- 시퀀스 타입은 다음과 같은 속성을 가진다
- 멤버쉽 연산 : in 키워드 사용
- 크기 함수 : len(seq)
- 슬라이싱 속성 : seq[:-1]
- 반복성 : 반복문에 있는 데이터를 순회할 수 있다.
- 파이썬에는 5가지(혹은 그 이상) 내장 시퀀스 타입이 있다.
- 문자열
- 튜플
- 리스트
- 바이트 배열
>>> ba = bytearray(b"")
>>> type(ba)
<class 'bytearray'> - 바이트
>>> b = bytes([])
>>> type(b)
<class 'bytes'>
- 이외에 네임드 튜플(named tuple)은 파이썬 표준 라이브러리인 collections 모듈에서 사용할 수있다.
2.1 깊은 복사와 슬라이싱 연산
2.1.1 가변성
-
불변형(immutable) 객체 : 튜플, 문자열, 바이트
-
가변형(mutable) 객체 : 리스트, 바이트배열
-
파이썬의 모든 변수는 객체 참조(reference)이므로 가변 객체를 복사할 때는 매우 주의해야 한다.
-
얕은 복사(shallow copy) :
- 객체의 1단계 주소만 복사한다. 즉, mutable한 A객체 안에 mutable한 B객체가 존재하는 A객체를 얕은 복사를 하여 C객체를 만들었을때, C객체안의 mutable한 객체를 수정시 B객체도 같이 수정된다.

- 객체의 1단계 주소만 복사한다. 즉, mutable한 A객체 안에 mutable한 B객체가 존재하는 A객체를 얕은 복사를 하여 C객체를 만들었을때, C객체안의 mutable한 객체를 수정시 B객체도 같이 수정된다.
-
깊은 복사(deep copy) :
- 객체 안의 객체 까지 새로 메모리에 할당한다.

- 객체 안의 객체 까지 새로 메모리에 할당한다.
- 가변형 객체를 얕은 복사(shallow copy)하는 방법
- 리스트
- myList = [1, 2, 3, 4]
- newList = myList[:]
- newList2 = list(myList)
- set
- foods = {"사과", "딸기", "복숭아"}
- fruits = foods.copy()
- dict
- myDict = {"Hello":"World"}
- newDict = myDict.copy()
- 리스트
- 가변형 객체를 깊은 복사(deep copy)하는 방법
- copy 모듈을 사용한다.
객체2 = copy.deepcopy(객체)
2.1.2 슬라이싱 연산자
- seq[시작]
- seq[시작 : 끝]
- seq[시작 : 끝 : 스탭]
2.2 문자열
-
파이썬은 불변형의 str타입을 사용하여 문자열을 표현한다.
-
파이썬의 모든 객체에는 두 가지 출력 형식이 있다.
- 문자열(str)형식
- 표현(repr)형식
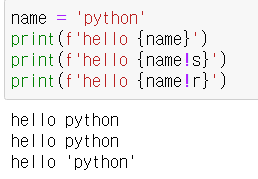
-
위의 그림에서는 python이라는 문자열을 담고있는 name 객체를 출력하였다. 각각 기본형(문자열), 문자열형, 표현형 으로 출력했다.
-
문자열 형식과 표현 형식의 출력형태는 문자열객체를 빼고는 같다. 문자열 객체를 출력할때만 따옴표가 붙는다.

-
사용자 객체를 기본형과 repr() 과 str()로 출력해보았다. 같은 결과가 나온다.

-
클래스에
__repr__()와__str__()매직 메서드를 추가하고 출력해보았다. -
repr() 함수는
__repr__()를 호출하고, str() 함수는__str__()를 호출했다. 그리고 기본형으로 출력했을땐,__str__()를 호출하는걸 알 수 있다. -
__repr__()은 개발자를 위한 것이다. 본질적인 목적은 대상이 무엇인지를 명확하게 설명하는 것이다. -
__str__()은 최종 사용자를 위한 것이다. 본질적인 목적은 객체에 포함된 데이터를 읽을 수 있는 방식으로 설명하는 것이다.

