2014년 발표된 vgg 논문을 읽고 정리한 글입니다.
1. Introduction
합성곱 신경망(convolutional networks)이 컴퓨터 비전 영역에서 더욱 유용한 도구가 되어가는 동시에 수많은 시도들을 통해 기존 아키텍처(AlexNet)를 개선해 왔습니다.
예를 들면 ILSVRC-2013에서 가장 좋은 성능을 낸 모델은 작은 크기의 receptive window를 사용하고 작은 stride를 사용하였습니다.
논문에 저자들은 합성곱 신경망 구조의 중요한 측면중 하나인 깊이(depth)를 다룹니다.
이를위해 모델 구조의 다른 파라미터들은 고정시키고 합성곱 층을 꾸준히(steadily) 추가하며 네트워크의 깊이(depth)를 증가시켰습니다.
깊이를 증가시키기 위해 논문에서는 3x3 크기의 작은 필터를 모든 레이어에서 사용하였습니다.
그 결과 저자들은 ILSVRC classification / localisation 문제에서 SOTA를 달성할 뿐 아니라 다른 이미지 인식 데이터셋에 적용될수 있는 더욱 정확한 합성곱 신경망 구조를 제안합니다.
2. ConvNet Configurations
모델의 깊이(depth)를 증가시킴으로써 얻는 개선점을 측정하기 위해서 AlexNet에서 영감을 받은 같은 원리를 합성곱 신경망을 디자인하는데 사용하였습니다.
2.1 Architecture
훈련을 진행하는동안 모델의 입력은 224x224 크기로 고정된 RGB 이미지로 주어지고 저자들이 사용한 유일한 pre-processing은 각각의 픽셀에 대하여 RGB의 평균값을 빼는 방법을 사용하였습니다.
저자들은 3x3 크기의 작은 필터를 사용하는 동시에 1x1 합성곱 필터 또한 사용하였습니다.
그리고 stride를 1로 고정시키고 합성곱 층의 공간적 패딩(spatial padding)은 합성곱 연산을 수행한 이후에도 공간적 해상도(spatial resolution)를 보존시키기 위해서 사용합니다.
예를들면 3x3 합성곱 연산시 1픽셀의 패딩이,
1x1 합성곱 연산시 패딩을 사용하지 않습니다.
공간적 풀링은 다섯개의 max-pooling 층에 의해 수행됩니다.
max-pooling은 2x2 pixel window와 2 stride로 수행됩니다.
합성곱 층의 연산을 모두 수행하고 나면 뒤이어 세개의 완전 연결층(Fully_Connected layers)의 연산을 수행합니다.
완전 연결층은 순서대로 4096-4096-1000 개의 채널을 가집니다.
(마지막 층은 softmax layer 입니다.)
모든 은닉층은 ReLU 활성화 함수를 가지고 있습니다.
논문의 모델 구조는 AlexNet에서 영감을 받았다고 했었는데 본 논문에서는 Local Response Normalisation을 사용하지 않았습니다. 저자들은 LRN을 사용함으로써 memory consumtion, computation time이 증가하는 반면 ILSVRC 데이터셋에서 성능개선이 이루어지지 못했다고 주장합니다.
2.2 Configurations
본 논문의 모델 구조는 Table 1에 나타나 있습니다.
