최근 이직을 하고 회사에서 쓰고 있는 기술스텍인 "Apache Kafka"에 대한 교육을 듣고 왔다. 교육을 듣기와 동시에 정리한 내용을 그대로 가져왔기에 엉성하게 보일수도😒
Kafka

🍞 Kafka란?
LinkedIn에서 개발된 분산환경에 특화된 분산 메시징 시스템으로 Pub-Sub 모델의 메시지 큐
🍞 구성 요소
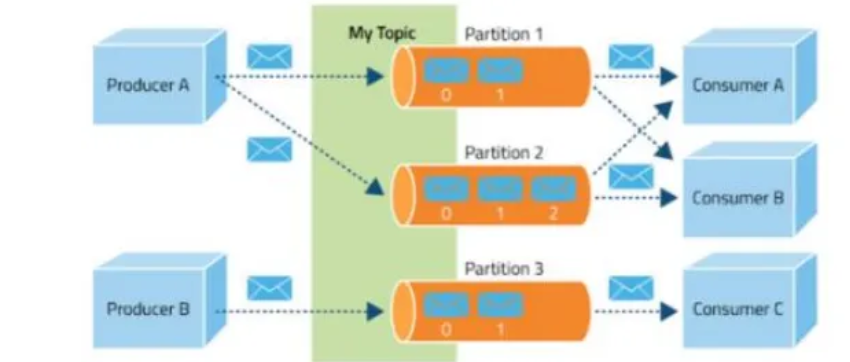
- Event
- kafka에서 Producer와 Consumer가 데이터를 주고 받는 단위
- Producer
- kafka에 이벤트를 게시(post)하는 클라이언트 어플리케이션
- Consumer
- Topic을 구독하고 이로부터 얻어낸 이벤트를 처리하는 클라이언트 어플리케이션
- Topic – Partition
- Topic : 이벤트가 모이는 곳. producer는 topic에 이벤트를 게시하고, consumer는 topic을 구독해 이로부터 이벤트를 가져와 처리하는 게시판 같은 개념
- Partition : topic은 여러 Broker에 분산되어 저장되며, 이렇게 분산된 topic을 partition이라고 함
- Zookeeper
- 분산 메시징 큐를 위한 분산 cordinator
🍞 주요 개념
- Producer와 Consumer 분리
- Producer는 Broker의 Topic에 메시지를 게시하기만 하면 되며, Consumer는 Broker의 특정 Topic에서 메시지를 가져와 처리를 하기만 하면 됨(이 덕분에 높은 확장성 제공)
- Push / Pull
- Producer는 Broker에게 push, Consumer는 Broker로부터 pull
- 다양한 소비자의 처리 형태와 속도를 고려하지 않아도 됨
- 불필요한 지연 없이 일괄처리를 통해 성능향상 도모
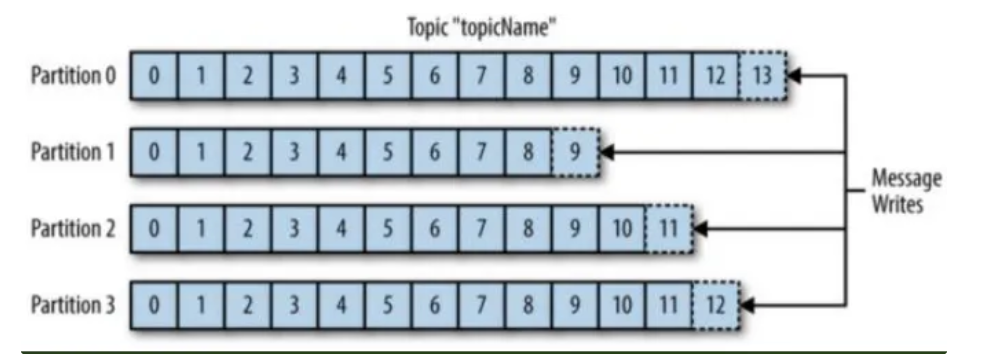
- 소비된 메시지 추적 (Commit과 Offset)
- Offset : 각 파티션 내에서 메시지의 위치를 나타내는 고유한 식별자로 Consumer가 메시지를 읽을 때마다 해당 메시지의 Offset을 저장하고, 다음에 읽을 때 이 Offset을 기반으로 메시지를 가져옴
- Commit : Consumer가 읽은 마지막 Offset을 저장하는 과정으로 Commit을 통해 Consumer가 중단된 후에도 이전에 읽은 위치에서 메시지를 다시 가져올 수 있음
=====
- Cluster
- 여러 대의 서버(브로커)로 구성된 Kafka 시스템이다. 클러스터는 대량의 데이터를 처리하고, 여러 소비자(Consumer)와 생산자(Producer)에게 메시지 서비스를 제공
- 클러스터는 메시지의 저장, 처리 및 전달을 담당한다. 클러스터는 고가용성과 확장성을 제공하며, 데이터를 여러 브로커에분산시켜 저장
- Broker
- Kafka 시스템을 구성하는 개별 서버
- 데이터 저장 및 관리
- 각 브로커는 Kafka 토픽의 하나 이상의 파티션을 저장하고 관리한다. 이 파티션들에는 메시지 또는 레코드가 순차적으로 저장된다.
