- 컬렉션(collection) 자료구조는 시퀀스 자료구조와 달리, 데이터를 서로 연관시키지 않고 모아두는 컨테이너이다.
- 컬렉션 자료구조는 시퀀스 자료구조에서 봤던 속성 중 세가지 속성을 지닌다.(시퀀스 자료구조에서 슬라이싱을 뺀 나머지)
- 멤버쉽 연산자 : in
- 크기 함수 : len(seq)
- 반복성 : 반복문의 데이터를 순회한다.
- 파이썬의 내장 컬렉션 데이터 타입에는 셋 과 딕셔너리가 있다.
3.1 셋(set)
- 파이썬의 셋(집합, set)은 반복 가능(iterable)이고, 가변적이며(mutable), 중복 요소가 없고, 정렬되지 않은(collections 모듈은 정렬된 셋도 지원한다) 컬렉션 데이터 타입이다.
- 셋은 멤버쉽 테스트 및 중복 항목 제거에 사용된다.
- 셋의 삽입 시간복잡도는 O(1)
- 셋의 합집합(union) 시간복잡도는 O(m+n)
- 셋의 교집합(intersection) 시간복잡도는 O(n)
- 프로즌 셋(frozen set)은 일반 셋과 달리 불변형 객체이고 셋에서 사용하는 일부 메서드를 사용할 수 없다.즉, 프로즌 셋의 요소를 변경하는 메서드를 사용할수 없다. frozenset()으로 생성한다.
3.1.1 셋 메서드
- add() => A.add(x) 는 셋 A에 x가 없는 경우 x를 추가한다.
- update()와 |= 연산자 => A.update(B) 혹은 A |= B는 셋 B를 셋 A에 추가한다(합집합).
- union()과 | 연산자 => A.union(B)와 A|B 는 셋 A와 셋 B의 합집합인 셋을 반환한다.
- intersection()과 &연산자 => A.intersection(B)와 A&B는 셋 A와 셋 B의 교집합인 셋을 반환한다.
- difference()와 - 연산자 => A.difference(B)와 A-B는 셋 A와 셋 B의 차집합인 셋을 반환한다.
- clear() => A.clear()는 셋 A의 모든 항목을 제거한다.
- discard(), remove(), pop() =>
- A.discard(x)는 셋 A의 항목 x를 제거한다(in place).
- A.remove(x)는 A.discard(x)와 같지만, 항목 x가 없을 경우 KeyError 예외를 발생시킨다.
- A.pop()는 A에서 한 항목을 무작위로 제거하고 그 항목을 반환한다. 더 이상 삭제할 항목이 없다면 KeyError 예외를 발생시킨다.
3.1.2 셋과 리스트
- 리스트 타입은 셋 타입으로 변환(casting)할 수 있다.
- 딕셔너리에서도 셋 속성을 사용할 수 있다.
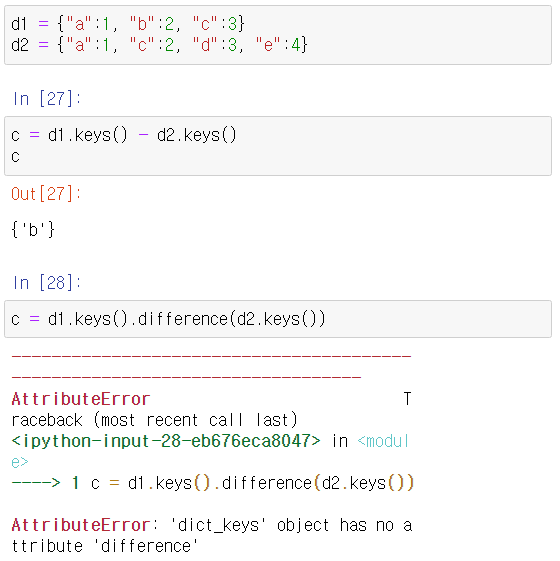
|,&,-은 지원하지만|=및 메서드는 지원하지 않는다.- 딕셔너리의 items()와 keys() 메서드에서 셋 연산을 사용할 수 있지만, values() 메서드에서는 셋 연산을 지원하지 않는다.
3.2 딕셔너리
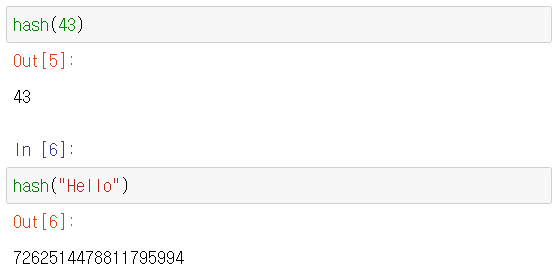
- 파이썬 딕셔너리는 해시 테이블(hash table)로 구현되어 있다.
해시 함수는 특정 객체에 해당하는 임의의 정수 값을 상수 시간 내에 계산한다. 이 정수는 연관 배열의 인덱스로 사용된다. - 연관 배열 : 연관 배열(associative array)은 자료구조의 하나로, 키 하나와 값 하나가 연관되어 있으며 키를 통해 연관되는 값을 얻을 수 있다. 연상 배열, 결합형 배열, 맵(map), 사전(dictionary)으로 부르기도 한다.
- 딕셔너리를 순회할 때, 정렬되지 않은 매핑 타입은 임의의 순서대로 항목을 순회한다.
- 딕셔너리는 가변형 이므로 항목의 추가 및 제거가 가능하다.
단, 파이썬 3.7부터는 표준 딕셔너리도 항목의 삽입 순서를 보존한다.
3.2.1 딕셔너리 메서드
- setdefault() => A.setdefault(key, default)를 사용하면 딕셔너리 A에 key가 존재할 경우 키에 해당하는 값을 얻을 수 있고, key가 존재하지 않는다면, 새 키와 기본값 default가 딕셔너리에 저장된다. setdefault() 메서드는 딕셔너리에서 키의 존재 여부를 모른 채 접근할 때 사용된다.

