호이스팅
console.log(a)
let a = "a";
이 코드를 실행하면 a is not defined 라는 에러가 뜸
즉 let 키워드는 사전에 잘못된 동작을 방지해줌
console.log(b)
var b = "b";
이 코드를 실행하면 undefined 반환값을 줌
즉 var 키워드는 계속 언디파인드 상태로 코드가 실행이됨
이러한 차이가 나는 이유는 호이스팅 때문이다.
호이스팅이랑 함수가 선언되기 전에 먼저 코드가 읽히는거
var 키워드로 선언하면 먼저 선언부가 위로 올라가게 됨
즉
var b;
console.log(b)
b = "b"
이런식으로 올라가게 됨 (실제로는 올라가지 않음)
그래서 언디파인드가 반환이 됨
let 키워드는
console.log(a)
let a = "a";
이렇게 순서대로 코드가 읽혀짐
그래서 var 키워드는 지향해야함
함수도 호이스팅이 발생함
fn1();
function fun1() {
console.log("A")
}
이 함수를 선언하기 전에 호출해도 작동이됨
fun2()
const fn2 = function() {
console.log("b")
}
이 코드를 실행하면 fn2 is not defined라는 에러가 뜸
즉 사전에 오류 방지
function fun1() {
console.log("A")
}
fn1();
왜 이 함수가 작동외 되나면 이렇게 코드순서로 읽음
변수 선언 단계는 총 3개의 단계를 지나게 된다
선언 단계 => 초기화 단계 => 할당 단계 =>
선언 단계: 선언한 변수를 식별자가 담기는 객체에 할당하는 객체
식별자란? 변수 선언할때 let test =1; 변수명 test가 식별자라고 한다.
초기화 단계: 변수에 할당할 메모리 공간을 부여하는 단계이다.
할당 단계: 정의된 변수에 데이터가 할당되는 단계
선언 단계와 초기화 단계 전에 tdz라는 공간이 있음
이 단계는 변수에 할당할 메모리가 부여되기 전 단계이다.
즉 let와 const는 코드가 작성된 곳으로 도달하기 전까지 tdz라는 공간에 머무름
let와 const도 val와 같이 호이스팅이 발생하기는 함 하지만 tdz라는 공간에 머무르기 때문에
사전에 오류를 방지해줌
var 키워드는 tez 공간에 안머무르기 때문에 코드가 작동이 되는거임 그래서 언디파인드 상태로 작동
함수 선언식은 tdz의 영향을 받지 않는다.
API
api란 어떠한 프로그램에서 제공하는 기능을 사용자가 활용할 수 있도록 만들어 둔 인터페이스이다.
즉 유저가 서버에게 요청을 하고 서버는 필요한 데이터를 전달해 준다.
즉 데이터를 주는 것을 응답이라고 한다.
HTTP
Hypertext Transfer Protocol
서버와 클라이언트가 통신하기 위해 정의된 규약을 HTTP라고 한다.
GET : 서버의 데이터를 조회하는 메소드
POST : 서버의 데이터를 등록하는 메소드
PUT : 서버 내 데이터를 수정하는 메소드
PATCH : 데이터를 일부 수정하는 메소드
DELETE : 서버의 데이터를 삭제하는 메소드
OPTIONS : 서버가 허용하는 메소드를 확인하기 위한 메소드
동기와 비동기
동기 방식은 서버에 요청을 했을 때 응답을 받아야 그 다음 동작을 수행할 수 있다.
예를 들어서 a작업을 요청 했으면 a을 응답해 올때까지 b작업은 대기해야 한다.
비동기 방시은 서버에 요청을 보냈을 때 응답이 왔는지 안왔는지 상관없이 다음 작업도 수행할 수 있다
a작업을 요청 했으면 b작업도 수행 가능
자바스크립트는 동기작동하고 비동기적으로도 작동한다.
stack, queue
자료구조에는 스택과 큐가 있다.
자료구조란 컴퓨터의 데이터를 효율적으로 관리하기 위한 체계이다.
스택은 LIFO인데 먼저 들언온 데이터가 가장 늦게 나가고 마지막으로 들어온 데이터가 먼저 실행이 된다.
큐가 먼저 들어온 데이터가 먼저 실행이 된다. 나중에 들어온 데이터가 마지막으로 실행이 된다.
Promise 객체
Promise의 상태는 3가지 상태가 있다.
1. fulfilled: 요청이 성고한 상태
2. pending: 요청에 대한 응답을 기다리고 있는 상태
3. rejected: 요청이 실패한 상태
then, catch
좀더 공부를 하고 적겠다.
구조분해할당
구조분해할당이란 구조화 되어 있는 배열, 객체와 같은 데이터를 destructuring 시켜, 각각의 변수에 담는 것을 말한다.