-
repr로 출력하면 따옴표가 붙여서 나오는걸 확인할 수 있다. 저것의 의미는 Car클래스의 BMW인스턴스라는걸 명확히 보여준다.
반면에, str로 출력하면 따옴표가 붙지않아서 의미가 모호하다.
따라서 repr은 객체가 무엇인지 명확하게 보여주는데 쓰이고, str은 코드를 사용하는 사용자가 읽기 쉽게 설명하게 적는것이 바람직하다. -
객체를 정의 할때 위에 나온 문자열의 두가지 표현형식을 사용하는게 바람직하나, 하나만 쓰겠다고 한다면 repr을 하는게 낫다. 왜냐하면
__str__()이 정의되지 않았을때 자동으로__repr__()을 호출하기 때문이다. 반면에__str__()만 정의되었다면 repr()로는__str__()에 접근을 못하고 원래 출력하는것 처럼 그 객체의 주소만 출력되기 때문이다. -
인터프리터에서 print()를 쓰지않고 출력되는 경우는 repr을 호출한 것이다. 그래서 문자열을 출력하면 따옴표가 붙여져서 나온다.
2.2.1 유니코드 문자열
- Python3 부터는 모든 문자열이 일반적인 바이트가 아닌 유니코드이다.
- 문자열 앞에 u를 붙이면 유니코드 문자열을 만들수가 있다.
- 일반적인 아스키 코드의 표현은 7비트(아스키 코드를 확장한 ANSI 코드는 8비트)이고, 유니코드 표현에는 16비트가 필요하다.
2.2.2 문자열 메서드
- join() => 문자열.join(리스트)