- 클라이언트 요청 처리
- 브로커는 Kafka 생산자(Producer)로부터 데이터를 받아 저장하고, 소비자(Consumer)의 요청에 따라 저장된 데이터를 제공한다.
- 고가용성 및 확장성
- Kafka는 데이터의 안정성을 위해 파티션을 여러 브로커에 복제한다. 이를 통해, 하나의 브로커에 장애가 발생해도 시스템은 계속 작동할 수 있다. 그리고 필요시 클러스터에 새로운 브로커를 추가하여 시스템의 처리 능력과 저장 용량을 확장할 수 있다.
- 리더와 팔로워
- 각 파티션에는 '리더'와 '팔로워' 브로커가 있다. 리더 브로커는 모든 읽기 및 쓰기 작업을 처리하고, 팔로워 브로커는 리더의 데이터를복제한다. 이러한 구조는 데이터의 일관성을 유지하고, 부하를 분산시키는 데 도움이 된다.
- 통신 및 조정
- 브로커들은 클러스터 내에서 서로 통신하여 데이터의 동기화와 상태 정보를 공유한다. 이를 통해 클러스터 전체가 일관된 상태를 유지하고, 효율적으로 작동할 수 있다.
- Kafka 브로커는 Kafka 시스템의 중추적인 역할을 하며, 데이터의 저장, 처리 및 전송을 담당한다. 브로커들의 상호작용과 조정을 통해 Kafka는 대용량의 데이터를 효율적이고 안정적으로 관리할 수 있다.
=====
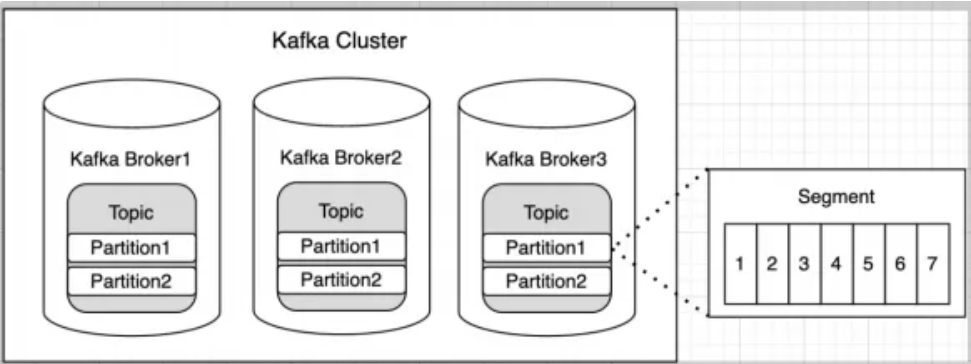
- Topic
- Producer와 Consumer가 사용하는 기본적인 데이터 저장 단위
- Partition
- Topic을 구성하는 하위 단위
- 하나의 토픽은 여러 개의 파티션으로 나누어질 수 있으며, 이는 Kafka의 확장성과 병렬 처리 능력을 향상시킬 수 있음
- 데이터 분산 및 병렬 처리 : 각 파티션은 독립적으로 데이터를 저장하고, 여러 브로커에 걸쳐 분산될 수 있다. 이를 통해 Kafka는 데이터를 효율적으로 관리하고, 동시에 여러 소비자에게 서비스할 수 있다.
- 순차적 데이터 관리 : 각 파티션 내에서 메시지는 순차적으로 저장되며, 이 순서는 파티션 내에서 유지된다. 이는 데이터의 일관성과 정확한 순서 보장에 중요하다.
- 스케일 아웃 : 시스템의 부하가 증가할 때, 더 많은 파티션을 추가하여 처리 능력을 확장할 수 있다.
- Segment
- 파티션의 데이터를 실제로 저장하는 물리적인 파일
- kafka는 데이터를 파티션에 순차적으로 기록하지만, 이 데이터는 여러 세그먼트 파일로 나누어 저장
- 데이터 저장 단위 : 세그먼트는 Kafka 파티션 내의 데이터를 저장하는 기본 단위다. 각 세그먼트 파일은 일정 크기에 도달하거나 특정 시간이 경과하면 새로운 세그먼트 파일로 전환된다.
- 효율적인 데이터 관리 : 세그먼트 기반의 데이터 관리는 Kafka가 불필요한 데이터를 효율적으로 정리하고, 디스크 공간을 최적화하는 데 도움을 준다.
