This is the journal that related to code clone detecting. This summer vacation I tried to make jCCTokener by using this journal.

It use the AST structure. AST is Abstract Syntax Tree that shows the overall structure. The people who wrote this journal made AST parser it python language. However, I didn't have the right time so I used the Eclipse JDT Library.
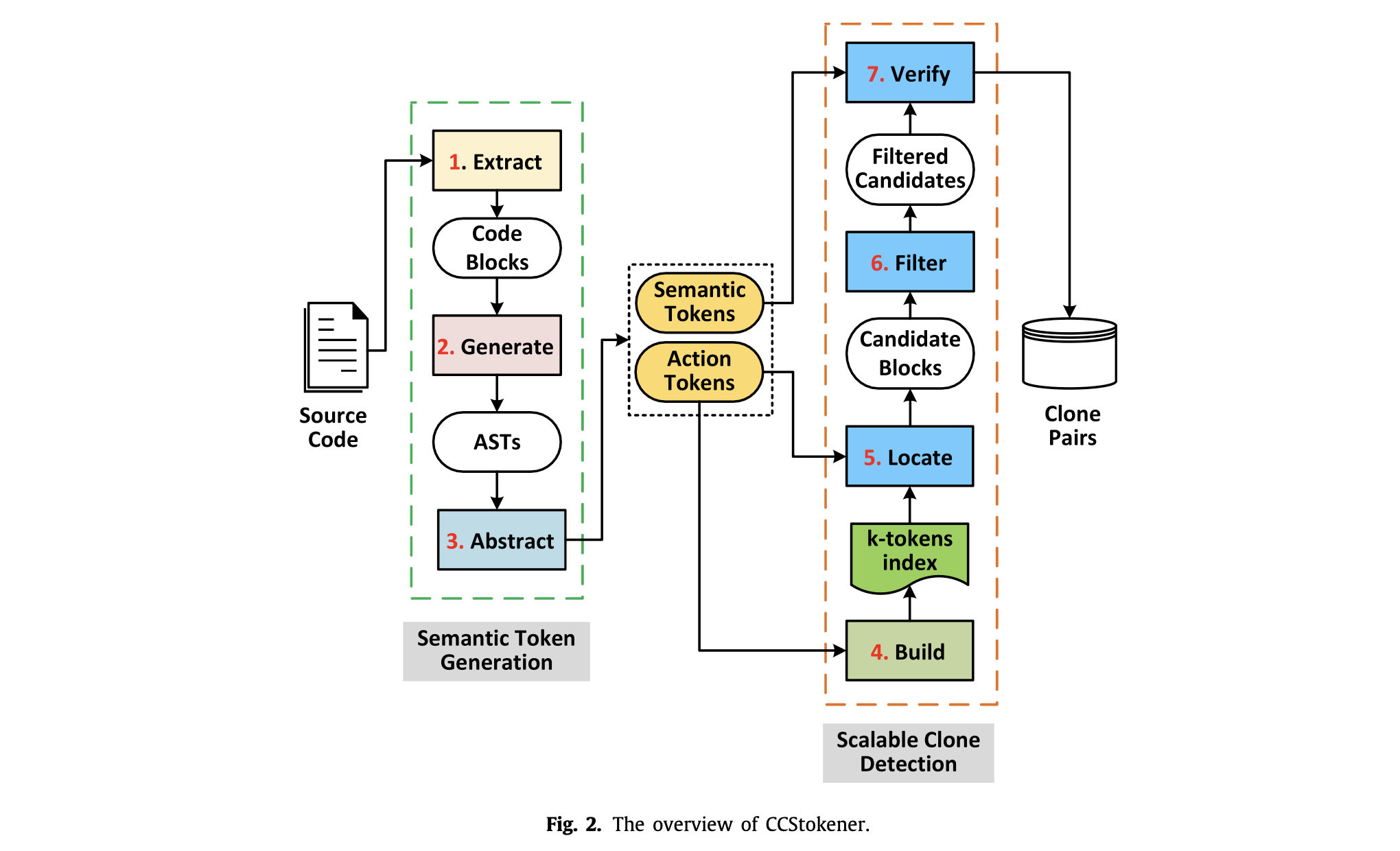
This is the overvies of this journal stack.
In this library, it provides the ASTParser, ASTVisitor classes.
First, they divided 25 types in 25 demension array.
