[Foundation] Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications 리뷰
Foundation Model
논문 제목
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse
Operator for Vision Applications (CVPR 2024)
URL: https://arxiv.org/abs/2401.06197
Github : https://github.com/OpenGVLab/DCNv4
인용수 : 110회 (25.7.2 기준)
저번 논문 리뷰는 DCNv3였고, 이번에는 동일 저자분께서 아키텍쳐의 디테일적인 부분과 GPU 최적화를 통해 성능과 속도를 모두 향상시킨 DCNv4를 제안하였습니다. 실제로 사용해보는데 Swin Transformer Block (WMSA), DCNv3 보다 메모리도 적게먹고 속도도 꽤 빨랐습니다.
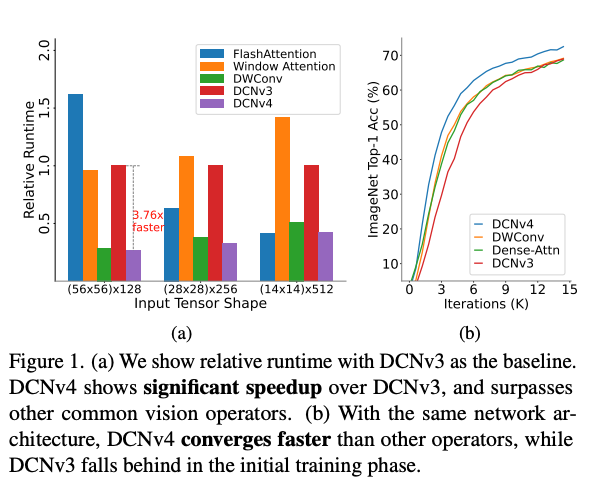
Abstract
- DCNv4는 광범위한 시각 과제에 대해 매우 효율적이고 효과적인 연산자로 설계되었으며,
이전 버전인 DCNv3의 한계를 다음의 두 가지 핵심 개선(softmax 정규화를 제거, 메모리 접근 최적화)을 통해 극복함. - DCNv4는 DCNv3 대비 훨씬 빠르게 수렴하며 연산 속도도 크게 증가하였고, forward 연산만 기준으로 DCNv3보다 3배 이상의 처리 속도를 달성하였음.
Related Work
Core operators in vision models
생략 - DCNv3 내용과 동일
Memory access cost (MAC) in vision backbones
FLOPs는 모델 복잡성을 측정하는 데 자주 사용되는 지표임에도 불구하고 모델의 속도 또는 지연 시간을 정확하게 나타내지 못함. 실제 시나리오에서 모델의 실행 속도는 FLOPs뿐만 아니라 여러 요인의 영향을 받음. 이러한 맥락에서 메모리 접근 비용(MAC)은 특히 중요한 역할을 함.
Flash-Attention 은 고대역폭 메모리(HBM)에 대한 접근 횟수를 줄임으로써 바닐라 어텐션에 비해 FLOPs가 더 높음에도 불구하고 실제로는 훨씬 더 빠른 속도를 달성함. DCN 연산자는 FLOPs 측면에서 불리함을 보이지 않지만 동일한 FLOPs에서 DWConv에 비해 대폭적인 메모리 접근 비용으로 인해 지연 시간이 상당히 길게 나타남.
본 연구에서는 DCN 연산자와 관련된 메모리 접근 비용에 대한 철저한 분석 및 최적화를 수행하여 DCN의 실행 속도를 크게 가속화했다함.
Method

Rethinking the Dynamic Property in Deformable Convolution
DCNv3의 수식은 아래와 같음.
여기서 G는 공간 집계 그룹의 수를 나타냅니다 . g번째 그룹에 대해, (C′=C/G)는 그룹 차원을 나타내는 슬라이스된 입력/출력 특징 맵을 나타낸다.
는 g번째 그룹의 k번째 샘플링 포인트에 대한 공간 집계 가중치(모듈레이션 스칼라라고도 함)를 나타내며 입력 x에 따라 조건화되고 K 차원을 따라 소프트맥스 함수에 의해 정규화됨.
는 일반 컨볼루션에서와 같이 과 같이 사전 정의된 그리드 샘플링의 k번째 위치를 나타내며, 는 g번째 그룹의 그리드 샘플링 위치 에 해당하는 오프셋임.