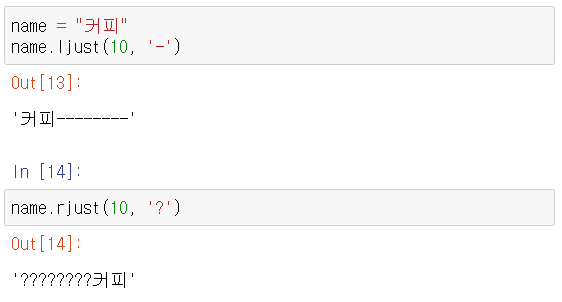
- ljust(), rjust() => 문자열.ljust(width, fillchar), 문자열.rjust(width, fillchar)
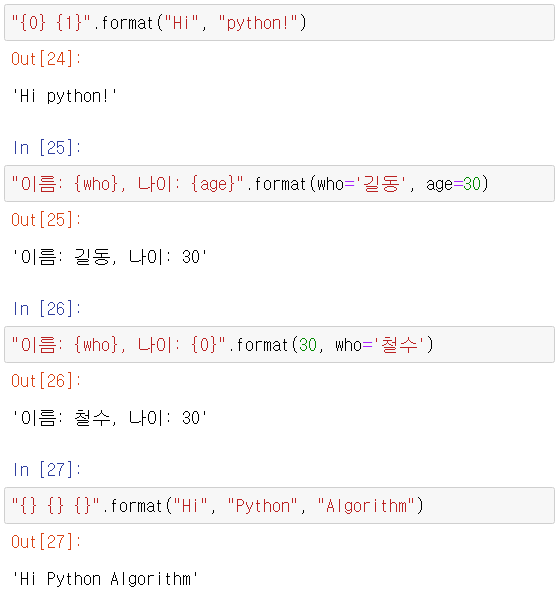
- format()
- 문자열 언패킹 => 문자열 언패킹 연산자는
**이다.
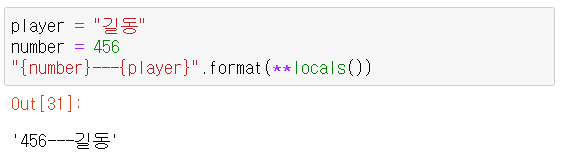
이 코드를 알기위해선 locals() 함수에 대한 설명이 필요하다.
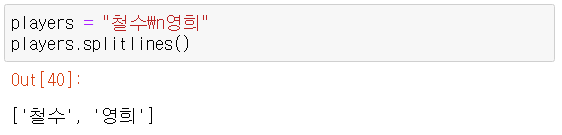
이 함수는 현재 스코프에 있는 지역변수를 딕셔너리로 반환하는 함수이다. 즉,"{number}---{player}".format(player:"길동", number:456)가 되고 함수에 딕셔너리 형태가 전달될때는 자동으로 변환되어서 최종적으로"{number}---{player}".format(player="길동", number=456)가 되어서 위의 출력결과가 나온다. - splitlines() => 문자열.splitlines()
- split() => 문자열.split(문자열t, 정수n). 문자열 t를 기준으로 정수 n번만큼 분리한 리스트를 반환한다. n생략시 최대로 분리하고 t생략시 공백문자로 구분한다.
- strip() => 문자열.strip(문자열b). 문자열 앞뒤의 문자열b를 제거한다. 단, 제거할때 문자열 단위로 제거되는게 아니라 문자 하나단위로 제거된다.
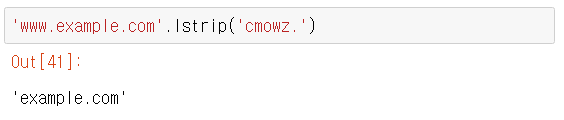
- lstrip(), rstrip() => strip()의 왼쪽만, 오른쪽만 버전
- swapcase() => 문자열.swapcase(), 문자열의 대소문자 반전
- index(), find() => 문자열.index(sub문자열, start, end), 문자열.find(sub문자열, start, end). 문자열 내에 sub문자열이 없다면 index()는 ValueError를 발생시키고, find()는 -1값을 반환한다. 인덱스start, end는 문자열 범위이며, 생략시 전체 문자열에서 찾는다. rindex()와 rfind()는 문자열의 끝(오른쪽)에서 부터 일치하는 부분 문자열 sub의 인덱스를 반환한다.
- count() => 문자열.cound(sub, start, end). 문자열에서 start, end인덱스 범위내의 sub문자열이 나온 횟수를 반환한다.
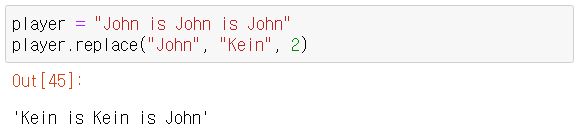
- replace() => 문자열.replace(old, new, maxreplace)
- f-string => 기존의 %나 .format 방식에 비해 간결하고 직관적이며 속도도 빠르다.
2.3 튜플
- 튜플은 불변형(immutable) 시퀀스 타입이다.
- 리스트와 같이 가변형 타입을 포함하는 튜플을 만들 수도 있다. 그 경우 튜플의 아이템인 리스트는 변경 가능하다.
- 아이템이 1개인 튜플을 생성하려면
(item)가 아닌(item,)로 해야한다. 그 이유는 쉼표를 쓰지 않으면 소괄호가 튜플을 뜻하는게 아니라 연산자 소괄호로 취급되기 때문이다.
2.3.1 튜플 메서드
- count() => A.count(x)는 튜플 A에 담긴 항목 x의 개수를 반환한다.
- index() => A.index(x)는 튜플 A에 담긴 항목 x의 인덱스 위치를 반환한다.
2.3.2 튜플 언패킹
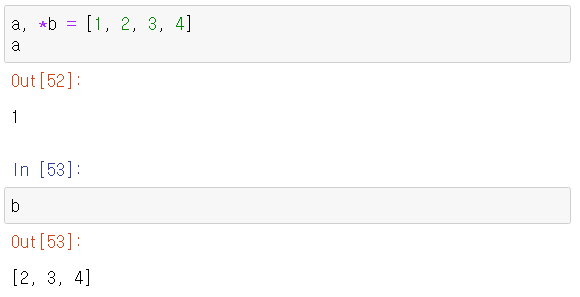
- 파이썬에서 모든 반복 가능한(iterable) 객체는 시퀀스 언패킹 연산자 * 를 사용하여 언패킹할 수 있다.

2.3.3 네임드 튜플
- 파이썬 표준 모듈 collections에는 네임드 튜플 이라는 시퀀스 데이터 타입이 있다.
- 네임드 튜플은 일반 튜플과 비슷하지만, 튜플 항목을 인덱스 위치뿐만 아니라 이름으로도 참조할 수 있다.

