적인 엔트로피 모델을 통합하여 잠재 표현을 추정하고, 각 요소를 arithmetic coder로 독립적으로 인코딩함.
추후 hyperpriors, predictive models, learned parametric models로 발전되어 엔트로피를 명시적으로 추정한다.
이전에 언급한 learned transform coding framework외에도 다른 방법론들이 등장함.
conditional generative adversarial networks (GAN)같은 생성 모델을 사용하여 고효율 이미지 코델을 디자인하는데 활용될 수 있다.
4. BACKBONES FOR IMAGE COMPRESSION
이미지 압축을 위한 일반적인 신경망 백본은 VAE 구조를 기반으로 구축됨. VAE 구조는 이미지를 latent space의 벡터로 인코딩하여 압축된 표현을 생성한다. 차원 축소와 entropy constraints을 통해 이미지 중복성은 compressive transform을 통해 압축된다.
프레임워크의 백본을 위한 다양한 구조가 존재하며, 크게 one-time feed-forward framework와 multistage recurrent framework 범주로 나눌 수 있다.
one-time feed-forward framework의 각 구성요소는 인코딩 및 디코딩 과정에서 feed-forward를 한 번만 수행한다. 일반적으로 인코더와 디코더 네트워크가 rate- distortion trade-off를 결정하기 때문에 다양한 범위의 bit-rate를 커버하도록 여러 모델을 학습시켜야 한다.
이와 달리 multistage recurrent framework에서는 네트워크의 인코딩 구성요소가 original과 residual signals에 대해 반복적으로 압축을 수행하며 반복 횟수에 따라 rate- distortion trade-off가 제어된다.
각 반복은 일정 비트 수로 residual signal 일부를 인코딩한다. 이러한 모델은 자체적으로 variable-bit-rate compression를 수행할 수 있다.
4.1 One-Time Feed-Forward Frameworks
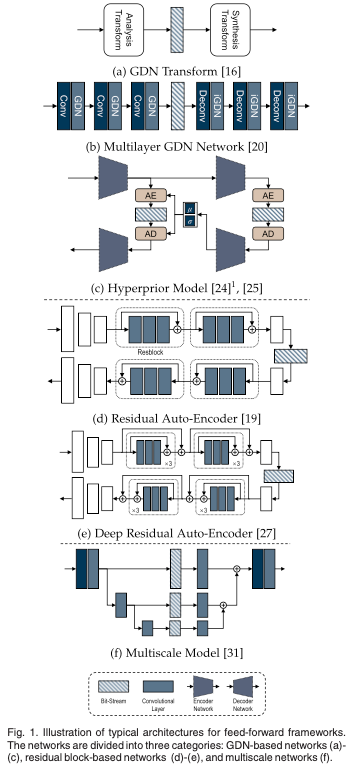
One-time feed-forward framework는 end-to-end learned image compression에서 주로 사용되는 방법이다.
GDN을 사용하면 아키텍쳐를 더 복잡하게 설계하여 압축 성능을 더 높일 수 있지만, Hyperprior보다는 중요도가 낮다고함.
일반적으로 층을 깊에 쌓은 네트워크가 추가적인 향상을 가져올 수 있는 image recognition과 같은 다른 CV task와 달리, learned image compression에서는 모델 복잡하게 확장해도 성능이 크게 향상되지 않는다. 더 깊은 구조는 더 높은 fidelity를 제공하지만, 특히 파이프라인 병목 현상이 심한 경우 얕은 네트워크보다 훈련하기 더 어렵다. 메모리 용량이 충분해도 문제 특성 상 end-to-end optimization process가 local minima에 쉽게 빠질 수 있으므로, 복잡성이 증가해도 성능이 크게 향상되지 않는다고함.
4.2 Multistage Recurrent Frameworks
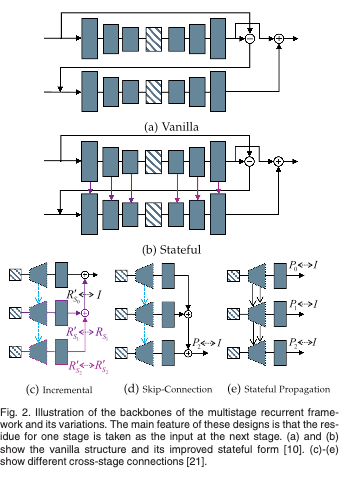
이미지 압축을 위한 Multistage Recurrent Framework의 기본 아키텍처와 변형은 다음과 같다.