Softmax normalization
컨볼루션과 DCNv3의 주요 차이점은 DCNv3가 scaled dot-product self-attention의 관례에 따라 소프트맥스 함수로 공간 집계 가중치 m을 정규화한다는 것이다. 반대로, 컨볼루션은 가중치에 소프트맥스를 사용하지 않고도 잘 작동함. 어텐션이 소프트맥스를 필요로 하는 이유는 간단하다. 를 사용하는 scaled dot-product self-attention은 다음 공식으로 정의됨.
여기서 N은 동일한 어텐션 윈도우 내의 포인트 수이고, d는 은닉 차원이며, Q, K, V는 입력으로부터 계산된 쿼리, 키, 값 행렬임. 어텐션에는 위 식에서 소프트맥스 연산이 필요로함.
소프트맥스가 없으면 가 먼저 계산될 수 있으며, 이는 동일한 어텐션 윈도우의 모든 쿼리에 대한 선형 투영으로 저하되어 성능이 저하됨.
그러나 DWConv 및 DCNv3와 같은 컨볼루션 연산자의 경우 각 포인트가 자체 aggregation window를 가지고 있으며 각 집계 윈도우의 값은 이미 다르므로 "키" 개념이 없기 때문에 이러한 성능 저하 문제는 더 이상 존재하지 않으며 정규화는 불필요함.
소프트맥스를 사용하여 컨볼루션 가중치를 고정된 0-1 범위로 정규화하는 것은 연산자의 표현력에 상당한 제약을 가하고 학습을 느리게 할 수 있음.
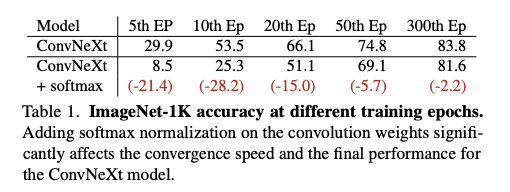
위 표에서 DWConv 7x7 윈도우에 소프트맥스를 적용했음. 결과에서 모델 성능과 수렴 속도가 현저하게 감소하는 것을 확인.
이는 컨볼루션 또는 DCN과 같이 각 위치에 전용 집계 윈도우를 가진 연산자의 경우 무한한 범위를 가진 aggregation weights가 소프트맥스 정규화된 bounded-range weights보다 더 나은 표현력을 제공한다는 것을 시사한다.
Enhancing dynamic property
위 실험을 통해 DCNv3에서 소프트맥스 정규화를 제거하여 변조 스칼라의 범위를 0에서 1까지에서 컨볼루션과 유사한 무한한 동적 가중치로 변경을 진행. 이러한 변경은 DCN의 동적 속성을 더욱 증폭시고 학습 과정에서 훨씬 빨리 수렴한다고함.
Speeding up DCN
이론적으로 DCN은 3×3 윈도우를 가진 sparse operator이므로, dense attention 또는 7×7 DWConv과 같이 더 큰 윈도우 크기를 사용하는 다른 일반적인 연산자보다 빠르게 작동해야 함. 그러나 실제로는 그렇지 않음을 발견했다고 한다.
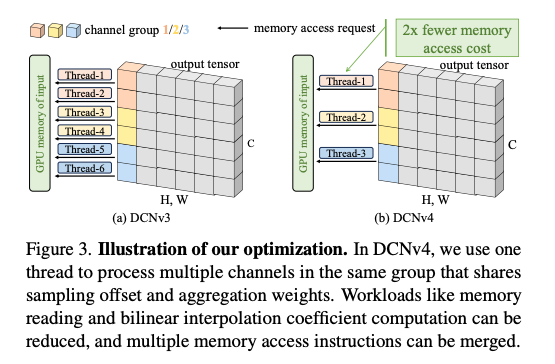
Eliminating redundant workload
CUDA DCN 커널 구현에서는 (H,W,C) 형태의 입력에 대해 오프셋 및 집계 가중치 를 사용하여 전체 H×W×C 스레드를 생성하여 병렬성을 극대화했습니다. 여기서 각 스레드는 하나의 출력 위치에 대해 하나의 채널을 처리함.
특히, 각 그룹 내의 D=C/G 채널은 각 출력 위치에 대해 동일한 샘플링 오프셋 및 집계 가중치 값을 공유함. 동일한 출력 위치에서 D개 채널을 처리하기 위해 여러 스레드를 사용하는 것은 낭비라고함.
