
📍목차
- HTTP 리퀘스트 메시지를 작성한다.
- 웹 서버의 IP 주소를 DNS 서버에 조회한다.
- 전 세계의 DNS 서버가 연대한다.
- 프로토콜 스택에 메시지 송신을 의뢰한다.
1️⃣ HTTP 리퀘스트 메시지를 작성한다.
사용자가 브라우저에 URL을 입력하면, 브라우저가 URL을 해독한다.
이때, URL은 http: 뿐만 아니라 ftp: file: mailto: 등 클라이언트의 기능에 따라 다양하다.
모든 URL의 공통점은 맨 앞의 문자열을 통해 목적지에 접근하는 법을 명시한다는 것이다.
따라서 맨 앞부분에 따라 URL 뒷부분의 작성법이 결정된다.
본 포스팅에서는 HTTP 프로토콜을 기준으로 설명한다.
- HTTP 프로토콜 URL 요소
- 요소 :
http://(웹 서버명)/(디렉토리명)/(파일명) - 예시 :
http://doohyeon/spring/jpa
- 요소 :
브라우저가 위 예시를 해독하면, 어느 프로토콜을 사용해 어디에 접근해야하는지 알 수 있다.
이러한 정보를 바탕으로 HTTP 리퀘스트 메시지를 만들고, 메시지가 웹 서버(목적지)에 도달하면 그 속의 내용을 해독하여 요구 사항에 따라 동작한 후 결과 데이터를 응답 메시지에 저장한다.
리퀘스트 메시지와 응답 메시지의 구조를 간단하게 정리하면 아래와 같다.
- 리퀘스트 메시지
<메소드> <URL> <HTTP_버전> // 리퀘스트 라인
<필드명>:<필드값> // 메시지 헤더 시작
<필드명>:<필드값>
// 메시지 헤더 종료
<메시지_본문>- 응답 메시지
<HTTP 버전> <스테이터스_코드> <응답_문구>
<필드명>:<필드값> // 메시지 헤더 시작
<필드명>:<필드값>
// 메시지 헤더 종료
<메시지_본문>여기서 스테이터스 코드와 응답 문구는 모두 처리 결과에 대한 내용을 담고있으나, 용도가 다르다.
스테이터스 코드는 프로그램에 실행 결과를 알려주기 위함이며, 응답 문구는 사람에게 결과를 알리기 위함이다.
이후 응답 메시지가 돌아오면 데이터를 추출하여 화면에 표시하게 되는데,
페이지에 문장 외에 이미지나 영상 등 태그가 포함되는 경우, 태그 정보란에는 공백을 남겨두고 모든 문장을 출력한 후 태그마다 다시 웹 서버에 접근하여 데이터를 가져오게 된다.
이는 리퀘스트 메시지에 쓰는 URI는 한 개로 제한되어 있기 때문이고,
이미지가 3개 존재한다면 문장을 읽는 리퀘스트와 3개의 이미지를 읽는 리퀘스트로 총 4번의 리퀘스트 메시지를 보내게 된다. 이때 웹 서버는 4번의 요청이 한 개의 페이지인지 여러개의 페이지인지는 신경쓰지 않는다.
2️⃣ 웹 서버의 IP 주소를 DNS 서버에 조회한다.
그러나 브라우저는 URL을 해독하고 HTTP 메시지를 만들지만, 이를 네트워크에 송출하는 기능은 없다.
따라서 메시지를 만든 후 이를 OS에게 의뢰하여 웹 서버에 송신하게 되는데,
OS에 송신을 의뢰할 때는 도메인명(www.naver.com 형태)이 아닌 IP(127.0.0.1 형태)로 메시지 상대를 지정해야한다.
따라서 HTTP 메시지를 만든 후에는 IP 주소를 조사하게 된다.
접근 대상의 서버까지 메시지를 운반할 때는 이 IP 주소에 따라 운반하게 되고,
서브넷 내의 허브가 가장 가까운 라우터에 운반하는 과정을 반복한다.
✔️ IP의 32비트 데이터만으로 네트워크 번호와 호스트 번호를 어떻게 구분할까?
10.1.2.3과 같은 IP 주소가 있을 때, 이는 네트워크 번호와 호스트 번호를 합쳐 32비트로 한다는 것만 정해져 있을 뿐 어느 부분까지가 네트워크 번호인지 알 수 없다.
이는 사용자가 직접 내역을 결정할 수 있기 때문에, 호스트 번호를 구분하기 위해 넷마스크라는 정보를 IP 주소에 덧붙인다.