- 메서드의 첫 번째 인수는 만들고자 하는 사용자 정의 튜플 데이터 타입의 이름이다. (보통 할당하는 변숭의 이름과 동일하게 작성한다).
- 두 번째 인수는 사용자 정의 튜플 각 항목을 지정하는 '공백으로 구분된 문자열'이다. (리스트 또는 튜플로 지정할 수도 있다).
- 관용적으로 클래스 처럼 대문자를 사용한다.
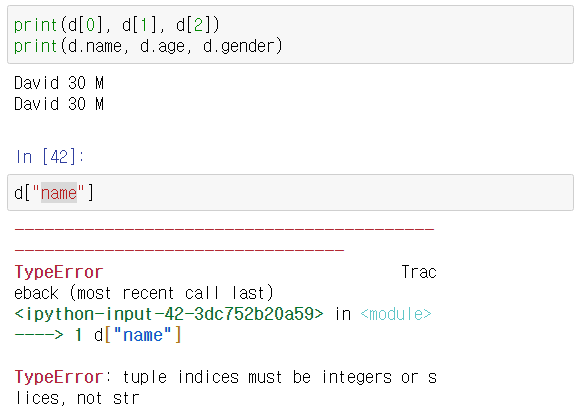
- .연산자를 이용해서 이름으로도 각 항목에 접근이 가능하지만 딕셔너리처럼 []를 이용해서 접근은 불가하다.
2.4 리스트
-
배열(또는 파이썬이 리스트)는 여러 요소들이 연속된 메모리에 순차적으로 저장되는 구조이다.
-
연결 리스트는 여러 분리된 노드가 서로 연결되어 있는 구조이다.
-
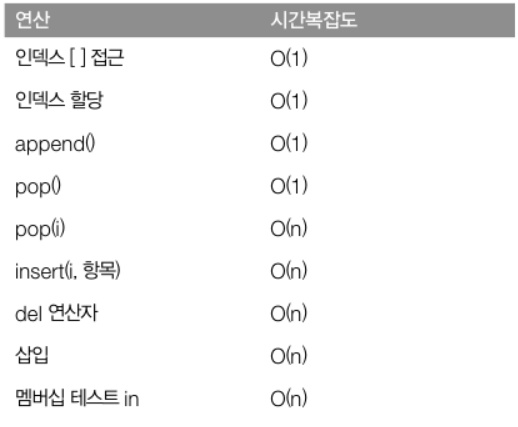
어떤 요소에 직접 접근할 때 배열의 시간복잡도는 O(1)이고, 연결 리스트는 O(n)이다. 연결리스트는 어떤 노드에 접근하려면 처음부터 순회를 시작해야 한다.
-
또한 연결 리스트에서 어떤 노드를 삽입할때는 노드들이 메모리에 연속적이게 저장되어 있지 않기때문에, 그 위치를 안다면 노드 수에 상관없이 시간복잡도는 O(1)이다.
-
배열에서 어떤 위치에 항목을 삽입하려면, 그 위치에서부터 모든 항목을 오른쪽으로 옮겨야 하므로 시간복잡도는 O(n)이다.
-
리스트 끝에서 항목을 추가/삭제 할땐 append()/pop() 메서드를 사용하며, 시간복잡도는(1)이다. 단, 리스트 중간에 항목을 삽입하는 insert() 메서드는 항목을 삽입한 후, 그 이후의 인덱스 항목들을 한칸씩 뒤로 밀어야 하므로 시간복잡도는 O(n)이다.
-
리스트 항목을 검색해야 하는 remove(), index(), 멤버쉽 테스트 in 등의 시간복잡도는 O(n)이다.
-
검색이나 멤버십 테스트 시 빠른 속도가 필요하면 셋이나 딕셔너리같은 컬렉션 타입을 선택하는 것이 더 적합할 수 있다.