- 로그 컴팩션 및 삭제 : Kafka는 설정에 따라 오래된 세그먼트 파일을 삭제하거나 로그를 컴팩션(중복 제거)하는 방식으로 데이터를 관리한다. 이는 저장 공간을 절약하고 시스템의 성능을 유지하는 데 중요하다.
=====
- MOM 비교표
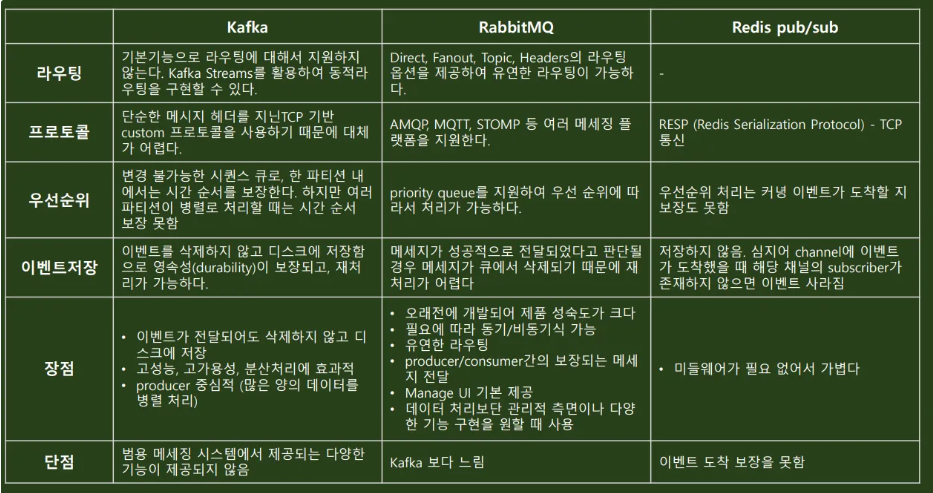
- 카프카 입맛대로 정리
- Kafka는 라우팅 개념이 존재하지 않는다(다만 kafka streams로 동적 구현은 가능)
- TCP 기반 텍스트 형태의 커스텀 프로토콜(단, 플러그인을 통한 추가 구현은 가능하다)
- 단순 시퀀스(선입선출의 형태, 우선순위 X)
- 이벤트를 삭제하지 않고 디스크에 전부 저장함으로 그를 통한 재처리가 가능
🍞 Kafka - Partition

-
별도 설정 없이 사용
- 1개의 파티션만 사용됨
- 만약 여러 개의 consumer가 동일한 토픽에 메시지를 요구하면? 하나의 consumer만 메시지 사용 가능
-
Kafka의 로드 밸런싱 단위는 “Partition”
- Consumer Group 내에서 각 파티션은 오직 하나의 consumer에게만 할당 가능
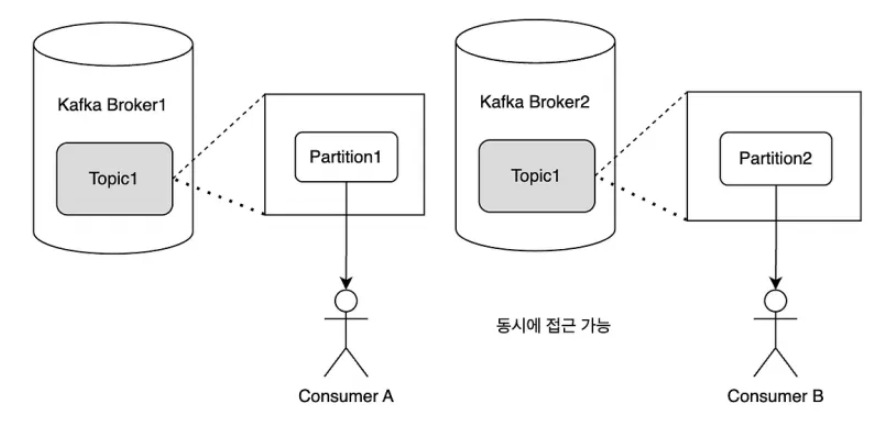
-
Partitioning
- 특정 topic을 subscribe하는 consumer는 이 중 하나 이상의 Partition에 할당하여 메세지를 소비한다.
- 단, 하나의 Partition에는 동일한 Consumer Group에서 반드시 하나의 Consumer만 할당이 된다.
