[Day5] 2021/08/27
강의리뷰
이미지 분류 9강: Ensemble
- 앙상블: 싱글 모델보다 더 나은 성능을 위해 서로 다른 학습모델들을 사용하는 법.
- Low biasm High Variance는 Overfitting의 경향이 생긴다.
- 앙상블의 효과는 각각의 모델이 특성을 보일때 시도할 수 있다.
- Model Averaging(Voting)은 앙상블의 다른 의미.
- Cross Validation: 검증셋을 활용하여 학습
- Stratified K-Fold Cross Validation: 가능한 경우를 모두 고려 + split시에 class 분포까지 고려
- TAA(Test Time Augmentation) : 테스트할 때 Augmentation을 진행 후 결과를 앙상블
이미지 분류 10강: Experiment Toolkits & Tips
- Training Visualization은 Tensorboard와 wandb를 많이 사용한다.
- EDA는 Jupyter Notebook, 디버깅과 모델 구현은 Python IDLE.
이미지분류 대회 준비
- EfficientNetb3 (pretrained, NUM_EPOCH = 30, BATCH_SIZE = 32, LEARNING_RATE = 0.002) : Epoch30 - Loss: 0.018, Acc: 0.994, F1: 0.9892 -> 제출 결과- ACC: 74.9841% F1: 0.6824
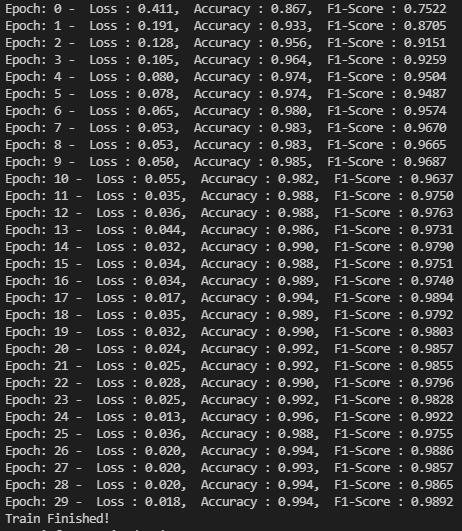
- EfficientNetb3 + MCNN을 통한 crop 후 데이터 (pretrained, NUM_EPOCH = 30, BATCH_SIZE = 32, LEARNING_RATE = 0.002)
-> 제출 결과- ACC: 73.6349% F1: 0.6371
피어세션
- 주말 계획: Efficient net 더 연구해봐야할듯. (face crop 후 성능이 좋아지는지 확인하겠다.)
Q. (본인) Data imbalance 문제를 어떻게 해결했나요?
A. (캠퍼) 데이터가 3000장이 넘으면 3000장으로 자르고, 3000장이 안되면 3000장이 되도록 복사했다. 또한, 모든 사진을 224*224로 resize했다. (하지만, test set의 이미지 크기를 모르기에 불안하다.)
Q. (본인) Data Balance를 맞춘 거랑 맞추지 않은 거랑 차이가 있는가?
A. (캠퍼) Data distribution 외에도 다양한 변수를 수정했기 때문에, data balance만의 효과인지는 알 수 없다. 그러나 다른 분들은 이를 맞추지 않아도 잘 되었기 때문에 내 방법이 효과적인지는 모르겠다.
마무리
요즘 잠을 못자며 계속 이런 저런 연구와 시도를 해보는 중인데, 결과가 이상적이지 못해 조금 속상하다. 그래도 계속 새로운 방법을 연구할 계획이다. 주말부터는 모델 실험이외에 데이터 증강과 전처리에 대해 조사해보고 시도해야겠다. 또, 너무 순위에 집착하지 않고 공부한다는 느낌으로 해봐야겠다.
아, 그리고 이제 적응기간은 끝난것 같다. 슬슬 더 적극적으로 열심히 해봐야겠다 화이팅!

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)