이번엔 Ensembling을 통해 모델의 성능을 개선해보자.
먼저 Bagging로, 일반적인 앙상블 모델로써 작은 크기의 데이터셋에 대한 유사한 classifier들을 적용한다. 그리고 나서 모든 prediction의 평균을 가져온다. 평균값으로 인해 variance를 줄일 수 있다.
model=BaggingClassifier(estimator=DecisionTreeClassifier(),random_state=0,n_estimators=100)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged Decision Tree is : ',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged Decision Tree is : ',result.mean())The accuracy for bagged Decision Tree is : 0.7709923664122137
The cross validated score for bagged Decision Tree is : 0.7835483870967741
model=BaggingClassifier(estimator=KNeighborsClassifier(n_neighbors=10),random_state=0,n_estimators=600)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged KNN is : ',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged KNN is: ',result.mean())The accuracy for bagged KNN is : 0.816793893129771
The cross validated score for bagged KNN is: 0.7673118279569893
다음 Boosting은 연속적인 classifier를 learning함으로 써 앙상블을 사용하는 방법이다. 성능이 낮은 모델을 강화하는 데 도움이 된다. 모델은 처음에 완전한 데이터셋으로 트레인되고, 다음 interation에서 잘못된 predicted instances로 이동하면 weight를 더 준다. 그래서 잘못된 instance를 정확하게 예측하도록 한다.
AdaBoost(Adaptive Boosting)
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.1)
result=cross_val_score(ada,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for AdaBoost is:',result.mean())The cross validated score for AdaBoost is: 0.7683932346723044
Stochastic Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
grad=GradientBoostingClassifier(n_estimators=500,random_state=0,learning_rate=0.1)
result=cross_val_score(grad,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for Gradient Boosting is : ',result.mean())The cross validated score for Gradient Boosting is : 0.8076638477801268
Xgboost 는 자료형을 Dmatrix로 바꾸고 돌려야 한다.
train_Xxgb = train_X.iloc[:train_X.shape[0]].values
test_Xxgb = train_X.iloc[train_X.shape[0]:].values
train_Yxgb = train_Y['Survived'].values
gbm = xgb.XGBClassifier(max_depth=3, n_estimators=300, learning_rate=0.05)
result = cross_val_score(gbm, train_Xxgb, train_Yxgb, cv=10, scoring='accuracy')
print('The cross validated score for XGBoost is:', result.mean())The cross validated score for XGBoost is: 0.806774193548387
정확도가 괜찮게 나온 Gradient Boosting으로 Hyper-Parameter Tuning을 해보자.
n_estimators=list(range(100,1100,100))
learn_rate=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
hyper={'n_estimators':n_estimators,'learning_rate':learn_rate}
gd=GridSearchCV(estimator=GradientBoostingClassifier(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)Fitting 5 folds for each of 120 candidates, totalling 600 fits
0.8097439916405433
GradientBoostingClassifier(learning_rate=0.05, n_estimators=400)
기존보다 약간 향상되었다.
이것도 confusion matrix로 확인해보자.
ada=GradientBoostingClassifier(learning_rate=0.05, n_estimators=400)
result=cross_val_predict(ada,X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,result),cmap='winter',annot=True,fmt='2.0f')
plt.show()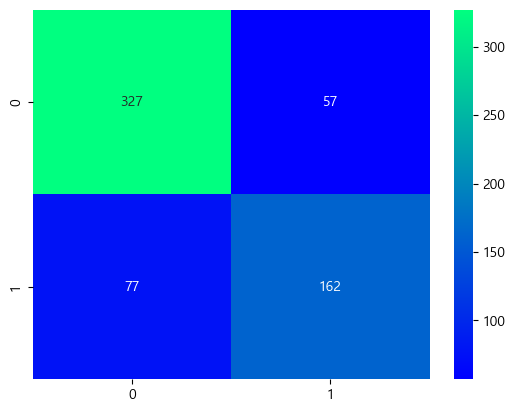
마지막으로 각 항목별 중요도를 각 모델에서 어떻게 평가했는지 살펴보자.