넷마스크가 /24 라고 가정하면 10.1.2.3/24 형태로 표기되며,
넷마스크가 1인 부분(10.1.2)은 네트워크 번호, 0인 부분은 호스트 번호(.3)를 나타낸다.
즉, 10.1.2.3/11111111.11111111.11111111.00000000과 같은 의미이다.
✔️ 왜 도메인명과 IP 주소를 구분할까?
익히 알다시피, IP 주소는 기억하기 힘드므로 도메인명을 사용하고 있다.
그렇다면 차라리 IP 주소를 버리고 도메인명으로 OS에 의뢰하도록 하는 것이 편하지 않을까?
이는 실행 효율의 관점에서 바라볼 때 현명하지 못하기 때문이다.
IP 주소는 32비트, 즉 4바이트의 데이터를 통해 판단하는 반면, 도메인명은 최소 수십 바이트에서 255바이트까지 가질 수 있으므로 라우터에 수십배의 부하가 걸리게 된다.
다시 IP 주소를 찾는 방법에 대해 얘기해보자.
IP 주소 조회는 가까운 DNS 서버에 "www.velog.io라는 서버의 IP 주소를 알려줘." 라고 질문하며 시작된다.
즉, DNS 서버에 조회 메시지를 보내고 응답을 받는 DNS 클라이언트에 해당하는 것을 리졸버라고 칭한다.
리졸버의 실체는 Socket 라이브러리의 일부인데,
Socket 라이브러리는 네트워크 기능을 호출하기 위한 프로그램의 모음이다.
이러한 프로그램의 기능 중 gethostbyname()과 웹 서버의 이름(www.velog.io)을 통해 리졸버를 호출할 수 있다.
호출된 리졸버는 DNS 서버에 조회 메시지를 보낸 후 받은 응답 메시지를 브라우저가 지정한 메모리 영역에 써넣음으로써 IP 주소 조회는 끝나게 된다.
이후 브라우저는 이 메모리 영역에서 IP 주소를 추출해 HTTP 리퀘스트 메시지와 함께 OS에 송신을 의뢰하게 된다.
리졸버 내부의 작동
그러면 리졸버의 작동 방식에 대해 조금 더 알아보자.
브라우저가 리졸버에게 IP 조회를 요청하면,
즉 gethostbyname("www.velog.io")를 호출하면 DNS 서버에 문의하기 위한 조회 메시지를 생성한다.
생성을 마치면 메시지를 DNS 서버에 보내게 되는데, 리졸버또한 브라우저와 마찬가지로 네트워크 송수신 기능이 없다.
따라서, 리졸버는 OS 내부의 프로토콜 스택을 호출해 DNS 서버에 메시지를 보내게 된다.
작동 구조를 나타내면 아래와 같다.
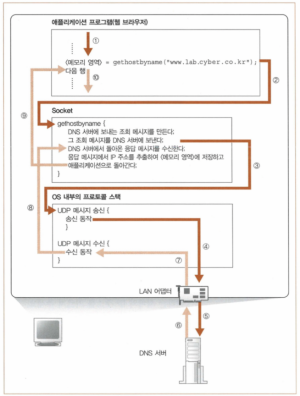
DNS 서버에 메시지를 송신할 때도 DNS 서버의 IP 주소가 필요하다.
단, DNS 서버의 IP 주소는 컴퓨터에 미리 설정되어 있으므로 다시 조회할 필요가 없다.
즉, 리졸버는 컴퓨터에 미리 설정된 IP 주소에 조회 메시지를 보낸다.
3️⃣ 전 세계의 DNS 서버가 연대한다.
이제 DNS 서버의 동작 방식에 대해 자세히 알아보자.
앞서 리졸버가 DNS 서버에 송신하는 조회 메시지는 아래 세 정보를 포함한다.
1. 이름 : 서버나 메일 배송 목적지
2. 클래스 : 네트워크 식별자. 지금은 인터넷 외 네트워크가 소멸되어 항상 IN 값을 가진다.
3. 타입 : 이름의 종류 ex) A : IP, MX : 메일 배송 목적지
DNS 서버는 서버에 등록된 도메인명과 IP 주소의 대응표를 조사하여 일치하는 IP 주소를 반환한다.
그러나 수많은 서버를 1대의 DNS에 서버에 등록하는 것은 불가능하기 때문에,
정보를 분산시켜 다수의 DNS 서버에 등록한 후, 다수의 DNS 서버가 연대하여 IP 주소를 반환하게 된다.
이때 DNS 서버에서 취급하는 이름은 www.velog.io와 같이 점으로 계층을 구분하는데,
이는 io라는 도메인 아래에 velog라는 도메인이 있고, 또 그 아래 www이 있는 셈이다.