(Partition : Consumer = N : 1 관계)
-
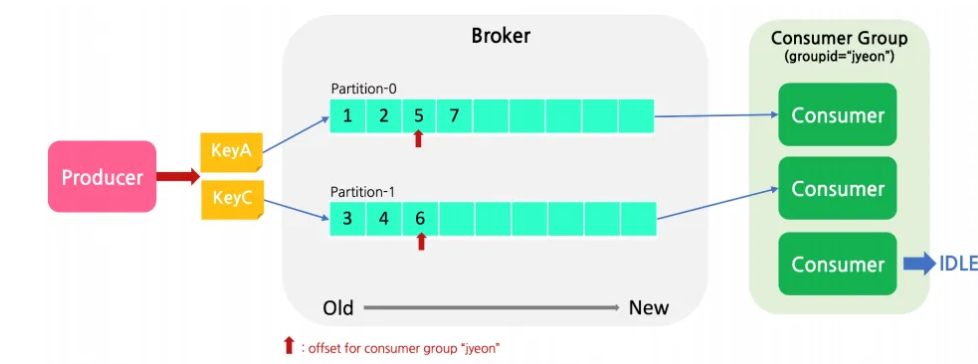
Offset
- partition이 여러 개일 경우 producer가 보낸 메세지의 순서는 보장될 수 없지만, 각 partition 안에서의 메세지를 순서가 보장된다.
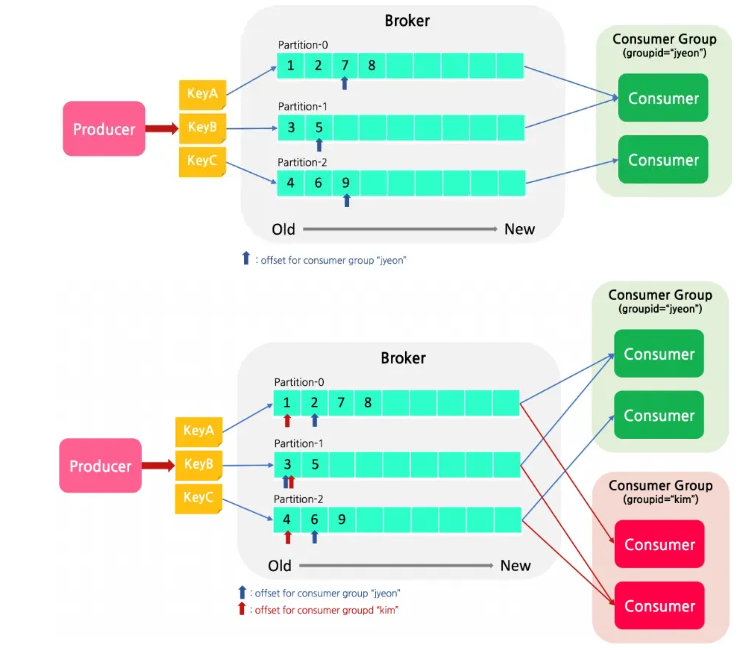
- 하나의 Topic에 여러 Consumer Group이 붙어 메세지를 가져갈 수 있다.
- 각 consumer group마다 해당 topic의 partition에 대한 별도의 offset을 관리하고, group에 컨슈머가 추가/제거 될 때마다 rebalancing을 하여 group 내의 consumer에 partition을 할당한다.
- partition이 여러 개일 경우 producer가 보낸 메세지의 순서는 보장될 수 없지만, 각 partition 안에서의 메세지를 순서가 보장된다.
-
Commit
- Commit이 되는 시점에 offset이 갱신됨
- 종류
- 수동 commit
- 메시지 처리가 완전히 완료되기 전까지 메세지를 가져온 것으로 간주되면 안되는 경우 사용
- 작업을 처리하다가 에러가 나는 경우 중복이 발생할 수 있음
- 자동 commit
- 컨슈머 옵션 중 enable.auto.commit을 true로 설정해주어야 함
- 이 경우, 컨슈머에서 poll()을 호출할 때
auto.commit.interval.ms(default: 5s)이 지났는지를 확인하고, 커밋할 때가 되었으면 가장 마지
막 offset을 commit 함 - 주의할 점은 commit 이후 아직 메시지의 처리가 끝나지 못한 상태에서 컨슈머에 장애가 발생하면 해당 메시지는 손실될 수 있음
- 수동 commit
-
Kafka 미세팁
- Consumer Health Check & Rebalance
- Consumer는 자신이 살아있다는 것(Partition에 대한 소유권을 주장)을 그룹 코디네이터에게 알려주기 위해
heartbeat.interval.ms(default: 3s) 주기로 heartbeat를 보냄 session.timeout.ms(default: 10s) 에 설정된 시간이 지나도록 특정 consumer가 heartbeat를 보내지 않으면, 해당 컨슈머는 종료되었거나 무언가 문제가 생긴 것으로 인지하고 컨슈머 그룹은 rebalance를 시도session.timeout.ms가 짧은 경우 장애를 빨리 인지할 수 있지만, 너무 짧게 설정된 경우 Full GC가 오래걸리는 경우 등의 이유로 원치 않은 rebalance가 일어날 수도 있음- consumer가 heartbeat만 보내고 실제로 topic에서 메세지를 가져가지 않는 경우가 생길 수도 있다. 이 경우, 코디네이터는 해당 consumer를 정상 상태로 인지하기 때문에 consumer는 계속 partition을 점유하고 있지만, 해당 partition에서 메세지는 하나도 consuming이 되지 못하는 상태가 됨 → 컨슈머가 heartbeat를 보내더라도,