let arr = [1, 2, 3, 4, 5] 라는 배열이 있다면
let one = arr[0];
let two = arr[1];
이렇게 각 변수에 배열의 요소를 담는 방법이 있었다.
이 방법을 사용하려면 코드 5줄이 필요하다.
이 방법보다 간편하게 하는 방법이 있다.
let arr = [1, 2]
let[one, two] = arr
이렇게 배열의 요소를 담을 수 있다.
console.log(one, two) // 1 2 가 출력이 된다.
즉 배열에 있는 구조를 분해해서 각 변수에 할당하는 방법이다.
let[one, two] = {name: "otter"}
객체는 위 방법으로는 못한다.
{(intermediate)}is not iterable 라는 오류가 뜸
객체는 구조 분해 할당을 하지 못할까??
let obj = {name: "홍길동", gender: "남성" }
let newname = obj.name
let newgender = obj.gender
객체는 이렇게 키의 값을 담을 수 있다
console.log(newname, newgender) // 홍길동 남성 <출력
이런식으로 구조 분해가 가능한데 이러면 코드가 길어진다.
let obj = { name: "홍길동", gender: "남성" }
let {name, gender} = obj
이렇게 간단한 방법이 있다.
console.log(name, gender) // 홍길동 남성 <출력이 된다.
즉 name, gender 라는 변수에 담김
배열의 구조 분해할당은 순서가 중요 했다.
객체는 순서보다는 키의 이름이 중요하다.
만약 객체에 존재하지 않는 age라는 키를 적으면 구조분해할당이 안된다.
객체의 구조 분해 할당은 키의 이름으로 변수명을 꼭 할필요가 없다.
원하는 이름으로 할당이 가능하다.
let { name: newName , gender: newGender } = obj
이렇게 하면 새로운 변수명으로 할당이 가능하다.
console.log(newName, newGender) // 홍길동 남성
spread 연산자
spread 연산자는 하나로 뭉쳐있는 값들의 집합을 전개해주는 연산자이다.
spread 연산자는 ... 이다
let arr = [1, 2, 3, 4, 5]
console.log(arr) // [1, 2, 3, 4, 5]
console.log(...arr) // 1 2 3 4 5
arr 라는 변수 앞에 ...을 붙여주면 배열을 벗겨줌
let str = "Hello"
console.log(str) // "Hello"
console.log(...str) // "H" "e" "l" "l" "o"
이렇게 문자열에도 스프레드 연산자 사용이 가능하다.
객체에도 스프레드 연산자 사용이 가능하다.
const obj = {name: "otter", gender: "male" }
const newObj = ...obj // 오류
객체는 이렇게 사용 불가
const copyObj = {...obj}
// 객체는 이렇게 사용해야 한다.
// ...obj를 하면 중괄호 밖으로 벗어 나는데 다시 한번 중괄호로 감싸주는 거다.
// 즉 새로운 객체 탄생
copyObj // {name: "otter", gender: "male"
즉 copyObj의 키값을 변경을 해도 원본 객체한테는 영향이 안간다.
하지만 객체 안에 객체가 있으면 완벽한 복사가 되지 않는다.
즉 객체 안에 객체는 복사가 안되어 새로운객체의 값을 변경을 하면 원본객체에 영향이 간다.
깊은 복사, 얕은 복사
얕은 복사: 주소값까지만 복사하는 얕은 복사
깊은 복사: 실제 데이터까찌 복사하는 깊은 복사
const obj = {name: "otter", gender: "male" }
const 키워드는 재할당과 재선언이 안된다고 하였다.
근데 객체랑 배열안에 요소와 키값을 변경이 가능하였다.
const는 재할당이 되는건가라는 의문이 생길 수 있다.
하지만 재할당이 되는건 아니다.
const 키워드로 선언된 obj(안에 담긴 주소값)는 변환되지 않는다.
근데 왜 배열과 객체를 const로 선언을 하는 것인가?
const로 선언을 하면 어떤 값이 담겨져 있는지 확실할 수 있기 때문이다.
얕은 복사