왜냐하면 다른 스레드가 동일한 샘플링 오프셋 및 집계 가중치 값을 GPU 메모리에서 여러 번 읽을 것이기 때문이다. 이는 메모리 바운드 연산자에게 중요하다고함. 각 출력 위치에서 동일한 그룹 내의 여러 채널을 하나의 스레드로 처리하게되면 이러한 중복 메모리 읽기 요청을 제거하여 메모리 대역폭 사용량을 크게 줄일 수 있다고한다.
Eliminating redundant memory instructions
DCNv3 구현의 경우, 각 스레드가 하나의 채널을 처리하도록 설계되어 있어, 여러 스레드가 동일한 샘플링 오프셋 및 집계 가중치 값을 GPU 메모리에서 여러 번 읽는 비효율이 발생. 이는 메모리 바운드(memory-bound) 연산자에게 특히 문제가 됨.
DCNv4에서는 이 문제를 해결하기 위해 다음과 같은 방법을 사용.
- 스레드당 여러 채널 처리
- Vectorized Load/Store
- Half-precision Data Format
최적화 결과 DCNv4는 DCNv3에 비해 3배 이상 효율적인 성능을 달성.
Micro design in DCN module
DCNv4는 속도와 성능을 더욱 향상시키기 위해 DCNv3 모듈의 마이크로 디자인에도 개선 사항을 적용. 핵심 커널이 최적화됨에 따라, 이러한 미세한 디자인 변경이 전체 속도에 미치는 영향이 커졌기 때문.
Linear 레이어 통합 및 불필요한 레이어 제거
DCNv3에서 오프셋(offset)과 동적 가중치(dynamic weights)를 계산하는 데 사용되던 두 개의 선형 레이어를 하나로 결합했습니다. 또한, 오프셋/집계 가중치 계산에 사용되던 비용이 많이 드는 Layer Normalization 및 GELU 활성화 함수를 제거.
이를 통해 network fragmentation를 줄이고 커널 시작 및 동기화와 같은 추가 오버헤드를 제거하여 GPU의 실행 시간 효율성을 향상시킨다고함.
Experiments
제안된 DCNv4 모듈의 속도 및 성능 관점에서 효과를 검증했으며 모든 속도 테스트 결과는 NVIDIA A100 80G SXM GPU에서 얻어졌다고한다. 모델명은 FlashInternImage로 명명.
Speed Benchmark for Operators
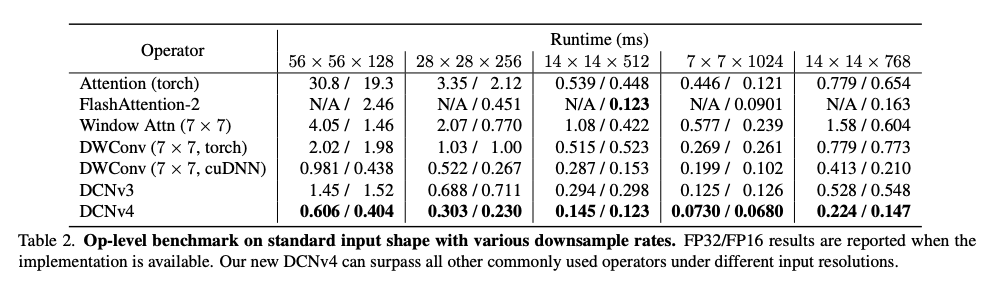
DCNv4는 DCNv3에 비해 3배 이상의 속도 향상을 제공하여 실행 시간을 크게 절약함.DCNv4는 3×3 sparse window를 사용하는 이점을 성공적으로 활용하여 다양한 설정에서 다른 기준선보다 훨씬 빠르게 작동.
