신경망의 성능을 몇 퍼센트 끌어올릴 수 있는 믿을만한 방법 중 하나는
하나의 문제에 대해 여러 개의 독립적인 전문가(모형)를 만들고 테스트 때 그들의 평균 예측을 취하는 것입니다.
앙상블에 관여하는 모형수에 비례하여 보통 성능은 단조적으로 올라갑니다.
게다가, 앙상블 내의 모형의 다양함이 늘어날수록 성능의 개선은 더 극적으로 이루어집니다.
앙상블을 구축하는 몇 가지 방법은 다음과 같습니다
1. 같은 모형, 다른 초기화
검증 데이터를 사용하여 최적의 hyper parameter를 결정한 후
각 모델에 동일한 하이퍼 파라미터를 이용하되 변수들의 초기값을 임의로 다양하게 설정하여 모형을 훈련합니다.
하지만 이러한 방식은 모형의 다양성이 오직 다양한 변수 초기값에만 달렸다는 것입니다.
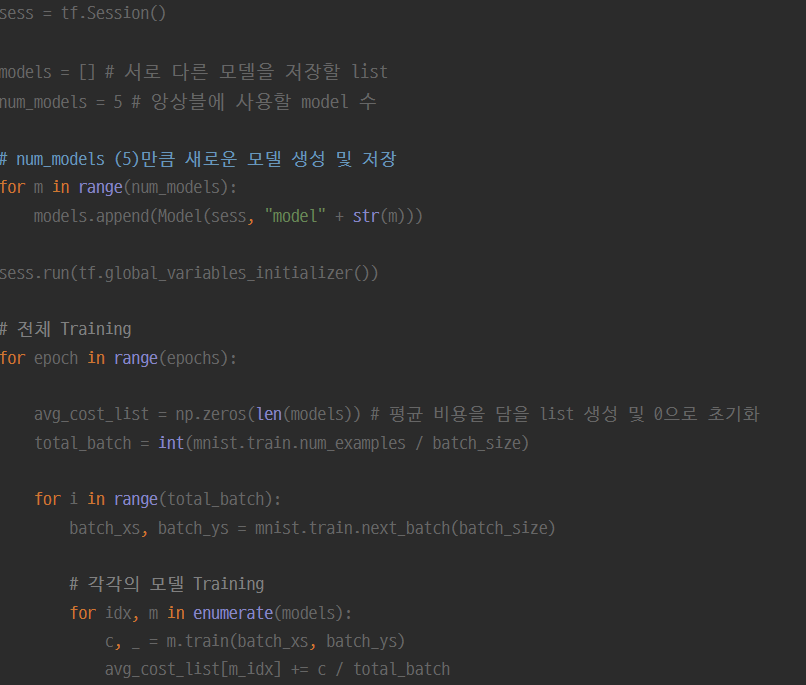
Python 및 Tensorflow, MNIST를 사용하여 간단히 구현한 내용은 아래와 같으며 아래 github의 소스코드를 참조했습니다
(https://github.com/hunkim/deeplearningzerotoall)
Training
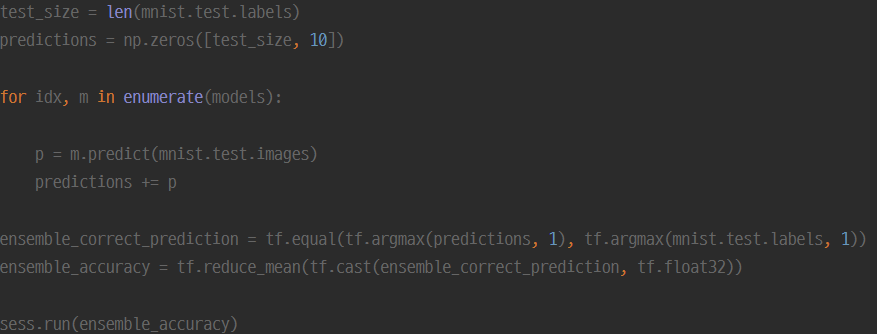
Test

위와 같이 원하는만큼의 모델을 생성 및 학습 후
테스트시에는 간단히 해당 문제에 대해 모든 모델에게 출력결과를 물어본 뒤 합산을 합니다.