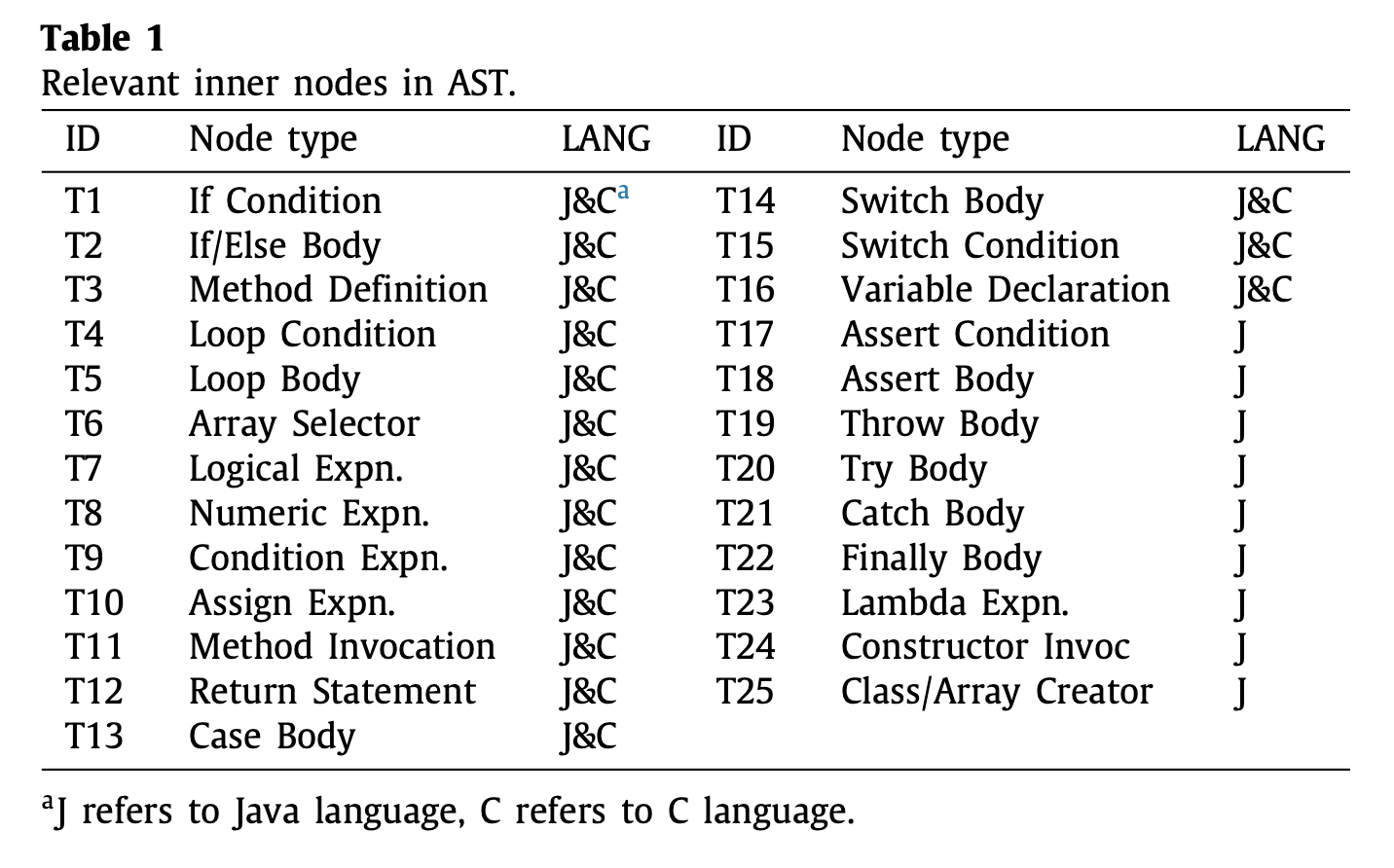
In the picture, type 1 is IfCondition. Eclipse AST Library have IfStatement node. This node represents type 1.
For example, sample code is this.
It is the sample code. The variable of md is in the VariableDeclarationFragmenetNode " MessageDigest md = messageDigest.getInstance("MD5").
The seconde floor of md is try body. Finally md in the MethodDefinition.
In the 25type of vector, the variable of md is count up in 3, 16, 20.
All of the variable and method, operator was divided in the 25 demention vectors.