f,ax=plt.subplots(2,2,figsize=(15,12))
model=RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,0])
ax[0,0].set_title('Feature Importance in Random Forests')
model=AdaBoostClassifier(n_estimators=200,learning_rate=0.05,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1],color='#ddff11')
ax[0,1].set_title('Feature Importance in AdaBoost')
model=GradientBoostingClassifier(n_estimators=700,learning_rate=0.05,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,0],cmap='RdYlGn_r')
ax[1,0].set_title('Feature Importance in Gradient Boosting')
model=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
model.fit(train_Xxgb,train_Yxgb)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,1],color='#FD0F00')
ax[1,1].set_title('Feature Importance in XgBoost')
plt.show()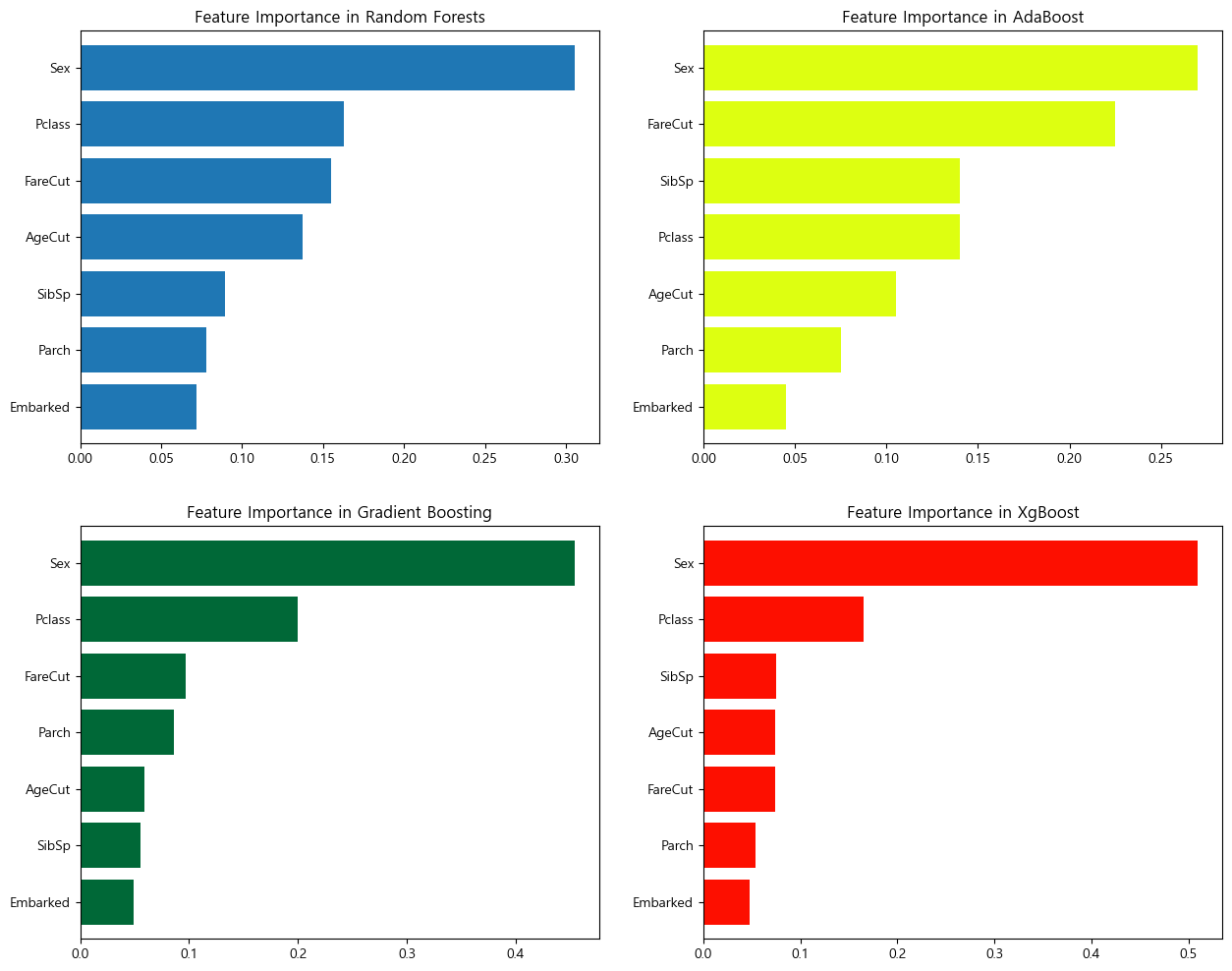
4모델 공통적으로 성별을 가장 중요하게 보았다. 다만 Ada는 다른 3모델과 다르게 Pclass의 중요도를 낮게 측정하는 경향이 있었다. 4모델의 평균 정확도 차이가 크지 않았음을 고려하면, 이는 알고리즘에 따른 차이라 보인다.
Ada모델은 결정 트리(Decision Tree)에서 각 관측값에 같은 가중치(weight)을 주고 훈련해 약한 모델을 강한 모델로 성장시키는 방식이고, XGBoost,Gradient Boosting는 손실함수를 최소화하는 방향으로 모델을 최적화하는 방식, 그리고 RandomForest는 데이터, 변수를 랜덤하게 뽑아 다양한 모델을 생성하는 방식이다. XGBoost와 Gradient Boosting가 비슷한 결과를 낸 것이 같은 유형의 알고리즘을 사용했기 때문이라는 생각이 들었다.
Decision Tree라고 하니, 전에 무료로 받았던 while True: learn() 이라는 게임이 생각났다. 내가 기르는 고양이가 나보다 머신러닝을 잘해서, 퍼즐을 풀면서 고양이 번역 시스템을 구축한다는 내용인데, 결정 트리의 종류나 작동방식의 시각화가 잘되서
이런 형태로 강화학습을 최적화하는 과정을 퍼즐 형태로 만날 수 있었다. 오랫만에 퍼즐을 풀면서 주말을 보내야 겠다.
PS. 캐글 점수는 0.75 정도였다. 평균정도면 감지덕지하다. 