(MNIST이므로 0-9까지)
마지막에는 0-9중 합산이 가장 높은 index (모든 모델을 합산한 결과 가장 확률이 높은 수)를 리턴하여 앙상블을 구현할 수 있습니다.
2. 최고의 모델 추출
검증 데이터로 최고의 하이퍼 파라미터를 결정한 후 몇 개의 최고 모형을 선정(예. 10개) 이들로 앙상블을 구축합니다.
이 방법은 앙상블 내의 다양성을 증가시키지만, 최적보다 조금 떨어지는 모형을 포함할 수도 있는 위험이 있습니다.
3. 한 모형에서 다른 체크포인트 사용
만약 한번한번의 훈련 비용이 매우 크다면 단일 네트워크에서 체크포인트들을 앙상블하는 방법을 사용할 수 있습니다.
명백하게 다양성이 떨어지는 방법이지만 간편하고 저렴하게 동작하며 실전에서 합리적으로 잘 작동할 수 있습니다.
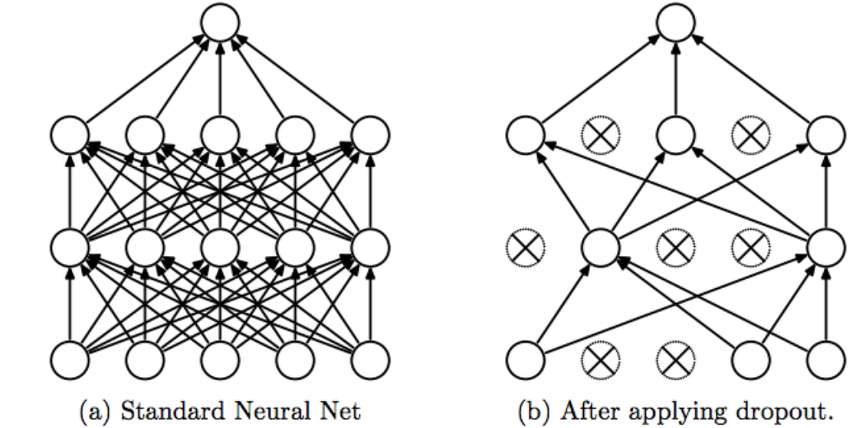
이 맥락과 유사한 방식은 드롭아웃(Dropout)이라는 방식인데
이 방식은 훈련 시, 한 네트워크 안에서 매 epoch마다 은닉층의 뉴런을 임의로 삭제하면서 학습하는 기법입니다.
훈련 때는 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택하고, 이를 통해 학습된 네트워크에서 시험 때는 모든 뉴런에 신호를 전달합니다.
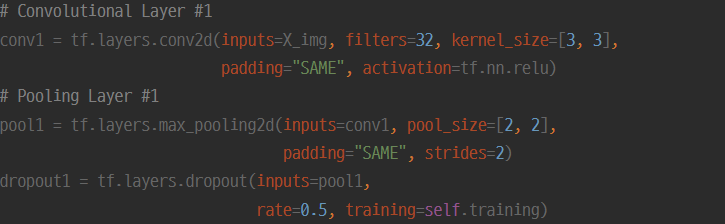
위와 같이 CNN모형의 convolution layer - pooling layer를 통과한 후 dropout을 적용하여 간단히 다음 레이어로 넘겨줄 수 있습니다.
함수에서 받는 rate인수는 해당 layer에서 얼마만큼의 뉴런을 삭제할지의 비율을 정하여 넘겨줍니다.
대개 훈련시에는 0.5-0.7의 값으로 설정하고 테스트에는 반드시 1.0으로 설정해주어야 합니다.
부가적인 효과로 임의의 뉴런을 삭제한채 트레이닝 데이터의 최적 신경망보다 신경망의 일반화를 도모하므로 오버피팅(과적합)을 억제해주는 방식으로도 많이 사용됩니다.
하지만 너무 많은 귀중한 입력값 손실을 야기한다는 이유로 사용하지 않기도 합니다.