-
리스트에서 항목을 순서대로 정렬하여 보관하면 빠른 검색을 제공할 수 있다.(시간복잡도가 O(logn)인 이진 검색 알고리즘)
2.4.1 리스트 메서드
- append() => A.append(x), 리스트 A 끝에 항목 x를 추가한다.
- extend() => A.extend(c), 모든 항목 c를 리스트 A에 추가한다.
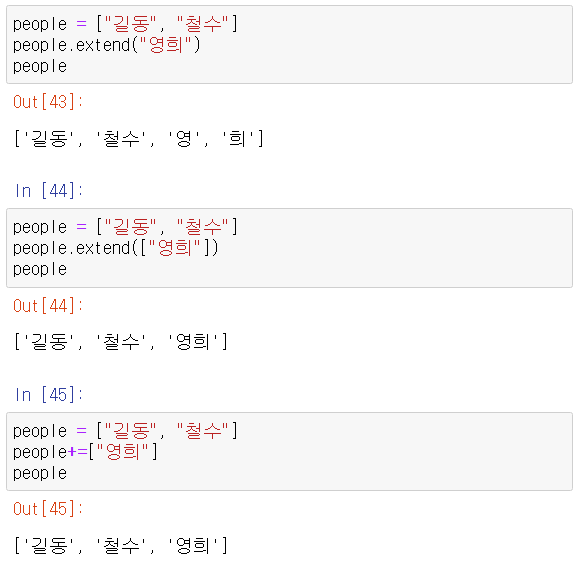
- insert() => A.insert(i, x)는 리스트 A의 인덱스 위치 i에 항목 x를 삽입한다.
- remove() => A.remove(x)는 리스트 A의 항목 x를 제거한다. x가 존재하지 않으면 ValueError를 발생시킨다.
- pop() => A.pop(x)는 리스트 A에서 인덱스 x에 있는 항목을 제거하고 그 항목을 반환한다. x생략시 맨 끝 항목이 대상이 된다.
- del문 => del문은 리스트 인덱스를 지정하여 특정한 항목을 삭제한다. 또는 슬라이스를 사용하여 범위를 삭제할 수도 있고 변수 자체도 삭제 가능하다. 특이점은 소괄호를 사용하지 않는다는 점이다.
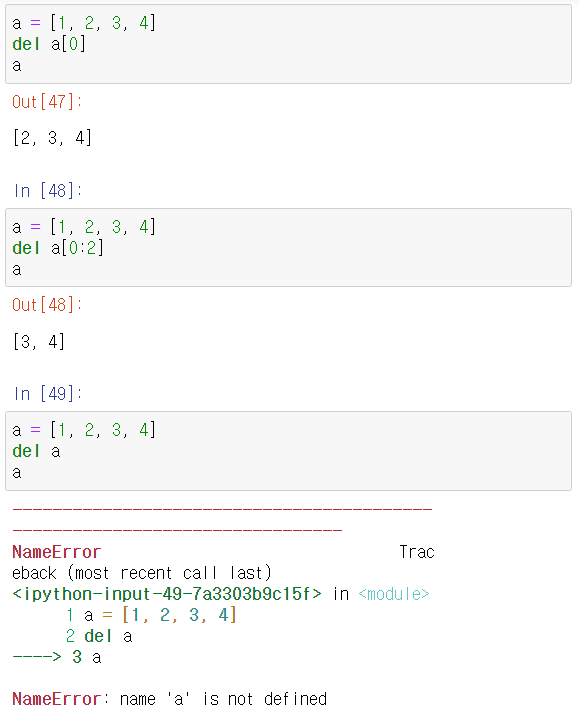
- index() => A.index(x)는 리스트 A에서 항목 x의 인덱스를 반환한다.
- count() => A.count(x)는 리스트 A에 항목 x의 개수를 반환한다.
- sort() => A.sort(key, reverse)는 리스트 A의 항목을 정렬하여 변수 자체에(in place) 적용한다. key 는 인자 하나를 받아들이는 함수를 지정하는데, 각 리스트 요소에서 비교 키를 추출하는 데 사용된다. 기본값 None 은 리스트 항목들이 별도의 키값을 계산하지 않고 직접 정렬된다는 것을 의미한다. reverse 는 논리값이다. True 로 설정되면, 각 비교가 역전된 것처럼 리스트 요소들이 정렬된다.