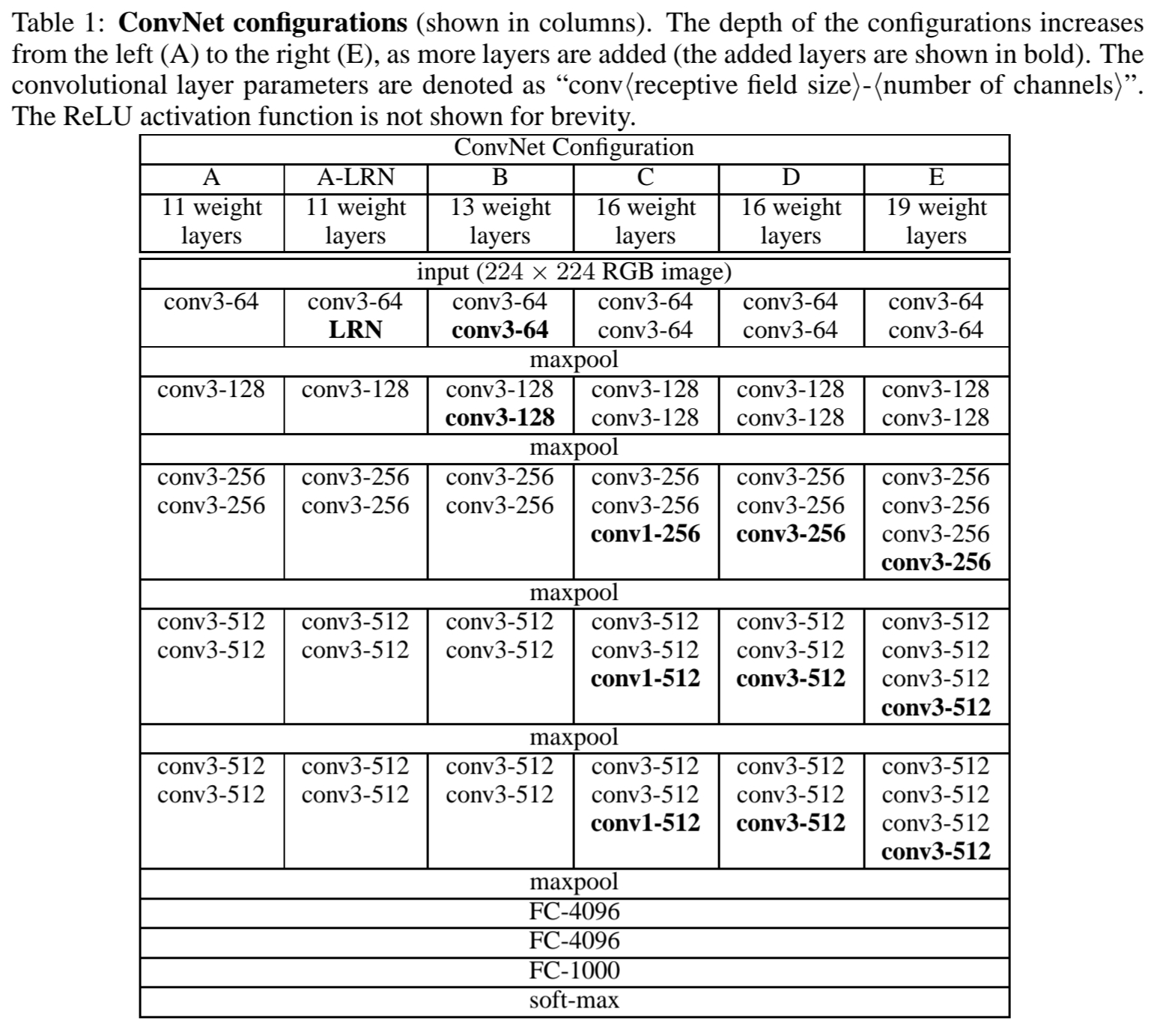
A-E까지 6개의 모델 구조는 2.1에서 설명한 구조를 따르고 오직 깊이(depth)만 다릅니다.
2.3 Discussion
논문에서는 3x3 크기의 매우 작은 커널을 사용하였는데 두개의 3x3 커널을 쌓으면(pooling 없이) 5x5 크기의 커널을 사용하는것과 같은 효과를 가진다고 볼 수 있다고 주장합니다. (마찬가지로 세개의 3x3 커널을 쌓으면 7x7 크기의 커널을 사용하는것과 같은 효과를 가질수 있다함)
저자들은 7x7커널을 사용하는 대신에 3x3 커널을 쌓으면 다음 두가지 효과를 얻을 수 있다고 주장합니다.
- 모델의 구별 능력이 향상됩니다. (decision function more discriminative)
- 파라미터의 개수를 줄일 수 있습니다.
Section 3(details of training and evaluation)
Section 4(configurations are compared)
이 두가지 섹션은 따로 정리하지 않고 Section 4에 모델 구조에 따른 성능만 참고하겠습니다.