얕은 복사의 방법이다.
매번 각각의 값을 복사하는 단점이 있다.
이 단점을 극복하는 방법 스프레드 연산자를 사용한다.

배열에도 스프레드 연산자 사용이 가능하다.

이렇게 두 배열을 합쳐서 복사가 가능하다.
깊은 복사

이렇게 복사를 하면 원본 객체에도 영향이 간다.
즉 제대로 복사가 되지 않는다.
그래서 깊은 복사가 필요하다.
얕은 복사가 된 이유는 주소값만 복사를 해왔기 때문이다.
즉 주소안에 있는 데이터까지 복사를 하지 않았기 때문이다.
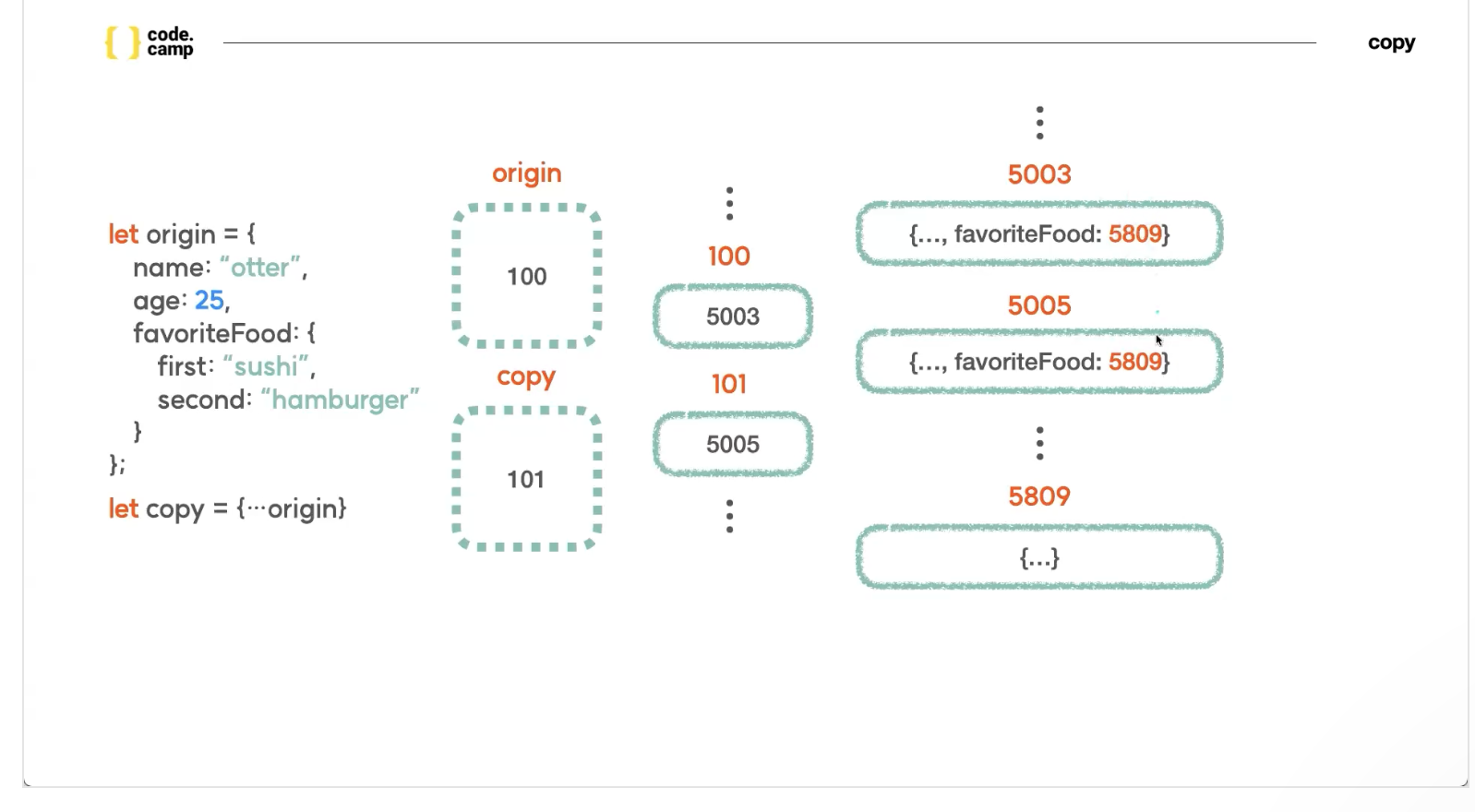
이게 바로 얉은 복사이다.
깊은 복사의 방법은

json데이터 포맷으로 변경해주는 stringify 메소드 안에 배열과 객체를 넣어준다.

json.parse 라는 메소드 안에 다시 객체와 배열을 넣어주면
깊은 복사가 가능하다.

이게 왜 깊은 복사이나면 deepCopy라는 객체가 새로운 주소값이 생기기 때문이다.
rest 파라미터
rest parameter는 객체의 특정 키만 가져와서 깊은 복사를 하고 싶을때 사용이 가능하다.

즉 이렇게 필요한 데이터만 가져오고 싶을때 rest를 사용한다.
...rest라는 변수명을 꼭 rest라고 사용안해도 된다.
즉 ...any 같은 다른 변수명도 가능하다.