max.poll.interval.ms(default:
300000ms) 내에 poll()을 호출하지 않으면 해당 컨슈머를 그룹에서 제외하고 다른 컨슈머에서 해당 파티션에서 메세지를 컨슈밍 할 수 있도록 rebalance 함
- Consumer는 자신이 살아있다는 것(Partition에 대한 소유권을 주장)을 그룹 코디네이터에게 알려주기 위해
- Consumer Health Check & Rebalance
🍞 Zookeeper - coordinator
- 분산 코디네이션 서비스를 제공하는 오픈소스
- Leader – Follower 아키텍쳐
- 직접 애플리케이션 작업을 조율하지 않고 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구
- Request Processor : Write 요청 처리
- Zab(Zookeeper Atomic Broadcast Protocol) : Request Processor에서 처리한 요청을 트랜잭션을 생성하여 모든 서버에게 전파
- Leader-Propose -> Follower-Accept -> leader-Commit 단계로 구성
- In-memory DB : Znode의 정보가 저장되며, 로컬 파일시스템에 Replication을 구성할 수 있음
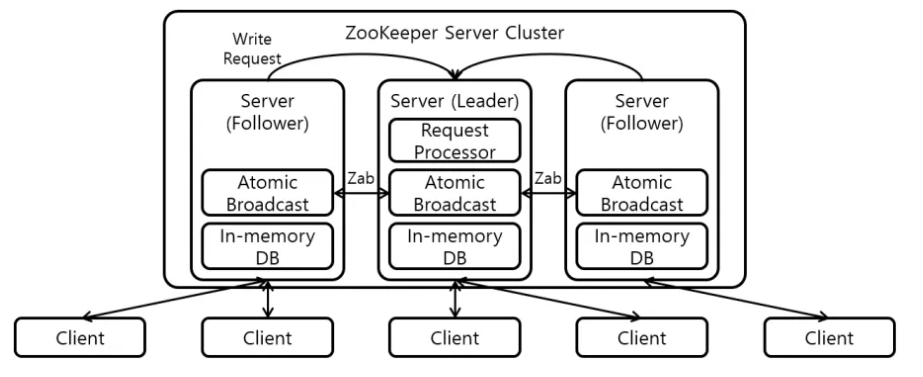
클러스터는 홀수(3, 5, …)로 구축 어떤 서버에 문제가 생겼을 경우 과반수 이상의 데이터를 기준
으로 일관성을 맞추기 때문 살아있는 노드가 과반수 이상이라면 지속적인 서비스를 제공
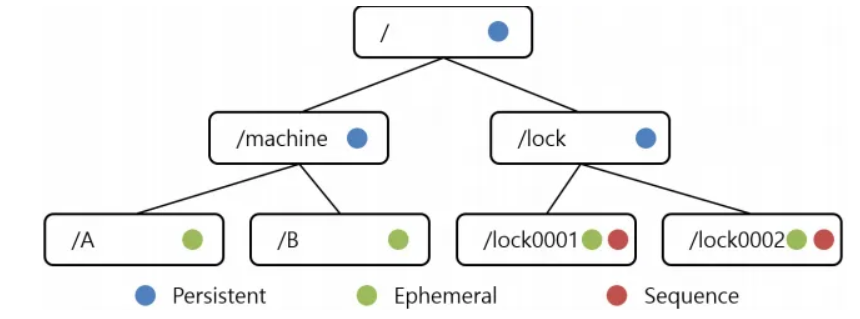
- Znode
- zookeeper가 정보를 저장하는 곳
- 디렉토리(트리) 구조
- 종류
- Persistent Node: 영구 저장소
- Ephermeral Node: Client가 종료되면 사라진다.
- Sequence Node: 생성 시 뒤에 숫자가 붙는다.
- 일반 Node
- Watcher
- 주키퍼를 사용하는 클라이언트 A가 ZooKeeper에게 Watcher 등록을 요청한다.
- 주키퍼를 사용하는 클라이언트 B가 ZooKeeper에게 ZNode를 수정한다고 말한다.
- 클라이언트 A에게 변경 이벤트를 전달한다.