- update() => A.update(B)는 딕셔너리 A에 딕셔너리 B의 키가 존재한다면, 기존 A의 키, 값을 B의 키, 값으로 갱신한다. 만약 B의 키가 A에 존재하지 않는다면, B의 키, 값을 A에 추가한다.
- get() => A.get(key)는 딕셔너리 A의 key값을 반환한다. key가 존재하지 않으면 아무것도 반환하지 않는다. A["key"]와 다른점은 A["key"]는 key가 없을 시 KeyError 예외를 발생시킨다.
- items(), values(), keys() => 딕셔너리 뷰(view)이다. 딕셔너리 뷰란 딕셔너리의 항목을 조회하는 읽기 전용의 iterable객체이다.
- pop(), popitem() => A.pop(key)는 딕셔너리 A의 key 항목을 제거한 후, 그 값을 반환한다. A.popitem()은 딕셔너리 A에서 항목을 제거한 후, 그 키와 항목을 튜플로 반환한다.
- clear() => 딕셔너리의 모든 항목을 제거한다.
3.2.2 딕셔너리 성능 측정
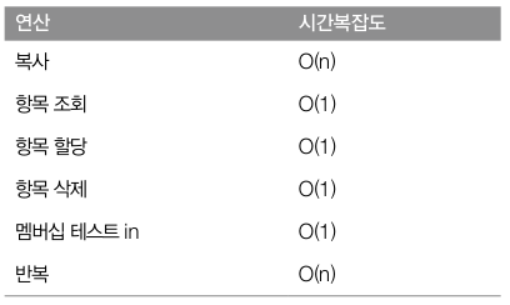
- 멤버쉽 연산에 대한 시간복잡도는 리스트는 O(n)인 반면, 딕셔너리는 O(1)이다.
3.2.3 딕셔너리 순회
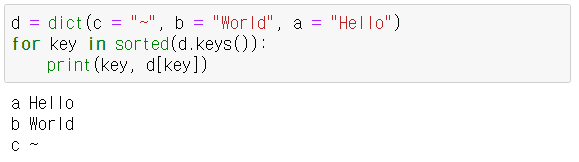
- 딕셔너리의 키는 삽입 순서(python3.7부터)대로 나타나지만, sorted()함수를 사용하면 정렬된 상태로 순회할 수 있다. sorted()함수는 딕셔너리의 keys(), values(), items()에 대해 사용가능하다.
3.2.4 딕셔너리 분기
- 두 함수를 조건에 따라 실행해야 한다고 가정해 볼때, if문을 쓰는 대신 딕셔너리를 사용하면 더 효율적으로 분기할 수 있다.