다음으로 DNS 서버에 등록한 정보를 찾아내는 방법에 대해 알아보자.
수만 대의 DNS 서버를 모두 찾아볼 수는 없으므로, 아래와 같은 방법을 사용한다.
하위 도메인을 담당하는 DNS 서버의 IP 주소를 상위의 DNS 서버에 등록한다.
즉, www.velog.io를 담당하는 DNS 서버를 velog.io를 담당하는 DNS 서버에 등록하고,
velog.io를 담당하는 DNS 서버를 io를 담당하는 DNS 서버에 등록하여 상위 DNS 서버부터 조회하는 방식이다.
이때, 최상위 도메인은 io가 아닌 .으로 나타내는 루트 도메인이 존재한다.
루트 도메인은 생략 가능하기 때문에, www.velog.io.와 www.velog.io는 같은 도메인이다.
따라서 io를 담당하는 DNS 서버또한 루트 도메인을 담당하는 DNS 서버에 등록된다.
등록 작업으로 한 가지가 더 있는데, 루트 도메인의 DNS 서버를 모든 DNS 서버에 전부 등록하는 것이다.
이를 통해 어느 DNS 서버든지 루트 도메인에 접근할 수 있게 된다.
루트 도메인의 DNS 서버에 할당된 IP 주소는 전 세계에 13개뿐이고 잘 변경되지 않으므로, 별로 어려운 작업이 아니다.
실제로 루트 도메인의 DNS 서버에 관한 정보는 기본 설정 파일로 배포되어 있어 DNS 서버 소프트웨어 설치 시 자동으로 등록된다.
위 동작 과정을 그림으로 나타내면 아래와 같다.
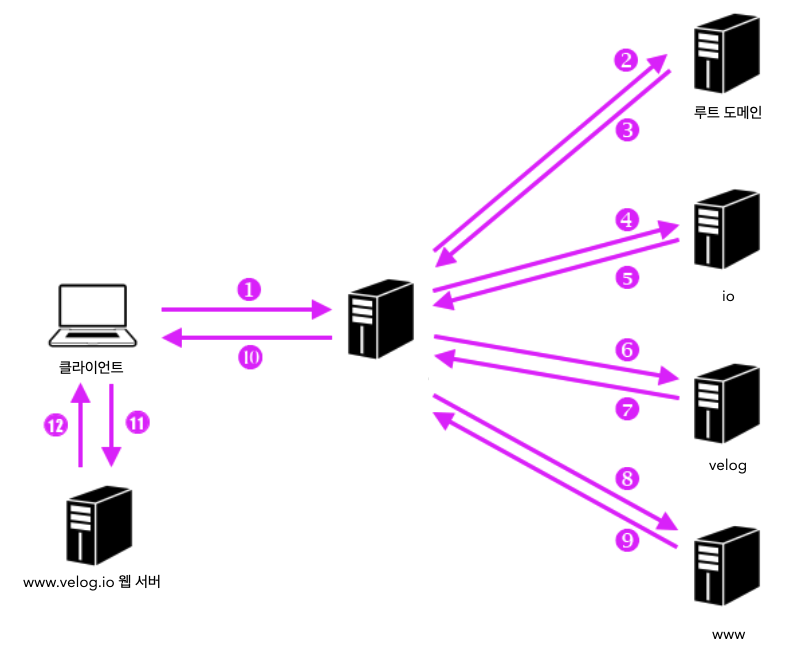
즉, 이는 브라우저가 gethostbyname("www.velog.io")를 호출하여 웹 서버의 IP 주소를 조회하는 과정이다.
한 대의 DNS 서버에 여러 개의 도메인 정보를 등록할 수도 있기 때문에,
상위와 하위의 도메인을 같은 DNS 서버에 등록하여 반드시 계층별로 하나씩 조회하지 않을 수 있다.
또한, DNS 서버는 한 번 조사한 이름을 캐시에 기록할 수 있기 때문에, 항상 루트 도메인의 DNS 서버부터 차례대로 따라가지 않을 수 있으며, 캐시에 저장한 후 등록 정보가 변경될 수도 있으므로 올바르지 않을 수 있음에 유의해야한다.
따라서 DNS 서버에 등록하는 정보에 유효 기간을 설정하여 캐시에 저장한 데이터의 유효 기간이 지나면 삭제한다.
DNS 서버의 응답 메시지에는 정보가 캐시에 저장된 것인지, DNS 서버에서 회답한 것인지가 포함되어있다.
4️⃣ 프로토콜 스택에 메시지 송신을 의뢰한다.