- Quorum(쿼럼)
- Zookeeper 클러스터 내 모든 서버 묶음 단위를 의미
- Client가 Zookeeper에 접속할 때에도 quorum 내 leader에 의존해 실제 연결할 follower를 할당 받아 사용
🍞Kafka Connect
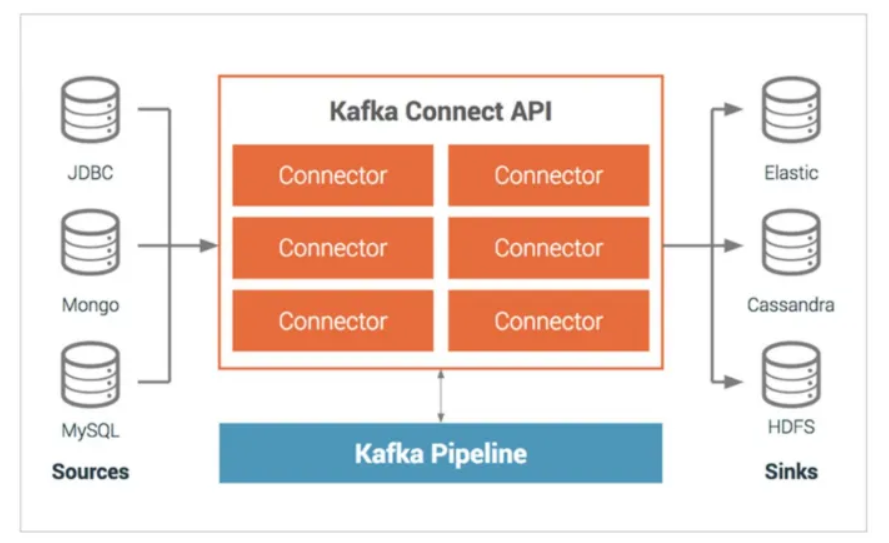
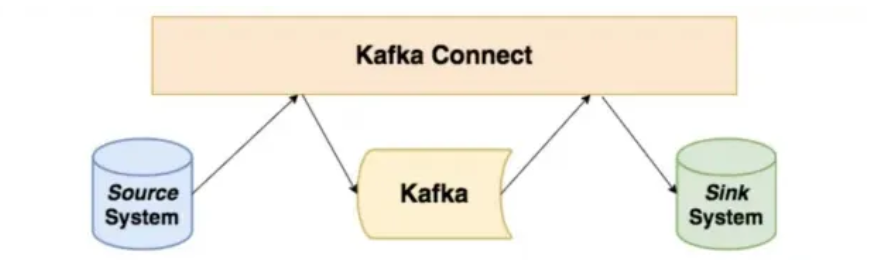
- 아파치 카프카의 오픈소스 프로젝트 중 하나로, 카프카와 외부 시스템(관계형 DB, 파일, 클라우드
SaaS 등) 간의 파이프라인 구성을 코드 없이 환경 설정만으로 쉽게 해주는 프레임워크 - 카프카 클러스터를 기준으로 커넥터를 양방향으로 배치하여 구성할 수 있음
- Connectors
- Source connector : 외부 시스템에 담긴 데이터를 카프카 클러스터로 담아주는 프로듀서의 역할을 하는 커넥터
- Sink connector : 카프카 클러스터에 있는 데이터를 외부 시스템으로 보내는 컨슈머의 역할을 하는 커넥터
- 특징
- 데이터 중심 파이프라인 : 카프카 커넥트를 이용해 카프카로 데이터를 보내거나, 카프카로 데이터를 가져옴
- 유연성 : 커넥트는 테스트를 위한 단독 모드(standalone mode)와 대규모 운영 환경을 위한 분산 모드(distributed mode)를 제공
- 재사용성과 확장성 : 커넥트는 기존 커넥터를 활용할 수도 있고 운영 환경에서의 요구사항에 맞춰 확장이 가능
- 편리한 운영과 관리 : 카프카 커넥트가 제공하는 REST API로 빠르고 간단하게 커넥트 운영 가능
- 장애 및 복구 : 카프카 커넥트를 분산 모드로 실행하면 워커 노드의 장애 상황에도 메타데이터를 백업함으로써 대응 가능
하며 고가용성 보장
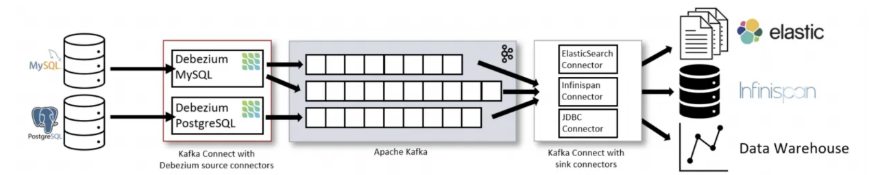
- 운영 환경에서 이용하는 커넥터의 대표적인 예시는 미러 메이커 2.0, 데비지움(Debezium)등
🍞 Kafka Streams
- Stream Processing
- 이벤트 스트림에 대해 데이터가 도착할 때마다 처리를 하여, 계속해서 이어가는 어플리케이션
- Kafka의 에코시스템에 있어서는 Kafka Broker에 Consumer로서 접속하여 무한 루프로 polling를 실행하여, 데이터가 도착할 때마다 짧은 간격(interval)으로 처리를 실시하는 어플리케이션