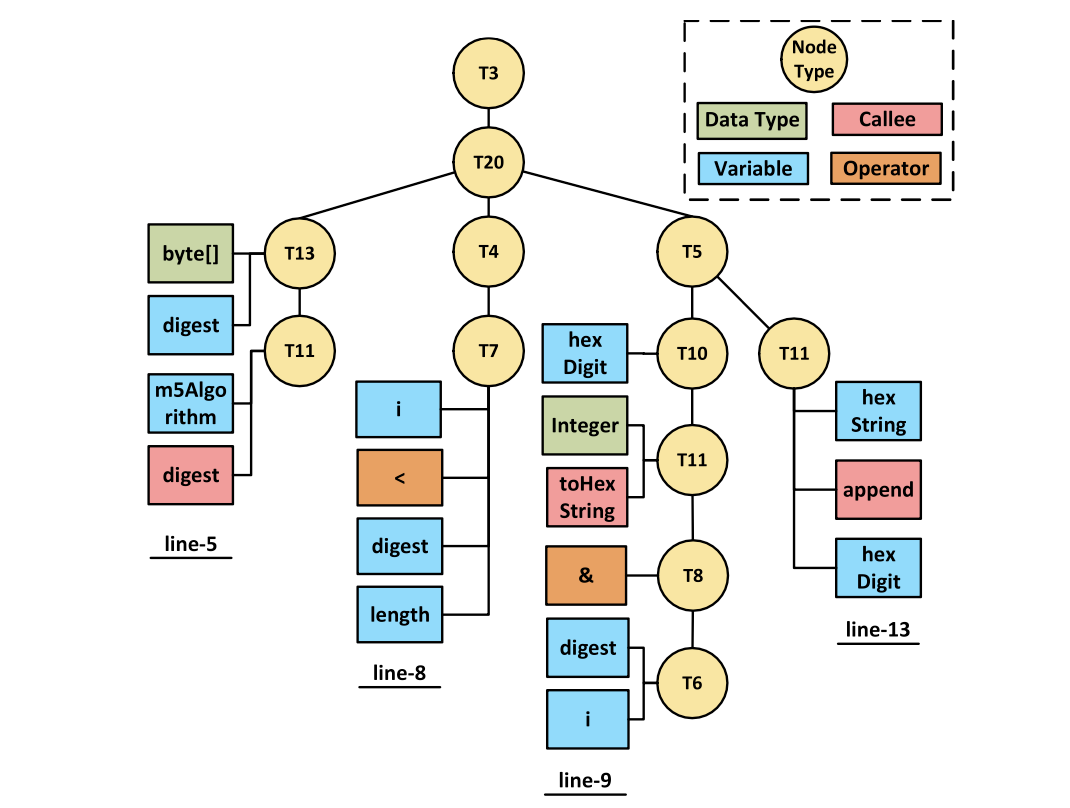
This is the example of code parsing.
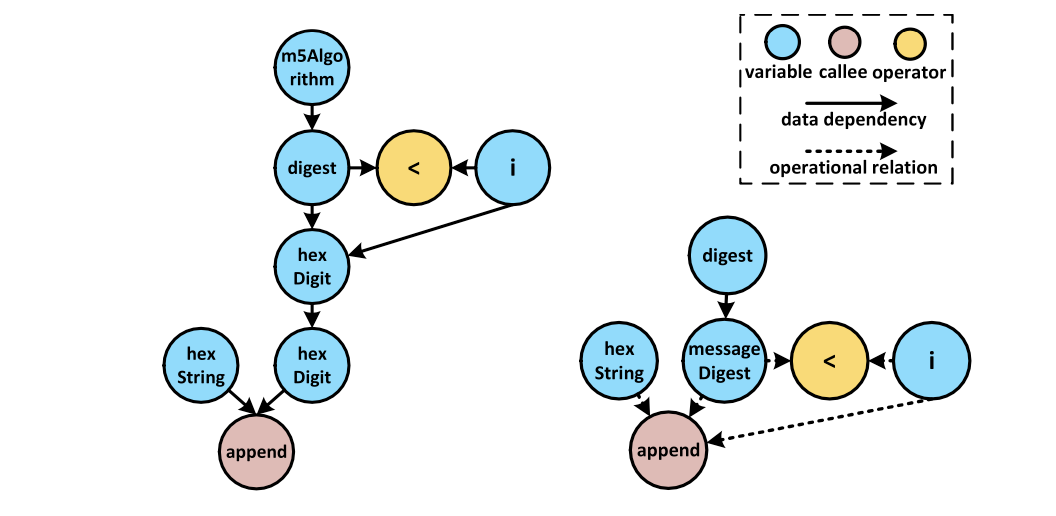
The next step is creating all varible's data dependency. Data dependency means if one variable was made by VariableDeclarationFragmentNode and in the node, there were ArrayAccessNode(a[b]), the variable related to variable a and b. In this approach, this journal made 3 types of variable(variable, operator, callee).
Every type of variable should be exist as type of semantic vector. The type1 semantic vector is constructed by adding all type1 vectors in the data dependency.
The type2 semantic vector(operator) is constructed by adding related variable's semantic vector. For example, if the InfixExpressionNode a = b + c; the operator of + semantic vector is sum of b, c's semantic vector.
The type3 semantic vector(method) is consturcted by adding related vairable's semantic vector and method's structure vector. For example, in case of a.post(b), the type3 node is post and its semantic vector is sum of a and b's semantic vector and post's structure vector.
The next step is filteration step. In this step, the parser divides Action token(Action token is the variable that can't change in other form. For example, String, Long, and method name). After do that, all of the Action tokens sorted in lexical order. Finally, parser makes k-tokens(k-tokens is bundle that tied up in k pieces.) by using k-tokens, parser can filter related clone pairs.


Finally, filtered clone pairs should be calculated all semantic vectors by using cosine similarity. Total similarity is sum of type1 similarity, type2 similarity, and type3 similarity. This journal mentioned that if total similarity is more than 0.65, it might be clone.

개발자로서 배울 점이 많은 글이었습니다. 감사합니다.