위 과정을 통해 IP 주소를 받은 후에는, OS 내부의 프로토콜 스택에 의뢰하여 웹 서버(목적지)에 메시지를 송신한다.
여기서도 Socket 라이브러리의 기능을 호출하며, 이를 통해 클라이언트와 서버 사이에 데이터를 주고받기 위한 파이프를 설치하게 된다.
파이프의 양끝 출입구를 소켓이라 부르는데, 서버 측에서 먼저 소켓을 만든 후 클라이언트가 서버가 만든 소켓에 파이프를 연결하기를 기다린다. 즉, 클라이언트도 소켓을 만든 후 파이프를 늘려 서버 측 소켓에 연결하는 원리이다.
송수신이 끝난 후에는 클라이언트/서버 상관없이 한 쪽에서 파이프를 분리하면 파이프가 사라지고, 소켓을 말소하여 통신을 마친다.
데이터의 송수신 동작을 요약하면 다음과 같다.
- 소켓 생성
- 서버측 소켓에 파이프 연결
- 데이터 송수신
- 파이프 분리 및 소켓 말소
이때 중요한 것은, 위 네 가지 동작을 수행하는 것은 OS 내부의 프로토콜 스택이라는 것이다.
Socket 라이브러리는 브라우저에게 요청받은 내용을 프로토콜 스택에 전달하는 중개역이다.
프로토콜 스택 동작 과정
1. socket()
소켓을 만드는 단계이다.
이에 대한 반환 값으로 디스크립터라는 것이 존재하는데,
디스크립터는 소켓을 식별하기 위한 데이터이다.
컴퓨터 내부에서는 동시에 여러 개의 데이터를 송수신하는 경우가 많으므로 소켓또한 여러 개를 생성해야하며,
이러한 소켓을 구별하기 위한 식별자가 디스크립터인 것이다.
2. connect()
서버측에서 만들어진 소켓에 접속하도록 프로토콜 스택에 의뢰하는 단계이다.
이때 지정하는 값으로는 디스크립터, 서버의 IP 주소, 포트 번호라는 세 가지 값이다.
- 디스크립터 : 클라이언트 측의 어느 소켓을 서버에 접속시킬지 판단하기 위한 값
- 서버의 IP 주소 : 송수신 상대의 IP 주소를 프로토콜 스택에 알리기 위한 값
- 포트 번호 : 서버의 IP 주소를 통해 대상 컴퓨터에 접근한 후, 서버측의 어느 소켓인지 판단하기 위한 값
서버의 IP 주소로는 네트워크의 어느 컴퓨터인가까지만 알 수 있음에 유의해야 한다.
포트 번호를 통해 서버 측에서 어느 소켓에 클라이언트의 소켓을 연결해야하는지 알 수 있게 된다.
앞서 언급한 디스크립터는 클라이언트측의 소켓 식별자인 것이지, 서버측 소켓의 디스크립터를 클라이언트측이 알 수는 없기 때문에 포트 번호가 필요하다.
3. write()
소켓이 연결되었으므로, 데이터를 송수신하는 단계이다.
write() 호출 시 디스크립터와 송신 데이터를 지정하며, 이때 송신 데이터는 앞서 브라우저가 생성한 HTTP 리퀘스트 메시지가 된다.
4. read()
write() 호출 후 서버측에서 돌아온 응답 메시지를 수신하는 단계이다.
응답 메시지를 수신 버퍼에 저장하고,
수신 버퍼는 브라우저(애플리케이션 프로그램)에서 마련한 메모리 영역이므로,
수신 버퍼에 저장되는 시점에서 브라우저에게 응답 메시지를 전달한다.
5. close()
데이터 송수신을 마치고 소켓을 말소하는 단계이다.
디스크립터를 전달해 어느 소켓을 말소할지를 지정하며, 웹의 경우 서버측에서 먼저 close()를 호출하면 연결이 끊겼다는 정보를 브라우저에게 전달한 후 브라우저에서도 close()를 호출하여 연결을 끊게된다.
추가적으로 HTTP/1.1 버전부터는 하나의 페이지에 태그가 여러 개인 경우, connect()와 close()를 태그마다 반복하는 것이 아닌 더이상 요청할 데이터가 없어진 상태에서 close()를 수행하게 된다.
👏 마무리
본 포스팅을 통해 브라우저와 웹 서버가 메시지를 송수신하는 과정에 대해 알아봤다.
메시지를 송수신하는 것은 프로토콜 스택, LAN 드라이버, LAN 어댑터로 세 가지이며,
다음 포스팅에서 이에 대해 알아보자.
참고 자료
💕좋아요와 댓글은 큰 힘이 됩니다.💕