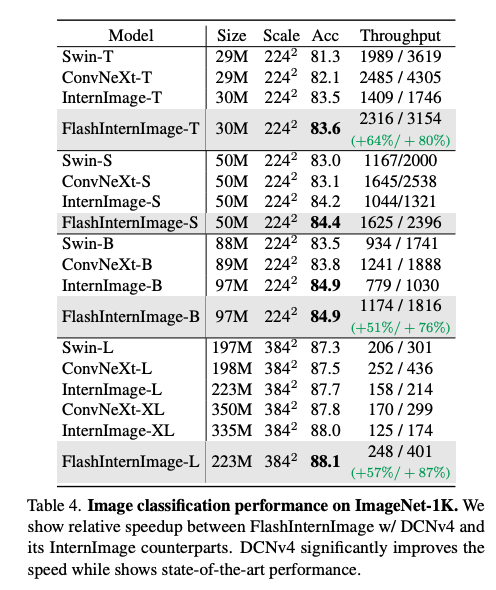
Image Classificatation
Downstream Tasks with High-Resolution Input
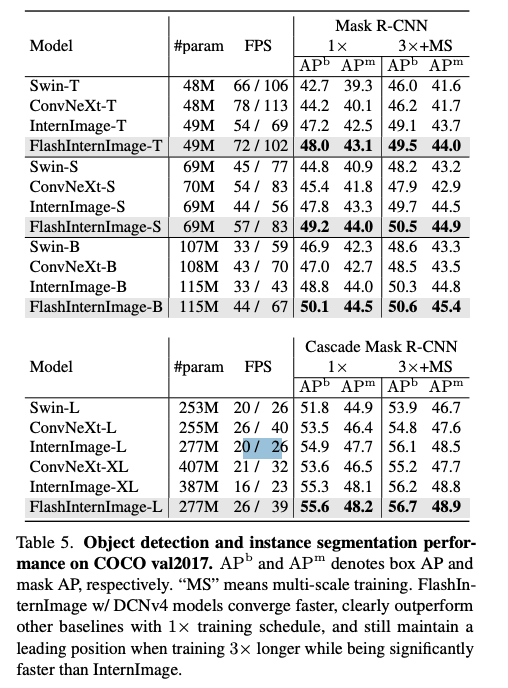
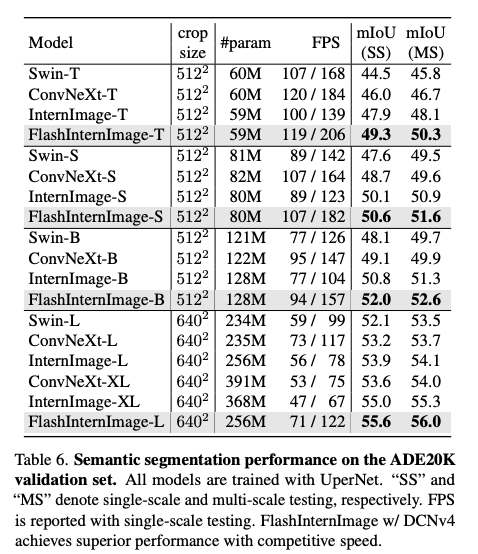
여러 다운스트림 태스크에서 기존 DCNv3기반의 InternImag보다 파라미터는 작지만 성능은 향상된 것을 확인할 수 있다.
DCNv4 as a Universal Operator
DCNv4가 ConvNeXt 및 ViT와 같은 다른 연산자로 설계된 아키텍처에서도 잘 작동하는지 확인했다고함.
이를 위해 ViT 및 ConvNeXt에서 어텐션 모듈과 DWConv 레이어를 DCNv4로 대체하고 FlashInternImage 및 InternImage와 유사하게 다른 아키텍처 및 하이퍼파라미터를 변경하지 않고 ImageNet-1K에서 지도 학습을 진행했다고한다.
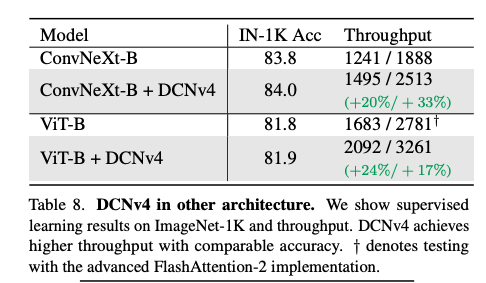
DCNv4의 빠른 속도 덕분에 새 모델은 더 나은 처리량을 달성할 수 있으며 DCNv4의 우수한 성능을 보여줌.
Conclusion
- 본 연구는 효율적인 동적 희소 연산자인 DCNv4를 제안. 변형 가능한 컨볼루션의 동적 속성과 메모리 접근을 효율화함으로써 이전 버전인 DCNv3보다 훨씬 빠르고 효과적인 연산자임을 시사.
- DCNv4를 탑재한 FlashInternImage 백본은 속도를 향상시킬 뿐만 아니라 다양한 비전 작업 전반에 걸쳐 성능을 개선
- DCNv4를 ConvNeXt 및 ViT와 같은 최첨단 아키텍처에 통합하여 처리량 및 정확도 측면에서 향상된 결과를 보여줌으로써 범용 연산자로서의 다용도성과 효과를 입증.