최신 연구에선느 Multistage Recurrent Framework보다는 One-Time Feed-Forward Framework를 주로 사용하고 있기 때문에 생략하였습니다.
4.3 Comparative Analysis
두 가지 백본 아키텍처에는 각각 고유한 특성과 그에 따른 장단점이 있다.
- Recurrent model은 variable-rate compression를 자연스럽게 처리할 수 있지만, feed-forward network의 경우 다양한 bit-rates를 지원하도록 네트워크의 여러 인스턴스를 학습시켜야한다.
- Feed-forward network는 상대적으로 더 얕고, 역전파 경로가 훨신 짧다. 이러한 네트워크를 훈련하는 것이 더 쉬울 수 있음. 반면 recurrent model을 훈련하려면 back-propagation through time (BPTT) 기법이 필요하며, 더 복잡함.
- 가중치는 recurrent model의 여러 단계에서 공유되므로 실제 이미지 코덱의 총 파라미터 수는 One-Time Feed-Forward model에 비해 파라미터에 대한 저장 공간이 더 적게 필요할 수 있다. 그러나 residual signal와 image signal은 본질적으로 다르기 때문에 recurrent model의 훈련이 더 어려움.
- 일반적으로 recurrent model은 네트워크가 여러번 실행되기 때문에 이미지를 인코딩하고 디코딩하는데 더 많은 시간이 걸린다.
장단점이 있음에도 불고하고 기존연구에서는 one-time feed-forward architectures에서 더 높은 rate-distortion performance를 보였다.
5. ENTROPY MODELS
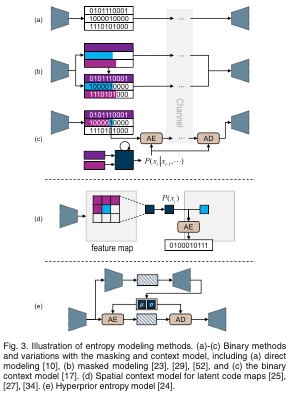
엔트로피 코딩은 이미지 압축 프레임워크에서 중요한 구성요소이다.
정보 이론에 따르면 신호를 인코딩하는 데 필요한 bit-rate는 신호를 나타내는 symbol의 확률분포에 해당하는 정보 엔트로피에 의해 제한된다. 따라서 엔트로피 코딩 구성 요소는 end-to-end learned image compression framework에 내장되어 latent representation의 확률 분포를 추정하고 엔트로피에 constraints를 적용하여 bit-rate를 줄인다.
이상적인 엔트로피 코딩을 위해서는 이미지의 각 인스턴스에 대해 latent representations에 포함된 요소의 joint distribution를 정확하게 추정해야한다.
이전 연구에서는 설계를 단순화하기 위해 이러한 요소들이 독립적으로 분호되어 있다고 가정하였음. 그러나 optimized transform을 사용하더라도 이미지의 latent map에서 spatial redundancy를 제거하기는 여전히 어려움. 따라서 latent code의 중복성을 더욱 줄이기 위해 다양한 엔트로피 모델이 제안되고 있다.
이러한 방법 중에는 주어진 데이터 세트에 대한 통계분석,contextual prediction, 엔트로피 모델링을 위한 hyperprior 활용 등이 있다.
엔트로피 모델을 사용하는 대부분의 작업에서 arithmetic coding을 사용하여 latent representation의 기호를 실질적으로 무손실 인코딩(losslessly encode)한다.
기존의 하이브리드 프레임워크(전통적인 방법)에서 엔트로피 모델의 개선이 엔트로피 코딩 성능에만 영향을 미쳤다. 학습을 통한 방법(딥러닝)의 경우 모든 구성요소가 공동으로 최적화되므로 엔트로피 모델을 더 잘 설계하면 엔트로피를 더 정확하게 추정할 수 있을 뿐 아니라 분석 변환에 의해 생성되는 패턴도 변경된다. 따라서 엔트로피 모델을 설계할 때는 파이프라인에 있는 다른 구성요소의 구조도 고려해야 한다.
섹션 6 이후는 제안 모델이어서 생략하였음
이 논문에서는 기존의 학습된 이미지 압축 방법에 대한 벤치마크를 한 논문이다.
기존에 진행했던 연구들에 대해 요약해준 논문이었다.