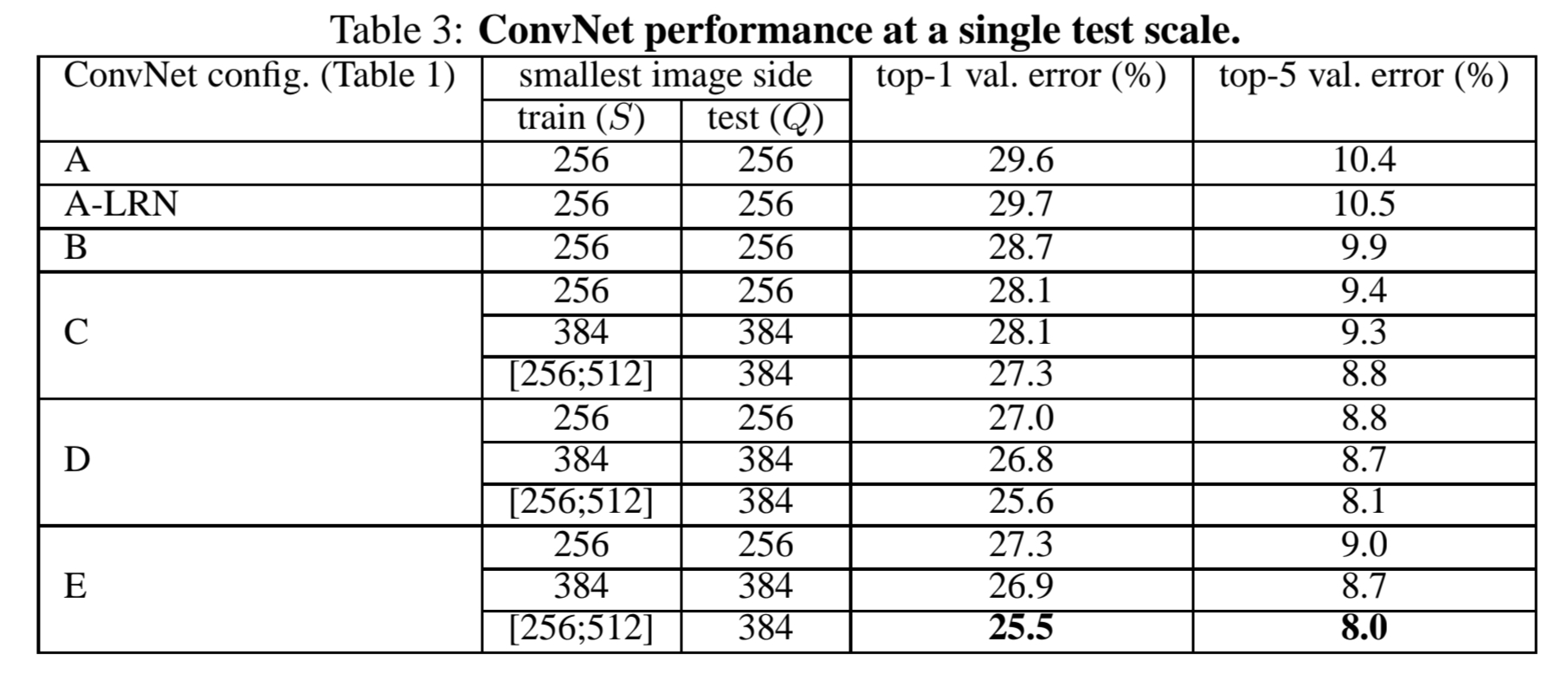
모델의 깊이(depth)가 증가함에 따라 top-1 / top-5 에러 비율이 감소함을 확인할 수 있습니다.
5. Conclusion
본 연구에서는 모델의 깊이(representation depth)가 분류(classification) 정확도에 유익함을 보였고 합성곱 신경망을 사용하여 ImageNet 데이터셋에서 SOTA 성능을 달성할수 있음을 보였습니다.
Pytorch Implementation
논문에선 normalisation layer를 사용하지 않았기 때문에 저또한 사용하지 않았습니다.
아래 코드는 pytorch를 사용한 VGG 입니다.
import torch
import torch.nn
class VGG16(nn.Module):
def __init__(self, num_classes=1000, dropout=0.5):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(7*7*512, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x훈련 코드는 이전 AlexNet 글을 참고하시기 바랍니다.