- 딕셔너리의 value값으로 함수객체를 저장시켜 놓고, 필요시에 소괄호를 붙여 호출할 수 있다.
3.3 파이썬 컬렉션 데이터 타입
- 파이썬의 collections 모듈은 다양한 딕셔너리 타입을 제공하며 위의 범용 내장형 딕셔너리보다 더 강력한 성능을 보인다.
3.3.1 기본 딕셔너리(default dictionary)
- collections.defaultdict 모듈에서 제공하는 추가 딕셔너리 타입이다. 내장 딕셔너리의 모든 연산자와 메서드를 사용할 수 있고, 추가로 다음과 같이 누락된 키도 처리가능하다.

- 내장 딕셔너리와 같은 경우는 키가 없을 경우를 대비하여 따로 코드를 작성해 주어야 하지만 defaultdict는 키가 없을 경우 자동으로 인자로 넘겨준 자료형의 False값으로 설정된다. (예: int는 0, list는 [])
3.3.2 정렬된 딕셔너리(ordered dictionary)
- collections.OrderedDict 모듈에서 제공하는 딕셔너리 타입이다.
내장 딕셔너리의 모든 메서드와 속성을 가지고 있고, 삽입 순서대로 항목을 저장한다(python3.7부터는 표준 딕셔너리도 삽입순으로 저장한다).
3.3.3 카운터 딕셔너리(counter dictionary)
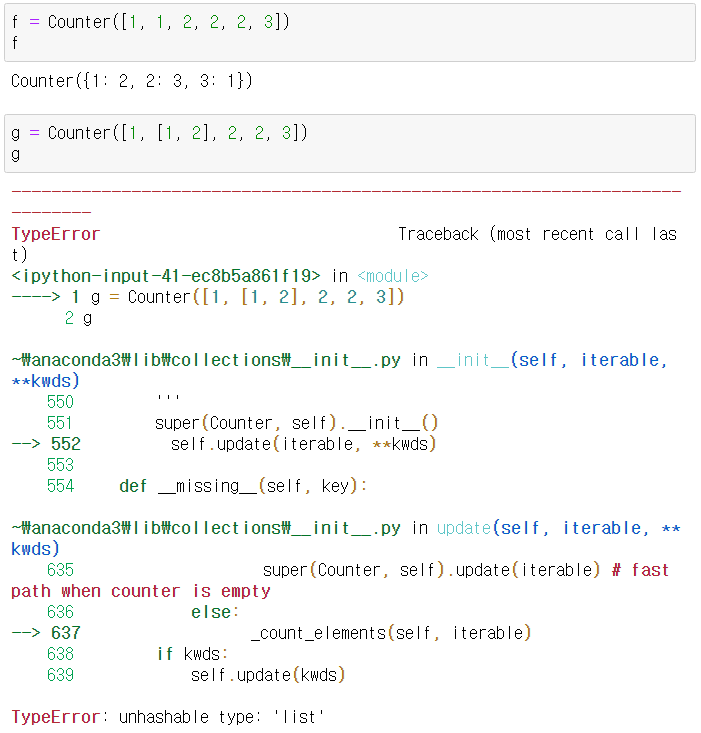
- 카운터 타입은 해시 가능한(hashable) 객체를 카운팅하는 특화된 서브클래스이다. collections.Counter 모듈에서 제공한다.


- update()로 갱신 가능하다.

- 셋의
|(합집합),-(차집합),&(교집합)연산자도 사용할 수 있다.
- update()로 갱신 가능하다.
- 해시 가능한 객체를 카운팅하는 자료형인데, 인자로 리스트(리스트는 해시불가능한 객체)가 들어갔음에도 카운팅이 되는 모습에 헷갈릴 수도 있다. 정확히 이해하자. 리스트 안에 있는 항목을 카운팅 하는거라서 그 항목이 해시 가능한 객체이면 된다.

프론트에_가까운_풀스택_개발자