- Stream Processing 형태 구분
- Stateless : 어느 이벤트 레코드가 도착했을 때, 그 레코드만으로 처리가 완료하는 처리
- Stateful : 도착한 이벤트 레코드나 그것을 기초로 생성한 데이터를 일정 기간 보관 유지해 두고, 그것과 조합하여 결과를생성하는 처리
- Kafka Streams
- Apache Kafka 개발 프로젝트에서 공식적으로 제공되는 스트림 프로세싱 프레임워크
- 고기능
- 애플리케이션에 높은 확장성, 탄력성, 분산성, 내결함성을 구현
- “엄밀히 한번"의 처리 시멘틱스 지원
- Stateful와 Stateless 프로세싱
- 윈도우, 조인, 집계를 사용한 이벤트 시간 프로세싱
- 스트림과 데이터베이스를 통합하기 위해 Kafka Streams의 대화형 쿼리를 지원
- 높은 제어성과 유연성을 위해 선언형으로 함수형 API와 하위 레벨의 명령형 API 중에서 선택할 수 있음
- 가벼운 기능
- 도입에 진입 장벽이 낮음
- 소규모, 중규모, 대규모, 특대규모의 사례에 대응
- 로컬 개발 환경에서 대규모 프로덕션 환경으로 원활하게 전환
- 처리 클러스터 필요 없음
- Kafka 이외의 외부 종속성 없음
- Kafka pub/sub과 Streams 비교
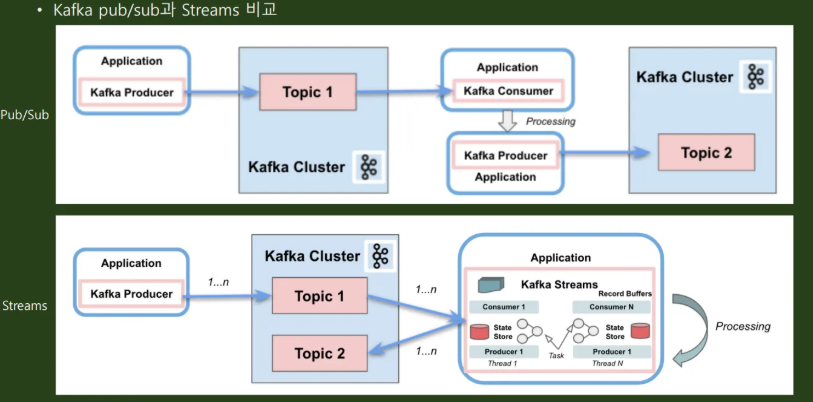
- pub/sub는 메세지가 들어오면 별도의 프로세싱 과정을 걸치는데,
- streams는 메세지가 들어오는 즉시 프로세싱을 통한 프로세싱이 이루어진다- Topology 구성을 통한 Kafka Streams 구현
- Topology 구성을 통한 Kafka Streams 구현
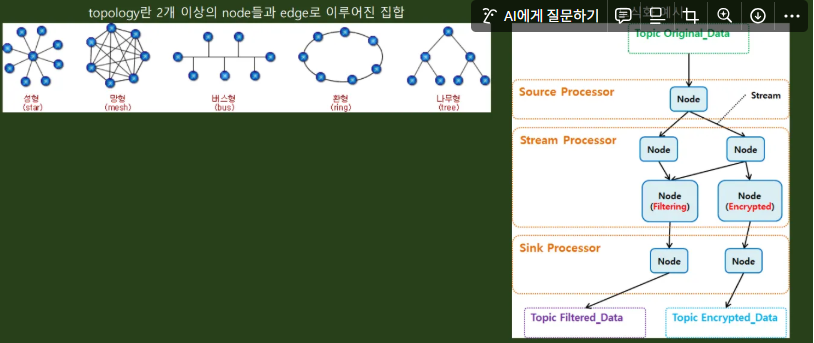
- 데이터를 처리하는 프로세서(Processor)가 노드이고 다음 노드로 넘어가는 데이터(Stream)를 엣지로 구성할 수 있음
- Streams DSL (Domain Specific Language)
- 미리 제공되는 함수들을 이용하여 토폴로지를 정의하는 방식
- 대부분의 변환 로직을 어렵지 않게 개발할 수 있도록 스트림 프로세싱에 쓰일만한 다양한 기능들을 자체 API로 제공하고있으며, 이벤트 기반 데이터 처리를 할 때 필요한 다양한 기능들(map, join, window 등)을 대부분 제공되고 있음