- reverse() => A.reverse() 메서드는 리스트 A의 항목들을 반전시켜서 그 변수 자체에(in plac) 저장한다. list[::-1]과 동일하다.
2.4.2 리스트 언패킹
- 튜플 언패킹과 비슷하다.
- 함수의 전달 인수로 별 인수(starred argument)를 사용할 수도 있다.
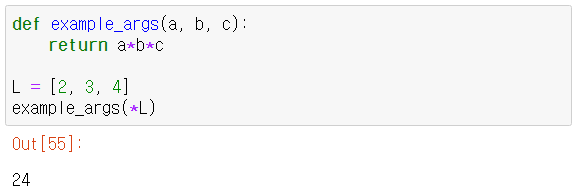
- 튜플과 리스트의 언패킹의 응용

2.4.3 리스트 컴프리헨션
- 리스트 컴프리헨션은 반복문의 표현식이다.
- [ 항목 for 항목 in 반복 가능한 객체 ]
- [ 표현식 for 항목 in 반복 가능한 객체 ]
- [ 표현식 for 항목 in 반복 가능한 객체 if 조건문 ]
- 리스트 컴프리헨션은 단순한 경우에만 사용하는 것이 좋다. 가독성을 위해서는 여러 줄의 표현식과 조건문으로 표현하는 것이 리스트 컴프리헨션 한 줄로 표현하는 것보다 나을 수도 있다.
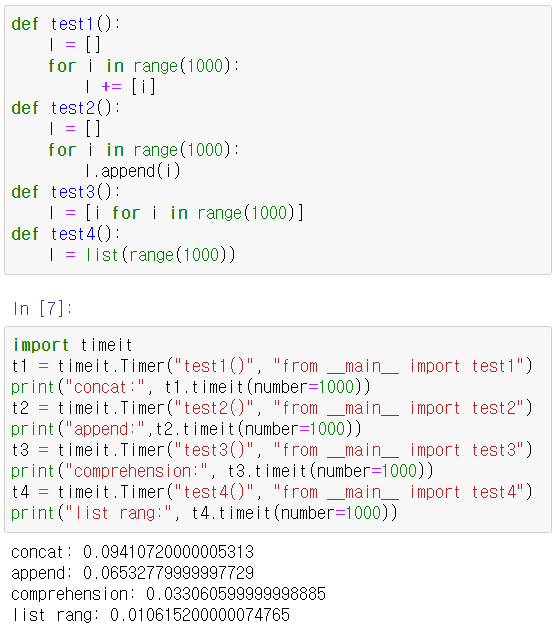
2.4.2 리스트 메서드 성능 측정
- 아래 테스트에서는 timeit 모듈의 Timer 객체를 생성해 사용한다. Timer 객체의 첫 번째 매개변수는 우리가 측정하고자 하는 코드이며, 두 번째 매개변수는 첫 번째 매개변수 코드 테스트를 위한 설정문이다. 즉 첫 번째에 어떠한 변수가 오면 그 변수를 두 번째 매개변수에 정의해야 한다.
- timeit 모듈은 명령문을 정해진 횟수만큼 실행하는 데 걸리는 시간을 측정한다.(기본값은 number = 1000000)
- 테스트가 완료되면, 문장이 수행된 시간(밀리초)를 부동소수점 값으로 반환한다.

2.5 바이트와 바이트 배열
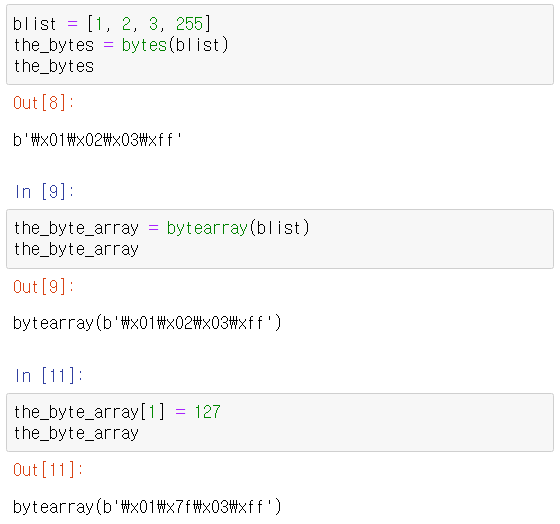
- 파이썬은 원시 바이트를 처리하는 데 사용할 수 있는 데이터 타입으로 불변형인 바이트(bytes)와 가변형인 바이트 배열(bytearray)을 제공한다.
2.5.1 비트와 비트 연산자
- 비트 연산자는 비트로 표현된 숫자를 조작하는데 유용하다.
- 곱셈 연산자 대신 비트 연산자로 곱셈을 할 수 있다.
1 << x는 숫자 1을 x번 만큼 왼쪽으로 시프트 한다는 의미이다. - 또한
x & (x - 1)이 0인지 확인하면, x가 2의 제곱인지 아닌지 신혹하게 확인할 수 있다. (2의 제곱인 수들은 맨 첫자리만 1이고 나머지는 0이다. 그러므로x & (x - 1) == 0이면 2의 제곱수가 된다.