- 레코드의 흐름을 추상화한 3가지 개념인 KStream, KTable, GlobalKTable 이 있음
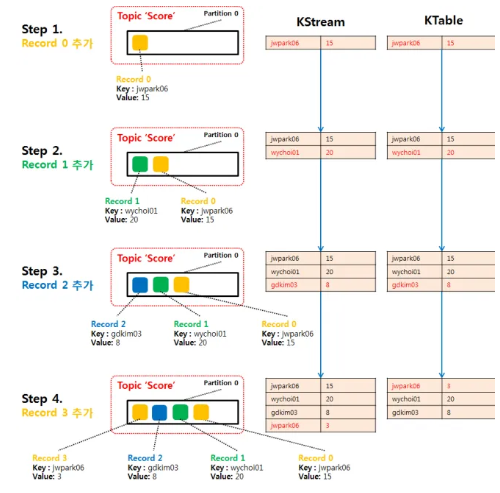
- KStream
- KStream으로 데이터를 조회하면 토픽에 존재하는 모든 데이터가 출력
- 토픽에 존재하는 데이터(레코드)의 key가 동일해도 key의 중복을 허용하며 데이터를 모두 가져옴
- 일반적인 consumer 와 비슷한 느낌
- KTable
- 주어진 메세지 키에 대한 최신 값을 보유한다. 즉, 동일한 메세지 키가 들어오면 제일 최신값으로 대체
- GlobalKTable
- KTable 과 동일하게 메시지 키를 기준으로 묶어서 사용
- 그러나 KTable로 선언된 토픽은 1개 파티션이 1개 태스크에 할당되나 GlobalKTable로 선언된 토픽은 모든 파티션 데이터가 각 태스크에 할당되어 사용되는 차이점이 존재
- KStream-KTable 조인 시 co-partitioning이 되어 있지 않은 경우 Global KTable을 이용하면 해결 가능
- Processor API
- Streams DSL에 없는 기능이 있다면 프로세서 API 사용
- Processor API는 Streams DSL보다 복잡한 코드를 가지지만, 데이터 처리를 토폴
로지를 기반으로 수행한다는 면에서 같은 역할 - Processor API를 사용할 때는 정의된 함수를 사용하는 것이 아니라 직접 구현해
야 하기 때문에 사용하기 어려움(KStream, KTable, GlobalKTable 개념이없음) - Stream DSL보다 더 정교한 로직을 구현할 수 있는 장점이 있음
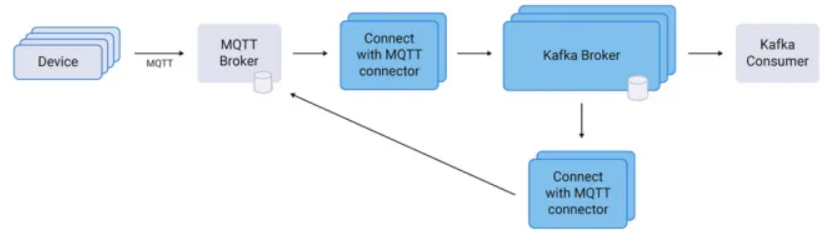
🍞 Kafka MQTT
- MQTT connector 활용
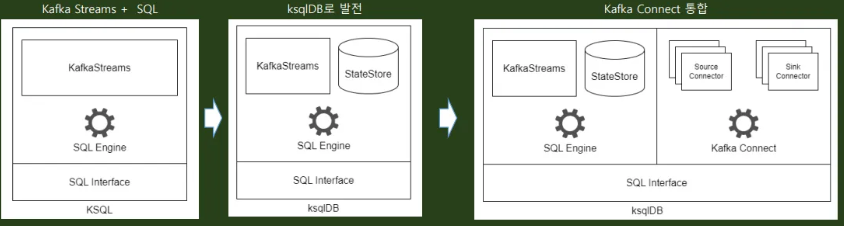
- 기타 : KsqlDB
- 2017년 Confluent에서 오픈소스로 공개한 이벤트 스트리밍 데이터베이스로 Kafka Streams + Kafka Connect로 구성되며, SQL을 인터페이스로 채용해 스트림처리 및 데이터 통합을 단순화시키는 효과를 가지도록 만든 opens source
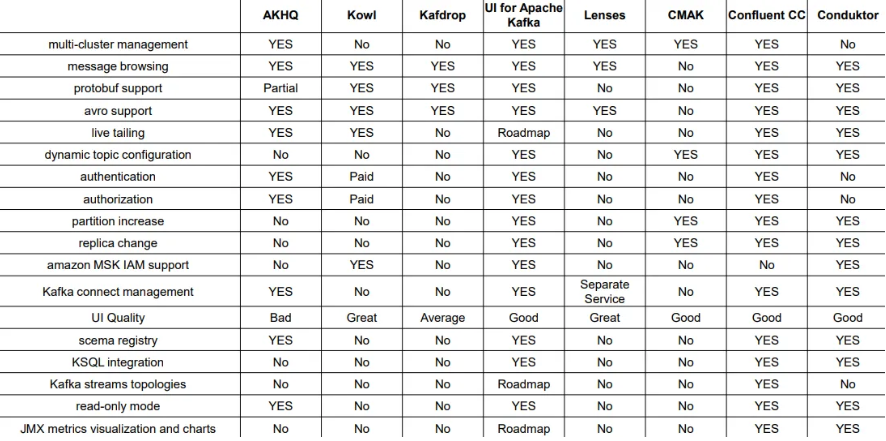
🍞 Kafka 관리툴

404